deepseek-tech-notes · 中文导读
丝滑阅读 × 深度拆解 × 前沿跟进 — 非官方 DeepSeek 技术笔记(V1→V4)。与 DeepSeek 官方无隶属关系。
Smooth, deep notes on frontier DeepSeek tech. Unofficial; not affiliated with DeepSeek.
推荐阅读
本笔记是双向引用 wiki:文首有反向回链,文内有正向深入链接。要发挥这套导航的价值,请用下面两种方式之一——不要用 GitHub 仓库内的 blob 预览。
| 方式 | 何时用 | 导航怎么玩 |
|---|---|---|
| IDE Preview(VS Code / Cursor) | 已 clone 仓库、本地精读或改稿 | 点文首 ← 回链与文内链接即可跳转;可开预览分栏或沿预览历史回溯——正向 / 反向引用价值最大 |
| GitHub Pages(mdBook) | 在线阅读、无需 clone | 公式、图示与 IDE 一致;用浏览器 后退 / 前进 沿阅读路径返回上一篇或再进下一篇,效果与 IDE 里点链接类似 |
小结:本地 IDE Preview 与 Pages 二选一即可;编辑与 PR 仍在本仓库 docs/ 进行。
善意提醒:正文里的 SVG 插图下方,通常都有 「图示详情」 链接——点进去可在新页查看可缩放的原图。不少机制就写在图里的箭头、分区与小字标注里,值得放慢节奏、仔细品读。
项目仍在完善中:梗概补全、书中镜像、链接与图示校验仍在推进。阅读时请以各篇文首的 arXiv / 官方 PDF 为准;发现断链、口径不一致或表述错误,欢迎提 issue。
这个项目在做什么
我从 DeepSeek V1 技术报告 一路跟到 V4,并把大部分主要技术文章里的机制与细节拆开写清楚:架构怎么变、训练/推理在优化什么、版本之间如何衔接。
范围包括:
- DeepSeek 主线(见 算法线 · MoE 线):MLA、DeepSeekMoE、aux-loss-free 路由、MTP、RLVR / R1、DSA、CSA / HCA、mHC、Hash MoE、V4 异构 KV 等。
- V4 及衍生的推理技术(见 基础设施线):如 DSpark 投机解码(半自回归 draft + 置信度调度验证)、HiSparse、磁盘 Prefix Cache 等。
- 叠在 DeepSeek checkpoint 上的衍生工作——尤其 AI Infrastructure 向:
- Index Share / IndexCache(清华 + 智谱):跨层复用 DSA indexer 的 top-$k$ index,纯推理补丁;逻辑详解
- ESS(百度百舸):Latent-Cache CPU offload,与 DSA 算法正交;论文梗概
演进
版本演进总览 — 全系列唯一主线入口:时间线 + 算法 / 基础设施 / MoE 三线;各版本与 infra 补丁的内链均从此文展开。

{kind=link}

图示详情 · RLVR / GRPO · R1
{kind=link}

图示详情 · DSpark 投机解码 · MTP 融合 scheme
{kind=link}
文章
| 主题 | 一句话 |
|---|---|
| V1 | DeepSeek-LLM 完整中文译文 |
| V1 BBPE | Byte-level BPE 词表与预分词 |
| V2 | 236B/21B;MLA + DeepSeekMoE 首次引入 |
| V3 | 671B MoE + MLA 开源旗舰基座 |
| V3 FP8 | 训练侧 FP8 块级动态量化 |
| R1 | V3-Base + RLVR;架构不变 |
| RLVR / GRPO | 可验证奖励 + 组内相对优化 |
| V3.1 | Hybrid 推理,128K |
| V3.2 | DSA 稀疏注意力 |
| DSA | indexer + top-$k$ + Core MLA |
| Index Share | IndexCache 纯 infra 补丁 |
| ESS · 论文梗概 | Latent-Cache CPU offload |
| V4 | CSA + HCA + mHC;1M context |
| CSA / HCA | 4:1 稀疏 + 128:1 dense 混合压缩注意力 |
| mHC | 双随机流形约束超连接 |
| Hash MoE + FP4 | Hash 路由 + routed expert FP4 |
| V4 KV | Classical + State 双池 |
| V4 HiSparse | inactive C4 CPU offload |
| V4 磁盘 Prefix | CSA/HCA 落盘 + SWA 三档策略 |
| DSpark | V4 投机解码:半自回归 draft + 置信度验证 |
| MLA | latent 压缩 KV |
| DeepSeekMoE | 细粒度 routed + shared experts |
| MoE 路由 | aux-loss-free 动态 bias 负载均衡 |
| $L_{\mathrm{Bal}}$ | 序列内专家均衡损失 |
| Hyper-Connections | $n$ 路并行残差流;mHC 前置 |
许可
| 范围 | 许可 |
|---|---|
| 导读、图示、成书读本 | CC BY 4.0 |
scripts/ | MIT |
docs/engram/ | Apache 2.0 |
docs/material/ 镜像 | 上游 / 原论文许可 |
DeepSeek 论文、权重与官方代码库另有其许可;引用时请以 arXiv / 官方发布 为准。
DeepSeek 版本演进:V1 → V3 → V3.2 → V4,Index Share 与 KV-offload
更新:2026-06-25 ← 中文导读 · ← 仓库首页(EN) · V1→V3 前代演进
1. 总览
DeepSeek 开源主线分两段:
- V1 → V2 → V3(2024):稠密双语基座 → MLA + MoE → 671B 旗舰(详见 V1→V3 演进)
- V3 之后(2025–2026):R1 / V3.1 / V3.2 / V4 与 infra 补丁
V3 发布后的 Attention / KV infra 与全系列的 MoE 可概括为三条线:
- 算法线:MLA → DSA 稀疏注意力 → CSA/HCA 混合压缩注意力 + mHC
- 基础设施线:标准 MLA KV cache → Indexer/Latent 异构 cache → Index Share → ESS offload → V4 异构 KV + HiSparse
- MoE 线:稠密 FFN → DeepSeekMoE → aux-loss-free 路由 + $L_{\mathrm{Bal}}$ → Hash MoE + FP4
1.1 各工作优化方向分类
下列 §3 版本 与 §4–§6 infra 中的每一项工作,按三条正交优化轴归类。多轴并存时给出 比例(合计 100%);单列 100 表示该工作主要落在此轴。
| 轴 | 含义 | 典型内容 |
|---|---|---|
| 模型 | 权重、数据、对齐与后训练 | scaling laws(答疑)、词表、SFT/DPO / RL(R1)、Hybrid 能力、checkpoint 规模 |
| 架构-train | 为训练改结构或训推系统 | MoE 路由(DeepSeekMoE)、MTP 辅助头、mHC、Muon、FP8 训推数值、DSA / CSA 等需重训的算子 |
| 架构-infer | 为推理改结构或纯 infer 补丁 | MLA latent KV、Prefill/Decode 模式切换、DSA 异构 cache、Index Share、ESS、DSpark、HiSparse |

{kind=link}
版本 / 工作一览:
| 工作 | 模型 % | 架构-train % | 架构-infer % | 产出机构 | 发表时间 | 说明 |
|---|---|---|---|---|---|---|
| V1 scaling / BBPE / SFT·DPO | 100 | — | — | DeepSeek | 2024-01 | 数据管线、词表、对齐(SFT/DPO);结构为常规模型 |
| MLA(V2 起) | — | 40 | 60 | DeepSeek | 2024-05 | 低秩 KV;训推同构,显存/吞吐收益主要在 infer |
| DeepSeekMoE(V2 起) | — | 45 | 55 | DeepSeek | 2024-05 | 稀疏 FFN;路由在训推两阶段共用 |
| V3 aux-loss-free + 256/8 MoE | — | 50 | 50 | DeepSeek | 2024-12 | 去 aux loss、sigmoid 路由、专家池扩容 |
| V3 MTP | — | 70 | 30 | DeepSeek | 2024-12 | 辅助训练目标;推理可接原生投机 |
| V3 FP8 动态量化 | — | 100 | — | DeepSeek | 2024-12 | 预训练数值与吞吐;非 Transformer 拓扑 |
| R1 RLVR / GRPO | 100 | — | — | DeepSeek | 2025-01 | 与 V3 同架构;差异全在后训练 |
| V3.1 Hybrid / Agent | 80 | — | 20 | DeepSeek | 2025-中 | post-train 能力;同一权重切换 thinking/chat |
| V3.1-T MLA Prefill MHA / Decode MQA | — | — | 100 | DeepSeek | 2025 | 同权重;仅推理路径 MHA↔MQA 间切换 |
| V3.2 DSA | — | 35 | 65 | DeepSeek | 2025-12 | Lightning Indexer + 异构 cache;长上下文 infer 主战场(Exp 2025-09) |
| Index Share | — | — | 100 | 清华 + 智谱 | 2026-03 | 跨层复用 top-$k$ index |
| ESS Latent offload | — | — | 100 | 百度百舸 | 2025-12 | 仅 Latent-Cache CPU 分层;与 DSA 算法正交 |
| V4 CSA / HCA | — | 30 | 70 | DeepSeek | 2026 | 压缩 KV 序列;1M context 算力与 cache 主因 |
| V4 mHC | — | 55 | 45 | DeepSeek | 2025-12 | 残差双随机流形;训推均改前向图(V4 落地 2026) |
| V4 Muon | — | 100 | — | DeepSeek | 2026 | 优化器替换,加速收敛 |
| V4 Hash MoE + FP4 | — | 55 | 45 | DeepSeek | 2026 | Hash 路由与 FP4 权重量化 |
| DSpark | — | — | 100 | DeepSeek | 2026-06 | V4 线上投机解码;基线 MTP-1;不改基座 |
| V4 HiSparse / 异构 KV offload | — | — | 100 | DeepSeek(layout)+ Together 等 | 2026-05 | C4 inactive entry、磁盘 prefix;纯 infer 内存层级 |
| FlashMLA / DeepGEMM indexer | — | — | 100 | DeepSeek | 2025 | Kernel 实现;承载 MLA / DSA 算子(§6) |
| Visual Primitives MLLM | 60 | 25 | 15 | DeepSeek-AI | 2026 | V4-Flash + ViT;visual primitives CoT;CSA 压视觉 KV(§3.8) |
版本级粗汇总:
| 版本 | 模型 % | 架构-train % | 架构-infer % | 发表时间 | 相对上一版主叙事 |
|---|---|---|---|---|---|
| V1 | 100 | — | — | 2024-01 | 系列首篇;scaling + 双语 |
| V2 | 10 | 45 | 45 | 2024-05 | 首次 MLA + MoE |
| V3 | 15 | 55 | 30 | 2024-12 | MoE 路由 + MTP + 671B 规模 |
| R1 | 100 | — | — | 2025-01 | 纯后训练 |
| V3.1 / Terminus | 75 | — | 25 | 2025-中 | Hybrid + MLA 模式切换 |
| V3.2 | — | 35 | 65 | 2025-12 | 唯一架构改动 = DSA |
| V4(基座) | — | 40 | 60 | 2026 | CSA/HCA/mHC/MoE/Muon 打包 |
| V4 + DSpark(线上) | — | — | 100† | 2026-06 | † 相对已训好的 V4 checkpoint 的 decode 补丁 |
读法:Index Share、ESS、DSpark 等 100% 架构-infer 的工作,与「改权重」的 V3.2 DSA、V4 CSA 可叠加部署;§5 KV-offload 三代与 §6 推理栈是 infer 轴的进一步展开。
1.2 Transformer 四模块演进
Raschka 第三方解读 §8 · 表 8-1 将 Transformer 拆成四条正交演进链;下表映射到本仓库版本节点(非 exhaustive,仅 DeepSeek 主线):
| 模块 | 行业演进链 | DeepSeek 落点 |
|---|---|---|
| Normalization | LayerNorm → RMSNorm → Dynamic TanH | V1–V4:RMSNorm(Pre-Norm) |
| Attention | GQA → sliding window(SWA) → MLA → sparse (DSA) → CSA/HCA | MLA → DSA → CSA/HCA · V4 另含 SWA 局部精确 KV |
| FFN | GeLU → SwiGLU → MoE | DeepSeekMoE → aux-loss-free → Hash MoE + FP4 |
| 残差 | 恒等(ResNet) → Hyper-Connections → mHC | HC → mHC(V4 落地) |
读法:V3.2 的「唯一结构改动」几乎全在 Attention 轴(DSA);V4 同时在 Attention(CSA/HCA)、残差(mHC)、FFN(Hash MoE)三轴打包升级;后训练(R1 RLVR)与 infer 补丁(Index Share / ESS / DSpark)不改变模块拓扑,见 §1.1。
延伸:Raschka 全文 §8 · mHC 专文 §1

{kind=link}
2. 版本时间线与关系

{kind=link}
图 2 补充:V1 · V2 · MLA · DeepSeekMoE · aux-loss-free · RLVR · DSA · Index Share · ESS · V4 · DSpark · mHC · 优化方向分类 §1.1 各节代表图:§3.1 scaling/BBPE · §3.2 MLA · §3.3 MoE vs V2 / MTP / FP8 · §3.4 GRPO · §3.5 MLA 模式切换 · §3.6 DSA · §3.7 V4 异构 KV + DSpark · §3.8 Visual Primitives · §4 Index Share · §5.1–5.3 KV offload 三代
| 版本 | 发布时间 | 参数量 | 激活参数 | 上下文 | 机构 | arXiv | 相对上一版的核心变化 |
|---|---|---|---|---|---|---|---|
| DeepSeek-LLM V1 | 2024-01 | 7B / 67B | 同左(稠密) | 4K | DeepSeek | 2401.02954 | 系列首篇;LLaMA 系 + GQA(67B);2T 双语;scaling laws |
| DeepSeek-V2 | 2024-05 | 236B | 21B | 128K | DeepSeek | 2405.04434 | 首次 MLA + DeepSeekMoE;8.1T |
| DeepSeek-V3 | 2024-12 | 671B | 37B | 128K | DeepSeek | 2412.19437 | MLA 旗舰化 + 256/8 MoE + MTP + aux-loss-free;14.8T |
| DeepSeek-R1 | 2025-01 | 同 V3 | 同 V3 | 128K | DeepSeek | 2501.12948 | V3-Base 上 RLVR + GRPO,架构不变 |
| DeepSeek-V3.1 | 2025 中 | 同 V3 | 同 V3 | 128K | DeepSeek | — | Hybrid 推理:同一权重切换 thinking / non-thinking |
| V3.1-Terminus | 2025 | 同 V3.1 | 同 V3.1 | 128K | DeepSeek | — | V3.1 收尾 checkpoint,作为 V3.2 续训起点 |
| DeepSeek-V3.2-Exp | 2025-09 | 同 V3.1-T | 同 V3.1-T | 128K | DeepSeek | Exp PDF · 2512.02556 | DeepSeek 官方实验版;引入 DSA(DeepSeek 原创稀疏注意力) |
| DeepSeek-V3.2 | 2025-12 | 同 V3.1-T | 同 V3.1-T | 128K | DeepSeek | 2512.02556 | DeepSeek 官方正式版;DSA 定型;唯一架构改动即为稀疏注意力 |
| ESS | 2025-12 | — | — | — | 百度百舸 | 2512.10576 | 纯推理补丁:Latent-Cache CPU offload;与 DSA 正交 |
| DeepSeek-V4-Pro | 2026 | 1.6T | 49B | 1M | DeepSeek | 2606.19348 | CSA + HCA + mHC + Muon;MoE FP4 |
| DeepSeek-V4-Flash | 2026 | 284B | 13B | 1M | DeepSeek | 同 2606.19348 | 更小激活量,效率优先 |
| Index Share | 2026-03 | — | — | — | 清华 + 智谱 | 2603.12201 | 纯推理补丁 |
| DSpark | 2026-06 | — | — | — | DeepSeek + 北大 | DeepSpec | V4 Flash/Pro 预览引擎;相对 MTP-1 基线;半自回归 draft + 置信度验证;纯推理 |
arXiv 说明:V3.1 / Terminus 为 post-train 与 checkpoint,无独立论文;V3.2-Exp 先发 GitHub 技术报告,DSA 完整叙述并入 V3.2 论文 2512.02556。DSpark 无独立 arXiv,技术报告见 DeepSpec / DSpark_paper.pdf;与 V4 同期开源,叠加在 V4 checkpoint 之上(§3.7 / §6)。
3. 各版本详解
各版本一页纸梗概见 版本梗概索引。以下为展开说明(按时间线从 V1 起)。更细的 V1→V3 脉络另见 V1→V3 演进。
3.1 DeepSeek-LLM V1
V1 正文:DeepSeek-LLM V1(2401.02954 完整中文译文)
论文:DeepSeek-LLM arXiv:2401.02954
架构要点
- 稠密 LLaMA 系:Pre-Norm + RMSNorm + SwiGLU + RoPE;7B(30 层 MHA)与 67B(95 层加深 + 8 头 GQA)。
- 上下文 4K;词表 BBPE 102,400。
- 预训练 2.0T 中英双语;数据管线:跨 dump 去重 → 过滤 → domain 重混。
- 对齐:~150 万 instruction,SFT + DPO。
研究贡献
- 系统 scaling laws($C=M\cdot D$);IsoFLOP 下数据质量越高越应扩模型而非堆数据。
答疑:为何用 $C=M\cdot D$ 而非 Chinchilla 的 $C=6ND$? — $M$=non-embedding FLOPs/token、Table 3 误差、与 IsoFLOP 的关系
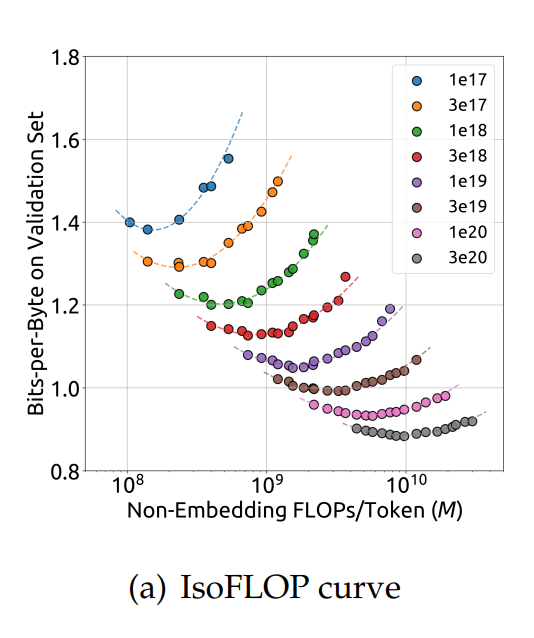
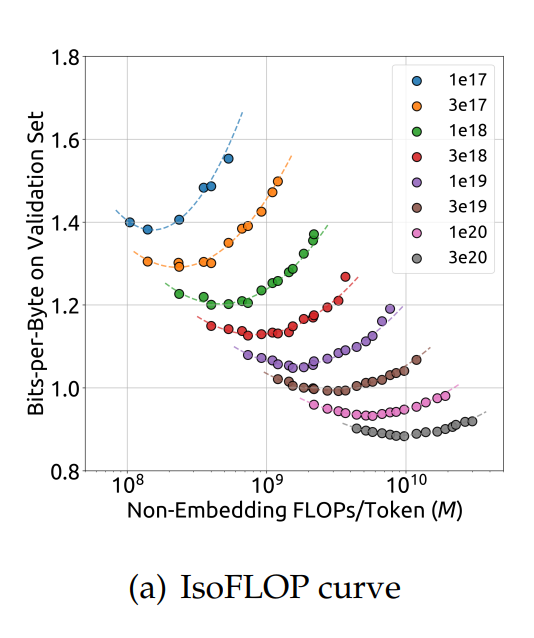
Figure 4a — IsoFLOP 曲线(各算力档 loss 随 $M$ 呈 U 形,谷底 = 最优分配)
{kind=link}
来源:V1 论文 Figure 4a(详见 V1 §3.2 最优 model/data Scaling)。横轴 = non-embedding FLOPs/token $M$;纵轴 = validation bits-per-byte;每条 U 形曲线对应固定总算力 $C$,谷底即该预算下最优 model/data 分配。
词表 BBPE:

{kind=link}
推理 infra 特征
- 标准 GQA/MHA KV cache(与后续 MLA 不兼容);无 MoE、无 latent 压缩;可按常规 Transformer 部署。
3.2 DeepSeek-V2
梗概:DeepSeek-V2 · MLA 详解
论文:DeepSeek-V2 arXiv:2405.04434 仓库:deepseek-ai/DeepSeek-V2
相对 V1 的架构跃迁
| 维度 | V1(67B 稠密) | V2 |
|---|---|---|
| FFN | 稠密 SwiGLU | DeepSeekMoE(160 routed + 2 shared / token 激活 6) |
| 注意力 | GQA | 首次 MLA latent KV |
| 规模 | 67B 全激活 | 236B / 21B activated |
| 上下文 | 4K | 128K |
| 预训练 | 2T | 8.1T |
要点
- MLA 将 K/V 压入 latent cache;论文称相对 67B 稠密 KV 体积约 -93.3%、生成吞吐 5.76×。
- MoE 路由为 softmax 系(V3 起改为 aux-loss-free sigmoid 路由)。
- MLA 结构被 V3 / R1 / V3.1 / V3.2 沿用;V2 是系列中 MLA+MoE 的首次引入。

{kind=link}
为什么 1536 能变成 [128,128] 和 [128,64]? ——不是切分,是两个独立上投影矩阵放大后按头 reshape:
- $q_t^C = W^{UQ} c_t^Q$: $[16384 \times 1536] \cdot [1536] \to [16384]$, 其中 $16384 = n_h \times d_h = 128 \times 128$ → reshape $[128, 128]$
- $q_t^R = \mathrm{RoPE}(W^{QR} c_t^Q)$: $[8192 \times 1536] \cdot [1536] \to [8192]$, 其中 $8192 = n_h \times d_h^R = 128 \times 64$ → reshape $[128, 64]$
$[128,128]$ 里两个 128 含义不同:前一个是头数 $n_h$(共 128 个头),后一个是每头维度 $d_h$(每头 128 维),本配置恰好都等于 128。二者都是架构超参,不是从 1536 算出来的;1536 只决定矩阵的列数。(KV 侧同理:$c_t^{KV} = 512$ 经 $W^{UK}, W^{UV}$ 投影成 $[128,128]$。)
右边 $k_t^R = [64]$ 的 64 怎么来? ——$64 = d_h^R$(每头 RoPE 维度,架构超参);$W^{KR}: [64 \times 5120] \cdot h_t \to [64]$,再加上 RoPE。 关键: $k_t^R$ 没有头维度——所有 $n_h = 128$ 个头共享同一个 $[64]$(解耦 RoPE);而左边 $q_t^R$ 是每头各一份 $[128, 64]$。 正因为 K 的 RoPE 部分全局只存一份 $[64]$(不按头复制),KV 缓存才这么小——这是 MLA 省显存的另一半原因。
MLA 到底压缩了谁?如果不做压缩会变多大? ——下面三项就是 MLA 压缩/解耦的对象(格式:MLA 压缩后 $\Rightarrow$ 不压缩):
- $c_t^Q$ 查询潜向量: $1536 \Rightarrow 16384\ (= n_h d_h)$, 约 11×; 不进缓存,省的是参数与计算量。
- $c_t^{KV}$ KV 联合潜向量: $512 \Rightarrow 16384\ (= n_h d_h)$, 32×; ★进缓存 —— 这是省显存的核心。
- $k_t^R$ 共享 RoPE 键: $64 \Rightarrow 8192\ (= n_h d_h^R)$, 128×; ★进缓存,靠全头共享(不按头复制),而非低秩压缩。
缓存总量: 标准 MHA $= 2n_h d_h = 32768$ → MLA 若不压缩 $= 16384 + 64 = 16448$(仅 MHA 一半) → 实际 MLA $= 512 + 64 = 576 \approx$ MHA 的 1/57
来源:V2 论文 Eq. 37–47;cache 仅存 $c_t^{KV}$(512)+ 共享 $k_t^R$(64)。
推理 infra 特征
- KV cache 变为 MLA latent 格式;需引擎侧自定义 kernel / 适配(后续 FlashMLA 等)。
3.3 DeepSeek-V3
梗概:DeepSeek-V3 · 相对 V2 纯模型结构优化:§对比 V2
论文:DeepSeek-V3 Technical Report 仓库:deepseek-ai/DeepSeek-V3
相对 V2 的架构升级
| 维度 | V2 | V3 |
|---|---|---|
| 规模 | 236B / 21B 激活(~8.9%) | 671B / 37B 激活(~5.5%) |
| MoE | 160 routed,top-6,2 shared;softmax + aux loss | 256 routed,top-8,1 shared;aux-loss-free(sigmoid + bias $b_i$) |
| 注意力 | 首次 MLA | 同族 MLA(latent KV 方程不变;671B / 128K 配比升级) |
| 预测头 | 单步 next-token | + MTP 辅助头(多步并行预测) |
| 预训练 | 8.1T | 14.8T |
要点(三条结构线)
-
MoE 路由革新:去掉 aux loss 主路径;router 内 可学习 bias 做负载均衡,sigmoid affinity 选 expert、门控与选择解耦;专家池扩至 256/8,激活占比更低。
-
MTP(全新):输出层 Multi-Token Prediction 辅助目标;推理可原生投机解码 → 投机解码与 DSpark 专文 §2
-
MLA 继承:K/V 仍压入 latent cache($c_t^{KV}$ 512 + 共享 $k_t^R$ 64);V3 价值在旗舰规模与 128K 巩固,非新 attention 算子(Hybrid / DSA 在 V3.1 / V3.2)。

图示详情 · MoE 详解 · aux-loss-free · MLA 前向流程图
{kind=link}
- 训练:14.8T tokens;后训练含 SFT + RL(R1 为同架构 + RLVR)。
训练 infra(非模型结构):FP8 动态量化 — 块级 scale + 每 $N_c{=}128$ MMA 提升 FP32 累加;与 DualPipe / DeepEP 并列,支撑 671B 预训练吞吐与数值稳定。
推理 infra 特征
- KV cache 为 MLA latent 格式,与标准 GQA/MHA 不兼容。
- vLLM 等引擎需
--trust-remote-code、--block-size 1(MLA 专用)。 - 长上下文下主要瓶颈是 Latent-Cache 线性增长 占满 HBM,限制 batch size。
3.4 DeepSeek-R1
梗概:DeepSeek-R1 · RLVR 详解
论文:DeepSeek-R1 arXiv:2501.12948 训练管线:DeepSeek-R1 训练 Pipeline
要点
- 架构与 V3 完全相同;差异仅在 后训练。
- RLVR(Reinforcement Learning with Verifiable Rewards):数学/代码等用 规则验证器 给奖励,配合 GRPO(无 critic),不用神经 reward model 做主信号。
- R1-Zero:V3-Base 上纯 RL,推理能力自发涌现;可读性弱。
- R1:冷启动 SFT → RL → 拒绝采样 SFT → 二阶段 RL(推理 + 通用 RM),补齐 helpful / safe。

{kind=link}
推理 infra:与 V3 相同(MLA latent KV、引擎配置一致)。
3.5 DeepSeek-V3.1 / V3.1-Terminus
变化:在 V3 权重基础上做 post-training,无架构变更。
| 维度 | V3 | V3.1 |
|---|---|---|
| 推理模式 | Base / R1 分离 | Hybrid:同一模型切换 thinking / chat |
| 上下文 | 128K | 128K(续训扩展) |
| Agent / Tool Use | 较弱 | 明显加强(BrowseComp、SWE 等) |
V3.1-Terminus 是 V3.1 系列的最终 checkpoint,上下文已扩至 128K,作为 V3.2 继续预训练 的起点。
MLA 模式切换:

{kind=link}
- Prefill:MHA 模式(多 query head 独立 latent)
- Decode:MQA 模式(latent 在 query head 间共享)
这为后续 DSA 在 MQA 模式下做稀疏选择打下基础。
3.6 DeepSeek-V3.2 / V3.2-Exp
梗概:DeepSeek-V3.2 · V3.2-Exp
论文:DeepSeek-V3.2 · V3.2-Exp 仓库:deepseek-ai/DeepSeek-V3.2
相对 V3.1-Terminus 的唯一架构改动:DeepSeek Sparse Attention (DSA)

{kind=link}
DSA 两阶段(三阶段表):
- Lightning Indexer:对每个 query,用廉价点积为所有历史 token 打分(复杂度仍 $O(L^2)$,但 head 维极低)。
- Top-$k$ Selector:选出 $k=2048$ 个最重要 token 的 latent entry。
- Core Attention(Core MLA):仅对这 $k$ 个 latent 做 MLA attention(复杂度 $O(Lk)$)。
概念:Lightning Indexer · Top-$k$ Selector · Core MLA · Indexer-Cache · Latent-Cache · ESS
因此 V3.2 的 cache 分裂为两类(异构 KV · DSA逻辑详解 §4):
| Cache 类型 | 作用 | 占总量比例(ESS 论文) | 是否 offload |
|---|---|---|---|
| Indexer-Cache | 计算重要性、选 top-$k$ | ~16.8% | 否(每步全算) |
| Latent-Cache | MLA 核心 attention 的 KV | ~83.2% | 可 offload(ESS) |
V3.2-Exp 与 V3.2 架构相同;Exp 用于验证 DSA 不损精度,V3.2 为正式训练 + 后训练成品。
推理内核:DeepGEMM(indexer logits)、FlashMLA(sparse attention paged kernel)→ 推理 infra
3.7 DeepSeek-V4
论文:DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence 模型:V4-Pro(1.6T / 49B act)、V4-Flash(284B / 13B act)
相对 V3.2 的算法大步进
| 组件 | 说明 |
|---|---|
| CSA (Compressed Sparse Attention) | 每 $m=4$ token 压缩为 1 条 KV entry,再对压缩序列做 DSA(top-$k$ 压缩 entry)→ 专文 §2 |
| HCA (Heavily Compressed Attention) | 每 $m'=128$ token 压缩为 1 条,序列极短,直接 dense attention → 专文 §3 |
| mHC | Manifold-Constrained Hyper-Connections(§3 双随机流形):Sinkhorn–Knopp 凸组合 |
| Muon | 优化器替换,加速收敛 → 专文 §1 |
| Hash MoE | 前几层 dense FFN → Hash-routed MoE → 专文 §1 |
| FP4 MoE | routed expert 权重 FP4 + QAT → 专文 §2 |

图示详情 · V4 梗概 · CSA/HCA 详解 · Hash MoE + FP4 · Muon 详解 · mHC 详解
{kind=link}
1M context 效率
| 模型 | 单 token FLOPs | 累计 KV cache |
|---|---|---|
| V4-Pro @ 1M | 27% | 10% |
| V4-Flash @ 1M | 10% | 7% |
Agentic Coding 场景:V4 面向 100K–1M token 的 agent 工作流(代码库、多轮 tool trace),算法侧用 CSA/HCA 压 cache,infra 侧用异构 KV 管理 + offload 才能「真的跑得动」。
推理加速:V4 预览引擎已部署 投机解码与 DSpark(相对 MTP-1 基线;同等吞吐下单用户 +57%–85%)。细节、图示、自测与 MTP 机制 均在专文,此处不重复。
专文:投机解码与 DSpark · DeepSpec
Ablation 困境:V4 同时改了注意力、残差、优化器、MoE 路由、量化精度,很难像 V3.2 那样做单一变量对照——这也是社区更青睐 Index Share 这类「纯 infra、零重训」补丁的原因之一。
3.8 Thinking with Visual Primitives
要点专文:Visual Primitives 论文要点 · PDF:Visual Primitives 原文 PDF
定位:V4-Flash 之上的 MLLM 支线——把 点 / 框 作为 CoT 的 visual primitives,解决语言难以精确 空间引用 的 Reference Gap。
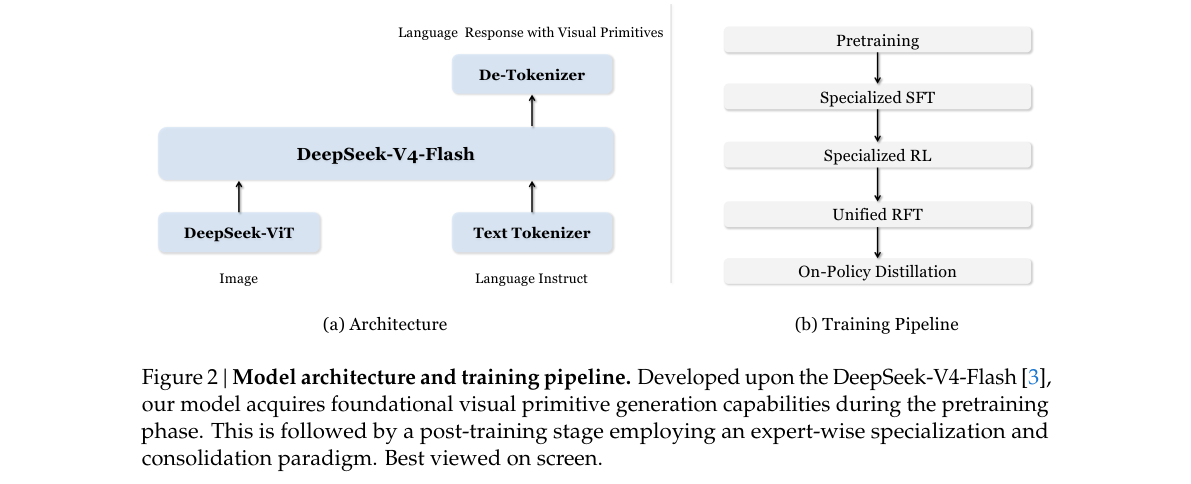
双模块架构:
| 模块 | 角色 |
|---|---|
| DeepSeek-ViT | 任意分辨率图像 → patch token → 3×3 通道压缩 |
| V4-Flash LLM | 视觉 + 文本交错序列;CSA 将视觉 KV 再压 4× |
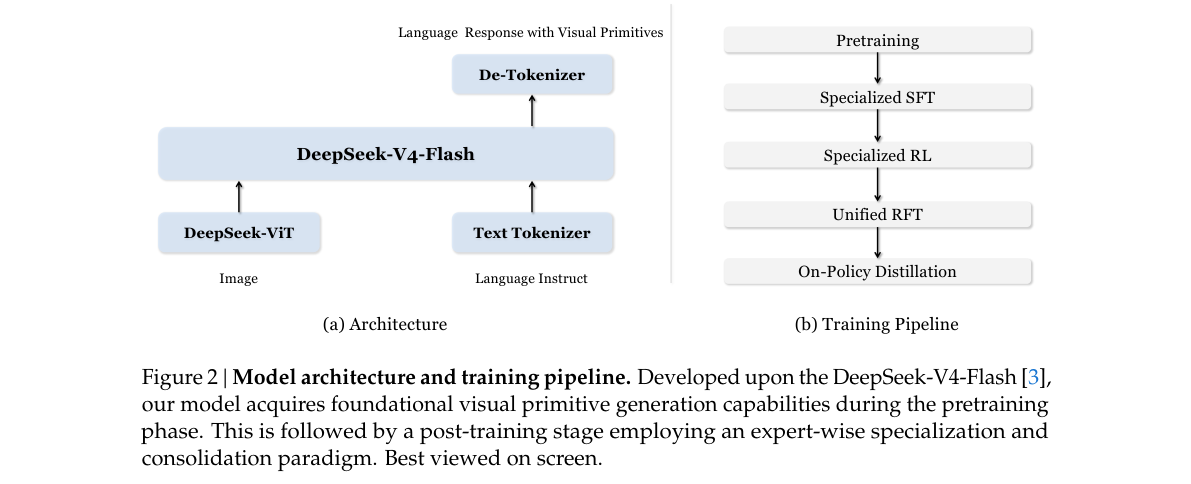
Figure 2 | Model architecture and training pipeline(论文原图)。756×756 示例:2,916 patch → 324 LLM token → 81 KV entries,总压缩 7,056×。
{kind=link}
效率与精度:
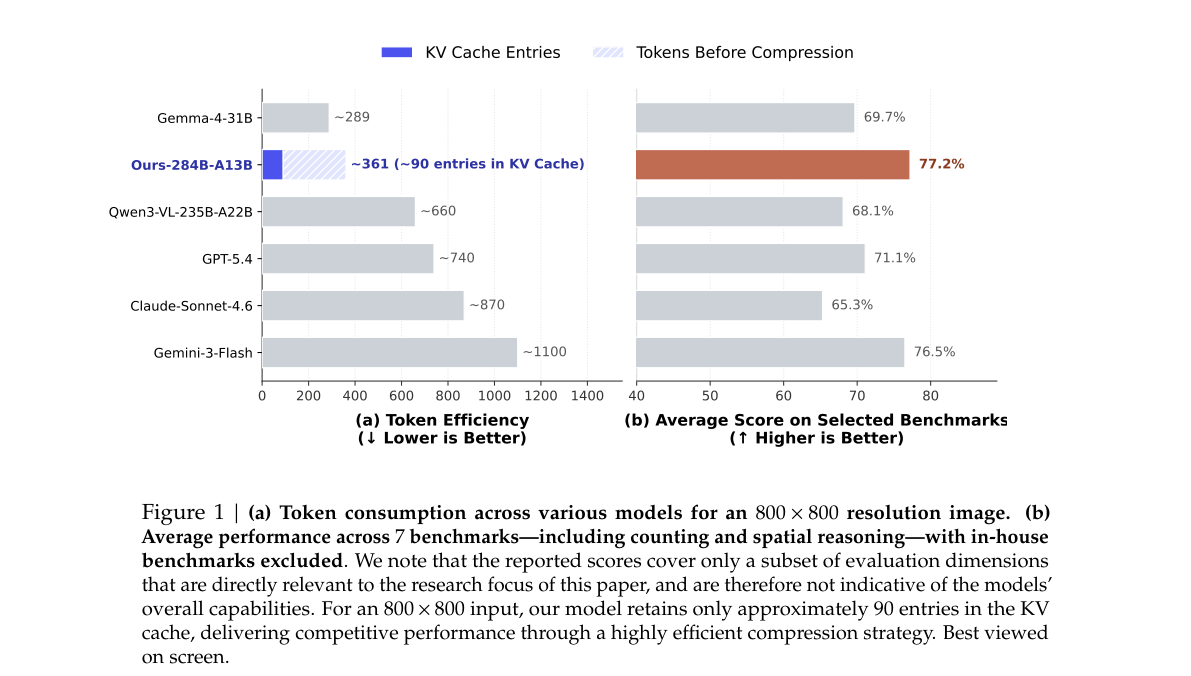
| 指标 | 数值 / 对比 |
|---|---|
| 800×800 视觉 KV | 约 90 entries(全文 ~361 tokens)vs Gemini-3-Flash ~1100 tokens |
| 7 项 benchmark 均分 | 77.2%(子集评测,非全能榜) |
| 拓扑推理 | DS_Maze 66.9、DS_Path_Tracing 56.7,显著高于 Qwen3-VL-235B |
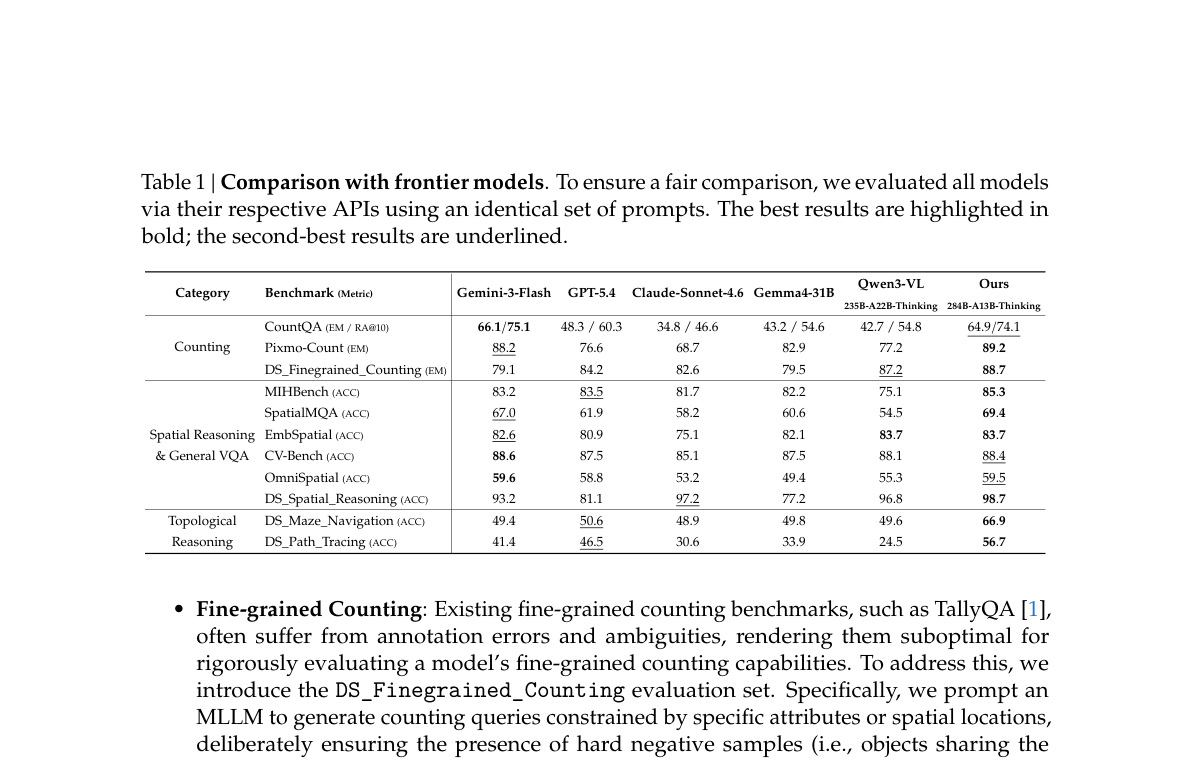
Table 1 | Comparison with frontier models(bold=最佳)。
直接打开 Figure 1 · Table 1 · 要点专文 §4–§5
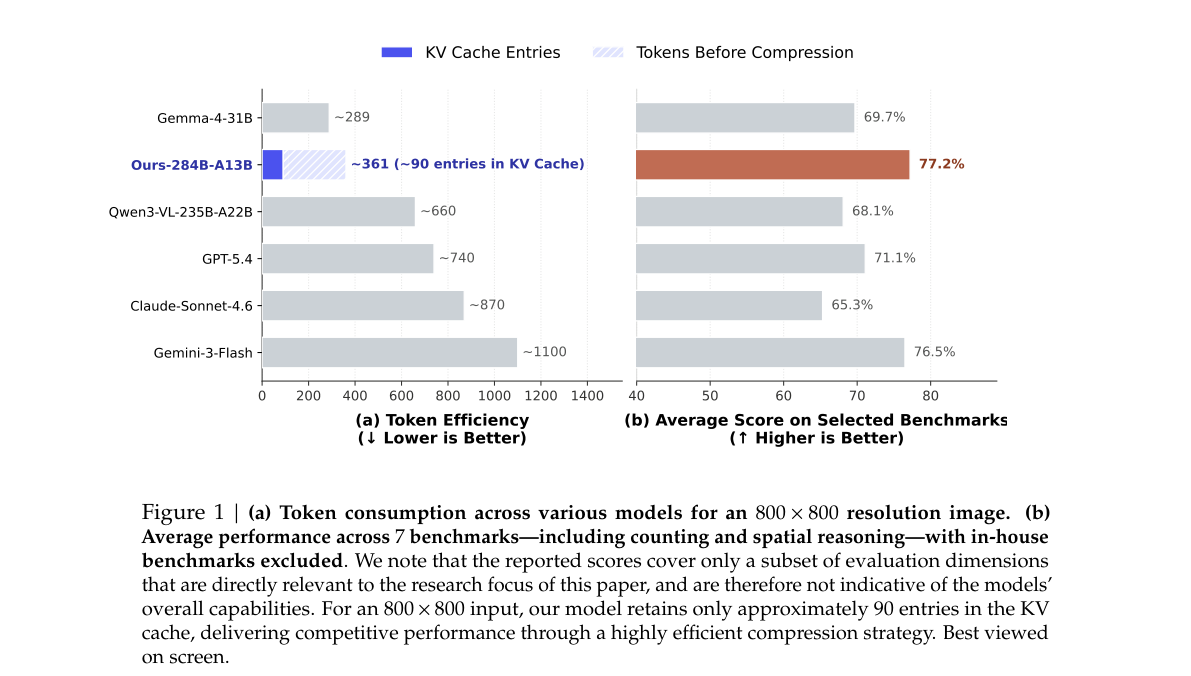{kind=link}
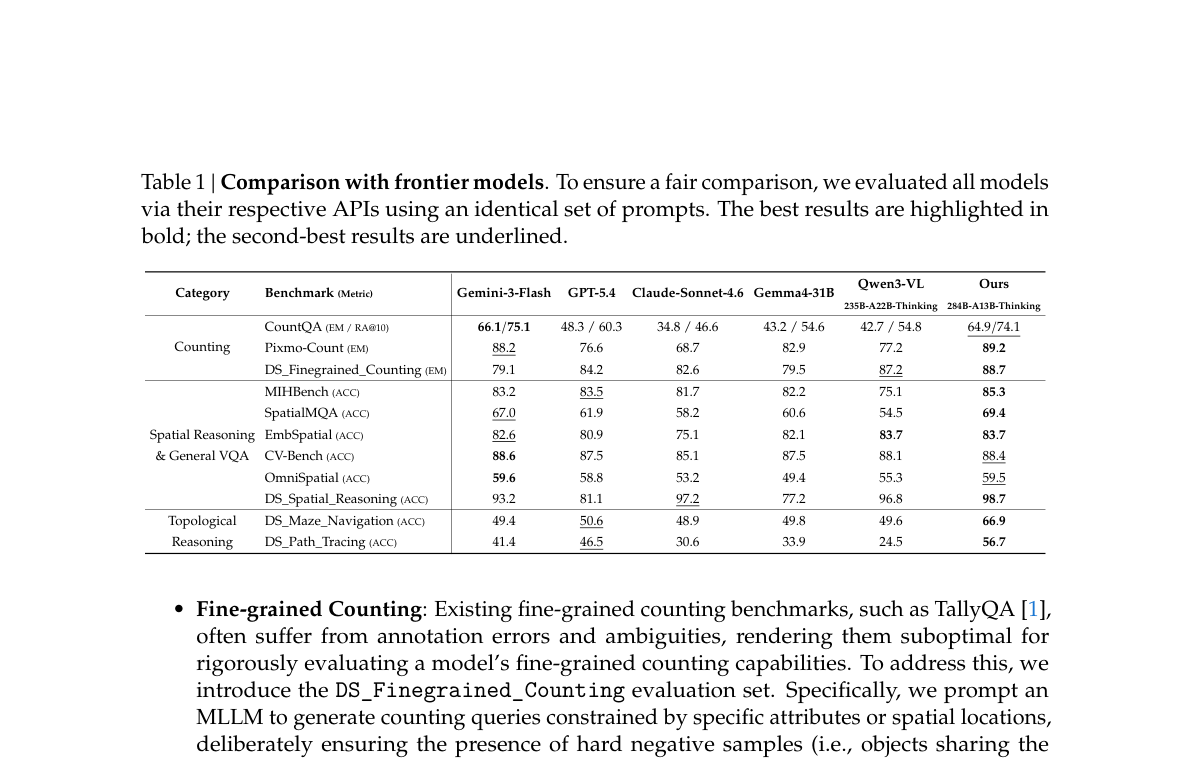{kind=link}
与 §3.7 V4 的关系:共享 CSA 压缩 attention 与 MoE 推理栈;增量在 ViT 编码器 + visual primitives 后训练管线,属于 模型轴(数据/对齐)+ 架构-train(ViT 模块) 的扩展,而非新的文本稀疏注意力变体。
4. Index Share
梗概:Index Share 逻辑详解:Index Share逻辑详解
社区昵称 Index Share / 「V3.3」;正式名 IndexCache。 论文:arXiv:2603.12201(清华大学 + 智谱 AI / Z.ai)· 代码:THUDM/IndexCache
4.0 技术归属
| 角色 | 机构 | 说明 |
|---|---|---|
| 被优化对象 | DeepSeek | 自研 DSA + Lightning Indexer;每层独立 top-$k$,长上下文下 indexer 成为瓶颈 |
| 优化算法 | 清华 + 智谱(Z.ai) | IndexCache / index-share:F 层缓存索引、S 层复用,非 DeepSeek 官方产物 |
| 工程落地 | 百度百舸 等 | 训推引擎集成 IndexCache、分布式与异构芯片适配;ESS 为百舸自研的 Latent-Cache offload,与 IndexCache 正交 |
4.1 解决什么问题
DSA 的 indexer 每层独立运行,复杂度 $O(L^2)$,长上下文 prefill 时 indexer 成为显著开销。观察:相邻层的 top-$k$ index 高度相似。
4.2 机制
将 Transformer 层分为两类:
- Full (F) 层:保留 indexer,正常计算 top-$k$
- Shared (S) 层:不跑 indexer,直接复用最近一个 F 层的 cached indices
典型模式:每 4 层保留 1 个 F 层(FFFS 重复),去掉 75% indexer 计算。

{kind=link}
两种部署:
| 模式 | 做法 |
|---|---|
| Training-free | 在校准集上贪心搜索哪些层保留 indexer,最小化 LM loss |
| Training-aware | 多层蒸馏,让保留的 indexer 拟合其覆盖层的平均 attention 分布 |
4.3 为何被称为「最好的 infra 补丁」
| 属性 | Index Share | V4 级架构改动 |
|---|---|---|
| 权重变更 | 无 | 全量重训 |
| 额外显存 | 零 | 新 cache layout |
| 实现 | SGLang / vLLM 一个 if/else 分支 | 异构 KV + 新 kernel |
| 加速 | 200K:TTFT 1.82×,decode 1.48× | 1M:FLOPs/KV 降至 10% 级 |
| 适用模型 | DSA 系(V3.2、GLM-5) | V4 自带 CSA indexer |
结论:Index Share 典型体现「infra 归 infra,算法归算法」——在 DSA 算法不变的前提下,用跨层冗余做系统优化。
5. KV-offload 演进
KV-offload 指将部分 cache 卸载到 CPU DRAM(或磁盘),按需 prefetch 回 GPU。DeepSeek 各代的 cache 形态不同,offload 策略也完全不同。
5.1 V3 / V3.1:标准 MLA Latent-Cache
- Cache 内容:单一 MLA latent 向量序列。
- Offload:可用通用 KV offload(FlexGen、vLLM CPU offload 等),但 MLA 自定义格式导致很多引擎 不支持标准 offload。
- 瓶颈:线性增长的 latent 占满 HBM → decode batch size 受限。

图示详情 · MLA 前向专文 · MLA §KV Cache
{kind=link}
5.2 V3.2:Indexer-Cache + Latent-Cache 分离 → ESS
归属澄清:DeepSeek-V3.2-Exp / V3.2 与 DSA 均为 DeepSeek 官方发布。下文 ESS 论文标题虽含「DeepSeek-V3.2-Exp」,但 ESS 算法来自百度百舸,是针对 DeepSeek DSA 模型的 Latent-Cache offload 方案,不是 DSA 本身,也不是 V3.2-Exp 的发布方。
论文:ESS: An Offload-Centric Latent-Cache Management Architecture for DeepSeek-V3.2-Exp

{kind=link}
| 策略 | 说明 |
|---|---|
| Indexer-Cache 常驻 GPU | 占 16.8%,每步必须全算,offload 无意义 |
| Latent-Cache offload 到 CPU | 占 83.2%,利用 top-$k$ 的 时间局部性(相邻 decode step 的 $K_t^l$ 重叠率高) |
| FlashTrans + UVA | 解决 656B 小块 PCIe 传输带宽极低(原 ~0.8 GB/s H2D)→ 提升至 ~37 GB/s |
| GPU 侧 Sparse Memory Pool | LRU 维护 GPU 热 latent 子集,miss 时从 CPU prefetch |
| Layer-wise overlap | 计算与传输流水线掩盖延迟 |
收益:32K context 吞吐 +69.4%;128K 最高 +123%。
与 V3 的本质区别:offload 单位从「整条 MLA latent 序列」变为「稀疏选中的 Latent-Cache entry」,且需与 indexer 的 top-$k$ 选择协同。
5.3 V4:异构 KV + HiSparse + 磁盘 Prefix Cache
V4 的 cache 不再是单一 MLA latent,而是多类型并存:
| KV 类型 | 来源 | 特点 |
|---|---|---|
| CSA 压缩 entry | 每 4 token → 1 | 序列长 $\frac{L}{4}$,稀疏 top-$k$ |
| HCA 压缩 entry | 每 128 token → 1 | 序列极短,dense attend |
| SWA (Sliding Window) | 最近 $n_{\text{win}}$ token | 独立 eviction 策略 |
| Indexer KV | CSA 的 lightning indexer | 与主 attention 维度不同 |
| Tail buffer | 不足 $m$ 个 token 的未压缩尾 | 等待凑满再压缩 |
KV layout→ 专文:V4 KV Layout
- Classical KV cache:按 $\mathrm{lcm}(m, m')$ 对齐的压缩块,服务 CSA/HCA
- State cache:每请求固定大小块,存 SWA + 未就绪压缩尾
HiSparse→ 专文:V4 HiSparse
- 将 inactive 的 C4(CSA 4:1 压缩层)cache entry offload 到 CPU pinned memory
- GPU 只保留 active「热」工作集
- 单节点 B200 上 KV 容量从 ~1.2M tokens 提升到 ~3.7M tokens(约 3×)
磁盘 Prefix Cache→ 专文:V4 磁盘 Prefix Cache
- CSA/HCA 压缩 entry 可直接落盘,共享 prefix 免重复 prefill
- SWA 体积约为压缩 entry 的 8×,提供 Full / Periodic Checkpointing / Zero 三档策略
5.4 三代 offload 对比
| 维度 | V3 / V3.1 | V3.2 (ESS) | V4 (HiSparse) |
|---|---|---|---|
| Cache 结构 | 同质 MLA latent | Indexer + Latent 异构 | CSA + HCA + SWA + Indexer + tail |
| Offload 对象 | 全量 latent(若引擎支持) | 仅 Latent-Cache | Inactive C4 压缩 entry + 磁盘 prefix |
| 局部性依据 | 顺序滑动窗口 | top-$k$ index 时间相似度 | 稀疏激活 + SWA 复用策略 |
| 传输优化 | 通用 PCIe | FlashTrans / UVA | 分层内存池 + PD 分离 |
| 与算法耦合 | 低 | 中(依赖 DSA top-$k$) | 高(依赖压缩比 $m, m'$) |
知乎社区观点(2026-06):V4 的 KV-offload 策略与 DSV3.2 完全不同——不是简单扩大 ESS,而是围绕异构压缩 cache 重新设计内存层级;V3.2 上可叠加 Index Share + ESS,V4 则需要 HiSparse + 定制 layout。
6. 推理技术栈对照
| 技术 | 适用版本 | 类型 | 链接 |
|---|---|---|---|
| FlashMLA | V3+ | Kernel | deepseek-ai/FlashMLA |
| DeepGEMM indexer | V3.2+ | Kernel | DeepGEMM PR#200 |
| DSpark + DeepSpec | V4 Flash / Pro(线上) | 投机解码 / decode 吞吐 | DeepSpec · DSpark 专文 |
| IndexCache (Index Share) | V3.2, GLM-5 | Infra 补丁 | THUDM/IndexCache |
| ESS(百度百舸) | DeepSeek-V3.2 / V3.2-Exp | Latent-Cache offload | arXiv:2512.10576 |
| SGLang / vLLM recipes | 全系列 | serving | 各模型 README |
7. 与本仓库其他专题的关系
优化方向:各专题在 §1.1 模型 / 架构-train / 架构-infer 分类 中的落点见该表「工作一览」。
| 专题 | 关系 |
|---|---|
| Engram | 另一条稀疏轴(条件记忆查表),与 MoE 正交;可 offload 到 Host/CXL |
| Engram 系列导读 | Engram / CXL Pooling / Tiny-Engram 深度笔记 |
| DSA 系列 · ESS 概念 · Index Share | V3.2 稀疏注意力 + 推理 infra 补丁(与 §3.6 / §5.2 对应) |
| DSpark / DeepSpec | V4 投机解码 线上加速;与 KV/offload 正交(§3.7 / §6) |
| Visual Primitives | V4-Flash 多模态:visual primitives CoT + ViT;CSA 压视觉 KV(§3.8) |
| DeepSeek-R1 训练管线 | R1 四阶段;RLVR 概念 |
8. 参考资料
- DeepSeek-AI. DeepSeek-V3 Technical Report. arXiv:2412.19437, 2024.
- DeepSeek-AI. DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models. arXiv:2512.02556, 2025.
- DeepSeek-AI. DeepSeek-V3.2-Exp: Boosting Long-Context Efficiency with DeepSeek Sparse Attention. 2025.
- Chen et al. ESS: An Offload-Centric Latent-Cache Management Architecture for DeepSeek-V3.2-Exp. arXiv:2512.10576, 2025.
- Bai et al. IndexCache: Accelerating Sparse Attention via Cross-Layer Index Reuse. arXiv:2603.12201, 2026.
- DeepSeek-AI. DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence. arXiv:2606.19348, 2026.
- Together.ai. Serving DeepSeek-V4: why million-token context is an inference systems problem. 2026.
DeepSeek 算法线:MLA → DSA → CSA/HCA + mHC
← 中文导读 · ← 仓库首页(EN) · 更新:2026-06-27 ← 演进总览 §1 · 基础设施线导读 · MoE 线导读 · 版本梗概索引 · 《ds-技术报告》读本
V3 发布之后,DeepSeek 在 注意力与残差路径 上的算法演进可概括为(与 演进总览 §1 正文内联一致):
MLA → DSA 稀疏注意力 → CSA/HCA 混合压缩注意力 + mHC
本文是这条 算法线 的专题导读与双向跳转 hub;全景时间线(含 infra 线)见 版本演进总览。
1. 演进链
| 阶段 | 核心机制 | 首发 / 定型版本 | 本地文档 | 论文 |
|---|---|---|---|---|
| ① MLA | K/V 压入低维 latent 再缓存;Core 仍做多头注意力 | V2(2024-05)→ V3/R1/V3.1 沿用 | MLA 低秩注意力 | 2405.04434 |
| ② DSA | Lightning Indexer 选 top-$k$ → 仅对 $k$ 个 latent 做 MLA | V3.2-Exp / V3.2(2025) | DSA 稀疏注意力 · DSA 逻辑详解 | 2512.02556 |
| ③ CSA / HCA | 4:1 / 128:1 压缩 KV + 内嵌 indexer;百万 token | V4(2026) | CSA / HCA · DeepSeek-V4 | 2606.19348 |
| ④ mHC | 残差 Hyper-Connections → 双随机流形约束 | V4 落地 | mHC(含 §3 双随机流形)· HC 基础 | 2512.24880 |
注意:mHC 改的是 残差路径(与 Attention / KV 正交),在演进总览里与 CSA/HCA 并列 标注,便于对照 V4 全架构;详见 mHC §7。
2. 阅读顺序
- MLA 低秩注意力 — latent KV 压缩基座
- V3.1 Hybrid — Prefill MHA / Decode MQA(DSA 前置)
- DSA 梗概 → 逻辑详解 → Lightning Indexer
- CSA/HCA 混合压缩注意力 — 4:1 稀疏 + 128:1 dense
- V4 梗概 — 两个规格、MoE、训练与 infra 总览
- Hyper-Connections(HC) — 多路残差流基础
- mHC 流形约束超连接 — V4 残差组件
外部解读:Raschka 要点速读 §3–4 MLA/DSA · §8 mHC
3. 节点间关系
| 边 | 关系 |
|---|---|
| MLA → DSA | MLA 结构不变;在 latent 序列上加 indexer + top-$k$ 稀疏选择 |
| DSA → CSA/HCA | DSA 的「先选再看」思想延续;V4 先做 token 块压缩 再在压缩序列上稀疏 / dense |
| CSA/HCA ⊥ mHC | 前者改 Attention / KV;后者改 残差拓扑,V4 同期引入 |
4. 与 infra 线的交叉
完整 基础设施线 见 基础设施线导读。
| 算法阶段 | 常见 infra 补丁 | 文档 |
|---|---|---|
| DSA | Indexer/Latent 异构 cache、Index Share、ESS | infra 线 §②–④ |
| V4 CSA/HCA | HiSparse、磁盘 prefix cache、异构 KV layout | infra 线 §⑤ · KV layout · HiSparse · 磁盘 prefix |
MoE 线:MoE 线导读。
5. 反向引用
| 节点文档 | 文首应含 |
|---|---|
| MLA 低秩注意力 | [← 算法线导读](05-算法线导读.md) |
| DSA 稀疏注意力 | 同上 + 上游 MLA、下游 V4 |
| CSA / HCA | 同上 + 上游 DSA、下游 infra |
| DeepSeek-V4 | 同上 + 链 CSA/HCA 专文 |
| mHC | 同上 + 说明残差路径角色 |
维护约定见 DeepSeek 版本演进线文档引用约定。
DeepSeek 基础设施线:MLA KV → 异构 Cache → Index Share → ESS → V4 HiSparse
← 中文导读 · ← 仓库首页(EN) · 更新:2026-06-27 ← 演进总览 §1 · 算法线导读 · MoE 线导读 · 版本梗概索引 · 《ds-技术报告》读本
V3 发布之后,DeepSeek 推理侧 KV cache 与 offload 的演进可概括为(与 演进总览 §1 正文内联一致):
标准 MLA KV cache → Indexer/Latent 异构 cache → Index Share → ESS offload → V4 异构 KV + HiSparse
本文是这条 基础设施线 的专题导读与双向跳转 hub;算法侧演进见 算法线导读,全景时间线见 版本演进总览。
1. 演进链
| 阶段 | 核心机制 | 适用版本 | 本地文档 | 论文 / 归属 |
|---|---|---|---|---|
| ① 同质 MLA KV | 单类 latent cache;整条序列同格式 | V2/V3/R1/V3.1 | MLA 低秩注意力 · 演进 §5.1 | MLA 2405.04434 |
| ② Indexer/Latent 异构 | DSA 把 cache 拆成 Indexer-Cache + Latent-Cache | V3.2 | DSA稀疏注意力§异构 KV · DSA 逻辑详解 | DSA 2512.02556 |
| ③ Index Share | 跨层复用 top-$k$ index;减 indexer 重复计算 | V3.2 / GLM-5(纯 infra) | Index Share 梗概 · Index Share 逻辑详解 | 2603.12201(清华 + 智谱) |
| ④ ESS offload | Latent-Cache → CPU;Indexer 常驻 GPU;稀疏 prefetch | V3.2 / GLM-5(纯 infra) | ESS Latent offload · ESS 论文梗概 | 2512.10576(百度百舸) |
| ⑤ V4 异构 KV + HiSparse | CSA/HCA/SWA/Indexer/tail 多类 cache;C4 offload + 磁盘 prefix | V4 | CSA/HCA 算法 · DeepSeek-V4 梗概§推理 infra · KV layout · HiSparse · 磁盘 prefix | 2606.19348 |
| ⑥ 投机解码 / DSpark | MTP 原生 + DSpark 线上;唯一专文 | V4 Flash/Pro 预览引擎 | 投机解码与 DSpark | DeepSpec |
③ 与 ④ 并列:二者都依赖 ② 异构 cache,分别优化 indexer 算力 与 Latent 显存;可 同开。 ⑥ 与 ①–⑤ 正交:DSpark 优化 decode 步吞吐,不改变 KV 布局。
2. 阅读顺序
- MLA 低秩注意力 — 理解 同质 latent KV 基线
- DSA 梗概 §异构 KV — Indexer/Latent 分裂
- Index Share 梗概 → 逻辑详解 — 跨层 index 复用
- ESS 概念 → 论文梗概 — Latent offload
- V4 §推理 infra — 异构 cache 总览
- 投机解码与 DSpark — 唯一入口(MTP、自测、DSpark、MTP-1)
3. 节点间关系
| 边 | 关系 |
|---|---|
| ① → ② | DSA 算法改动 使 cache 天然分为 Indexer / Latent 两类 |
| ② → ③ | Index Share 只优化 indexer 路径;不改 Latent 布局 |
| ② → ④ | ESS 只 offload Latent-Cache;Indexer 必须 GPU 常驻 |
| ③ ⊥ ④ | 正交:一个省算、一个省显存;V3.2 上可叠加 |
| ④ → ⑤ | V4 非 ESS 简单放大;围绕 CSA/HCA/SWA 重做 内存层级 |
4. 与算法线的交叉
| infra 阶段 | 依赖的算法组件 | 文档 |
|---|---|---|
| ② 异构 cache | DSA(Lightning Indexer + Core MLA) | 算法线 §② |
| ⑤ V4 HiSparse | CSA/HCA 压缩 entry | CSA / HCA · 算法线 §③ |
算法线完整导读见 算法线导读。MoE 线见 MoE 线导读。
5. 反向引用
| 节点文档 | 文首应含 |
|---|---|
| MLA 低秩注意力 | [← 基础设施线导读](06-基础设施线导读.md) |
| DSA 稀疏注意力 | 同上 + 下游 Index Share / ESS |
| Index Share 梗概 | 同上 + 并列 ESS |
| ESS Latent offload | 同上 + 并列 Index Share |
| DeepSeek-V4 | 同上 + 说明与 V3.2 ESS 差异 |
| V4 KV Layout · V4 HiSparse · V4 磁盘 Prefix Cache | V4 infra 三专题;文首链回 §5.3 |
| 投机解码与 DSpark | 投机解码 / DSpark 唯一专文 |
维护约定见 DeepSeek 版本演进线文档引用约定。
DeepSeek MoE 线:稠密 FFN → DeepSeekMoE → aux-loss-free → Hash MoE
← 中文导读 · ← 仓库首页(EN) · 更新:2026-06-27 ← 演进总览 §1 · 算法线导读 · 基础设施线导读 · V1→V3 演进 · 版本梗概索引 · 《ds-技术报告》读本
DeepSeek 在 FFN / 专家路由 上的演进可概括为(与 演进总览 §1 正文内联一致):
稠密 FFN → DeepSeekMoE → aux-loss-free 路由 + $L_{\mathrm{Bal}}$ → Hash MoE + FP4
本文是 MoE 线 专题导读;Attention 侧见 算法线导读,KV/offload 见 基础设施线导读。
1. 演进链
| 阶段 | 核心机制 | 定型版本 | 本地文档 | 论文 |
|---|---|---|---|---|
| ① 稠密 FFN | 全参数 SwiGLU;无稀疏激活 | V1(2024-01) | DeepSeek-LLM V1 | 2401.02954 |
| ② DeepSeekMoE | 细粒度 routed + shared experts;softmax 路由 | V2(2024-05) | DeepSeekMoE · DeepSeek-V2 | 2405.04434 |
| ③ aux-loss-free | sigmoid affinity + 动态 bias $b_i$;无 aux loss 主均衡 | V3(2024-12)→ V3.2 | aux-loss-free MoE 路由 · DeepSeek-V3 | 2412.19437 §2.1 |
| ④ $L_{\mathrm{Bal}}$ | 序列内 $f_i P_i$ 互补兜底;极小 $\alpha$ | V3 起 | 序列均衡损失 | 同上 Eq. 17–20 |
| ⑤ Hash MoE + FP4 | 前几层 Hash-routed MoE;routed expert FP4 + QAT | V4(2026) | Hash MoE + FP4 · DeepSeek-V4 | 2606.19348 |
③ 与 ④ 互补:aux-loss-free $b_i$ 管 **batch 级**主均衡;$L_{\mathrm{Bal}}$ 防 单序列内 expert 打穿。
2. 阅读顺序
- V1 正文 — 稠密基线
- DeepSeekMoE 架构 — 细粒度 routed + shared(Figure 2 优化逻辑 · Fine-grained vs GShard)
- V2 梗概 — MLA + MoE 版本落地(236B/21B)
- V3 梗概 — 256 / 8 act 旗舰化
- aux-loss-free 路由逻辑 → $L_{\mathrm{Bal}}$ 详解
- Hash MoE + FP4 — Hash 路由与 FP4 量化
- V4 梗概 — 两个规格、Attention、训练与 infra 总览
前代三代对照:V1→V3 演进 §3.2 FFN
3. 节点间关系
| 边 | 关系 |
|---|---|
| ① → ② | V2 用 条件计算 替换稠密 FFN,稀疏激活降训练/推理 FFN 成本 |
| ② → ③ | V3 扩专家数(256/8)并改 sigmoid + bias 路由,去掉 aux loss 主路径 |
| ③ + ④ | $L_{\mathrm{Bal}}$ 不替代 aux-loss-free,仅序列内安全网 |
| ③ → ⑤ | V4 继承 DeepSeekMoE 框架;前几层改 Hash 路由,并 FP4 量化 routed expert |
4. 与 Attention / infra 线的交叉
| MoE 阶段 | 正交模块 | 文档 |
|---|---|---|
| 全阶段 | Attention / KV | 算法线 · 基础设施线 |
| V3.2+ | DSA / Index Share | 不改 MoE 路由权重形状 |
| V4 | mHC 残差 | mHC — 子层前后混合,不替代 expert 选择 |
5. 反向引用
| 节点文档 | 文首应含 |
|---|---|
| DeepSeekMoE | [← MoE 线导读](07-MoE线导读.md) |
| DeepSeek-V2 | [← MoE 线导读](07-MoE线导读.md) |
| DeepSeek-V3 | 同上 |
| aux-loss-free MoE 路由 | 同上 + 上游 DeepSeekMoE |
| 序列均衡损失 | 同上 + 主文档 aux-loss-free |
| Hash MoE + FP4 | 同上 + 上游 aux-loss-free |
| DeepSeek-V4 | 同上 + 链 Hash MoE 专文 |
维护约定见 版本演进线文档引用约定。
DeepSeek V1 → V2 → V3:前代到旗舰基座
1. 三代在系列中的位置
DeepSeek 开源主线可粗分为两段:
- V1 → V2 → V3(2024):从稠密双语基座,到 MLA + MoE 效率架构,再到 规模化旗舰 MoE(671B)
- V3.1 → V3.2 → V4(2025–2026):在同一 V3 权重架构上 post-train、加 DSA、再 架构大步进
本文梳理第一段:V1 → V2 → V3。
2. 对照总表
| 版本 | 时间 | 机构 | arXiv | 总参 / 激活 | 上下文 | 注意力 | FFN | 预训练 |
|---|---|---|---|---|---|---|---|---|
| DeepSeek-LLM V1 | 2024-01 | DeepSeek | 2401.02954 | 7B / 7B;67B / 67B | 4K | MHA / GQA | 稠密 SwiGLU | 2T |
| DeepSeek-V2 | 2024-05 | DeepSeek | 2405.04434 | 236B / 21B | 128K | MLA | DeepSeekMoE(6 routed + shared) | 8.1T |
| DeepSeek-V3 | 2024-12 | DeepSeek | 2412.19437 | 671B / 37B | 128K | MLA(同 V2 族) | MoE 256 / 8 act + aux-loss-free | 14.8T |
3. 演进逻辑
3.1 注意力:标准 GQA → MLA

{kind=link}
- V2 首创 MLA(2405.04434);V3 沿用同一 latent 格式(MLA 详解)
- V3.1 再在 Prefill/Decode 间切换 MHA/MQA 模式;V3.2 叠加 DSA — 均属 V3 代之后,不在 V1–V3 段
3.2 FFN:稠密 → MoE → 大规模 aux-loss-free MoE
| 代际 | 做法 |
|---|---|
| V1 | 全参数激活;67B 用 加深(95 层) 而非单纯加宽 FFN |
| V2 | DeepSeekMoE:160 routed,每 token 6 个 + shared;稀疏激活降训练/推理 FFN 成本(MoE 线 §②) |
| V3 | 扩到 256 experts / 8 activated;路由改为 sigmoid + 动态 bias(aux-loss-free),并加 MTP 辅助头 |
3.3 规模与数据:scaling laws → 产品化旗舰
| 代际 | 训练叙事 |
|---|---|
| V1 | 系统研究 IsoFLOP / batch-LR scaling;7B/67B 同训 2T 双语语料 |
| V2 | 8.1T 多源语料;证明 21B 激活可打过 67B 稠密 |
| V3 | 14.8T + 完整后训练管线;671B 成为 R1 / V3.1 / V3.2 的共同架构母版 |
4. 能力代际

{kind=link}
5. 推理 infra 代际差异
| 维度 | V1 | V2 | V3 |
|---|---|---|---|
| KV 格式 | 标准 GQA/MHA | MLA latent | MLA latent(同 V2) |
| 引擎适配 | 通用 HF/vLLM | 需 MLA / MoE 定制 | FlashMLA、DeepGEMM、block-size=1 |
| 长上下文瓶颈 | 4K 上限 | 128K latent 线性涨 | 同左;V3.2 才拆 Indexer/Latent |
6. 阅读顺序
- V1 正文(DeepSeek-LLM 完整译文)
- DeepSeekMoE 架构 · V2 梗概 · MLA 前向流程图
- V3 梗概 · 演进总览 §3
- 后续代际:R1 → V3.1 → V3.2 → V4
7. 参考
- DeepSeek-AI. DeepSeek LLM: Scaling Open-Source Language Models with Longtermism. arXiv:2401.02954, 2024.
- DeepSeek-AI. DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model. arXiv:2405.04434, 2024.
- DeepSeek-AI. DeepSeek-V3 Technical Report. arXiv:2412.19437, 2024.
DeepSeek 各版本梗概
更新:2026-06-25 ← 中文导读 · ← 仓库首页(EN) · 版本演进总览 · 算法线导读 · 基础设施线导读 · MoE 线导读
每篇一页纸梗概:定位、核心改动、infra 关注点、上下游关系。
| 算法线 | 算法线导读 | MLA → DSA → CSA/HCA + mHC 专题 hub | | 基础设施线 | 基础设施线导读 | MLA KV → 异构 Cache → Index Share → ESS → V4 HiSparse | | MoE 线 | MoE 线导读 | 稠密 FFN → DeepSeekMoE → aux-loss-free → Hash MoE |
| 版本 | 文档 | 一句话 |
|---|---|---|
| V1 | DeepSeek-LLM V1 | DeepSeek-LLM 完整中文译文(7B/67B;Figure 2–5 / Table 3–4) |
| V1 BBPE | V1 BBPE 词表 | Byte-level BPE 词表、预分词规则、102,400 embedding |
| V2 | DeepSeek-V2 | 236B/21B;MLA + DeepSeekMoE 首次引入;128K |
| V1→V3 | V1→V3 前代演进 | 前代三代对照与演进逻辑 |
| V3 | DeepSeek-V3 | 671B MoE + MLA 基座,开源旗舰起点 |
| V3 FP8 | V3 FP8 动态量化 | 训练侧 FP8 块级动态 scale + FP32 累加提升 |
| R1 | DeepSeek-R1 | V3-Base + RLVR;架构不变 |
| RLVR | RLVR | 可验证奖励 + GRPO;R1 后训练核心 |
| MLA | MLA 低秩注意力 | latent 压缩 KV;前向流程图(Eq. 37–47) |
| DeepSeekMoE | DeepSeekMoE | 细粒度 routed + shared;V2 首发、V3 旗舰化 |
| MoE 路由 | aux-loss-free MoE 路由 | aux-loss-free 动态 bias 负载均衡(V3 论文 Table 5) |
| Seq-wise $L_{\mathrm{Bal}}$ | 序列均衡损失 | 单序列内 $f_i P_i$ 互补均衡(Eq. 17–20) |
| V3.1 | DeepSeek-V3.1 | Hybrid 推理,无架构变更,128K |
| V3.2 | DeepSeek-V3.2 | DSA 稀疏注意力,长上下文效率拐点 |
| DSA | DSA 稀疏注意力 | indexer + top-$k$ + Core MLA;完整逻辑 |
| Index Share | Index Share 梗概 | IndexCache 纯 infra 补丁,社区称「V3.3」 |
| ESS | ESS Latent offload | Latent-Cache CPU offload;论文梗概 |
DSA / Index Share 逻辑详解:DeepSeek DSA 与 Index Share 系列
| mHC | mHC | 双随机流形约束残差超连接(含 §3 流形推导);V4 落地 | | Hyper-Connections | Hyper-Connections | $n$ 路并行残差流 + pre/post/comb;mHC 前置(HC 子专文) | | CSA / HCA | CSA / HCA | 4:1 稀疏 + 128:1 dense 混合压缩注意力;V4 算法线 ③ | | Hash MoE + FP4 | Hash MoE + FP4 | 前几层 Hash 路由 + routed expert FP4;MoE 线 ⑤ | | Muon | Muon 优化器 | 矩阵正交化优化器;V4 训练侧替换大部分 AdamW | | V4 | DeepSeek-V4 | V4-Pro / V4-Flash 梗概,1M context | | V4 KV layout | V4 KV Layout | Classical + State 双池 | | V4 HiSparse | V4 HiSparse | inactive C4 CPU offload;~3× KV 容量 | | V4 磁盘 Prefix | V4 磁盘 Prefix Cache | CSA/HCA 落盘 + SWA 三档策略(§3.5.2) | | DSpark / 投机解码 | 投机解码与 DSpark | 唯一专文(MTP + 自测 + DSpark + MTP-1) |
DeepSeek 技术报告与外部解读
← 中文导读 · ← 仓库首页(EN) · 版本梗概 · 演进总览 · Raschka V3→V3.2 解读
本目录存放 官方技术报告摘要 与 第三方深度解读。
| 文档 | 类型 | 说明 |
|---|---|---|
| V1→V3 前代演进 | 本地总览 | V1 → V2 → V3 前代演进 |
| DeepSeek-LLM V1 | 精读 | DeepSeek-LLM V1 完整中文译文(2401.02954;Figure 2–5 / Table 3–4) |
| 版本演进总览 | 本地总览 | 全系列 V1→V4 算法线 + infra 线 |
| 算法线导读 | 算法线导读 | MLA → DSA → CSA/HCA + mHC 专题 hub |
| 基础设施线导读 | 基础设施线导读 | MLA KV → 异构 Cache → Index Share → ESS → V4 HiSparse |
| MoE 线导读 | MoE 线导读 | 稠密 FFN → DeepSeekMoE → aux-loss-free → Hash MoE |
| Raschka 要点速读 | 梗概 | Raschka 一文要点速读 |
| Raschka 全文解析 | 全文解析 | 分章整理 + 关键表格嵌入 |
| 如何评价 DeepSeek 发布 DSpark?哪些亮点值得关注? | 外部解读 | 酱紫君(GalAster):DSpark、半自回归、验证截断、MTP、draft 训练 |
| 投机解码与 DSpark | 投机解码全集 | MTP、外挂 draft 自测、DSpark、MTP-1(唯一入口) |
| 投机解码自测加速比 | 重定向 | 已并入上表专文 §3 |
| 文档系列结构审查 | 结构审查 | 双向引用、章节导航、概念/SVG 复用审计 |
CI 门禁:bash scripts/doc_series_gate.sh(check_svgs + build_book + FP8 导航 spot-check)
外部原文:A Technical Tour of the DeepSeek Models from V3 to V3.2(Sebastian Raschka,2025-12-03,更新 2026-01-01)
DeepSeek-V3 梗概
← 中文导读 · ← 仓库首页(EN) · ← 演进总览 §3.3 · ← MoE 线导读 · ← 版本目录 · Raschka 解读
定位
2024 年 12 月发布的开源旗舰 Base 模型,奠定 DeepSeek 后续全系架构基座。671B 总参数、每 token 激活 37B,支持 128K 上下文。同年 1 月基于同一架构推出 DeepSeek-R1(RLVR 推理专精,DeepSeek-R1),架构不变、训练管线不同。
核心架构
| 组件 | 要点 |
|---|---|
| MLA | Multi-Head Latent Attention:K/V 压入 latent 再缓存;前向流程图(Eq. 37–47) |
| DeepSeekMoE | 256 routed + shared experts,每 token 激活 8 个 |
| MTP | Multi-Token Prediction 辅助训练,推理可做 speculative decoding |
| 路由 | aux-loss-free 负载均衡(动态 expert bias,无 aux loss 主均衡) |
对比 V2:纯模型结构优化
边界:本节只讲 Transformer 内部 — MoE 路由、注意力、预测头、层内数据流;不含 DualPipe / FP8 训练框架、DeepEP、vLLM 调度、KV 量化等训推系统(见文末 排除项)。
一、MoE:路由与负载均衡

图示详情 · 详解:aux-loss-free · DeepSeekMoE
{kind=link}
二、MLA 注意力
V3 沿用 V2 的 MLA 方程与 latent KV 格式($c_t^{KV}$ 512 + 共享 $k_t^R$ 64 进 cache;前向流程图)。相对 V2 的改动主要是 671B 母版下的 hidden / 层数 / 128K 上下文配比,而非全新 attention 算子。
| 项 | V2 | V3 |
|---|---|---|
| MLA 结构 | 首次引入 latent KV | 同族,checkpoint 可续训 |
| 解耦 RoPE(content $d_h^C$ + RoPE $d_h^R$) | 有(Eq. 37–47) | 继承 |
| 128K | V2 主模型已支持 | V3 14.8T 预训练巩固 |
易混:Prefill MHA / Decode MQA Hybrid 自 V3.1-Terminus 起;Lightning Indexer + top-$k$ 稀疏 自 V3.2 DSA 起。二者均 不是 V3-Base 相对 V2 的架构差分。
三、MTP:Multi-Token Prediction
V3 相对 V2 全新 的训练目标头:主 loss + MTP 辅助头(链式预测 $t{+}2, t{+}3, \ldots$)。推理时可丢弃 MTP,也可 复用做 speculative decoding。
| V2 | V3 | |
|---|---|---|
| 预测头 | 单步 next-token | 主 loss + MTP 辅助头 |
| 预训练 | — | 辅助 CE 提升数据效率 |
| 推理 | — | 可 原生 投机解码(无需外挂第二套权重) |
投机解码全集:投机解码与 DSpark§2
补充阅读:酱紫君(GalAster)知乎:DSpark 与投机解码全篇 — 投机背景、半自回归、MTP 融合、draft 训练;知乎原文
四、Transformer 主干层内微调
- RMSNorm / 残差:随层数与 MoE 深度做实现级微调,适配 671B 稀疏 FFN 栈(细节见 2412.19437)。
- 128K 原生配比:hidden、MLA latent 秩、MoE intermediate 等张量维随旗舰规模重配;词表扩至 128K(V1 BBPE 演进)。
- MoE 层内张量布局:routed 按 expert 分组 gather/scatter 的 层内数据流 随 256/8 专家池优化(属模块前向结构,非 EP 通信库本身)。
附、FP8 动态量化
不属于上文「纯模型结构」;与 DualPipe / DeepEP 并列,支撑 671B 预训练。详解:FP8 动态量化专文

{kind=link}
五、排除项
| 类别 | 示例 |
|---|---|
| 推理引擎 | KV 量化、FlashMLA kernel、投机解码 调度、batch 调度 |
| 训练分布式 | DualPipe、FP8 动态量化、DeepEP、集群拓扑 |
| 纯工程 | 显存框架、硬件协同 |
六、浓缩:V3 相对 V2 的三条结构线
- MoE 路由:aux-loss-free(bias 均衡 + sigmoid)+ 256/8 细粒度稀疏,激活占比 5.5% vs V2 8.9%。
- MTP:多 token 并行预测头,预训练提效 + 推理可投机解码。
- MLA:结构继承 V2;V3 价值在 671B / 128K / 14.8T 旗舰化落地(Hybrid、DSA 在后续版本)。
V2 ↔ V3 结构对照
| 维度 | DeepSeek-V2 | DeepSeek-V3 |
|---|---|---|
| 总参 / 激活 | 236B / 21B | 671B / 37B |
| Routed / token | 160 / 6 | 256 / 8 |
| Shared / 层 | 2 | 1 |
| 路由 | softmax + aux loss | sigmoid + bias(aux-loss-free) |
| MLA | 首次引入 | 同族 |
| MTP | 无 | 有 |
| 预训练 | 8.1T | 14.8T |
MoE 线位置
| 方向 | 文档 |
|---|---|
| 本节点(③ 256/8) | DeepSeekMoE 架构 · MoE 线导读 §1 |
| 上游 ② DeepSeekMoE | DeepSeekMoE(V2 首发) |
| 同节点 ③④ | aux-loss-free MoE 路由 · 序列均衡损失 |
训练约 14.8T tokens;后训练含 SFT + RL。
推理 infra 关注点
- KV cache 为 MLA latent 格式,与标准 GQA/MHA 不兼容
- vLLM 等需
--trust-remote-code、--block-size 1 - 长上下文瓶颈:Latent-Cache 线性增长占满 HBM,限制 decode batch size
- 通用 KV CPU offload 常因 MLA 自定义格式而不可用
上下游
| 方向 | 关系 |
|---|---|
| 上游 | DeepSeek-V2(MLA 首次引入)· V1→V3 演进 |
| 下游 | R1(RLVR)、V3.1(post-training)、V3.2(在 V3.1-T 上续训 + DSA) |
参考
- 论文:arXiv:2412.19437
- MoE 路由:aux-loss-free 负载均衡
- 仓库:deepseek-ai/DeepSeek-V3
- R1 训练:DeepSeek-R1 训练管线
MLA前向计算流程
← 中文导读 · ← 仓库首页(EN) · ← 演进总览 §2 · ← 算法线导读 · ← 基础设施线导读 · ← V3 梗概 · V2 MLA 首发 · V3.1 Hybrid MLA 切换 · 下游 DSA · Raschka §3.1 MLA 论文:DeepSeek-V2 首次提出 MLA arXiv:2405.04434;V3/R1/V3.1/V3.2 沿用同一 MLA 结构
一句话
MLA 把 K/V 先压到低维 latent $c^{KV}$ 再写入 KV cache;推理时对 latent 升维 得到多头 K/V 的 content 部分;RoPE 的 R 分量维度小且 全头共享。相对标准 MHA,单 token cache 可从 $O(n_h d_h)$ 降到 $O(d_c^{KV} + d_h^R)$。
流程图

{kind=link}
为什么 1536 能变成 [128,128] 和 [128,64]? ——不是切分,是两个独立上投影矩阵放大后按头 reshape:
- $q_t^C = W^{UQ} c_t^Q$: $[16384 \times 1536] \cdot [1536] \to [16384]$, 其中 $16384 = n_h \times d_h = 128 \times 128$ → reshape $[128, 128]$
- $q_t^R = \mathrm{RoPE}(W^{QR} c_t^Q)$: $[8192 \times 1536] \cdot [1536] \to [8192]$, 其中 $8192 = n_h \times d_h^R = 128 \times 64$ → reshape $[128, 64]$
$[128,128]$ 里两个 128 含义不同:前一个是头数 $n_h$(共 128 个头),后一个是每头维度 $d_h$(每头 128 维),本配置恰好都等于 128。二者都是架构超参,不是从 1536 算出来的;1536 只决定矩阵的列数。(KV 侧同理:$c_t^{KV} = 512$ 经 $W^{UK}, W^{UV}$ 投影成 $[128,128]$。)
右边 $k_t^R = [64]$ 的 64 怎么来? ——$64 = d_h^R$(每头 RoPE 维度,架构超参);$W^{KR}: [64 \times 5120] \cdot h_t \to [64]$,再加上 RoPE。 关键: $k_t^R$ 没有头维度——所有 $n_h = 128$ 个头共享同一个 $[64]$(解耦 RoPE);而左边 $q_t^R$ 是每头各一份 $[128, 64]$。 正因为 K 的 RoPE 部分全局只存一份 $[64]$(不按头复制),KV 缓存才这么小——这是 MLA 省显存的另一半原因。
MLA 到底压缩了谁?如果不做压缩会变多大? ——下面三项就是 MLA 压缩/解耦的对象(格式:MLA 压缩后 $\Rightarrow$ 不压缩):
- $c_t^Q$ 查询潜向量: $1536 \Rightarrow 16384\ (= n_h d_h)$, 约 11×; 不进缓存,省的是参数与计算量。
- $c_t^{KV}$ KV 联合潜向量: $512 \Rightarrow 16384\ (= n_h d_h)$, 32×; ★进缓存 —— 这是省显存的核心。
- $k_t^R$ 共享 RoPE 键: $64 \Rightarrow 8192\ (= n_h d_h^R)$, 128×; ★进缓存,靠全头共享(不按头复制),而非低秩压缩。
缓存总量: 标准 MHA $= 2n_h d_h = 32768$ → MLA 若不压缩 $= 16384 + 64 = 16448$(仅 MHA 一半) → 实际 MLA $= 512 + 64 = 576 \approx$ MHA 的 1/57
口诀:$h_t$ → Q 降维 $c^Q$ / KV 共享降维 $c^{KV}$ → Q/K 拆头 C + 共享 R(RoPE)→ V 仅 C → 注意力 → concat + $W^O$。
符号
| 符号 | 含义 | 典型值(V2 论文) |
|---|---|---|
| $d$ / $d_{\mathrm{model}}$ | 隐状态维度 | 5120 |
| $n_h$ | 注意力头数 | 128 |
| $d_h^C$ | 单头 content 维 | 128 |
| $d_h^R$ | RoPE 维(全头共享) | 64 |
| $d_h$ | 单头 Q/K 维 $d_h^C + d_h^R$ | 192 |
| $d_c'$ | Q 侧 latent 秩 | 1536 |
| $d_c$ / $d_{\mathrm{latent}}^{KV}$ | KV 共享 latent 秩 | 512 |
三分支计算
① Query
| 步 | 公式 | Shape |
|---|---|---|
| 压缩 | $c_t^Q = W^{DQ} h_t$ | $[d] \to [d_c']$ |
| 升维 C | $q_t^C = W^{UQ} c_t^Q$ → 按头拆 $q_{t,i}^C$ | $[n_h \cdot d_h^C]$ |
| RoPE R | $q_t^R = \mathrm{RoPE}(W^{QR} c_t^Q)$ | $[d_h^R]$,所有头共用 |
| 拼接 | $q_{t,i} = [q_{t,i}^C;, q_t^R]$ | $[d_h]$ |
② Key
| 步 | 公式 | Shape |
|---|---|---|
| KV 共享压缩 | $c_t^{KV} = W^{DKV} h_t$ | $[d_c]$ — K 与 V 共用 |
| 升维 C | $k_t^C = W^{UK} c_t^{KV}$ → $k_{t,i}^C$ | 按头拆 |
| RoPE R | $k_t^R = \mathrm{RoPE}(W^{KR} h_t)$ | 来自 $h_t$(非 $c^{KV}$),全头共享 |
| 拼接 | $k_{t,i} = [k_{t,i}^C;, k_t^R]$ | $[d_h]$ |
③ Value
| 步 | 公式 | 说明 |
|---|---|---|
| 复用 latent | 同 $c_t^{KV}$ | 与 Key 分支共享降维结果 |
| 升维 | $v_t^C = W^{UV} c_t^{KV}$ → $v_{t,i}^C$ | 无 RoPE、无 R 支路 |
④ 注意力与输出
$$ o_{t,i} = \sum_{j=1}^{t} \mathrm{Softmax}j\left( \frac{q{t,i}^\top k_{j,i}}{\sqrt{d_h^C + d_h^R}} \right) v_{j,i}^C $$
$$ u_t = W^O, [o_{t,1};\ldots;o_{t,n_h}] $$
KV Cache 里到底存什么
| 标准 MHA | MLA(推理) | |
|---|---|---|
| 每 token 缓存 | $n_h$ 份 K + $n_h$ 份 V | $c^{KV}$ + $k^R$(共享) |
| 典型字节量(上表维度) | $2 \times n_h \times d_h^C \approx 32768$ 维量级 | $d_c + d_h^R = 512 + 64 = 576$ |
| 压缩比 | 1× | 约 1/57 |
推理时从 cache 读出 $c_j^{KV}$ 再乘 $W^{UK}$、$W^{UV}$ 现场升维;多一次矩阵乘,换显存。
V3.1 Hybrid:Prefill 时 Q/K可按 MHA 式展开 latent;Decode 时 MQA 式共享 latent。cache 布局仍是 MLA latent,切换的是展开方式。
基础设施线位置
| 方向 | 文档 |
|---|---|
| 本节点(① 同质 MLA KV) | 基础设施线导读 §1 |
| 下游 ② 异构 cache | DSA稀疏注意力§异构 KV |
算法线位置
| 方向 | 文档 |
|---|---|
| 本节点(① MLA) | 算法线导读 §1 |
| 下游 ② DSA | DSA 稀疏注意力(MLA 结构不变,加稀疏选择) |
| 下游 ③ CSA/HCA | CSA / HCA · DeepSeek-V4(新注意力,不再单一 MLA latent) |
与后续版本
| 版本 | MLA 变化 |
|---|---|
| V3 / R1 / V3.1 | 稠密 MLA attention |
| V3.2 + DSA | MLA 不变;indexer 在 latent 序列上选 top-$k$、Core 仍做 MLA |
| V4 | CSA/HCA 等 新注意力,不再单一 MLA latent · DeepSeek-V4 |
延伸
| 资源 | 说明 |
|---|---|
| MLA前向计算流程(含 PyTorch 对照) | 更长的 shape 推演与 mla_forward.py |
| FlashMLA | V3+ 推理 kernel |
| DeepSeek-V3 | V3 梗概中的 MLA 一行 |
论文:V2 2405.04434 · V3 2412.19437
DeepSeekMoE 架构
← 中文导读 · ← 仓库首页(EN) · ← 演进总览 §2 · ← MoE 线导读 · V2 首发版本 · V3 旗舰化 · aux-loss-free 下游 论文:V2 arXiv:2405.04434 · V3 arXiv:2412.19437 §2.1
一句话
DeepSeekMoE = DeepSeek 自研的 细粒度 routed experts + shared experts FFN 稀疏激活框架:每 token 只激活少量 routed expert,并 始终保留 shared expert 路径;V2(2024-05)首次引入,V3 / R1 / V3.1 / V3.2 沿用同一 MoE 骨架,V3 起路由改为 aux-loss-free,V4 前几层改 Hash 路由。
相对稠密 FFN 的动机
| 稠密(V1) | DeepSeekMoE |
|---|---|
| 每层 FFN 全参数激活 | 仅 top-$K$ routed + shared 参与计算 |
| 容量 ↔ 算力线性绑定 | 总参大、激活参小(如 236B / 21B) |
| 无 expert 路由 | 需 负载均衡(V2 softmax 系 → V3 aux-loss-free) |
V2 论文相对 67B 稠密:训练成本 -42.5%、生成吞吐 5.76×(同参数量级对比语境见 DeepSeek-V2)。
优化逻辑:从常规 MoE 到 DeepSeekMoE
V2 技术报告 §2.2 将 DeepSeekMoE 概括为两步改进(引自 Dai et al., 2024):
- Fine-grained expert segmentation(细粒度专家切分) — 把粗专家拆小,在相同激活算力下提高组合灵活性;
- Shared expert isolation(共享专家隔离) — 固定激活 shared expert 承担通用知识,routed expert 专注特化,减轻冗余与「参数竞争」。
论文用三张子图 (a)→(b)→(c) 说明:每一步都尽量保持每 token 激活的 FFN 参数量 / FLOPs 不变,只改「专家怎么切、怎么路由」。
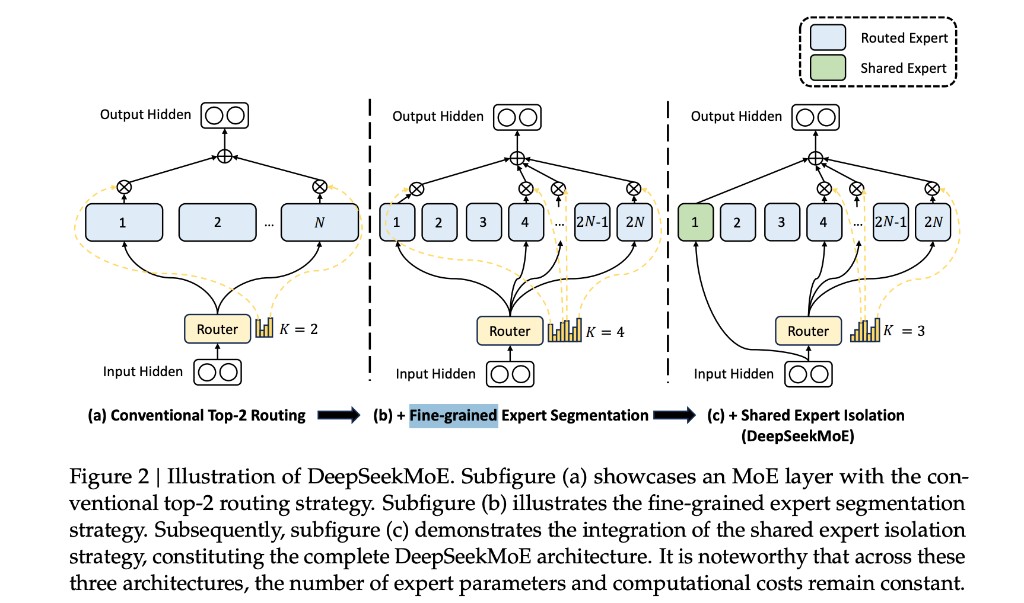
{kind=link}
来源:DeepSeek-V2 论文 Figure 2 — Illustration of DeepSeekMoE。蓝 = routed expert;绿 = shared expert;黄 = Router。
常规 Top-$K$ 路由
| 项 | 设定 |
|---|---|
| 专家池 | $N$ 个大 routed expert |
| 每 token 激活 | $K=2$(经典 Top-2 MoE,如 GShard / Switch 系) |
| 数据流 | Hidden → Router 选 2 个 expert → 加权求和 → 输出 |
局限:专家粒度粗,每个 expert 体积大;Top-2 组合空间只有 $\binom{N}{2}$ 种,特化不够细——不同 token 往往被迫共用同一套「大块」知识。
+ 细粒度专家切分
| 项 | 相对 (a) 的变化 |
|---|---|
| 专家池 | 同样总参下,$N$ 个大 expert → $2N$ 个小 expert(每个约一半宽度) |
| 每 token 激活 | $K=4$ routed(数量翻倍) |
| 算力约束 | 激活 expert 个数 × 单 expert 大小 ≈ 与 (a) 相同 → FLOPs 持平 |
直觉:用「更多、更小」的积木拼 FFN;每 token 仍只付固定算力,但可访问的组合从「选 2 大块」变成「选 4 小块」,表达更灵活、特化更准。 V2 产品配置是这一思想的规模化:单层 160 routed、每 token 6 routed(见下表),而非示意图里的 $N/2N$ 玩具数。
答疑:Fine-grained 为何优于 GShard? — 组合数 $\binom{N}{K}!\to!\binom{mN}{mK}$、IsoFLOP 切分与训练机制
+ Shared Expert 隔离
| 项 | 相对 (b) 的变化 |
|---|---|
| Shared expert | 划出 $N_s$ 个 shared(图中 1 个;V2 为 2 个/层),每个 token 必过,不经 Router |
| Routed 选择 | Router 只在剩余 routed 池里 Top-$K_r$;示意 $K_r=3$ |
| 总算力 | $N_s + K_r = 1 + 3 = 4$,仍与 (b) 的 4 routed 激活量同级 |
为什么要 shared? 许多 token 都需要的通用 FFN 模式(语法、高频搭配等)若全塞进 routed expert,会占掉 routed 容量,导致:
- 多个 routed expert 学重复(knowledge redundancy);
- 特化 expert 抢不过通用模式,负载均衡更难。
Shared 路径隔离通用知识,routed 专注长尾 / 领域特化——论文称这能提升 expert specialization 与知识获取精度。
三步合起来:设计不变量
| 不变量 | 含义 |
|---|---|
| 激活 FFN 预算 | (a)(b)(c) 示意中每 token 激活 expert 总数 × 单 expert 宽度大致恒定 |
| 总参可扩 | 总 expert 数可随层加宽加深,但每 token 只走 sparse 子集 |
| DeepSeekMoE = (b) + (c) | 细粒度 routed 且 shared 与 routed 分工 |
前向公式
对第 $t$ 个 token 的 FFN 输入 $u_t$,输出 $h_t'$ 为 残差 + shared 支路 + routed 支路:
$$ h_t' = u_t + \sum_{i=1}^{N_s} \mathrm{FFN}i^{(s)}(u_t) + \sum{i=1}^{N_r} g_{i,t},\mathrm{FFN}_i^{(r)}(u_t) $$
其中 routed 门控:
$$ g_{i,t} = \begin{cases} s_{i,t}, & s_{i,t} \in \mathrm{TopK}\big({s_{j,t}}{j=1}^{N_r},, K_r\big) \ 0, & \text{otherwise} \end{cases}, \quad s{i,t} = \mathrm{Softmax}_i(u_t^\top e_i) $$
| 符号 | 含义 |
|---|---|
| $N_s$ | shared expert 数(V2:2/层) |
| $N_r$ | routed expert 数(V2:160/层) |
| $K_r$ | 每 token 激活 routed 数(V2:6) |
| $e_i$ | 第 $i$ 个 routed expert 的 routing centroid(非 FFN 权重) |
答疑:为何叫 centroid 而非 gate-weight? — affinity / gate 分工与 V3 选择-门控解耦
Shared 项无 $g_{i,t}$ 门控 — 与图中 Expert 1(绿)始终接通一致。
与 V2 工程配置的对应
示意图用 $N,,2N,,K=2/4/3$ 做教学缩放;DeepSeek-V2 真实超参:
| 示意 (c) | DeepSeek-V2 |
|---|---|
| 1 shared + 3 routed | 2 shared + 6 routed / token / 层 |
| softmax Router | 同左;另加 device-limited routing(§2.2.2:每 token 目标 expert 最多跨 $M$ 台设备,$M\ge 3$ 时精度与无限制 Top-$K$ 接近) |
| 负载均衡 | Expert / device / comm 三级 aux loss(V3 起路由改为 aux-loss-free,MoE 骨架仍为 shared + fine-grained routed) |
结构要点
- Fine-grained routed experts:单层 routed 数量 显著多于 早期 MoE(V2:160),单 expert 更小 → 见上文 §优化逻辑 (b)。
- Shared experts:每层 恒激活 shared FFN(V2:2 个),与 routed 输出相加 → 见 §优化逻辑 (c)。
- Per-token top-$K_r$:V2 每 token 6 routed;V3 8 routed / 256 池。
- 路由演进:V2 softmax + aux balance loss → V3 aux-loss-free + $L_{\mathrm{Bal}}$。
各版本配置
| 版本 | 总参 / 激活 | routed 规模 | 每 token 激活 routed | shared | 路由 |
|---|---|---|---|---|---|
| V2 | 236B / 21B | 160 routed / 层 | 6 | 2 / 层 | softmax |
| V3 | 671B / 37B | 256 routed / 层 | 8 | 有 | aux-loss-free |
| V4 | 1.6T / 49B 等 | 继承 V3 框架 | 同族 | 有 | 前几层 Hash MoE + FP4 |
MoE 线位置
| 方向 | 文档 |
|---|---|
| 本节点(② DeepSeekMoE) | MoE 线导读 §1 |
| 上游 ① | 稠密 FFN(概念阶段;V1 产品实例见 DeepSeek-LLM V1) |
| 下游 ③④ | aux-loss-free MoE 路由 · 序列均衡损失 |
| 下游 ⑤ | Hash MoE + FP4 · DeepSeek-V4 |
推理 infra 关注点
- Expert Parallel(EP):routed expert 分片;负载不均时 GPU 空转 → 路由均衡是训练关键(答疑:EP 与 gather/scatter)。
- Shared + routed 双路径:引擎需支持 shared 始终 on + 稀疏 routed gather/scatter。
- V2 路由为 softmax 系;V3+ 为 sigmoid + 动态 bias,权重 checkpoint 不混用路由逻辑。
参考
- DeepSeek-V2 梗概 — MLA + DeepSeekMoE 首次落地(8.1T)
- DeepSeek-V3 梗概 — 256/8 旗舰化 + MTP
- aux-loss-free 路由逻辑
- 仓库:DeepSeek-V2 · DeepSeek-V3
aux-loss-free MoE 路由逻辑
← 中文导读 · ← 仓库首页(EN) · ← 演进总览 §3.3 · ← MoE 线导读 · ← DeepSeekMoE 上游 · ← V3 梗概 · 版本目录 论文:DeepSeek-V3 arXiv:2412.19437 §2.1 · Megatron MoE aux loss free
一句话
aux-loss-free = MoE 不用(或几乎不用)辅助损失 逼专家均匀,而是在每个 routed expert 上维护一个 可学习的 routing bias $b_i$,按 batch 负载 动态加减 $b_i$ 来调 top-$K$ 路由;门控权重仍用原始 affinity $s_{i,t}$,避免 aux loss 伤害主任务 loss。
V3 起标配;V4 系仍沿用同一思路。
为什么 MoE 要「负载均衡」
| 问题 | 后果 |
|---|---|
| 少数 expert 过热、多数闲置 | routing collapse(Shazeer et al., 2017) |
| Expert Parallel(EP)下 token 分布不均 | 部分 GPU 空转、部分打满 → 算力浪费 |
因此几乎所有 MoE 都要某种 load balancing——关键是 用什么机制,以及会不会 牺牲模型质量。
传统做法:auxiliary loss 及其矛盾
经典 Switch / GShard 路线在总 loss 里加 辅助损失 $L_{\mathrm{Bal}}$,惩罚专家负载不均(token 级或 sequence 级)。
| 优点 | 缺点 |
|---|---|
| 实现简单、梯度直接推路由 | aux loss 过大 → 损害主任务表现(Wang et al., 2024a) |
| 易与训练框架集成 | aux loss 过小 → 均衡不够,EP 效率差 |
| sequence-wise aux 强制 每条序列内 专家均匀 → 抑制 按领域 specialization |
DeepSeek-V3 论文 Table 5:纯 aux-loss 基线在多数 benchmark 上 不如 aux-loss-free。
aux-loss-free 核心逻辑
1. 路由分数 vs 门控值
DeepSeek-V3 MoE 对 routed experts 用 sigmoid affinity $s_{i,t}$,再对选中专家做归一化得到门控 $g_{i,t}$(与 V2 的 softmax 路由不同,见 V3 论文 §2.1)。
aux-loss-free 只改「谁进 top-$K$」,不改门控乘到 FFN 输出的数值:
| 量 | 是否加 bias $b_i$ | 作用 |
|---|---|---|
| Top-$K$ 选择 | ✅ 用 $s_{i,t} + b_i$ 排序 | 决定 token 去哪个 expert |
| 门控 $g_{i,t}$ | ❌ 仍用原始 $s_{i,t}$ | 乘 expert 输出,参与前向/反传主 loss |
这样 bias 是 纯路由调度旋钮,不直接扭曲 expert 输出的幅度。
2. 每个训练 step 末尾更新 $b_i$
监控 整个 batch(一步训练)上各 expert 的负载:

{kind=link}
$\gamma$ = bias update speed(V3 预训练:前 14.3T tokens 取 0.001,论文 §3.2)。
无 aux loss 梯度 参与均衡;均衡靠 启发式反馈 调 bias,主 loss 只负责「学得好不好」。
3. 公式
专家 $i$ 在 token $t$ 被激活,当且仅当 $s_{i,t} + b_i$ 落在 top-$K_r$ 集合内;否则 $g'{i,t}=0$。门控 $g{i,t}$ 仍由 $s_{i,t}$ 经 top-$K$ 内归一化得到。
与传统 aux loss 对比
| 维度 | auxiliary loss | aux-loss-free(+ bias) |
|---|---|---|
| 均衡信号 | 加在 loss 上,反传进 router | 不改 loss;改 routing bias |
| 均衡粒度 | 常见 sequence-wise(每序列内均匀) | 默认 batch-wise(一步内整体均匀) |
| 专家 specialization | sequence 内被压平 | 允许 不同领域 走不同专家 |
| 超参 | aux loss 系数 $\alpha$ 难调 | $\gamma$(bias 步长) |
| 与主任务冲突 | 大 $\alpha$ 伤性能 | 论文 ablation:多数 benchmark 更优 |
表:V3 论文 Table 5 摘要
Small MoE
| Benchmark | Aux-Loss-Based | Aux-Loss-Free |
|---|---|---|
| Pile-test (BPB↓) | 0.727 | 0.724 |
| BBH (EM) | 37.3 | 39.3 |
| MMLU (EM) | 51.0 | 51.8 |
| DROP (F1) | 38.1 | 39.0 |
| GSM8K (EM) | 27.1 | 29.6 |
| MATH (EM) | 10.9 | 11.1 |
Large MoE
| Benchmark | Aux-Loss-Based | Aux-Loss-Free |
|---|---|---|
| Pile-test (BPB↓) | 0.656 | 0.652 |
| BBH (EM) | 66.7 | 67.9 |
| HumanEval (Pass@1) | 40.2 | 46.3 |
| GSM8K (EM) | 70.7 | 74.5 |
| MATH (EM) | 37.2 | 39.6 |
论文结论:去掉纯 aux loss、改用 aux-loss-free 后,大多数评测一致更好。
补充:sequence-wise auxiliary loss 仍在
aux-loss-free 不是完全不管极端倾斜。V3 还保留 互补的 sequence-wise balance loss $L_{\mathrm{Bal}}$,防止 单条序列内 专家极度失衡——但 主均衡机制 仍是 bias 方案。
详解:序列均衡损失 — $f_i$、$P_i$ 如何在每条序列上统计、$f_i P_i$ 如何反传拉平负载、与 $b_i$ 的分工。
| 机制 | 作用域 | 角色 |
|---|---|---|
| aux-loss-free bias | batch-wise | 主负载均衡($b_i \pm \gamma$,无梯度) |
| sequence-wise aux loss $L_{\mathrm{Bal}}$ | 单序列 | 兜底,$\alpha$ 极小;$\sum_i f_i P_i$ 反传 router |
论文 §4.5.3:batch-wise(含 aux-loss-free)比 sequence-wise 更灵活,专家更易 按领域分化;1B/3B 实验上 batch-wise aux 与 aux-loss-free 的 val loss 可打平。sequence-wise 单独作主均衡时会 压平序列内 specialization(val loss 略差)。
推理时是什么
- $b_i$ 在训练结束后 固定(推理不再按 step 更新)。
- 路由仍按 训练结束时的 $s+b$ 选 expert;与训练一致。
- 与 Index Share / DSA 等 无关——纯 MoE router 训练策略。
工程对应
| 概念 | Megatron 配置 |
|---|---|
| aux-loss-free | --moe-router-enable-expert-bias |
| bias 步长 $\gamma$ | --moe-router-bias-update-rate(如 1e-3) |
| 传统 aux loss | --moe-router-load-balancing-type aux_loss / seq_aux_loss |
DeepSeek-V3 细粒度 MoE + sigmoid router 在 Megatron侧常配合 FlexDispatcher + DeepEP 做 token dispatch。
MoE 线位置
| 方向 | 文档 |
|---|---|
| 本节点(③ aux-loss-free) | MoE 线导读 §1 |
| 上游 ② DeepSeekMoE | DeepSeekMoE |
| 并列 ④ $L_{\mathrm{Bal}}$ | 序列均衡损失 |
| 下游 ⑤ Hash MoE | Hash MoE + FP4 · DeepSeek-V4 |
在 DeepSeek 系列中的位置
| 版本 | MoE 路由 |
|---|---|
| V3 / R1 / V3.1 / V3.2 | DeepSeekMoE + aux-loss-free(256 routed + shared,top-8) |
| V4 | 论文仍写 auxiliary-loss-free;另改 score 函数(如 Sqrt(Softplus))等 |
演进总览表中「aux-loss-free 路由」即指此项,不是 Engram 或 DSA 的 index。
参考
- DeepSeek-V3:arXiv:2412.19437 — §2.1 Auxiliary-Loss-Free Load Balancing;Eq. 17–20 sequence-wise $L_{\mathrm{Bal}}$;§4.5.2 Table 5;§4.5.3 batch vs sequence
- 方法先例:Wang et al., 2024a(V3 论文引用)
- 本地:序列均衡损失 · DeepSeek-V3 梗概§DeepSeekMoE · Raschka V3 导读
序列均衡损失
← 中文导读 · ← 仓库首页(EN) · ← 演进总览 · ← MoE 线导读 · ← aux-loss-free 主文档 · V3 梗概 论文:DeepSeek-V3 arXiv:2412.19437 §2.1(Eq. 17–20);§4.5.3 batch vs sequence
一句话
V3 主均衡靠 batch-wise $b_i$ 启发式(aux-loss-free);$L_{\mathrm{Bal}}$ 是互补兜底:在 每条序列内 用极小 $\alpha$ 惩罚 $\sum_i f_i P_i$,梯度反传进 router,防单条序列里少数 expert 被「打穿」。
两条机制的分工
| 机制 | 作用域 | 更新方式 | 角色 |
|---|---|---|---|
| aux-loss-free $b_i$ | 整个 training step 的 batch | step 末 $b_i \pm \gamma$,无梯度 | 主均衡 |
| $L_{\mathrm{Bal}}$ | 单条序列 | $\alpha \sum_i f_i P_i$,反传 router | 兜底 |
论文 §4.5.3:sequence-wise 强制序列内更均匀 → 抑制按领域 specialization;batch-wise(含 aux-loss-free)更灵活(Fig. 9)。
MoE 线位置
| 方向 | 文档 |
|---|---|
| 本节点(④ $L_{\mathrm{Bal}}$) | MoE 线导读 §1 |
| 主机制 ③ | aux-loss-free MoE 路由 |
总公式与符号
对 一条序列(长度 $T$,$N_r$ 个 routed expert,每 token 激活 $K_r$ 个):
$$ \mathcal{L}{\mathrm{Bal}} = \alpha \sum{i=1}^{N_r} f_i , P_i \qquad \text{(Eq. 17)} $$
| 符号 | 含义 | 论文 |
|---|---|---|
| $f_i$ | expert $i$ 的 实际负载(离散计数) | Eq. 18 |
| $P_i$ | expert $i$ 的 平均路由概率(连续、可微) | Eq. 19–20 |
| $\alpha$ | 极小超参,几乎不伤主任务 | §2.1 |
| $s_{i,t}$ | token $t$ 对 expert $i$ 的 sigmoid affinity | Eq. 15 |
| $K_r T$ | 整条序列的 routed 槽位总数 | — |
$f_i$ 与 $P_i$ 对照(先建立地图)
| $f_i$ | $P_i$ | |
|---|---|---|
| 问什么 | 实际接了多少活? | router 平均多想派给它多少? |
| 怎么算 | 数 top-$K$ 选中次数 | 对每个 token 归一化 $s$,再 对 $t$ 求平均 |
| 可微吗 | 否(计数);梯度经 $P_i$ 传入 | 是,直接反传 router |
| 均匀时 | $f_i = 1$(本文记法;论文 raw $= 1/N_r$) | $P_i = 1/N_r$ |
前置:「槽位」是什么?
MoE 每一层、对 一条序列:
- $T$ 个 token,每个 token 选 $K_r$ 个 routed expert
- 共 $K_r \times T$ 个槽位(slot)= 每次 expert 被选中的机会
T=4, K_r=2 → 共 8 个槽位
token1 → [A, B] token2 → [A, C]
token3 → [A, D] token4 → [B, C]
$f_i$ 数的是:这 8 个槽位里 expert $i$ 占几个。 $P_i$ 看的是:router 在每个 token 上对 $i$ 的归一化意愿,整条序列平均多少。
batch 里 每条序列单独 算一套 $(f_i, P_i)$,不跨样本混合。
一、$f_i$:实际负载
核心:$f_i$ = 这条序列里 expert $i$ 分到的槽位,相对完全均匀水平的倍数;均匀时 $f_i = 1$。
公式
$$ f_i = \frac{N_r}{K_r T} \sum_{t=1}^{T} \mathbf{1}!\left( \text{expert } i \text{ 在 token } t \text{ 被选入 top-}K_r \right) $$
| 步 | 做什么 | 结果 |
|---|---|---|
| 1 | 每个 token 上,$i$ 进 top-$K_r$ 则 $\mathbf{1}=1$,否则 $0$ | 逐 token 判断 |
| 2 | 对 $t$ 求和 | $\mathrm{count}_i$ = 被选总次数 |
| 3 | $\mathrm{count}_i / (K_r T)$ 再乘 $N_r$ | $f_i$:相对均匀的倍数 |
归一化直觉
$$ \text{raw}_i = \frac{\mathrm{count}_i}{K_r T}, \qquad f_i = N_r \cdot \text{raw}_i $$
| $f_i$ | 含义 |
|---|---|
| $= 1$ | 刚好均匀(每 expert 约 $K_r T / N_r$ 次) |
| $> 1$ | 过热 |
| $< 1$ | 偏冷;可为 $0$ |
论文写「均匀时 $f_i = 1/N_r$」指 raw 形态 $\mathrm{count}_i/(K_r T)$;与本文 $f_i = N_r \cdot \text{raw}_i$ 差一个 $N_r$,说的是同一件事。
实现注意:计数用 $s$ 还是 $s+b$?
| 环节 | 分数 |
|---|---|
| 真实派活(Eq. 16) | $s_{i,t} + b_i$ 取 top-$K_r$ |
| 论文 Eq. 18 写法 | 示性函数写 $s_{i,t}$ |
工程(Megatron seq_aux_loss) | 按真实 dispatch 计数($s+b$ 选中则 $\mathrm{count}_i{+}{+}$) |
二、$P_i$:平均路由概率
核心:$P_i$ = 这条序列上,router 对 expert $i$ 的 归一化意愿 的时间平均;均匀时 $P_i = 1/N_r$。
公式
Step 1 — 原始 affinity
$$ s_{i,t} = \mathrm{Sigmoid}(\mathbf{u}_t^\top \mathbf{e}_i) \in (0, 1) \qquad \text{(Eq. 15)} $$
$\mathbf{u}_t$:token $t$ 的 FFN 输入;$\mathbf{e}_i$:expert $i$ 的路由向量。注意:这里用 $s$,不加 $b_i$。
Step 2 — 在全体 expert 上归一化
$$ s'{i,t} = \frac{s{i,t}}{\displaystyle\sum_{j=1}^{N_r} s_{j,t}} $$
- 分母是 全部 $N_r$ 个 routed expert,不是只在 top-$K_r$ 内
- 对每个 token $t$,$\sum_i s'_{i,t} = 1$(概率分布)
- $s'_{i,t}$ 可微,梯度可回传到 router
Step 3 — 对序列求平均
$$ P_i = \frac{1}{T} \sum_{t=1}^{T} s'_{i,t} $$
| $P_i$ | 含义 |
|---|---|
| $= 1/N_r$ | router 对 $i$ 的意愿与其他 expert 相当 |
| $> 1/N_r$ | router 系统性偏爱 $i$ |
| $< 1/N_r$ | router 系统性冷落 $i$ |
$P_i$ 与门控 $g_{i,t}$ 的区别
| $s'_{i,t}$ / $P_i$ | 门控 $g_{i,t}$(Eq. 13–14) | |
|---|---|---|
| 归一化范围 | 全部 $N_r$ 个 expert | 仅 top-$K_r$ 内 的 $s$ |
| 是否进 loss | $P_i$ 进入 $L_{\mathrm{Bal}}$ | 乘 FFN 输出,进 主 loss |
| 是否加 $b_i$ | 不加 | top-$K$ 选择用 $s+b$,但 $g$ 仍用 $s$ |
$L_{\mathrm{Bal}}$ 通过 $P_i$ 调的是 router 的 全局偏好;门控 $g$ 只管选中 expert 的输出权重。
三、为什么乘 $f_i P_i$?
| 只惩罚 $P_i$ | 只惩罚 $f_i$ | $f_i P_i$ |
|---|---|---|
| router 可压低概率,top-$K$ 仍可能选它 | 计数不可微,无法直接反传 | 负载高 且 意愿高 → 惩罚最大 |
| 负载未必下来 | — | 梯度压低 $s_{i,t}$,top-$K$ 与 $P_i$ 一起下来 |
Switch / GShard 经典结构:离散负载 × 连续概率 = 可微的负载均衡信号。
计算流水线(每条序列、每个 MoE 层)

{kind=link}
四、完整手算示例
设定:$N_r=4,, K_r=2,, T=4$ → 8 个槽位;均匀目标每 expert 2 次。
4.1 路由结果
| token | 选中 expert | 累计 count |
|---|---|---|
| 1 | A, B | A:1 B:1 |
| 2 | A, C | A:2 C:1 |
| 3 | A, D | A:3 D:1 |
| 4 | B, C | B:2 C:2 |
| expert | $\mathrm{count}_i$ | $f_i = \dfrac{4}{8}\times\mathrm{count}_i$ | 状态 |
|---|---|---|---|
| A | 3 | $1.5$ | 过热(均匀是 2 次,拿了 3 次) |
| B | 2 | $1.0$ | 均匀 |
| C | 2 | $1.0$ | 均匀 |
| D | 1 | $0.5$ | 偏冷 |
4.2 各 token 的 $s$ 与 $s'$
设每层 router 给出的 raw affinity(sigmoid 后):
| token | $s_{0,t}$ | $s_{1,t}$ | $s_{2,t}$ | $s_{3,t}$ | $\sum_j s_{j,t}$ |
|---|---|---|---|---|---|
| 1 | 0.90 | 0.70 | 0.40 | 0.30 | 2.30 |
| 2 | 0.85 | 0.40 | 0.75 | 0.20 | 2.20 |
| 3 | 0.90 | 0.30 | 0.35 | 0.60 | 2.15 |
| 4 | 0.50 | 0.80 | 0.70 | 0.25 | 2.25 |
token 1 归一化:
$$ s'{0,1} = \frac{0.90}{2.30} \approx 0.391,\quad s'{1,1} \approx 0.304,\quad s'{2,1} \approx 0.174,\quad s'{3,1} \approx 0.130 $$
对 $t$ 求平均得 $P_i$:
| expert | 各 token 的 $s'_{i,t}$ | $P_i = \frac{1}{4}\sum_t s'_{i,t}$ | vs 均匀 $1/4=0.25$ |
|---|---|---|---|
| A (0) | .391, .386, .419, .222 | 0.355 | 偏爱 ↑ |
| B (1) | .304, .182, .140, .356 | 0.246 | ≈ 均匀 |
| C (2) | .174, .341, .163, .311 | 0.247 | ≈ 均匀 |
| D (3) | .130, .091, .279, .111 | 0.153 | 冷落 ↓ |
4.3 合并算 $L_{\mathrm{Bal}}$
(忽略 $\alpha$,只看 $\sum_i f_i P_i$)
| expert | $f_i$ | $P_i$ | $f_i P_i$ | 解读 |
|---|---|---|---|---|
| A | 1.5 | 0.355 | 0.532 | 负载高 + router 偏爱 → 惩罚最重 |
| B | 1.0 | 0.246 | 0.246 | 正常 |
| C | 1.0 | 0.247 | 0.247 | 正常 |
| D | 0.5 | 0.153 | 0.076 | 本就偏冷,贡献小 |
$$ \sum_i f_i P_i \approx 1.10 $$
反传会 压低 A 的 $s_{0,t}$ → 后续 token 更少选 A,$P_0$ 与 $\mathrm{count}_0$ 一起下降。D 的 $f_3 P_3$ 很小,loss 几乎不阻止其他 expert 把活分给 D。
五、超参与总 loss
$\alpha$:论文取 极小值(extremely small),$L_{\mathrm{Bal}}$ 只作安全网(对比 aux-loss-free Table 5 里大 $\alpha$ 的纯 aux-loss 基线)。
$$ \mathcal{L} = \mathcal{L}{\mathrm{main}} + \lambda{\mathrm{MTP}}\mathcal{L}{\mathrm{MTP}} + \alpha \sum{i} f_i P_i + \cdots $$
$L_{\mathrm{Bal}}$ 只动 router(经 $s_{i,t}$);不改 $b_i$ 启发式;不加在 expert FFN 上。
六、工程与场景
| 概念 | Megatron-LM |
|---|---|
| sequence-wise aux | --moe-router-load-balancing-type seq_aux_loss |
| batch-wise aux | aux_loss |
| aux-loss-free bias | --moe-router-enable-expert-bias |
| 场景 | 说明 |
|---|---|
| 训练 | $b_i$ + $L_{\mathrm{Bal}}$ 并存;$\alpha$ 小 |
| 推理 | $L_{\mathrm{Bal}}$ 不参与;$b_i$ 固定 |
参考
- aux-loss-free MoE 路由 — $b_i$、top-$K$ 双轨
- DeepSeek-V3 §4.5.3 — batch-wise vs sequence-wise val loss
- Megatron MoE README
DeepSeek-V3 FP8 动态量化
← 中文导读 · ← 仓库首页(EN) · ← 演进总览 §3.3 · ← V3 基座 · 论文 Figure 7 边界:属 训练侧 GEMM 数值/内核(与 DualPipe、DeepEP 并列),不是 Transformer 权重结构本身;V3 纯模型结构对比 刻意不含本节。
一句话
V3 在 FP8 Tensor Core GEMM 上用 块级动态 scale(fine-grained quantization) 抑制激活离群点误差,并 每隔 $N_c{=}128$ 次 MMA(名词解释:MMA)把 Tensor Core 低精度累加 提升到 CUDA Core FP32 寄存器 再续算——在保持 FP8 吞吐的同时,把 671B 预训练做稳。
为何需要「动态」量化
| 问题 | 后果 | V3 对策 |
|---|---|---|
| 激活 离群值(outliers) | 整块 FP8 动态范围被少数大值撑满,有效精度下降 | 细粒度:每 $N_c$ 元素一块,独立 scale |
| Tensor Core 低精度长累加 | 大量 FP8 MMA 后 partial sum 漂移 | 周期性提升:每 $N_c$ MMA 进 FP32 累加 |
| 仅粗粒度 per-tensor scale | 大模型宽 hidden / 宽 expert 更易失真 | 激活与权重 双侧 块 scale |
Figure 7 两路逻辑
Fine-grained quantization
对 激活 与 权重 均按长度 $N_c$ 分块:
- 每块各自算 动态 scale $s_x$(激活)、$s_w$(权重);
- 块内元素量化到 FP8 后在 Tensor Core 做 GEMM / MMA,得到 低精度积;
- 在 CUDA Core 用 $s_x \cdot s_w$ 反量化 写回输出。
要点:scale 随块动态更新,离群只污染所在块,不拖垮整条 tensor。
实现:$s_x = \mathrm{absmax}(X_{\mathrm{block}}) / F_{\max}$($F_{\max}$ 为 FP8 可表示最大值;$s_w$ 同理);量化 $\mathrm{FP8}(x) = \mathrm{round}(x / s_x)$;MMA 输出在 CUDA Core 做 $\mathrm{out} \mathrel{+}= \mathrm{MMA}(\mathrm{FP8}(x), \mathrm{FP8}(w)) \cdot s_x s_w$。
Increasing accumulation precision
一次 GEMM 对应多轮 WGMMA(warp-group MMA):
- Tensor Core 内先用 低精度累加器 收 partial sum;
- 每累计 $N_c = 128$ 个 MMA 元素,把当前 partial 提升到 CUDA Core 的 FP32 寄存器 再累加;
- 下一轮 WGMMA 再从低精度路径开始,避免 全程 FP8/低精度 长链漂移。
要点:算在 TC、稳在 CUDA FP32——速度与 671B 训练可收敛性之间的折中。
实现:沿归约维 $K$ 维护 MMA 计数;每 128 步执行 acc_fp32 += promote(acc_tc); acc_tc = 0;GEMM 结束后再 acc_fp32 += promote(acc_tc) 写回 BF16/FP16 激活。
分工速查
| 机制 | 实现落点 | 关键参数 |
|---|---|---|
| (a) 块 scale + 反量化 | 量化在 GEMM 前;CUDA Core 乘 $s_x s_w$ | $N_c = 128$ |
| (b) FP32 promotion | TC 低精度 acc;CUDA Core FP32 续加 | 每 128 MMA flush 一次 |
硬件分工
| 单元 | 职责 |
|---|---|
| Tensor Core | FP8 MMA / GEMM;块内低精度乘加 |
| CUDA Core | 乘 $s_x s_w$ 反量化;FP32 高精度累加 |
这与 V3 报告里 FP8 训练框架(配合 DualPipe 并行、DeepEP 通信)同属 训推系统层;换推理引擎 FP8 kernel(如自测 draft+FP8)是 另一套部署量化,数值策略不必与训练块 scale 完全相同。
在 V3 全景中的位置
| 层级 | 示例 | 本文 |
|---|---|---|
| 模型结构 | MLA、MoE 256/8、MTP | 否 |
| 训练数值/内核 | FP8 GEMM、块 scale、FP32 promotion | 是 |
| 训练并行 | DualPipe、DeepEP | 相关但另文 |
| 推理 infra | MLA KV、投机解码、KV 量化 | 否(推理 FP8 另论) |
参考
- 论文:DeepSeek-V3 arXiv:2412.19437 · Figure 7
- 结构边界:DeepSeek-V3 梗概§排除项
- 演进总览:§3.3 DeepSeek-V3
RLVR
← 中文导读 · ← 仓库首页(EN) · ← 演进总览 §2 · ← R1 梗概 · Raschka §RLVR/GRPO 论文:DeepSeek-R1 arXiv:2501.12948
一句话
RLVR = 在强化学习里 不用神经 reward model,而对 可程序/符号验证 的任务(数学答案、代码单测、格式规则)直接给 0/1 或规则分 作奖励;DeepSeek 用 GRPO 做优化(无 critic 的组内相对 advantage)。R1 = V3-Base 架构不变 + RLVR 后训练。
和 RLHF / GRPO 的关系

{kind=link}
| 路线 | 奖励从哪来 | 优化算法 | 典型场景 |
|---|---|---|---|
| RLHF | 人类偏好训练的 神经 RM | PPO(需 critic) | 开放域对齐 |
| GRPO | 任意标量奖励 | 组内采样 $G$ 条,相对 baseline 算 advantage;无 critic | 省显存、易扩展 |
| RLVR + GRPO | 规则 / 验证器(计算器、sympy、单测、格式检查) | 同上 GRPO | 数学、代码、可判定推理 |
同一条 prompt 采样 $G$ 次 rollout:每条用 verifier 打分(对/错、格式、语言)→ 组内减均值得 advantage → 更新 policy(R1 上即 V3-Base 权重)。
RLVR 省掉什么:不训、不依赖 reward model,减轻 reward hacking(模型讨好 RM 而非真做对题)。
RLVR 局限:只适合 答案可验证 的短程任务;开放域写作、主观 helpfulness 仍需 RM 或 LLM-as-judge(V3.2 后训练即 RLVR + 生成式 RM 混合)。
DeepSeek-R1 里的 RLVR
算法:GRPO
- 同一 prompt 生成 $G$ 条 完整回答(R1 一阶段约 16 rollout / 题)
- 每条算规则奖励 → 组内相对 advantage(无 value network)
- 配合 KL 到 reference、clip 等稳定训练
R1 奖励
| 奖励 | 作用 | 阶段 |
|---|---|---|
| Accuracy / verifier | 数学、代码等 对错(sympy、单测等) | R1-Zero、R1 一阶段 RL |
| Format | 思考/答案分隔、`` 等结构 | R1-Zero 起 |
| Language consistency | 惩罚中英混杂,鼓励与问题同语言 | R1 二阶段 RL 起 |
两条产物
| 模型 | 路径 | 要点 |
|---|---|---|
| R1-Zero | V3-Base → 纯 GRPO + RLVR(无 SFT 冷启动) | 推理能力 自发涌现(长度增长、自反思);可读性差 |
| R1 | 冷启动 SFT → RL → 拒绝采样 SFT → RL | 在 R1-Zero 能力上补 可读性、通用任务、安全 |
详见 R1 四阶段训练管线(含 Dev-1→R1 与 Table 3 指标)。
在 DeepSeek 系列中的位置
| 版本 | 与 RLVR 关系 |
|---|---|
| V3 | Base;无 RLVR |
| R1 | RLVR + GRPO 主路径;架构 同 V3 |
| V3.1 / Terminus | Hybrid 对话;训练管线不同,非 R1 专用推理模型 |
| V3.2 | 继承 R1 系 GRPO 经验 + 生成式 RM(开放域)+ DeepSeekMath V2 过程奖励;Raschka 对比 |

{kind=link}
为何 R1 不改架构
RLVR 只改 后训练(采样、奖励、策略梯度),不动 MLA / MoE 结构。因此 R1 与 V3 权重形状、KV cache 格式、推理引擎配置一致——差异在 行为分布(更长 CoT、更强推理)。
延伸
| 资源 | 说明 |
|---|---|
| DeepSeek-R1 | R1 一页纸梗概 |
| DeepSeek-R1 训练 Pipeline | 四阶段 + R1-Zero 详解 |
| Raschka 全文解析 §3.2 | RLVR vs PPO vs GRPO 对照表 |
| GRPO 长程任务局限 | 社区讨论:GRPO 与长程任务局限 |
论文:R1 2501.12948 · V3 2412.19437
DeepSeek-R1 梗概
← 中文导读 · ← 仓库首页(EN) · ← 演进总览 §3.4 · ← 版本目录 · RLVR 详解 · Raschka §RLVR/GRPO
定位
2025 年 1 月发布,基于 DeepSeek-V3-Base 的 推理专精 模型。架构与 V3 完全相同(671B / 37B activated / 128K);差异在 RLVR + GRPO 后训练,带火「可验证奖励强化学习」路线。
核心训练
| 组件 | 要点 |
|---|---|
| 基座 | DeepSeek-V3-Base,零架构改动 |
| RLVR | 规则/验证器奖励,无神经 RM → RLVR |
| GRPO | 组内相对 advantage,无 critic |
| R1-Zero | 纯 RL 探索路径(无 SFT 冷启动) |
| R1 | 冷启动 SFT → RL → 拒绝采样 SFT → 二阶段 RL(+ 通用 RM) |
与相邻版本
| 维度 | V3 | R1 | V3.1 |
|---|---|---|---|
| 架构 | MoE + MLA | 同 V3 | 同 V3 |
| 定位 | 通用 Base | 推理 / CoT | Hybrid chat + thinking |
| 后训练 | SFT + RL(V3 论文) | RLVR 为主 | 另一套 post-train |
推理 infra
与 V3 相同:MLA latent KV、--trust-remote-code、--block-size 1 等。
参考
RL / 后训练笔记
| 文档 | 内容 |
|---|---|
| RLVR 详解 | 可验证奖励强化学习;R1 的 GRPO + 规则奖励 |
| R1 梗概 | V3-Base + RLVR,架构不变 |
| R1 训练管线 | 四阶段 Dev-1→R1、R1-Zero |
| GRPO 长程任务局限 | 社区长文:GRPO 与长程任务局限 |
GRPO 长程任务局限
← 中文导读 · ← 仓库首页(EN) · ← RL 笔记索引 · ← RLVR · GRPO · ← 演进总览 §3.4 R1 · 书中对应
作者:划水的青蛙 · 知乎原文
性质:社区讨论整理;非 DeepSeek 官方文档。商业转载请联系原作者。
一句话
GRPO 仍是好算法,但 R1 时代验证的是 短程、可终局判分 的任务;硬搬到 长程 Agent / 编程 时,会在 吞吐、奖励稀疏、组内可比性 上同时吃瘪——智谱、MiniMax、DeepSeek 的后续路线都在 绕开或补 GRPO 的短板。
背景:短程优化 vs 长程 Agent
| 阶段 | 代表 | 任务形态 |
|---|---|---|
| 2024 末–2025 初 | DeepSeek R1、OpenAI O 系 | 数学、代码单测等 短而可验证 |
| 2025 下 | Sonnet 4.5、Opus + Claude Code 等 | 长程编程 / 多步 Agent 真正可用 |
R1 的 RLVR + GRPO 针对的是 同一 prompt、$G$ 条 rollout、终局 verifier 打分——在短 CoT 上成立。长程任务把 轨迹长度、上下文压缩、延迟归因 拉进同一个组内比较,前提就被动摇了。
核心结论
| 维度 | 短程(R1 舒适区) | 长程(GRPO 吃力) |
|---|---|---|
| 奖励 | 终局 0/1 或规则分,相对稠密 | 极度稀疏;整段 rollout 可能 零信号 |
| 吞吐 | 单题 rollout 短,组内 $G$ 条可并行收尾 | 长短任务 混训 → 算力空转;分阶段训 → 梯度震荡 |
| 比较单位 | 同一题下 $G$ 次 平行、完整 作答 | 轨迹 状态不一致(压缩、工具调用、试错长度差几个数量级) |
工程瓶颈:吞吐 vs 样本多样性
长程 RL 要先解决 怎么跑起来,再谈算法:
- 先短后长:课程从短任务切到长任务时,梯度信号剧烈震荡。
- 长短混训、同组打分:短 rollout 先结束,长 rollout 还在跑 → 组内 advantage 汇总前 大量 GPU 空转。
- 全组长程失败:一组任务跑数小时、$G$ 条全败 → 零 reward,等于白烧资源(见下文「全败退化态」)。
GRPO 的三条前提
社区归纳 GRPO / RLVR 能 work 的三条前提,以及长程下的裂缝:
| 前提 | 短程下 | 长程下的问题 |
|---|---|---|
| 同题可比较 | 同一 prompt 下 $G$ 条 独立完整 轨迹,比终局分即可 | 轨迹 状态空间不一致(见下例) |
| 信号可验证 | 答案 / 单测 终局可判 | 只有「整体不行」,第几步错 要几十步后才显现 |
| 组内能降噪 | 看相对组均,滤掉绝对分噪声 | 稀疏 + 低成功率 → 全败 或 独赢 两种退化(见下节) |
同题可比较:A/B/C/D 反例
同一长程 prompt 采样 $G=4$,终局成功 $=1$、失败 $=0$,组内均分 $\bar r = 0.5$:
| 样本 | 轨迹特征 | 终局分 | 组内 advantage |
|---|---|---|---|
| A | 约 4k token,路径干净 | 1 | $+0.5$ |
| B | 约 200k token,大量试错 + 工具调用 + 上下文压缩 | 1 | $+0.5$ |
| C | 与 B 类似过程 | 0 | $-0.5$ |
| D | 与 B 类似过程 | 0 | $-0.5$ |
问题在于:
- 同样的 $+0.5$,A 与 B 不是一回事:B 里大量 冗余 token 也被正向奖励 → per-token 信用分配不一致。
- B 后半段 可能在 摘要/压缩后的上下文 上生成,与 A 全程单一状态 的轨迹 不可比。
- GRPO 只奖终局:无法表达「前半段垃圾、后半段正确」这类 过程结构。
信号可验证 → 延迟归因
模型收到的是 「这次整体不行」,而不是 「第 $X$ 步动作错了」。错误可能要 几十步之后 才暴露,需要 反传归因——critic / 过程奖励 擅长,纯组内终局比较 不擅长。
组内降噪 → 两种退化态
| 退化态 | 现象 | 长程为何更致命 |
|---|---|---|
| $G$ 条全败 | 组内 advantage 全为 0 或无效更新 | 长 rollout 耗时极长,完全无信号 |
| 仅 1 条成功 | 唯一成功轨迹获得 巨大正 advantage | 长任务 基线成功率极低,成功多半是 偶然 → 高方差事件被当成 强监督 灌进梯度 → 训练 死循环 |
短程任务里「独赢」相对少见;长程里 二者都更常出现。
业界应对
| 方向 | 做法(原文归纳) | 本质 |
|---|---|---|
| 智谱 | Critic 回归,做 token 级 advantage | 恢复细粒度信用分配 |
| MiniMax | CISPO + 复合奖励(过程 / 时间 / 结果)+ Forge 调度 | 新算法 + 新 infra,不硬扛纯终局 GRPO |
| DeepSeek | GRPO 训 专家模型,On-Policy Distillation 在探索时给监督 | 专家提供 过程/行为 信号,不全靠组内终局分 |
三家路径不同,共同点:承认 GRPO 直接硬上长程不够,要在 critic、过程奖励、蒸馏监督 上补洞。
与本地文档的对照:
| 本地 | 关联 |
|---|---|
| RLVR · GRPO | R1 短程可验证 场景下 GRPO 怎么工作 |
| R1 训练管线 | 四阶段 + R1-Zero;非 长程 Agent 专文 |
| Raschka §RLVR/GRPO | V3.2 如何在 GRPO 上叠 生成式 RM / 混合奖励 |
延伸阅读
| 资源 | 说明 |
|---|---|
| RLVR 详解 | 可验证奖励 + GRPO 机制 |
| GRPO vs PPO 对照图 | PPO(critic)vs GRPO(组内 baseline)对照图 |
| 知乎原文 | 未删节的社区论述 |
DeepSeek-R1 训练 Pipeline
← 中文导读 · ← RL 笔记索引 · ← 演进总览 §3.4 R1 · 《ds-技术报告》 论文:DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning arXiv:2501.12948 · PDF:DeepSeek-R1 论文 PDF 基座:DeepSeek-V3 Base

{kind=link}
总览:两条支路
| 支路 | 产物 | 核心思想 |
|---|---|---|
| A. 纯 RL | DeepSeek-R1-Zero | 跳过 SFT,GRPO + 规则 reward,推理能力自发涌现 |
| B. 四阶段 | DeepSeek-R1 | 继承 R1-Zero 推理,补齐可读性、多语言能力、通用任务与对齐 |

{kind=link}
支路 A:DeepSeek-R1-Zero
输入 / 算法 / Reward
| 项 | 内容 |
|---|---|
| 起点 | DeepSeek-V3 Base |
| 算法 | GRPO(Group Relative Policy Optimization),无 critic,组内相对 advantage |
| Prompt | Reasoning prompts(数学/代码/逻辑) |
| Reward | Accuracy(答案对错,sympy 等规则验证)+ Format(`` 等格式约束) |
| 不用 | 神经 RM(防 reward hacking)、SFT 冷启动 |
涌现行为
- 响应长度随训练增长(「思考时间」增加)
- 自反思、验证、换策略
- 「Aha moment」:模型自发学会重新审视
局限
- 可读性差、中英混杂
- 偏推理,写作/开放域 QA 弱
支路 B:DeepSeek-R1 四阶段
中间 checkpoint:Dev-1 → Dev-2 → Dev-3 → R1
阶段 1:冷启动 SFT → R1 Dev-1
| 项 | 内容 |
|---|---|
| 数据 | 数千条 Cold Start Long CoT(高质量、对话式、第一人称思考) |
| 来源 | R1-Zero 高温采样 → 过滤正确+可读 → DeepSeek-V3 精炼 → 人工复核 |
| 目的 | 解决 R1-Zero 的语言混杂与表达问题;产品向可读 CoT |
| 数据配比(整理图参考) | 指令遵循 30% · 知识问答 30% · 推理 20% · 安全对齐 20% |
冷启动 CoT 风格要求:
- 先理解问题 → 详细推理 → 反思与验证
- 第一人称、段落简短、避免 markdown
- 语言与问题一致(V3 翻译 thinking 消混杂)
Trade-off:Dev-1 指令遵循↑(IF-Eval、ArenaHard),但冷启动数据小,AIME 等推理略降于 R1-Zero。
阶段 2:第一阶段 RL → R1 Dev-2
| 项 | 内容 |
|---|---|
| 算法 | GRPO |
| Prompt | Reasoning prompts |
| Reward | Rule-based(同 R1-Zero)+ Language Consistency(目标语言词占比) |
| 关键超参 | lr=3e-6,每题 16 rollout,max len 32768,clip ratio ε=10 |
Dev-2 推理能力恢复并超越 Dev-1(Table 3:AIME、Codeforces 等显著提升)。
阶段 3:拒绝采样 + SFT → R1 Dev-3
| 项 | 内容 |
|---|---|
| 数据总量 | ~800K SFT 样本 |
| Reasoning | ~600K:从 Dev-2 checkpoint 拒绝采样(多采样、只留正确);扩展生成式 RM(V3 判对错);过滤混杂语言/长段落/代码块 |
| Non-Reasoning | ~200K:写作、事实 QA、翻译、自认知、软件工程等(复用 V3 SFT 管线);简单 query 不加 CoT |
| 域分布 | Math 395K · Code 211K · General 178K · STEM 10K · Logic 10K(Table 5) |
后处理链:

{kind=link}
Dev-3 在推理与通用(MMLU、IF-Eval)上进一步平衡。
阶段 4:第二阶段 RL → DeepSeek-R1
| 项 | 内容 |
|---|---|
| Prompt | Diverse prompts(推理 + 通用) |
| Reward | $R = R_{\text{reasoning}}^{\text{rule}} + R_{\text{general}}^{\text{RM}} + R_{\text{language}}$ |
| RM | Helpful RM(66K 偏好对,只看 summary)+ Safety RM(106K 点式安全标注) |
| 训练 | 共 1700 steps;最后 400 steps 才加入通用指令与偏好 RM(防 reward hacking) |
| 温度 | 0.7(比一阶段低,防incoherent) |
最终 R1:推理保持 + helpful & harmless 对齐。
各阶段指标快照
| Benchmark | R1-Zero | Dev-1 | Dev-2 | Dev-3 | R1 |
|---|---|---|---|---|---|
| AIME 2024 | 71.0 | 59.3 | 73.3 | 76.7 | 79.8 |
| MMLU | 88.8 | 89.1 | 91.2 | 91.0 | 90.8 |
| IF-Eval | 46.6 | 71.7 | 72.0 | 78.1 | 83.3 |
| LiveCodeBench | 50.0 | 57.5 | 63.5 | 65.9 | 65.9 |
| ArenaHard | 53.6 | 77.0 | 73.2 | 75.6 | 92.3 |
与 OneReason / LoRA 系列对照
| 维度 | DeepSeek-R1 | OneReason |
|---|---|---|
| 领域 | 通用 LLM 推理 | 生成式推荐 |
| 纯 RL 探索 | R1-Zero | 无直接对应 |
| 分阶段 RL | 两阶段 + 不同 reward | specialize-then-unify(分域 GRPO) |
| 拒绝采样 SFT | 800K 混合数据 | RFT 路径 |
| 冷启动 | 数千 Long CoT | R0–R3 分层 SFT |
蒸馏
DeepSeek-R1 还将长 CoT 能力 蒸馏到小模型(Qwen/Llama 等),开源 R1 系列 checkpoint。
文件索引
| 文件 | 说明 |
|---|---|
| 版本演进总览 §3.4 R1 | 全系列时间线中的 R1 定位 |
| DeepSeek-R1 训练 Pipeline | 本文 |
| R1 训练管线流程图 | 自绘流程图 |
| R1 训练管线参考图 | 外部参考图 |
| DeepSeek-R1 论文 PDF | 原文 |
DeepSeek-LLM V1
← 中文导读 · ← 仓库首页(EN) · ← 演进总览 §3.1 · ← 版本目录 · BBPE 词表专文 · V1→V3 演进 原文:DeepSeek LLM: Scaling Open-Source Language Models with Longtermism · arXiv:2401.02954 PDF:2401.02954.pdf · 图件见 Scaling Laws 图件 · BBPE 词表专文
命名说明:论文与社区常称 DeepSeek-LLM 或 DeepSeek V1;与后续 DeepSeek-V2 / V3(MoE + MLA 旗舰线)是不同架构代际,但构成同一产品线的早期稠密基座。
摘要
开源大语言模型(LLM)近年来发展迅猛,但既往文献中的 scaling laws 结论各异,给 LLM 规模化扩展蒙上了阴影。本文深入研究 scaling laws,并给出适用于两种主流开源配置(7B 与 67B)的独到发现。在 scaling laws 指导下,我们推出 DeepSeek LLM——一项以长期主义推进开源语言模型的工程。
预训练阶段我们构建了目前约 2 万亿 tokens、持续扩充的数据集;并对 Base 模型进行 监督微调(SFT) 与 直接偏好优化(DPO),得到 Chat 模型。评测表明:DeepSeek LLM 67B 在多项 benchmark 上超越 LLaMA-2 70B,尤其在代码、数学与推理领域;开放评测中,DeepSeek LLM 67B Chat 表现优于 GPT-3.5。
1. 引言
基于 decoder-only Transformer 的 LLM 已成为通向 AGI 的核心路径。通过下一词预测在大规模语料上自监督预训练,模型获得创作、摘要、代码补全等能力;SFT 与奖励建模使其更好遵循用户意图,对话能力迅速扩展。
ChatGPT、Claude、Bard 等闭源产品以巨大算力与标注成本拉高社区对开源 LLM 的期望。LLaMA 系列整合多项工作,形成高效稳定架构(7B–70B),成为开源模型的 de facto 基准。
然而开源社区在 LLaMA 之后多聚焦于固定尺寸(7B/13B/34B/70B)的高质量训练,较少系统研究 scaling laws。早期工作(Chinchilla、Kaplan 等)对模型/数据随算力扩展的最优分配结论不一致,对超参讨论也不充分。
本文工作:
- 研究 batch size 与 learning rate 的 scaling laws;
- 系统研究 模型与数据规模 的 scaling laws,揭示最优分配策略并预测大模型性能;
- 发现 不同数据集 拟合出的 scaling laws 差异显著——数据选择会明显影响 scaling 行为,跨数据集泛化 scaling laws 需谨慎。
在 scaling laws 指导下,我们从零训练并尽可能开源信息:
- 2T tokens 预训练语料,以中英文为主;
- 架构大体遵循 LLaMA,但用 multi-step LR 替代 cosine,便于 continual training;
- 150 万+ SFT 实例;并采用 DPO 提升对话表现。
DeepSeek LLM 67B 在代码/数学/推理上超越 LLaMA-2 70B;67B Chat 在中英文开放评测上优于 GPT-3.5;安全评测表明 67B Chat 在实践中可给出无害回复。
2. 预训练
2.1 数据
目标:全面提升数据丰富度与多样性。参考 The Pile、RedPajama、FineWeb、LLaMA 等来源,流程分三阶段:
| 阶段 | 作用 |
|---|---|
| 去重(deduplication) | 跨 dump 全局去重,保证样本唯一性 |
| 过滤(filtering) | 语言与语义质量评估,提高信息密度 |
| 重混(remixing) | 提升低占比 domain,平衡多样性 |
去重:对 Common Crawl 全语料去重,效果远优于单 dump 内去重。91 个 dump 跨库去重率达 89.8%,单 dump 仅 22.2%(Table 1)。
Tokenizer — 完整解读见 BBPE 词表与 Tokenizer 专文(§2.1 论文段落;V2 沿用同词表):
| 项 | 值 | 专文 |
|---|---|---|
| 算法 | BBPE(Byte-level BPE;BPE 简述) | HuggingFace tokenizers |
| 预分词 | 换行 / 标点 / CJK 不跨类 merge(同 GPT-2) | 避免中英混排边界错误 |
| 数字 | 拆成 单 digit(同 LLaMA) | 算术、代码、编号更稳 |
| 常规 + special | 100,000 + 15 → 100,015 | §4 词表规模 |
| BBPE 训练语料 | ~24GB 多语言 | 来自上述三阶段管线子集 |
vocab_size(embedding) | 102,400(预留扩展) | 有效 id 仍以 100,015 为准;见专文 易混点 |

图示详情 · 详述见 BBPE 专文 §2
{kind=link}
2.2 架构
Table 2 — DeepSeek LLM 规格
| 7B | 67B | |
|---|---|---|
| 层数 | 30 | 95 |
| d_model | 4096 | 8192 |
| n_heads | 32 | 64 |
| n_kv_heads | 32 (MHA) | 8 (GQA) |
| 上下文 | 4096 | 4096 |
| 序列 batch | 2304 | 4608 |
| 学习率 | 4.2e-4 | 3.2e-4 |
| 预训练 tokens | 2.0T | 2.0T |
同 D、不同 M → 不同 $C$;2T 是产品统一语料,非 Formula 4 compute-optimal 要求(7B 相对 ~140B 最优属 over-train)。详见 产品训练与 Scaling Law。
微观设计:
- Pre-Norm + RMSNorm
- FFN:SwiGLU,中间维 8/3 × d_model
- 位置编码:RoPE
- 67B 使用 GQA 降低推理成本
宏观设计:
- 7B:30 层;67B:95 层(在参数量与其他开源模型可比的前提下,便于 pipeline 划分)
- 与常见 GQA 模型加宽 FFN 不同,67B 加深网络而非加宽 FFN,以追求更好性能
2.3 超参数
- 初始化 std = 0.006
- AdamW:β1=0.9, β2=0.95, weight_decay=0.1
- Multi-step LR(非 cosine):
- Warmup 2000 steps 至最大 LR
- 80% tokens 后降至最大值的 31.6%
- 90% tokens 后降至 10%
- 梯度裁剪:1.0
Multi-step vs Cosine:1.6B 模型、100B tokens 上,最终性能基本一致;multi-step 在扩大训练规模时可复用第一阶段 checkpoint,便于 continual training。三阶段 token 比例选 80% / 10% / 10% 以平衡复用与性能。
原理详解、公式与 LLaMA cosine 对比 → 学习率调度 Wiki
Batch size 与 LR 随模型规模变化,见 Table 2。
2.4 基础设施
- 并行:数据并行 + 张量并行 + 序列并行 + 1F1B 流水线并行
- Flash Attention
- ZeRO-1 分片 optimizer states
- 计算/通信 overlap(ZeRO-1 reduce-scatter、序列并行 all-gather 等)
- 算子融合:LayerNorm、GEMM、Adam update
- bf16 训练 + fp32 梯度累积
- In-place cross-entropy(kernel 内 bf16→fp32,降低显存)
- 每 5 分钟 异步 checkpoint;支持换 3D 并行配置 resume
- 评测:vLLM(生成任务);continuous batching(非生成)
3. Scaling Laws
算力预算 $C$、模型规模 $N$、数据规模 $D$:传统近似 $C \approx 6ND$。核心问题:算力增加时如何最优分配模型与数据。
答疑:为何改用 $C=M\cdot D$? — $6N_1$/$6N_2$ 相对 $M$ 的误差(Table 3)、IsoFLOP 为何必须用 $M$
早期工作对最优分配结论不一,且超参是否达最优存疑。本文:
- 先研究超参 scaling laws(batch、LR);
- 用 M(non-embedding FLOPs/token) 替代 N,用 C = MD 替代 C = 6ND;
- 发现数据质量影响最优 model/data 分配。
3.1 超参 Scaling Laws
小算力($C=10^{17}$ FLOPs,177M FLOPs/token)网格搜索:batch 与 LR 在较宽范围内 generalization error 稳定(Figure 2a)。

Figure 2 — batch × LR 网格搜索(上:$C=10^{17}$;下:$C=10^{20}$ 验证)
{kind=link}
来源:Figure 2。(a) 小算力下 batch/LR 宽带稳定;(b) $10^{20}$ 验证时拟合点(红星)落在最优区中心。
用 multi-step LR 训练多组模型(算力 $10^{17}$–$2\times10^{19}$),复用第一阶段。将 generalization error 超出最小值 ≤0.25% 的参数视为 near-optimal,拟合得 Formula 1:
$$ \begin{aligned} \eta_{\mathrm{opt}} &= 0.3118 \cdot C^{-0.1250} \ B_{\mathrm{opt}} &= 0.2920 \cdot C^{0.3271} \end{aligned} $$
| 符号 | 含义 |
|---|---|
| $C$ | 训练算力预算(FLOPs),$C = M \cdot D$ |
| $\eta_{\mathrm{opt}}$ | 最优学习率(最大 LR) |
| $B_{\mathrm{opt}}$ | 最优 batch size,单位 tokens/step(非序列条数) |
Formula 1 数值对照:
| $C$ | $B_{\mathrm{opt}}$ | $\eta_{\mathrm{opt}}$ | 备注 |
|---|---|---|---|
| $10^{17}$ | 0.11M tok/step | $2.34\times10^{-3}$ | 小算力拟合区 |
| $10^{18}$ | 0.23M tok/step | $1.75\times10^{-3}$ | |
| $10^{19}$ | 0.48M tok/step | $1.31\times10^{-3}$ | |
| $10^{20}$ | 1.02M tok/step | $9.86\times10^{-4}$ | 1e20 验证点(Figure 2b) |
| $8.5\times10^{22}$ | 9.22M tok/step | $4.25\times10^{-4}$ | DeepSeek 7B @ 2T |
- 算力 ↑ → $B_{\mathrm{opt}}$ ↑,$\eta_{\mathrm{opt}}$ ↓
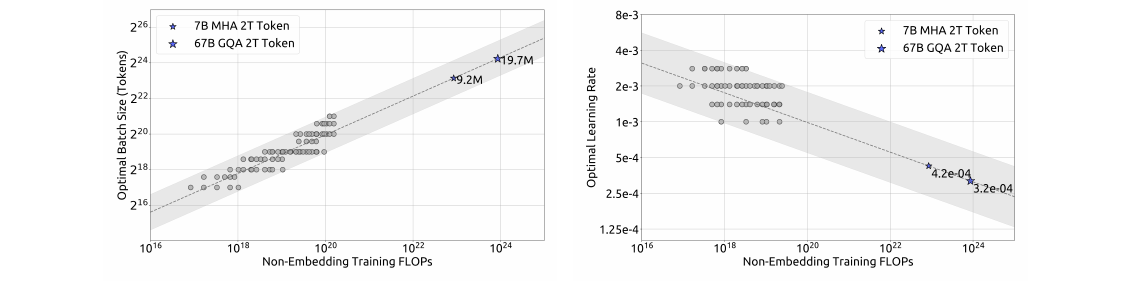{kind=link}
- 7B/67B 实测点落在 near-optimal 带内;$10^{20}$ 验证时拟合参数位于最优区中心(Figure 2b)
局限:尚未建模 $C$ 以外因素;同算力不同 model/data 分配下最优超参空间略有差异——待后续研究。→ Scaling-Law 选择性应用 §3
3.2 最优模型/数据 Scaling
传统写法用 $C \approx 6ND$,其中模型规模 $N$ 有两种常见取法:
| 符号 | 含义 | 来源 |
|---|---|---|
| $N_1$ | non-embedding 参数量 | Kaplan et al. |
| $N_2$ | 完整参数量(含 embedding) | Hoffmann et al. / Chinchilla |
于是可用 $6N_1$ 或 $6N_2$ 近似「每 token 算力」。但两者都有明显误差:
- $6N_1$:不含 attention 的 $O(L^2)$ 计算开销;
- $6N_2$:多了 vocab 投影(对模型能力贡献小),仍不含 attention。
为此报告引入 $M$(non-embedding FLOPs/token):计入 attention,不计 vocab;算力预算简化为 $C = M \cdot D$。
Formula 2 — 三种表示的关系:
$$ \begin{aligned} 6N_1 &= 72 \cdot n_{\mathrm{layer}} \cdot d_{\mathrm{model}}^2 \ 6N_2 &= 72 \cdot n_{\mathrm{layer}} \cdot d_{\mathrm{model}}^2 + 6 \cdot n_{\mathrm{vocab}} \cdot d_{\mathrm{model}} \ M &= 72 \cdot n_{\mathrm{layer}} \cdot d_{\mathrm{model}}^2 + 12 \cdot n_{\mathrm{layer}} \cdot d_{\mathrm{model}} \cdot l_{\mathrm{seq}} \end{aligned} $$
| 符号 | 含义 |
|---|---|
| $n_{\mathrm{layer}}$ | 层数 |
| $d_{\mathrm{model}}$ | 模型宽度 |
| $n_{\mathrm{vocab}}$ | 词表大小(V1 配置 102,400,见 BBPE 专文 §4) |
| $l_{\mathrm{seq}}$ | 序列长度 |
Table 3 — 不同规模下 $6N_1$、$6N_2$ 相对 $M$ 的偏差($n_{\mathrm{vocab}}=102400$,$l_{\mathrm{seq}}=4096$):
| $n_{\mathrm{layer}}$ | $d_{\mathrm{model}}$ | $N_1$ | $N_2$ | $M$ | $6N_1/M$ | $6N_2/M$ |
|---|---|---|---|---|---|---|
| 8 | 512 | 25.2M | 77.6M | 352M | 0.43 | 1.32 |
| 12 | 768 | 84.9M | 164M | 963M | 0.53 | 1.02 |
| 24 | 1024 | 302M | 407M | 3.02B | 0.60 | 0.81 |
| 24 | 2048 | 1.21B | 1.42B | 9.66B | 0.75 | 0.88 |
| 32 | 4096 | 6.44B | 6.86B | 45.1B | 0.85 | 0.91 |
| 40 | 5120 | 12.6B | 13.1B | 85.6B | 0.88 | 0.92 |
| 80 | 8192 | 64.4B | 65.3B | 419B | 0.92 | 0.94 |
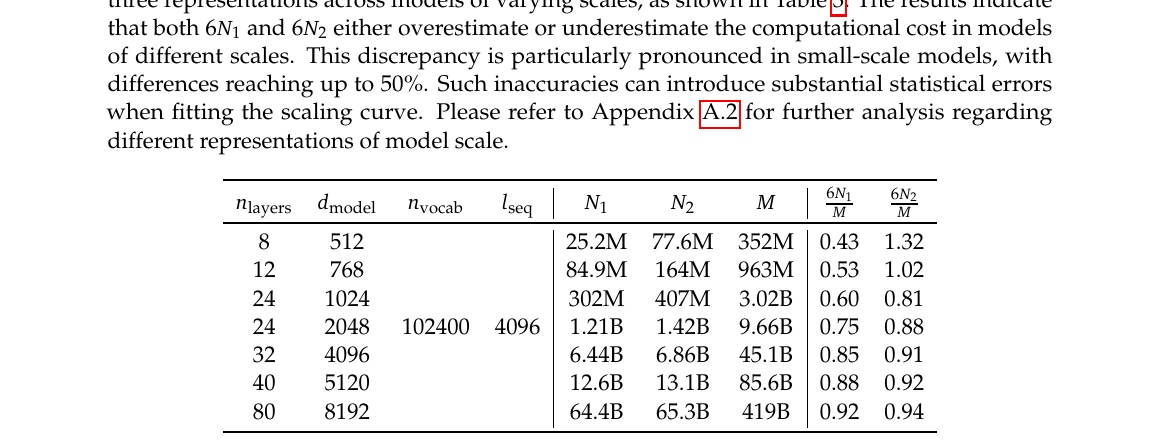
Table 3 — 模型规模三种表示的差异($N_1$、$N_2$ 相对 $M$ 的偏差)
{kind=link}
来源:Table 3。右两列 $6N_1/M$、$6N_2/M$ 越偏离 1,用 $6N$ 近似 $M$ 的误差越大。
怎么读 Table 3:
- $6N_1/M < 1$(小模型仅 0.43):$6N_1$ 低估算力,因缺 attention 项;层数少、$d$ 小时最明显。
- $6N_2/M > 1$(小模型 1.32):$6N_2$ 高估算力,因计入 vocab 投影。
- 模型变大后两列趋近 1,但小模型上偏差仍可达 50%,会污染 IsoFLOP 拟合——故 Formula 4 统一用 $M$ 而非 $6N_1$/$6N_2$。
采用 IsoFLOP profile(Chinchilla):8 个算力预算($10^{17}$–$3\times10^{20}$),每预算约 10 种 model/data 分配;超参由 Formula 1 确定;在 100M tokens 独立验证集上算 generalization error(bits-per-byte)。

Figure 4a — IsoFLOP 曲线(各算力档 loss 随 $M$ 呈 U 形,谷底 = 最优分配)
{kind=link}
来源:Figure 4a。横轴 = non-embedding FLOPs/token $M$;纵轴 = validation bits-per-byte。
Formula 4 — 最优 model/data 分配:
$$ \begin{aligned} M_{\mathrm{opt}} &= 0.1715 \cdot C^{0.5243} \ D_{\mathrm{opt}} &= 5.8316 \cdot C^{0.4757} \end{aligned} $$
| 符号 | 含义 |
|---|---|
| $M_{\mathrm{opt}}$ | 最优 non-embedding FLOPs/token |
| $D_{\mathrm{opt}}$ | 最优训练 token 总量 |
→ 模型与数据规模随算力近似等比扩展(指数 $a \approx b \approx 0.5$)。
Formula 4 数值对照:
| $C$ | $M_{\mathrm{opt}}$ (FLOPs/tok) | $D_{\mathrm{opt}}$ | 备注 |
|---|---|---|---|
| $10^{17}$ | $1.4\times10^{8}$ | 0.71B | |
| $10^{18}$ | $4.7\times10^{8}$ | 2.1B | |
| $10^{19}$ | $1.6\times10^{9}$ | 6.4B | |
| $10^{20}$ | $5.3\times10^{9}$ | 19B | |
| $8.5\times10^{22}$ | $4.2\times10^{10}$ | 2.0T | DeepSeek 7B @ 2T |
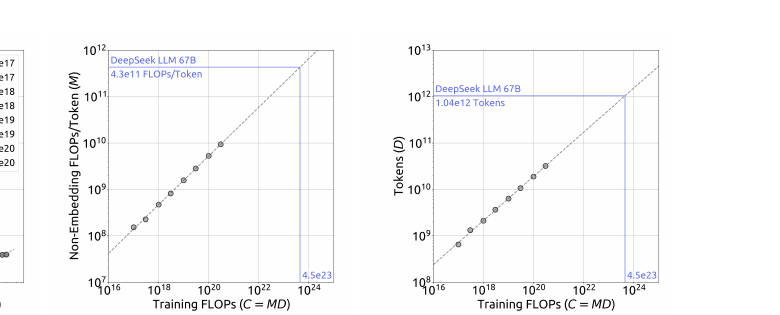
Figure 4b/4c — 最优 model / data scaling
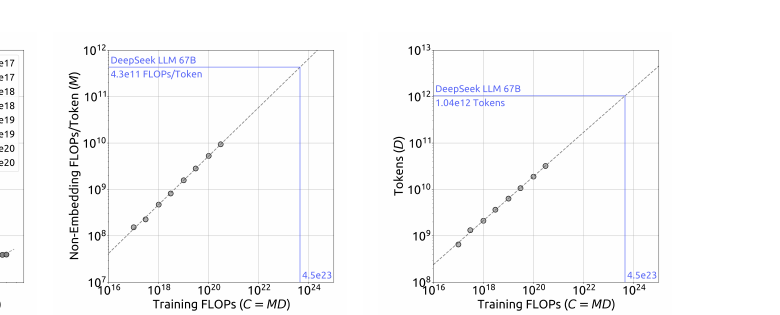{kind=link}
来源:Figure 4b/4c。左:$M_{\mathrm{opt}}$ vs $C$;右:$D_{\mathrm{opt}}$ vs $C$。
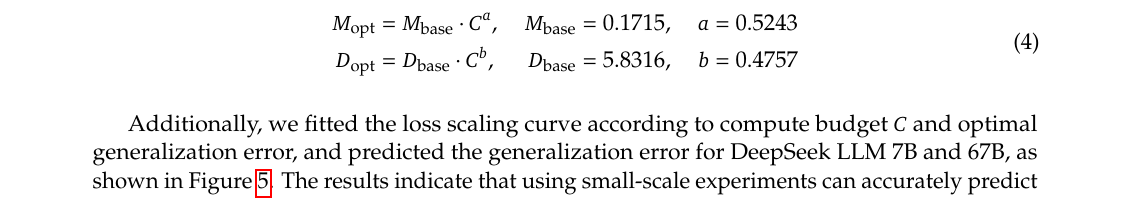
Figure 5 — 性能 scaling 曲线(小实验预测 7B/67B)
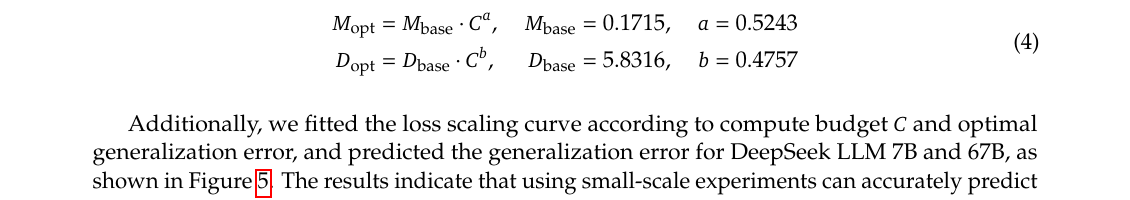{kind=link}
来源:Figure 5。灰点 = 小算力实验;虚线 = loss 幂律拟合;蓝星 = DeepSeek LLM 7B / 67B(各 2T tokens)。
小实验可准确预测 1000× 算力下 7B/67B 性能。
读图提示:Figure 3/5 蓝星 = 给定产品 $(M,D=2T)$ 校验 hyperparam / loss;Figure 4 = 固定 $C$ 下最优 $M/D$ 分配(未用于 Table 2 定 2T)。详见 Scaling-Law 选择性应用。
3.3 不同数据上的 Scaling Laws
DeepSeek LLM 开发过程中语料迭代多轮:调整各数据源占比、提升整体质量。借此可分析数据集差异对 scaling laws 的影响。
在三种语料上分别拟合 Formula 4 的指数 $a$($M_{\mathrm{opt}} \propto C^a$)与 $b$($D_{\mathrm{opt}} \propto C^b$):
- 早期内部数据 vs 当前内部数据(质量逐步提升)
- OpenWebText2(Kaplan et al. 用过的公开集;规模较小、处理更精细,质量甚至高于当前内部数据)
Table 4 — 模型/数据 scaling 系数随训练数据分布而变:
| 数据集 | 模型指数 $a$ | 数据指数 $b$ |
|---|---|---|
| OpenAI OpenWebText2 | 0.73 | 0.27 |
| Chinchilla MassiveText | 0.49 | 0.51 |
| Ours 早期 | 0.450 | 0.550 |
| Ours 当前 | 0.524 | 0.476 |
| Ours on OpenWebText2 | 0.578 | 0.422 |
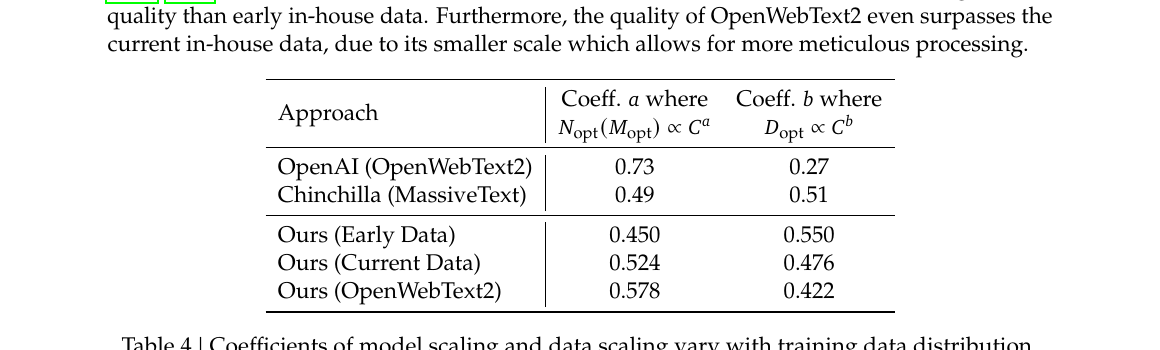
Table 4 — 模型/数据 scaling 系数随训练数据分布而变
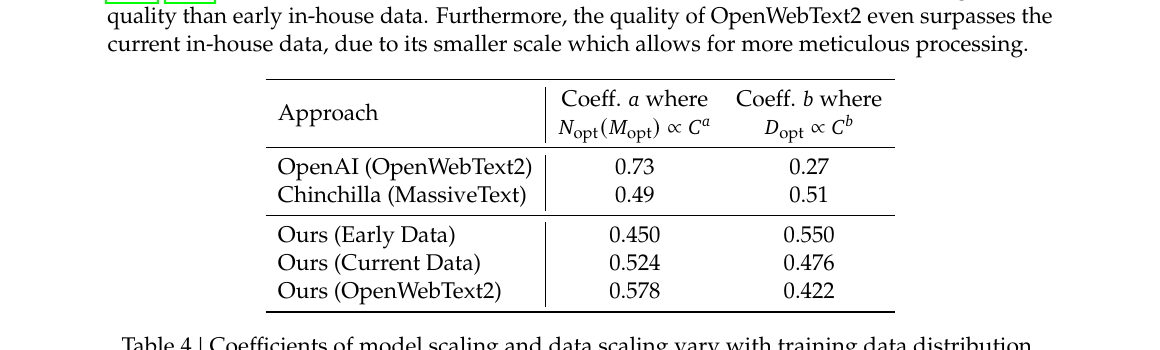{kind=link}
来源:Table 4。$a$ 越大 → 算力应多投模型;$b$ 越大 → 算力应多投数据。
数据质量越高 → $a$ 越大、$b$ 越小 → 应多分配算力给模型扩展。高质量数据逻辑清晰、充分训练后预测难度低,扩大模型更有利。不同数据集的 scaling 指数差异也可作为数据质量间接指标——这或许也是早期 scaling law 研究结论不一致的原因之一。
4. 对齐
4.1 数据
约 150 万 中英 instruction 实例:
- Helpful(120 万):通用 31.2% / 数学 46.6% / 代码 22.2%
- Safety(30 万):各类敏感话题
4.2 SFT
| 7B | 67B | |
|---|---|---|
| Epochs | 4 | 2(67B 过拟合严重) |
| LR | 1e-5 | 5e-6 |
- 7B:GSM8K、HumanEval 持续提升;67B 很快触顶
- 监控 repetition ratio:3868 条中英 prompt,统计无法终止、无限重复的比例
- 数学 SFT 增多 → repetition ratio 上升(推理模式相似,弱模型难学)
- 缓解:两阶段 SFT(第二阶段去掉 math/code)或 DPO
7B 两阶段 SFT:stage-1 repetition 2.0% → stage-2 1.4%
4.3 DPO
- 基于 helpfulness / harmlessness 构建 preference 数据
- Helpful:多语言 prompt(创作、QA、指令遵循等),用 DeepSeek Chat 生成候选回复
- 1 epoch,LR 5e-6,batch 512,warmup + cosine LR
- 效果:增强开放域生成;标准 benchmark 变化不大
5. 评测
5.1 公开 Benchmark
数据集覆盖:
- 多选:MMLU, C-Eval, CMMLU
- 语言理解/推理:HellaSwag, PIQA, ARC, OpenBookQA, BBH
- 闭卷 QA:TriviaQA, NaturalQuestions
- 阅读:RACE, DROP, C3
- 指代:WinoGrande, CLUEWSC
- LM:Pile
- 中文:CHID, CCPM
- 数学:GSM8K, MATH, CMath
- 代码:HumanEval, MBPP
- 考试:AGIEval
评测方式:
| 方式 | 适用任务 |
|---|---|
| Perplexity 选题 | HellaSwag, MMLU, C-Eval 等多选题 |
| 生成式(greedy) | GSM8K, HumanEval, BBH 等 |
| LM(bits-per-byte) | Pile-test |
最大序列长度 2048 或 4096。
5.1.1 Base 模型
- 2T 双语预训练,英文理解与 2T 英文 LLaMA-2 相当
- 67B 在 MATH、GSM8K、HumanEval、MBPP、BBH、中文 benchmark 上显著优于 LLaMA-2 70B
- 67B 相对 LLaMA-2 70B 的优势 大于 7B 相对 7B——语言冲突对小模型影响更大
- LLaMA-2 在部分中文任务(如 CMath)表现不错——数学推理可跨语言迁移;但 CHID(成语)等需足够中文 tokens
5.1.2 Chat 模型
- SFT 后多数任务提升
- 知识类(TriviaQA, MMLU):小幅波动,不代表 SFT 增删知识;Chat 0-shot 可比 Base 5-shot
- 推理类:SFT 含 CoT 格式,BBH 等略升——主要是学会推理格式而非新推理能力
- 下降任务:HellaSwag 等完形/句补——纯 LM 更擅长
- 数学/代码:HumanEval、GSM8K 等提升 20+ 点——Base 在这些任务上欠拟合,SFT 补充知识;能力可能偏代码补全与代数题
5.2 开放评测
5.2.1 中文 — AlignBench
683 题,8 大类 36 小类;GPT-4 按参考答案与模板打分。
- DeepSeek 67B Chat 超越 ChatGPT 等基线,仅次于两版 GPT-4
- DPO 版几乎全面提升
- 中文基础语言:DPO 版甚至高于最新 GPT-4;中文推理:显著领先其他中文 LLM
5.2.2 英文 — MT-Bench
8 类多轮对话。
- 67B Chat:8.35,与 GPT-3.5-turbo 可比;超越 LLaMA-2-Chat 70B、Xwin 70B、TÜLU 2+DPO 70B
- 67B Chat-DPO:8.76,仅次于 GPT-4
5.3 Held-Out 评测
在独立 held-out 集上 bits-per-byte 与 scaling 预测一致,验证 scaling laws 有效性。
5.4 安全评测
20 人专家团队,覆盖歧视偏见、侵犯合法权益、违法犯罪等类别。
- 多数子类 >95% 无害回复率(如歧视类 486/500,侵权类 473/500)
- 安全贯穿预训练、SFT、DPO 全流程
5.5 讨论
- 避免 benchmark decoration 与训练「暗箱」
- 双语训练在代码/数学/推理上的优势随规模放大
- SFT 数据配比(尤其数学)需与模型容量匹配
6. 结论、局限与未来工作
结论
DeepSeek LLM 是在 2T 中英 tokens 上从零训练的开源系列。本文详述超参选择、scaling laws 与微调经验;校准既往 scaling laws,提出新的最优 model/data 分配策略;给出给定算力下 near-optimal batch/LR 的预测方法;并指出 scaling laws 与数据质量相关——可能是不同工作 scaling 行为差异的根因。在 scaling laws 指导下完成预训练与全面评测。
局限
- Chat 模型无预训练后持续知识更新
- 可能生成非事实内容、幻觉
- 初版中文数据不 exhaustive,部分中文话题表现欠佳
- 语料以中英为主,其他语言需谨慎使用
未来
- 发布代码智能与 MoE 技术报告(高质量代码预训练数据、稀疏架构达稠密性能)
- 构建更大更好数据集,提升推理、中文知识、数学、代码
- 对齐团队研究 helpful/honest/safe;初步实验表明 RL 可提升复杂推理
附录概要
| 附录 | 内容 |
|---|---|
| A.1 | 致谢 |
| A.2 | 不同模型规模表示(N1/N2/M)分析 |
| A.3 | Benchmark 指标随训练曲线 |
| A.4 | 与代码/数学专用模型对比 |
| A.5 | DPO 阶段 benchmark 结果 |
| A.6 | 各 benchmark 评测格式细节 |
相关文档
- 版本演进总览 · 《ds-技术报告》§3.1 V1
- BBPE 词表与 Tokenizer 专文(§2.1 Tokenizer;预分词 / 102,400 embedding)
- V1→V3 演进
- Scaling 专题(本仓答疑)
- 产品训练 vs Scaling Law:7B/67B 为何都训 2T?
- Scaling-Law 选择性应用(Figure 3/4/5 分工)
- Scaling 答疑(Formula 1/4 推导)
- 学习率调度(§2.3 multi-step vs cosine)
- 中文结构化译文
- 技术要点提炼
- 索引
- 英文原文
- H20 八卡 Scaling Law 实验设计(Figure 3 / Formula 4 / Figure 5 拟合配置)
DeepSeek-LLM V1:BBPE 词表与 Tokenizer
← 中文导读 · ← 仓库首页(EN) · ← V1 正文 · ← 演进总览 §3.1 V1 · V1→V3 演进 论文:DeepSeek-LLM arXiv:2401.02954 §2.1 · V2 沿用同词表
一句话
DeepSeek-LLM V1 采用 BBPE(Byte-level Byte-Pair Encoding):在 UTF-8 字节序列上做 BPE,配合 字符类预分词 与 数字单 digit 拆分;常规词表 100,000,加 15 个 special token 后 100,015,模型 embedding 维配置 102,400 以预留扩展位。
BPE 简述
Byte Pair Encoding(BPE) 是 subword 分词里最常用的训练式词表构造法之一(Sennrich et al., 2016;GPT-2 / RoBERTa 系广泛采用)。相对词级分词,它在 词表大小 与 序列长度 / OOV 之间折中:常见片段共享 id,罕见词由若干 subword 拼成,无需 <unk>。
训练:
- 初始符号表 = 基础单元(字符、或 字节 —— 见下节 BBPE)
- 重复:统计当前序列中 相邻 symbol pair 的频率,将最高频 pair 合并为新 symbol,写入词表
- 达到目标 merge 次数或词表大小 $V$ 后停止
编码:对输入做同样的预切分后,按 merge 优先级 贪心最长匹配(或等价 trie 查表),得到 token id 序列。解码为 merge 的逆过程:id → subword 字符串 → 拼接还原文本。
| 方法 | 与 BPE 的关系 | 典型场景 |
|---|---|---|
| BPE / BBPE | 频率驱动 merge | GPT-2、LLaMA、DeepSeek V1 |
| WordPiece | 选 merge 时最大化语言模型似然 | BERT |
| Unigram LM | 从大词表 删 子词(SentencePiece) | T5、部分多语模型 |
对已有 NLP 基础的读者:BPE 不建模语义,只压缩词表;预分词(pre-tokenization) 规则(空格、标点、CJK 边界等)往往比 merge 算法本身更影响中英混排质量。DeepSeek V1 在标准 BPE 之上把基础单元降到 UTF-8 字节,并约束字符类不跨类 merge —— 即下文 §2 BBPE。
1. 与预训练数据管线的关系
Tokenizer 训练语料来自 V1 三阶段数据管线 的多语言子集(与 V1 §2.1 数据 / #tokenizer 同一论文段落):

{kind=link}
| 阶段 | 与 Tokenizer 相关的要点 |
|---|---|
| 去重 | 跨 Common Crawl 91 个 dump 全局去重,去重率 89.8%(单 dump 内仅 22.2%) |
| 过滤 | 语言 + 语义质量 |
| 重混 | 提升低占比 domain,保证多语言多样性 |
BBPE 本身在约 24GB 多语言语料 上训练 merge 规则;2.0T tokens 的预训练则走完整管线后再分词。
2. BBPE 是什么
BBPE = 在 字节(byte)序列 上运行 BPE,而非 Unicode 字符或 SentencePiece 的 pretokenized 单元。
| 对比 | 典型做法 | V1 BBPE |
|---|---|---|
| 词表基础 | 字符 / 子词 | UTF-8 字节 → 合并为 subword |
| OOV | 需 unk 或 fallback | 任意 UTF-8 文本可 字节级覆盖 |
| 实现 | 多种 | HuggingFace tokenizers 库 |
直觉:先 text → bytes,再在 byte 序列上统计 pair 频率、迭代 merge,得到 subword 词表。
示意说明:预分词后文本变为 UTF-8 字节流;初始符号表为 256 个字节;每轮合并语料中最高频 相邻 byte pair,写入 merge 表;重复至 100,000 次 merge。推理时对同样预切分后的字节序列 贪心最长匹配。因任意 UTF-8 文本可先落到字节层,不会出现字符级 OOV(罕见片段至多拆成更多 byte/subword token,序列变长而非 <unk>)。
图上
48 69、E4 B8 96是十六进制记法,不是单独一套「16 进制词表」。实现里每个符号是 8-bit 字节 $b \in {0,\ldots,255}$(即0x00–0xFF);48= 十进制 72 ='H',69='i'。E4 B8 96等为 中文等 CJK 字符在 UTF-8 下的 3 字节编码示意。HuggingFace tokenizers 在内部用u8序列做 merge/encode。
3. 预分词规则
论文在 BPE 合并前做 pre-tokenization,限制 不同字符类之间不得跨类 merge(做法类似 GPT-2):
| 规则 | 目的 |
|---|---|
| 换行 / 标点 / CJK 等分属不同字符类 | 避免中文与标点、换行被错误粘成单一 token |
| 数字拆成单 digit(同 LLaMA 系列) | 稳定算术、代码、编号类文本的 token 边界 |
效果:中英双语 + 代码混排时,CJK 与 Latin 边界清晰,数字可组合性更好。
4. 词表规模与 embedding 配置
| 项 | 数值 | 说明 |
|---|---|---|
| 常规 merge tokens | 100,000 | BPE 训练目标词表大小 |
| Special tokens | +15 | 如 BOS/EOS/PAD 及任务相关控制符 |
| Tokenizer 总大小 | 100,015 | 100,000 + 15 |
模型 vocab_size(embedding 行数) | 102,400 | 训练与推理配置;预留未来 special / 扩展 token |
易混点:HF
config.json里的vocab_size=102400是 embedding 矩阵行数;有效 token id 仍以 tokenizer 的 100,015 为准,未用 id 对应 embedding 行可视为预留。
5. 编码流程

{kind=link}
与后续 MLA / MoE / DSA 正交:改 attention 或 FFN 不改变 tokenizer;V1 Chat 的 SFT/DPO 也在同一词表上继续。
6. 在 DeepSeek 系列中的延续
| 版本 | Tokenizer 相对 V1 |
|---|---|
| V1(7B/67B) | 定义 BBPE 词表(本文) |
| V2 | 沿用 DeepSeek 67B 同一 tokenizer(2405.04434);8.1T 预训练 |
| V3 | 仍 BBPE 族,扩展至 128K 词表;pretokenizer 与训练语料针对多语言压缩优化(2412.19437 §4.1) |
| V3.2 / R1 | 与 V3 同词表 |
| V4 | 随新旗舰再扩展(DeepSeek-V4 梗概 训练节) |
V1 的 102,400 embedding 预留 与 V3 的 128K 扩展 是不同代际决策;读 checkpoint 时须对齐 config.vocab_size 与 tokenizer 文件。
7. 推理 infra 关注点
| 项 | V1 |
|---|---|
| 与 MLA 兼容性 | V1 为 标准 MHA/GQA,无 MLA;词表独立问题 |
| 引擎配置 | 常规 Transformers / vLLM;加载 deepseek-llm-7b-base 等官方权重即可 |
| 上下文 | 4K;tokenizer 无 RoPE,位置在模型侧 |
| 续训 / 扩词表 | 若新增 token,须 扩 embedding + lm_head 并重训或至少微调新增行 |
参考
- DeepSeek-AI. DeepSeek LLM: Scaling Open-Source Language Models with Longtermism. arXiv:2401.02954, 2024. — §2.1 Data, Tokenizer; Table 1 dedup.
- DeepSeek-V2:同 tokenizer(§2 / Appendix 数据节)。
- 本地精读:V1 §2.1 Tokenizer · technical-highlights(复现向)
DeepSeek-V2 梗概
← 中文导读 · ← 仓库首页(EN) · ← 演进总览 §3.2 · ← MoE 线导读 · ← 版本目录 · V1→V3 演进 · MLA 详解 · V1 BBPE 词表 · Raschka 解读
定位
2024 年 5 月发布。相对 DeepSeek-LLM 67B 稠密,V2 是架构代际跃迁:首次引入 MLA 与 DeepSeekMoE,236B 总参、每 token 激活 21B,128K 上下文。论文称相对 67B 稠密:训练成本 -42.5%、KV cache -93.3%、生成吞吐 5.76×。
核心架构
| 组件 | 要点 |
|---|---|
| MLA | K/V 低秩 latent 联合压缩进 cache;V3/R1/V3.1/V3.2 沿用同一 MLA 结构 |
| DeepSeekMoE | 每层 160 routed + 2 shared experts,每 token 激活 6 个 routed |
| 规模 | 236B total / 21B activated |
| 上下文 | 128K(Lite 版 16B / 2.4B act,32K) |
| 预训练 | 8.1T tokens |
| Tokenizer | 沿用 V1 DeepSeek 67B 同一 BBPE 词表(100K + special,embedding 102,400) |
| 后训练 | SFT + RL → Chat 版 |
相对 V1 的关键变化
| 维度 | V1(67B 稠密) | V2 |
|---|---|---|
| FFN | 稠密 SwiGLU | MoE 稀疏激活 |
| 注意力 | GQA(8 KV 头) | MLA latent KV |
| 上下文 | 4K | 128K |
| 预训练 | 2T | 8.1T |
| KV cache | 标准 GQA | ~6.7% 体积 |
推理 infra 关注点
- KV cache 变为 MLA latent 格式(后续 V3 系继承)
- 需自定义 kernel / vLLM 适配(DeepSeek 后续提供 FlashMLA 等)
- MoE 路由为 softmax 系(V3 改为 aux-loss-free sigmoid 路由,见 aux-loss-free)
| 方向 | 文档 |
|---|---|
| MoE 架构 | DeepSeekMoE 详解 |
| 本版本 | V2 为 DeepSeekMoE 首发落地(见上表配置) |
| 下游 ③ aux-loss-free | aux-loss-free MoE 路由 · DeepSeek-V3 |
上下游
| 方向 | 关系 |
|---|---|
| 上游 | DeepSeek-LLM V1(稠密 + scaling laws) |
| 下游 | DeepSeek-V3:671B / 37B act、256 experts / 8 act、MTP、aux-loss-free、14.8T |
参考
- 论文:arXiv:2405.04434
- 仓库:deepseek-ai/DeepSeek-V2
- MLA 前向:MLA前向计算流程§流程图 · 公式详解
DeepSeek-V3.1 梗概
← 中文导读 · ← 仓库首页(EN) · ← 演进总览 §3.5 · ← 版本目录 · Raschka §3.4 Hybrid
定位
2025 年中期在 V3 权重基础上做 post-training,无架构变更。主要贡献是 Hybrid 推理模式:同一套权重可在 thinking(推理链)与 chat(直接回答)之间切换,不再像 V3/R1 那样 Base 与推理模型分离。
V3.1-Terminus 是 V3.1 系列收尾 checkpoint,上下文扩至 128K,并作为 V3.2 继续预训练 的起点。
相对 V3 的变化
| 维度 | V3 | V3.1 |
|---|---|---|
| 推理模式 | Base / R1 分离 | Hybrid 单模型双模式 |
| 上下文 | 128K | 128K(续训巩固) |
| Agent / Tool Use | 较弱 | BrowseComp、SWE 等明显加强 |
| 架构 | MoE + MLA + MTP | 完全相同 |
MLA 模式切换
为后续 DSA 铺路,Prefill 与 Decode 采用不同 MLA 模式:

{kind=link}
- Prefill:MHA 模式(各 query head 独立 latent)
- Decode:MQA 模式(latent 在 query head 间共享)
两阶段 仍是 MLA(低秩 latent 进 cache);差别在 latent 按 head 展开还是全体共享。与常见注意力族的对应(以 8 个 Q head 为例):
| 族 | Q head 到 KV/latent | V3.1 对应 |
|---|---|---|
| MHA | 8 到 8 | Prefill 近似这一档 |
| GQA | 8 到 2(分组) | 不是 Decode 这一档 |
| MQA | 8 到 1 | Decode 近似这一档 |
| 阶段 | MLA 内的展开 | 瓶颈 | 取舍 |
|---|---|---|---|
| Prefill | per-head latent(MHA 式) | 算力 | 并行吃 prompt,表达力优先 |
| Decode | shared latent(MQA 式) | KV 带宽 | 每步读全长 cache,体积优先 |
延伸:DSA 逻辑 · 演进总览 §V3.1
推理 infra 关注点
- 与 V3 相同:同质 MLA Latent-Cache
- 新增 Prefill MHA / Decode MQA 切换逻辑,引擎需正确实现两阶段模式
- KV offload 困境与 V3 相同:格式非标准,长上下文仍受 HBM 限制
上下游
| 方向 | 关系 |
|---|---|
| 上游 | DeepSeek-V3 |
| 下游 | V3.2-Exp / V3.2(在 Terminus 上引入 DSA) |
参考
- 外部解读:Raschka V3→V3.2 梗概 · 全文解析 · 原文
- 仓库:deepseek-ai/DeepSeek-V3(V3.1 权重见 HuggingFace 发布页)
DeepSeek-V3.2 梗概
← 中文导读 · ← 仓库首页(EN) · ← 演进总览 §3.6 · ← 版本目录 · DSA 梗概 · Raschka §4 DSA
定位
2025 年 12 月正式版;2025 年 9 月先有 DeepSeek-V3.2-Exp(DeepSeek 官方实验 release)。相对 V3.1-Terminus,唯一架构改动是引入 DeepSeek Sparse Attention (DSA)——DeepSeek 原创稀疏注意力,在长上下文场景显著降算量,公开 benchmark 与 V3.1-Terminus 基本持平。
V3.2-Exp 与 V3.2 架构相同;Exp 用于验证稀疏注意力不损精度,V3.2 为完整续训 + 后训练成品。
DSA 机制
两阶段稀疏注意力:
- Lightning Indexer:廉价点积为历史 token 打分(仍 $O(L^2)$,但 head 维极低)
- Top-$k$ Selector:选出 $k=2048$ 个最重要 latent entry
- Core Attention:仅对 top-$k$ 做 MLA attention($O(Lk)$)
概念:Lightning Indexer · Top-$k$ Selector · Core MLA · Indexer-Cache · Latent-Cache · ESS
异构 Cache
| Cache 类型 | 作用 | 占比(ESS 论文) | Offload |
|---|---|---|---|
| Indexer-Cache | 算重要性、选 top-$k$ | ~16.8% | 否(每步全算) |
| Latent-Cache | 核心 MLA attention KV | ~83.2% | 可 ESS offload |
推理 infra 关注点
- DeepGEMM:indexer logit kernel(含 paged 版)
- FlashMLA:sparse attention paged kernel
- Index Share(IndexCache)与 ESS offload 均叠加在 V3.2 上
- vLLM day-0 support;需自定义 sparse attention 代码路径
规格
| 项 | 值 |
|---|---|
| 参数量 | 671B(同 V3.1-T) |
| 激活参数 | 37B |
| 上下文 | 128K |
| 发布时间 | Exp 2025-09,正式版 2025-12 |
上下游
参考
- 外部解读:Raschka V3→V3.2 梗概 · §4 DSA / §6 GRPO 全文表
- 论文:arXiv:2512.02556
- Exp:deepseek-ai/DeepSeek-V3.2
- ESS offload:ESS Latent offload · arXiv:2512.10576
- Index Share:Index Share 梗概
DeepSeek-V4 梗概
← 中文导读 · ← 仓库首页(EN) · ← 演进总览 §3.7 · ← 算法线导读 · ← 基础设施线导读 · ← MoE 线导读 · Hash MoE + FP4 详解 · Muon 详解 · ← 版本目录 · CSA/HCA 详解 · DSpark 投机解码 · 上游 DSA · 上游 MLA · mHC 详解 · Raschka §8 mHC
定位
2026 年 preview release,面向 百万 token 上下文与 Agentic Coding(100K–1M token 代码库、多轮 tool trace)。相对 V3.2 是架构级大步进:注意力、残差、优化器、MoE 路由、量化同时翻新,不利于做单一变量 ablation。
两个规格:
| 模型 | 总参数 | 激活参数 | 定位 |
|---|---|---|---|
| V4-Pro | 1.6T | 49B | 能力上限,含 Pro-Max 推理模式 |
| V4-Flash | 284B | 13B | 效率优先 |
核心架构变化
| 组件 | 说明 |
|---|---|
| CSA / HCA | 混合压缩注意力专文:CSA 4:1 + top-$k$;HCA 128:1 + dense |
| mHC | Manifold-Constrained Hyper-Connections(§3 双随机流形):Sinkhorn–Knopp 投影,恢复 HC 恒等映射稳定性 |
| Muon | Muon 优化器专文:矩阵正交化更新,更快收敛 |
| Hash MoE / FP4 | Hash MoE + FP4 专文:前几层 Hash 路由 + routed expert FP4 + QAT |
继承自 V3:DeepSeekMoE 框架、MTP 配置。

{kind=link}
MoE 线位置
| 方向 | 文档 |
|---|---|
| MoE 线 ⑤ Hash MoE + FP4 | Hash MoE + FP4 |
| MoE 线 hub | MoE 线导读 |
| 上游 ③④ | aux-loss-free MoE 路由 · DeepSeek-V3 |
1M context 效率
| 模型 | 单 token FLOPs | 累计 KV cache |
|---|---|---|
| V4-Pro @ 1M | 27% | 10% |
| V4-Flash @ 1M | 10% | 7% |
推理 infra 关注点
V4 的 cache 异构,不再是单一 MLA latent:
| KV 类型 | 特点 |
|---|---|
| CSA 压缩 entry | 4:1,稀疏 top-$k$ |
| HCA 压缩 entry | 128:1,dense |
| SWA | 滑动窗口,独立 eviction |
| Indexer KV | CSA lightning indexer |
| Tail buffer | 未凑满压缩块的尾 token |
KV layout→ 专文:V4 KV Layout(Classical + State 双池;演进总览 §5.3)
HiSparse → 专文:V4 HiSparse(inactive C4 offload;§5.3)
磁盘 Prefix Cache→ 专文:V4 磁盘 Prefix Cache(SWA 三档策略;§5.3)
Decode 吞吐:V4 预览引擎 → 投机解码与 DSpark 专文(含 MTP、MTP-1 基线、DSpark;与 HiSparse 正交)。
V4 的 KV-offload 与 V3.2 ESS 完全不同,需围绕异构压缩 cache 重新设计内存层级。
基础设施线位置
| 方向 | 文档 |
|---|---|
| 本节点(⑤ V4 异构 KV + HiSparse) | 基础设施线导读 §1 · KV layout · HiSparse · 磁盘 prefix |
| 上游 ②–④ | DSA 稀疏注意力 · Index Share 梗概 · ESS Latent offload |
| 算法线 ③ CSA/HCA | CSA / HCA · 算法线导读 |
| MoE 线 ⑤ Hash MoE | Hash MoE + FP4 · MoE 线导读 |
训练要点
- 32T+ tokens,渐进式上下文:4K dense → 16K → 64K 引入稀疏 → 1M
- 后训练:分域专家独立培养 + on-policy distillation 合并
算法线位置
上下游
| 方向 | 关系 |
|---|---|
| 上游 | V3.2(DSA 思想延续为 CSA 内嵌 indexer;算法线导读) |
| 并行 | Index Share 解决 V3.2 长上下文 indexer 瓶颈,与 V4 路线互补 |
参考
- 论文:arXiv:2606.19348
- 部署解读:Together.ai — Serving DeepSeek-V4
- HuggingFace:deepseek-v4 collection
CSA / HCA 混合压缩注意力
← 中文导读 · ← 仓库首页(EN) · ← 演进总览 §3.7 · ← 算法线导读 · ← 基础设施线导读 · V4 梗概 · 上游 DSA · 上游 MLA · 并列 mHC · Lightning Indexer 详解 论文:DeepSeek-V4 arXiv:2606.19348
一句话
CSA(Compressed Sparse Attention)与 HCA(Heavily Compressed Attention)是 V4 的 双档 KV 压缩注意力:先把历史 token 按块压成更短的 KV 序列,再在压缩序列上分别做 稀疏 top-$k$(CSA,$m{=}4$)与 dense attend(HCA,$m'{=}128$);二者与 SWA、Indexer KV、tail buffer 共同构成 百万 token 的算法侧主因。
答疑:SWA(滑动窗口精确局部) — 最近窗口内未压缩 K/V,进 State 池,eviction 与 prefix 策略独立于 CSA/HCA 答疑:Indexer KV — CSA 路径上对全长历史廉价打分,再 top-$k$ 选 C4 entry 答疑:Tail buffer — 未凑满 4/128 块的 token 尾,凑满后才压入 Classical 池
算法线位置
| 方向 | 文档 |
|---|---|
| 本节点(③ CSA / HCA) | 算法线导读 §1 |
| 上游 ② DSA | DSA 稀疏注意力 · DSA 逻辑详解 |
| 上游 ① MLA | MLA 低秩注意力(V4 不再单一 per-token latent) |
| 同代 V4 其他组件 | DeepSeek-V4(两个规格、MoE) · Muon · mHC(残差路径,与 Attention 正交) |
| infra 依赖 | KV layout · HiSparse · 磁盘 prefix |
1. 两个机制对照
| 维度 | CSA | HCA |
|---|---|---|
| 全称 | Compressed Sparse Attention | Heavily Compressed Attention |
| 压缩比 | 每 $m{=}4$ token → 1 条 KV entry | 每 $m'{=}128$ token → 1 条 entry |
| 压缩后序列长 | $\approx L/4$ | $\approx L/128$(极短) |
| 注意力模式 | 对压缩 entry 做 DSA 式 top-$k$ 稀疏读 | 序列已足够短 → dense attention |
| 典型角色 | 远距、高选择性 历史(indexer 挑块) | 全局粗粒度 摘要(全 entry 参与) |
| Cache 别名 | C4 压缩层(infra 文档常用) | HCA 128:1 entry |
| 1M context 量级 | ~250K 条 C4 entry(再经 top-$k$ 只读子集) | ~8K 条 HCA entry |
读法:CSA 延续 DSA「先选再看」;HCA 把「看」的成本压到足够低,直接 全 attend 仍可行。
2. CSA:块压缩 + 稀疏注意力
2.1 流程
- Prefill / decode 过程中,每凑满 4 个 token 的块,经可学习压缩算子合成 1 条 CSA KV entry(不再 per-token 缓存全长 latent)。
- 当前 query 经 lightning indexer(思想延续 DSA / Lightning Indexer)在 $\sim L/4$ 条压缩 entry 上打分。
- 取 top-$k$ 条 entry 做 attention;复杂度相对全长 MLA 的 $O(L^2)$ 降为 $O(Lk)$ 量级($k$ 为压缩 entry 数,$k \ll L/4$)。
2.2 相对 DSA 的变化
| 维度 | DSA(V3.2) | CSA(V4) |
|---|---|---|
| KV 粒度 | 每 token 一条 MLA latent | 每 4 token 一条压缩 entry |
| Indexer 作用对象 | 全长 latent 序列 | 更短的压缩序列 |
| MLA 结构 | Core MLA 不变 | V4 新注意力栈,非 V3.2 MLA 直扩 |
DSA 的「indexer + top-$k$ + 主 attention」范式 延续;V4 在 indexer 之前增加 固定 stride 块压缩,进一步压 cache 体积与 indexer 扫描长度。
3. HCA:重压缩 + 短序列 dense
3.1 流程
- 每 128 token 合成 1 条 HCA KV entry(压缩比远高于 CSA)。
- 序列长度 $\approx L/128$:1M context 仅 ~8K entry,对当前 query 做 标准 dense attention(无需 top-$k$)。
- 提供 全局、低分辨率 的历史摘要,与 CSA 的 局部高精度稀疏块 互补。
3.2 为何不用稀疏
HCA 的设计前提是:128:1 压缩后 entry 数 足够少,dense matmul 的 FLOPs 与带宽仍低于「对 $L/4$ 条 CSA entry 做 sparse 路径 + indexer」;相当于用 更粗粒度 换 更简单的读模式。
4. V4 内如何「混合」
V4 不是「全层 CSA 或全层 HCA」二选一,而是在同一模型中 组合多种 attention 路径:
| 对象 | 与 CSA/HCA 关系 |
|---|---|
| CSA C4 entry | 远距稀疏主路径;HiSparse offload 的 inactive 块 主要指此层 |
| HCA entry | 全局 dense 摘要路径 |
| SWA | 滑动窗口 精确局部 state;与压缩 entry 独立 eviction |
| Indexer KV | CSA 路径的 lightning indexer 向量;维度与主 entry 不同 |
| Tail buffer | 不足 4(CSA)或 128(HCA)token 的 未压缩尾;凑满后再入 Classical 池 |
内存布局→ V4 KV Layout 专文,算法对象与引擎池化的分界见该文 §1。
5. 相对 V3.2 的效率
V4 把 算力 与 KV 体积 同时压下来,CSA/HCA 是算法侧主因;infra 侧另需 HiSparse / 磁盘 prefix 才能「跑得动」1M。
| 模型 | 单 token FLOPs @ 1M(相对 V3.2) | 累计 KV cache @ 1M |
|---|---|---|
| V4-Pro | 27% | 10% |
| V4-Flash | 10% | 7% |
详见 DeepSeek-V4 梗概§1M context 效率。
6. 训练侧:渐进式上下文
V4 训练采用 渐进拉长上下文(DeepSeek-V4 梗概§训练要点):
- 4K dense 基座 → 16K → 64K 引入稀疏 → 1M
- CSA/HCA 与稀疏 indexer 在 中长上下文阶段 才全面启用;短上下文阶段可近似 dense 行为,便于稳定收敛。
7. 与 infra 线的关系
| infra 专题 | 依赖 CSA/HCA 的方式 |
|---|---|
| KV layout | Classical 池存 CSA/HCA 压缩块;State 池存 tail + SWA |
| HiSparse | 针对 C4 inactive entry 的 CPU offload |
| 磁盘 prefix cache | CSA/HCA 压缩 entry 可直接落盘;SWA 三档策略另计 |
| ESS | 不可直迁 — ESS 面向 V3.2 per-token latent |
完整 基础设施线 见 基础设施线导读。
8. 演进链小结

{kind=link}
| 边 | 关系 |
|---|---|
| MLA → DSA | MLA 结构不变;在 latent 序列上加稀疏选择 |
| DSA → CSA | 「先选再看」延续;先 块压缩 再 indexer |
| CSA ⊥ HCA | 互补档位:4:1 稀疏精细 vs 128:1 dense 粗摘要 |
| CSA/HCA ⊥ mHC | 前者改 Attention / KV;mHC 改 残差拓扑 |
9. 上下游
| 方向 | 文档 |
|---|---|
| 版本总览 | DeepSeek-V4(两个规格、MoE、训练要点) · Muon |
| 上游 | DeepSeek-V3.2 · DSA 稀疏注意力 |
| 并行(V3.2 infra) | Index Share 梗概 — 纯 infra,与 V4 路线 互补 |
| 同代残差 | mHC |
| 部署解读 | Together.ai — Serving DeepSeek-V4 |
参考
- 论文:arXiv:2606.19348
- HuggingFace:deepseek-v4 collection
Hyper-Connections
← 中文导读 · ← 仓库首页(EN) · ← mHC 主文档 · ← 算法线导读 · mHC §3 双随机流形 · V4 梗概 · Raschka §8 论文:mHC arXiv:2512.24880 §2(HC 为 mHC 前置)· 落地:V4 arXiv:2606.19348
一句话
Hyper-Connections(HC) 把 Transformer 每层 单条残差流 扩成 $n$ 条并行残差流,用可学习矩阵 pre / post / comb 在流与子层(Attention / FFN)之间混合;动机是 加宽残差信息高速公路,但无约束时 破坏恒等映射 → 深层信号可 指数放大,需 mHC 的 双随机流形 约束后才可大规模训练。
算法线位置
| 方向 | 文档 |
|---|---|
| 本文(HC 基础) | mHC 节点 前置概念;算法线 ④ 的上游 |
| 下游(约束版) | mHC(含 §3 双随机流形) |
| 正交模块 | CSA/HCA(Attention / KV)· MoE 线(FFN 路由) |
1. 标准残差 vs HC
1.1 标准 Transformer 残差
一层子模块(Attention 或 FFN)的典型写法:
$$ x_{l+1} = x_l + F_l(x_l) $$
| 性质 | 含义 |
|---|---|
| 单流 | 隐状态 $x_l \in \mathbb{R}^d$ 只有 一条 载体 |
| 恒等路径 | 即使 $F_l \approx 0$,仍有 $x_{l+1} \approx x_l$ |
| 深度可训 | 梯度可沿 $+x_l$ 直通 浅层 |
1.2 HC 改了什么
HC 不替换 Attention / FFN 内部算子,而是改 残差拓扑:
- 把每层隐状态扩成 $n$ 条并行残差流(扩展率 $n$,mHC / V4 常见 $n{=}4$);
- 子层 输入 由 $n$ 条流 加权汇聚 得到;
- 子层 输出 再 写回 $n$ 条流(可与原流 组合混合)。
直觉:$n$ 条并行「信息高速公路」,层间连接比单流残差 更丰富。

{kind=link}
2. 多路残差流
记第 $l$ 层、第 $t$ 个 token 处 $n$ 条残差流为:
$$ \mathbf{r}l = (r{l,1}, \ldots, r_{l,n}), \quad r_{l,i} \in \mathbb{R}^d $$
| 符号 | 含义 |
|---|---|
| $n$ | 扩展率(parallel stream count) |
| $r_{l,i}$ | 第 $i$ 条残差流上的隐状态切片(实现上常为 $d$ 维向量或 $d/n$ 维分片,依实现而定) |
| 初始化 | 通常由 embedding 或上一层输出 复制 / 投影 到 $n$ 路 |
相对单流 $x_l$,HC 在 宽度 上多了 $n$ 路,参数与激活的 读写模式 从「一条链」变成「$n$ 路网状混合」。
3. 三组混合矩阵
mHC 论文对每层子模块(Attention 或 FFN)使用 三组 可学习混合(裸 HC 为 无约束实矩阵;mHC 再投影到双随机流形):
| 矩阵 | 形状(直觉) | 作用 |
|---|---|---|
| $H^{\mathrm{pre}}$ | $1 \times n$(或列向量) | $n$ 条残差流 → 汇聚成子层输入 $\tilde{x}_l = \sum_i H^{\mathrm{pre}}i , r{l,i}$ |
| $H^{\mathrm{post}}$ | $n \times 1$ | 子层输出 $F_l(\tilde{x}_l)$ → 写入某条主流 的权重 |
| $H^{\mathrm{comb}}$ | $n \times n$ | 子层输出与 各路残差 的 组合混合(写回 $n$ 条流) |
另有层间或块级 $H_l^{\mathrm{res}}$($n \times n$)在 相邻层 / 子层之间 混合 $n$ 条流;深层复合 $\prod_l H_l^{\mathrm{res}}$ 是 不稳定性的主要来源(见 §5)。
4. 单层数据流
与 mHC 主文档 §4 及 vLLM MHCPreOp / MHCPostOp 对齐:
Pre(进 Attention / FFN 前)
- 对 $n$ 条残差流做 Norm(如 RMSNorm)。
- 由归一化后的流(及可选分支特征)算 mix logits → 得 $H^{\mathrm{pre}}$。
- 子层输入:$\tilde{x}_l = \sum_i H^{\mathrm{pre}}i \cdot r{l,i}$。
子层
$$ y_l = F_l(\tilde{x}_l) \quad (F_l = \text{Attention 或 FFN/MoE}) $$
Post(出子层后)
$$ r_{l+1,j} = H^{\mathrm{post}}j \cdot y_l + \sum_i H^{\mathrm{comb}}{ji} \cdot r_{l,i} $$
即:子层输出与各路残差按 post / comb 权重写回第 $l{+}1$ 层的 $n$ 条流。
| 阶段 | 单流残差 | HC |
|---|---|---|
| 输入 | $x_l$ 直连 $F_l$ | $n$ 路 先混合 再进 $F_l$ |
| 输出 | $x_l + F_l(x_l)$ | $F_l$ 输出 分流写回 $n$ 路 |
| 恒等性 | $F_l{=}0 \Rightarrow x_{l+1}{=}x_l$ | 一般 不成立(混合矩阵任意) |
5. 为何裸 HC 不稳定
| 问题 | 机制 |
|---|---|
| 恒等映射被破坏 | 即使 $F_l \approx 0$,$H^{\mathrm{pre/post/comb}}$ 仍可对 $n$ 路特征 重分配、放大 |
| 深层复合放大 | $\prod_l H_l^{\mathrm{res}}$ 若谱半径 $>1$,范数可 指数增长 |
| 论文观测 | 无约束 HC 可出现 ~3000× 量级信号放大,训练 万步级崩溃 |
标准残差把「子层增量」与「恒等捷径」 解耦;HC 把二者都变成 可学习线性混合,表达力↑,但 缺少保范数结构。
mHC 的修复:把上述混合矩阵 投影到双随机流形 $\mathcal{B}_n$,使混合变为 凸组合 / 加权平均 → 见 mHC §3。
6. HC 与 mHC、V4 的关系
| HC | mHC | |
|---|---|---|
| 残差拓扑 | $n$ 路并行 + 可学习混合 | 同 HC 拓扑 |
| 混合矩阵 | 无约束(或弱约束) | Sinkhorn–Knopp → 双随机 |
| 训练 | 大规模易不稳 | V4 / 论文报告可训可部署 |
| 文档 | 本文 | mHC |
| 版本 | HC / mHC |
|---|---|
| V3 / V3.2 | 无 HC、mHC |
| 独立论文 2512.24880 | 提出 HC + mHC |
| V4 | mHC 作为残差路径标准组件(与 CSA/HCA 等 正交) |
7. 与 Attention / MoE 的边界
| 模块 | HC 是否涉及 |
|---|---|
| MLA / DSA / CSA / HCA | 否 — 改 Attention 与 KV,不改残差拓扑 |
| MoE 路由 | 否 — HC 在子层 前后 混合残差流;expert 选择在 FFN 内部 |
| ESS / KV layout | 否 — infra 管 cache,不管残差宽化 |
HC 回答:残差路径加宽时如何连,不回答长上下文或稀疏注意力本身。
8. 上下游
| 方向 | 文档 |
|---|---|
| 下游 | mHC(§3 双随机流形) |
| 同代 V4 | DeepSeek-V4 · CSA/HCA |
| 外部解读 | Raschka §8 |
参考
- Xie et al. mHC: Manifold-Constrained Hyper-Connections. arXiv:2512.24880, 2025(§2 Hyper-Connections).
- DeepSeek-AI. DeepSeek-V4. arXiv:2606.19348, 2026.
- Raschka. From DeepSeek V3 to V3.2 — §8 mHC 附录.
mHC
← 中文导读 · ← 仓库首页(EN) · ← 演进总览 §3.7 · ← 算法线导读 · ← V4 梗概 · HC 基础 · Raschka §8 mHC 论文:mHC arXiv:2512.24880(2025-12-31)· 落地:V4 arXiv:2606.19348
一句话
mHC 在 Hyper-Connections(HC) 的多路残差流之上,用 Sinkhorn–Knopp 把残差混合矩阵投影到 双随机流形(Birkhoff 多面体),使层间信号混合等价于 凸组合 / 加权平均,从而 恢复恒等映射的稳定性;DeepSeek-V4 将其作为残差路径的标准组件。
答疑:HC(Hyper-Connections)基础 — $n$ 路并行残差流 + pre/post/comb 混合;裸 HC 破坏恒等映射,mHC 用双随机约束修复
1. 残差路径演进
| 阶段 | 做法 | 特点 |
|---|---|---|
| 标准残差 | $x_{l+1} = x_l + F_l(x_l)$ | 恒等路径清晰,深层可训 |
| Hyper-Connections (HC) | 扩宽残差流为 $n$ 条并行流,可学习混合 | 容量↑,但 破坏恒等映射 → 训练易爆(HC 专文) |
| mHC | HC + 流形约束(双随机混合矩阵) | 保留 HC 表达力,抑制信号放大 |
Raschka 扩展阅读 §8 · 表 8-1 归纳的 Transformer 模块演进链(节选)(要点速读):
| 模块 | 演进 |
|---|---|
| Attention | GQA → sliding window(SWA) → MLA → DSA → CSA/HCA |
| FFN | GeLU → SwiGLU → MoE |
| 残差 | 恒等残差(ResNet)→ HC → mHC |
算法线位置
| 方向 | 文档 |
|---|---|
| 本节点(④ mHC) | 算法线导读 §1 · HC 基础 · §3 双随机流形 |
| 同代 Attention | CSA / HCA · DeepSeek-V4 |
| Attention 上游 | MLA 低秩注意力 · DSA 稀疏注意力 |
2. Hyper-Connections基础
标准残差 → $n$ 路并行残差流 + pre / post / comb 混合 → 子层 Attention/FFN;裸 HC 破坏恒等映射,深层可出现 ~3000× 信号放大。
本节摘要
| 要点 | 说明 |
|---|---|
| 扩展率 | 常见 $n{=}4$(V4 / mHC 实验) |
| 混合 | $H^{\mathrm{pre}}$ 汇聚入子层;$H^{\mathrm{post}}$、$H^{\mathrm{comb}}$ 写回 $n$ 路 |
| 动机 | 加宽残差 信息高速公路 |
| 问题 | $\prod_l H_l^{\mathrm{res}}$ 无约束 → 训练易爆 → mHC(§3) |
3. mHC 核心:双随机流形约束
mHC 把 HC 的可学习混合矩阵 投影 到 双随机流形(Birkhoff 多面体 $\mathcal{B}_n$):非负、行和列均为 1 → 对 $n$ 条残差流做 凸组合,抑制无约束 HC 的 ~3000× 级信号放大,恢复深层 近似恒等映射 的稳定性。
3.1 双随机矩阵定义
设 $H \in \mathbb{R}^{n \times n}$。若同时满足:
$$ H_{ij} \ge 0 \quad \forall i,j; \qquad \sum_{j=1}^{n} H_{ij} = 1 ;; \forall i; \qquad \sum_{i=1}^{n} H_{ij} = 1 ;; \forall j $$
则称 $H$ 为 双随机矩阵(doubly stochastic matrix)。

{kind=link}
| 性质 | 含义 |
|---|---|
| 行随机 | 每一行是 $n$ 个非负数的 概率分布 |
| 列随机 | 每一列之和也为 1(比「仅行随机」更严) |
| 凸组合 | 对向量 $x$,$Hx$ 的每个分量都是 $x$ 各分量的 加权平均 |
极端点:置换矩阵 $P_\pi$(每行每列恰有一个 1)是双随机矩阵;其余双随机矩阵可写成置换矩阵的 凸组合(Birkhoff–von Neumann 定理)。
3.2 Birkhoff 多面体 = 「双随机流形」
所有 $n \times n$ 双随机矩阵的集合记为 Birkhoff 多面体 $\mathcal{B}_n$:
$$ \mathcal{B}n = \mathrm{conv},{, P\pi \mid \pi \in S_n ,} $$
即 $n$ 阶 置换矩阵 的 凸包。mHC 论文把 $\mathcal{B}_n$ 称为残差混合权重所在的 特定流形(manifold);工程语境下常口语化为 双随机流形。
答疑:Birkhoff 多面体(置换矩阵的凸包) — 双随机矩阵全体 = $\mathrm{conv}{P_\pi}$;mHC 把混合矩阵投影到此集合
训练时 HC 产生 无约束 logits $\tilde{H}$;mHC 用 Sinkhorn–Knopp(§3.4)把 $\tilde{H}$ 投影 到 $\mathcal{B}_n$ 的近似点 $H$。参数在 $\mathbb{R}^{n^2}$ 上优化,但 前向使用的混合矩阵 始终落在(或逼近)双随机集合——这就是 Manifold-Constrained 的含义。
3.3 为何 mHC 需要这个约束
HC 把每层残差扩成 $n$ 条并行流,用可学习矩阵 $H_l^{\mathrm{res}}$ 混合。若 不约束 $H_l^{\mathrm{res}}$:
- 复合映射 $\prod_{l=1}^{L} H_l^{\mathrm{res}}$ 的谱范数可 远大于 1
- 特征范数在深层 指数放大
- 训练在万步级 发散
标准残差 $x_{l+1} = x_l + F_l(x_l)$ 有清晰 恒等路径;无约束 HC 破坏了 这条保范数通道。
设 $n$ 条残差流向量堆叠为 $X \in \mathbb{R}^{n \times d}$,混合后第 $i$ 行:
$$ (X')i = \sum{j=1}^{n} H_{ij} X_j, \qquad H_{ij} \ge 0,; \sum_j H_{ij} = 1 $$
即 $(X')_i$ 是 ${X_j}$ 的 凸组合。由 Jensen / 三角不等式:
$$ |(X')i| \le \sum_j H{ij} |X_j| \le \max_j |X_j| $$
单层混合不会把范数放大到超过输入流的最大范数;多层复合时,信号仍被 凸组合 反复「平均」,近似 保范数恒等映射。
| 混合矩阵类型 | 对范数的影响 | 深层复合 |
|---|---|---|
| 无约束 $H$ | 可任意缩放 / 旋转 | 易指数放大 |
| 双随机 $H$ | 凸组合,不增最大流范数 | 近似稳定 |
3.4 Sinkhorn–Knopp 投影
给定非负矩阵 $K$(通常由 logits 经 $\exp$ 得到),交替 行归一化 与 列归一化:
$$ K \leftarrow \mathrm{diag}(r)^{-1} K \mathrm{diag}(c)^{-1} $$
迭代若干步(vLLM 中 sinkhorn_repeat;数值稳定项 hc_sinkhorn_eps)后,$K$ 逼近双随机 $H \in \mathcal{B}_n$。
mHC 对 三组 混合矩阵分别投影:
| 矩阵 | 作用 |
|---|---|
| $H^{\mathrm{pre}}$ | $n$ 条残差流 → 子层输入(流间汇聚) |
| $H^{\mathrm{post}}$ | 子层输出写回主流 |
| $H^{\mathrm{comb}}$ | 子层输出与残差流之间的组合混合 |
单层读写顺序见 §4 单层数据流。
3.5 与标准残差、HC 的对照
| 路径 | 混合结构 | 恒等映射 |
|---|---|---|
| 标准残差 | 单流 $x_{l+1} = x_l + F(x_l)$ | 显式 $+x_l$ |
| HC | 多流 + 任意 $H_l^{\mathrm{res}}$ | 无保证 |
| mHC | 多流 + $H_l^{\mathrm{res}} \in \mathcal{B}_n$ | 凸组合 ≈ 加权恒等 |
mHC 保留 HC 的多流表达力($n$ 条并行高速公路),只 把混合权重限制在 Birkhoff 多面体上——这是「Manifold-Constrained」相对裸 HC 的 最小必要约束。
| 符号(直觉) | 作用 |
|---|---|
| $H^{\mathrm{pre}}$ | 多条残差流 → 子层输入(流间加权汇聚) |
| $H^{\mathrm{post}}$ | 子层输出 → 写回某条主流 |
| $H^{\mathrm{comb}}$ | 子层输出与残差流之间的 组合混合 |
4. 单层数据流
与 vLLM MHCPreOp / MHCPostOp 对齐的直觉:
Pre(进子层前)
- 对 $n$ 条残差流做 RMSNorm(及可选 scale/bias)。
- 由归一化后的流 + 子层分支特征算 mix logits。
- Sinkhorn 得到 pre_mix;layer_input $= \sum_i \mathrm{pre_mix}_i \cdot \mathrm{residual}_i$。
Post(出子层后)
$$\mathrm{out}_j = \mathrm{post_mix}j \cdot x + \sum_i \mathrm{comb_mix}{ij} \cdot \mathrm{residual}_i$$
即:子层输出与各路残差按 post / comb 双随机权重写回 $n$ 条流。
infra 注:mHC 额外引入 多流读写 与 Sinkhorn 迭代;论文通过 算子融合 控制开销(见 §5)。
5. 训练与系统工程
mHC 论文除算法外强调 大规模可训可部署:
| 手段 | 目的 |
|---|---|
| TileLang / 自定义 kernel | Sinkhorn 迭代与 pre/post 融合,减少 HBM 往返 |
| 选择性重计算 | 不存巨大中间激活,换算力 |
| DualPipe 通信重叠 | 掩盖流水线 stage 延迟 |
| 重排 Norm 与混合顺序 | 降低内存带宽 |
论文报告:扩展率 $n{=}4$ 时,相对标准 Transformer 训练时间开销约 6.7%(基础设施优化后)。
6. 在 DeepSeek-V4 中的应用
| 维度 | 说明 |
|---|---|
| 角色 | V4 残差路径组件,与 CSA/HCA、Hash MoE、Muon 等 同期引入 |
| 相对 V3.2 | V3.2 无 mHC;mHC 独立论文(2512.24880)先发表,后在 V4(2606.19348) 与百万 token 架构一并落地 |
| Ablation | V4 多变量同改,难以单独剥离 mHC 贡献;Index Share 类纯 infra 补丁更易做对照 |
| 推理 | Engram 等演示代码将 Attention/MoE/mHC 作为标准块 mock;生产引擎(如 vLLM)提供 mhc_pre / mhc_post 自定义算子 |
详见 DeepSeek-V4 与 演进总览 §3.7。
7. 与 attention / MoE 线的关系
| 线 | mHC 是否涉及 |
|---|---|
| MLA / DSA / CSA | 否 — 改的是 注意力与 KV,不是残差拓扑 |
| MoE 路由 | 正交 — mHC 在子层 前后 混合残差流,不替代 expert 选择 |
| ESS / Index Share | 正交 — 后者是 V3.2 KV / indexer infra |
mHC 回答的是:把模型做深、做宽残差流时如何不失稳,而非长上下文 cache 或稀疏注意力本身。
8. 上下游
| 方向 | 文档 |
|---|---|
| 前置概念 | HC 基础 · §3 双随机流形 · Raschka 全文 §8 |
| 同代 V4 组件 | CSA / HCA · Muon · DeepSeek-V4(Hash MoE) |
| 对比(无 mHC 的上一档) | DeepSeek-V3.2 |
参考
- Xie et al. mHC: Manifold-Constrained Hyper-Connections. arXiv:2512.24880, 2025.
- DeepSeek-AI. DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence. arXiv:2606.19348, 2026.
- Raschka. From DeepSeek V3 to V3.2 — §8 mHC 附录.
- Birkhoff (1946) — 双随机矩阵与置换矩阵凸包(Birkhoff–von Neumann 定理)。
- Sinkhorn & Knopp (1967) — 行列交替归一化算法。
- 实现参考:vLLM
model_executor/layers/mhc.py(MHCPreOp/MHCPostOp+ TileLang Sinkhorn kernel).
Hash MoE + FP4
← 中文导读 · ← 仓库首页(EN) · ← 演进总览 §3.7 · ← MoE 线导读 · V4 梗概 · 上游 DeepSeekMoE · 上游 aux-loss-free · $L_{\mathrm{Bal}}$ · centroid vs gate-weight 答疑 论文:DeepSeek-V4 arXiv:2606.19348
一句话
Hash MoE 是 V4 在 MoE 线 ⑤ 对 FFN 的改动:前几层 把稠密 FFN 换成 Hash-routed MoE(token → expert 由 确定性 hash 决定,不再走 V3 的 centroid / sigmoid 亲和度路由);FP4 MoE 则对 routed expert 权重 做 FP4 量化 + QAT,在继承 DeepSeekMoE 256/8 + shared 骨架的前提下压显存与带宽。
MoE 线位置
| 方向 | 文档 |
|---|---|
| 本节点(⑤ Hash MoE + FP4) | §1 Hash 路由 · §2 FP4 量化 |
| MoE 线 hub | MoE 线导读 §1 |
| 上游 ②–④ | DeepSeekMoE · aux-loss-free MoE 路由 · 序列均衡损失 |
| 版本总览 | DeepSeek-V4(两个规格、Attention、训练) |
| 正交 | CSA/HCA · mHC — 不改 expert 选择逻辑本身 |
1. Hash MoE:路由从「学出来」到「算出来」
1.1 V3 及以前:centroid / affinity 路由
DeepSeekMoE(V2→V3)用 可学习 expert 向量 $e_i$ 与 token hidden $u$ 做亲和度 $u^\top e_i$,再 sigmoid + top-$K_r$ + 动态 bias $b_i$(aux-loss-free)。语义上是 「token 匹配 expert 原型」。
1.2 V4 Hash 路由
V4 前几层 改为 Hash-routed MoE:

浅层 MoE 只把路由从 gate 亲和($u^\top e_i$ + sigmoid + top-$K_r$)换成 hash 查表($\varphi(x_t,t)\bmod N_r$);expert id 确定后仍走同一套 EP scatter → Routed FFN → Gather+shared。
{kind=link}
| 维度 | V3 aux-loss-free | V4 Hash MoE(前几层) |
|---|---|---|
| Expert 选择 | $u^\top e_i$ + sigmoid + top-$K_r$ | 确定性 hash(token / 位置 → expert id) |
| 可学习路由参数 | $e_i$、$b_i$ 等 | 无 centroid 式语义匹配 |
| 负载均衡 | $b_i$ + $L_{\mathrm{Bal}}$ | hash 设计 + 仍可有 shared / 池化均衡 |
| 动机 | 语义特化 + 均衡 | 省路由算力与参数;浅层更偏通用变换 |
读法:Hash MoE 不是换掉整个 V4 的 MoE 栈,而是 部分层 离开 centroid 路由;更深层仍可在 DeepSeekMoE 256 routed / 8 active + shared 框架内沿用 V3 族路由 为准)。
答疑:为何只改浅层、深层仍用 centroid? — 浅层通用变换 vs 深层语义特化;静态 hash vs 动态 $b_i$ / EP 均衡
1.3 仍继承什么
- DeepSeekMoE 形态:细粒度 routed pool + shared experts 恒激活(DeepSeekMoE)
- MoE 并行 / EP:routed gather-scatter 推理路径与 V3 同族(答疑:EP 与 gather/scatter)
- 与 Attention 正交:Hash 只改 FFN 专家选择;CSA/HCA 改 Attention/KV
答疑:Expert Parallel(EP)与 gather/scatter — routed 分片、scatter/gather 与 V3 同族;Hash 只改 expert id,不改 EP 骨架
2. FP4 MoE:routed expert 低比特权重
| 对象 | 精度 | 说明 |
|---|---|---|
| Routed expert 权重 | FP4 + QAT | 训练时量化感知,部署减 HBM / 带宽 |
| Shared expert | 通常高于 FP4(与 V3 FP8 训推栈衔接) | 恒激活路径对误差更敏感 |
| Router(非 Hash 层) | 与 V3 族一致 | sigmoid + bias 等仍可能存在于深层 |
FP4 MoE 与 V3 的 FP8 动态量化 同族目标(压 FFN 内存),但 比特更 aggressive,且 只针对 routed expert 块。
3. 在 V4 两个规格中的角色
| 规格 | MoE 侧关注点 |
|---|---|
| V4-Pro(1.6T / 49B act) | Hash 前几层 + FP4 routed;能力上限 |
| V4-Flash(284B / 13B act) | 同族机制,激活参数更小 |
MoE 改动与 CSA/HCA、mHC、Muon 同期打包进 V4,难以单独 ablation Hash vs FP4 vs Attention。
4. 演进链小结

{kind=link}
| 边 | 关系 |
|---|---|
| ③ → ⑤ | 继承 MoE 池化与 shared;前几层 路由机制换 Hash |
| Hash ⊥ centroid | 浅层 不算 $u^\top e_i$;深层可仍用 V3 族路由 |
| FP4 ⊥ Hash | 量化对象(权重)与 路由函数(选 expert)正交,V4 同时上 |
5. 推理 infra 关注点
- EP + FP4 kernel:routed expert 权重 4bit 存取;需与 shared 高精度路径 分 kernel(EP 答疑)。
- Hash 层:路由 无 GEMM 打分,但 expert id 仍走 gather/scatter;负载由 hash 函数 静态近似均衡。
- Checkpoint 兼容:V3 sigmoid-router 权重 不可 直接灌入 Hash 层逻辑。
6. 上下游
| 方向 | 文档 |
|---|---|
| MoE 线 hub | MoE 线导读 |
| 版本总览 | DeepSeek-V4 |
| 路由对照 | MoE 路由:gate-weight 还是 expert centroid? §4.4 |
| FP8 前代 | V3 FP8 动态量化 |
参考
- DeepSeek-V4:arXiv:2606.19348
- HuggingFace:deepseek-v4 collection
Muon 优化器
← 中文导读 · ← 仓库首页(EN) · ← 演进总览 §3.7 · V4 梗概 · CSA/HCA · mHC · Hash MoE + FP4 论文:DeepSeek-V4 arXiv:2606.19348 · Algorithm 1 · §2.4 Muon Optimizer · §3.4.1 Efficient Implementation of Muon
一句话
Muon(Momentum Orthogonalized by Newton–Schulz)在 V4 中替换大部分矩阵参数的 AdamW:对动量矩阵做 Newton–Schulz 正交化得到更新方向 $UV^\top$(极因子),各奇异方向步长归一,从而更快收敛、训练更稳;嵌入、输出头、RMSNorm、mHC 门控等仍用 AdamW。
V4 中的位置
| 方向 | 文档 |
|---|---|
| 本专文 | §1 一步在做什么 · §2 Hybrid Newton–Schulz · §3 参数分组 · §4 训练 infra |
| 版本总览 | DeepSeek-V4(CSA/HCA、mHC、MoE、训练要点) |
| 演进总览 | §3.7 DeepSeek-V4 |
| 三轴图 | 架构-train 轴上的 Muon(100% 训练侧) |
1. Muon 一步在做什么
V3 全系 AdamW:对每个参数做元素级二阶矩估计。V4 对 二维权重矩阵 $W\in\mathbb{R}^{n\times m}$ 改用 Algorithm 1:
$$ G_t=\nabla_W\mathcal{L}t,\quad M_t=\mu M{t-1}+G_t,\quad O'_t=\mathrm{HybridNewtonSchulz}(\mu M_t+G_t),\quad O_t=O't\cdot\sqrt{\max(n,m)}\cdot\gamma,\quad W_t=W{t-1}(1-\eta\lambda)-\eta O_t $$
其中 Nesterov 技巧体现在对 $\mu M_t+G_t$ 做正交化(而非仅 $M_t$);$\gamma=0.18$ 用于 复用 AdamW 学习率超参(与 Kimi Muon 做法一致)。

{kind=link}
1.1 与 AdamW 的几何差异
设梯度(或动量)矩阵 $M=U\Sigma V^\top$(SVD):
| AdamW | Muon | |
|---|---|---|
| 更新形状 | 保留 $M$ 的各向异性($\Sigma$ 仍在) | 近似 $UV^\top$,奇异值全压到 1 |
| 步长语义 | 逐元素自适应 | 各方向等幅的矩阵步 |
| 适用参数 | 向量、标量、矩阵均可 | 矩阵参数为主 |
直观上:AdamW 沿「梯度自然拉伸」的方向走;Muon 先 去掉 $\Sigma$ 的缩放,只保留方向结构,再在正交方向上统一步长——论文报告在 万亿级 MoE 上收敛更快、对学习率 schedule 更不敏感。
1.2 V4 为何不用 QK-Clip
Kimi Muon 曾配合 QK-Clip 抑制 attention logit 爆炸。V4 在 query 与 KV entry 上直接做 RMSNorm(配合 CSA/HCA 架构),logit 已受控,故 不再使用 QK-Clip(论文 §2.4)。
2. Hybrid Newton–Schulz 正交化
显式 SVD 每步太贵;Muon 用 Newton–Schulz 迭代近似极因子 $UV^\top$。先将 $M$ 按 Frobenius 范数归一化 $M_0=M/|M|_F$,再重复:
$$ M_k=aM_{k-1}+b(M_{k-1}M_{k-1}^\top)M_{k-1}+c(M_{k-1}M_{k-1}^\top)^2M_{k-1} $$
V4 相对 Kimi Muon 的改动:混合两阶段、共 10 步——
| 阶段 | 步数 | 系数 $(a,b,c)$ | 作用 |
|---|---|---|---|
| 快速逼近 | 1–8 | $(3.4445,,-4.7750,,2.0315)$ | 奇异值快速靠近 1 |
| 精修稳定 | 9–10 | $(2,,-1.5,,0.5)$ | 将奇异值稳定在 1 |
下面代码与论文 Algorithm 1 / 式 (28) 对齐,便于对照 HybridNewtonSchulz 与单步 Muon 更新(教学用 NumPy,非 V4 生产实现):
import numpy as np
# V4 Hybrid Newton-Schulz: 8 fast + 2 stable (paper §2.4)
NS_STAGES = [
(8, (3.4445, -4.7750, 2.0315)),
(2, (2.0, -1.5, 0.5)),
]
def newton_schulz_step(m: np.ndarray, abc: tuple[float, float, float]) -> np.ndarray:
a, b, c = abc
mm = m @ m.T
return a * m + b * (mm @ m) + c * (mm @ mm @ m)
def hybrid_newton_schulz(m: np.ndarray) -> np.ndarray:
"""Approximate polar factor UV^T; input M is n×m."""
m = m.astype(np.float64)
norm = np.linalg.norm(m, ord="fro")
if norm == 0:
return m
m = m / norm
for n_steps, coeffs in NS_STAGES:
for _ in range(n_steps):
m = newton_schulz_step(m, coeffs)
return m
def muon_step(
w: np.ndarray,
grad: np.ndarray,
momentum: np.ndarray,
*,
lr: float = 2.7e-4,
mu: float = 0.95,
weight_decay: float = 0.1,
gamma: float = 0.18,
) -> tuple[np.ndarray, np.ndarray]:
"""One Muon step for matrix W (Algorithm 1)."""
momentum = mu * momentum + grad
nesterov = mu * momentum + grad
ortho = hybrid_newton_schulz(nesterov)
scale = np.sqrt(max(w.shape)) * gamma
update = ortho * scale
w = w * (1 - lr * weight_decay) - lr * update
return w, momentum
读法:hybrid_newton_schulz 输出近似正交矩阵;sqrt(max(n,m)) * gamma 把更新 RMS 缩放到与 AdamW 超参兼容的量级;最后 decoupled weight decay 与 AdamW 形式相同。
3. 哪些参数用 Muon,哪些仍用 AdamW
| 优化器 | 模块(论文 Basic Configurations) |
|---|---|
| AdamW | embedding、prediction head、所有 RMSNorm 权重、mHC 静态 bias / 门控因子 |
| Muon | 其余全部(Attention 投影、FFN、MoE expert 等矩阵权重) |
动机:正交化是 矩阵级 操作;embedding / LayerNorm 类 向量或标量 参数不适合 Muon,继续 AdamW 更自然。
V4-Flash / V4-Pro 共用 Muon 超参:momentum 0.95、weight decay 0.1、$\gamma=0.18$;AdamW 侧 $\beta_1=0.9$、$\beta_2=0.95$、$\varepsilon=10^{-20}$、weight decay 0.1(§4 训练设置)。
4. 训练 infra:Muon 与 ZeRO
Muon 需要 完整梯度矩阵 才能做 NS 迭代,与传统 ZeRO 按元素切分 AdamW 状态 冲突。V4 训练框架(§3.4.1)要点:
| 问题 | 做法 |
|---|---|
| ZeRO vs 整矩阵更新 | 混合 ZeRO bucket 分配:限制 ZeRO 并行度;用 knapsack 把参数矩阵分到各 rank,负载均衡 |
| bucket 对齐 | 各 rank bucket pad 到同大小 以便 reduce-scatter;padding 开销 < 10% |
| 超大 DP | 超出 ZeRO 上限的 DP 组内 冗余计算 Muon 更新,换更少 bucket 内存 |
| NS 吞吐 | 同 shape 连续参数 合并 batch 跑 NS |
| 精度 | NS 在 BF16 matmul 下仍稳定;MoE 梯度跨 DP 随机舍入到 BF16 同步,通信量减半 |
| 累加 | reduce-scatter 改为 all-to-all + 本地 FP32 求和,避免低精度树形累加误差 |
Muon 与 CSA/HCA、mHC、Hash MoE 同期打包进 V4,难以单独 ablation 优化器 vs 架构(见 V4 定位)。
5. 演进链小结
| 边 | 关系 |
|---|---|
| V3 AdamW → V4 Muon | 训练侧优化器替换;推理权重格式不变(读者侧无「Muon kernel」) |
| Muon ⊥ CSA/HCA | 优化器 vs Attention 算子 正交 |
| Muon ⊥ Hash MoE / FP4 | 优化器 vs MoE 路由/量化 正交 |
| Muon ↔ mHC | mHC 门控仍 AdamW;主体矩阵 Muon |
6. 上下游
| 方向 | 文档 |
|---|---|
| 版本梗概 | DeepSeek-V4 |
| 同代 Attention | CSA / HCA |
| 同代残差 | mHC |
| 同代 MoE | Hash MoE + FP4 |
| 演进总览 | §3.7 V4 |
参考
- 论文:arXiv:2606.19348 — Algorithm 1、§2.4、§3.4.1、§4 超参
- Muon 原论文:Momentum Orthogonalized by Newton-Schulz
- Kimi Muon 实践(V4 引用):Moonshot Kimi 技术报告中的 Muon + QK-Clip(V4 省略 QK-Clip)
DeepSeek DSA 与 Index Share 系列
← 中文导读 · ← 仓库首页(EN) · 主题:V3.2 的 DeepSeek Sparse Attention (DSA) 把长上下文注意力从 $O(L^2)$ 降到 $O(Lk)$;Index Share(IndexCache) 在 DSA 之上用跨层 index 复用砍掉冗余 indexer,纯 infra。 系列导读:DSA 逻辑详解 · Index Share 逻辑详解 · 算法线导读 · 基础设施线导读 · ← 演进总览 §3.6 V3.2
文档索引
| 文档 | 内容 | 对应梗概 |
|---|---|---|
| DeepSeek-V3.1 | 前置:128K、Hybrid 推理、Prefill/Decode MLA 切换;V3.2 续训起点 | V3.1-Terminus |
| DSA 稀疏注意力 | 版本表入口:DSA 三阶段、异构 Cache、流程图 | V3.2 梗概 |
| Lightning Indexer 详解 | Lightning Indexer 公式、Indexer-Cache、Decode 一步前向 | DSA 梗概 |
| DSA 逻辑详解 | DSA 两阶段稀疏注意力、异构 KV Cache、与 MLA/ESS 关系 | V3.2 梗概 |
| ESS Latent offload | Latent-Cache CPU offload;FlashTrans / 热池 | V3.2 infra |
| Index Share 逻辑详解 | F/S 层划分、FFFS 模式、与 ESS/V4 正交性 | Index Share 梗概 |
| DeepSeek-V4 | 下游算法:CSA/HCA、1M context(非 V3.2 补丁) | V4 梗概 |
示意图
⓪ Indexer Decode 一步前向

Lightning Indexer 详解§2 walkthrough
① DSA 流水线

Lightning Indexer → Top-$k$ → Core MLA;Indexer/Latent 双 Cache
② MLA Decode 一步分工

Indexer 选 $I$ vs Latent-Cache 升维 + Core MLA
③ Index Share FFFS

跨层 F/S 划分与 FFFS 复用示意
改图:python3 scripts/svg/gen_dsa_svgs.py → python3 scripts/svg/check_svgs.py(含 Markdown 嵌入 + 布局遮挡校验)
推荐阅读顺序
- V3.1-Terminus — 128K、Hybrid 推理、MLA Prefill/Decode 切换(DSA 直接前置)
- DSA 梗概 — 三阶段总览
- Lightning Indexer — indexer 公式与 Indexer-Cache
- DSA 逻辑 — 稀疏注意力 + Indexer/Latent 双 Cache
- ESS Latent-Cache offload — CPU offload 与 GPU 热池
- Index Share — 跨层 index 复用(infra 补丁)
- CSA/HCA 混合压缩注意力 — 算法线继续演进
与现有栈
| 组件 | 关联 |
|---|---|
| V3.1-Terminus 梗概 | DSA 上游:128K + Hybrid,无稀疏注意力 |
| V3.2 梗概 | DSA 所在版本 |
| 中文导读 | 文章索引、演进图示、许可说明 |
| Engram 条件记忆 | 正交稀疏轴:n-gram 查表 vs DSA top-$k$ |
| 版本演进总览 | 算法线 + infra 线全景 |
| 算法线导读 | MLA → DSA → CSA/HCA + mHC 专题 hub |
| 基础设施线导读 | MLA KV → 异构 Cache → Index Share → ESS → V4 HiSparse |
| Raschka V3→V3.2 解读 | DSA / RLVR / GRPO 第三方梳理 |
论文:DSA arXiv:2512.02556 · IndexCache arXiv:2603.12201 · ESS arXiv:2512.10576
DSA稀疏注意力
← 中文导读 · ← 仓库首页(EN) · ← 演进总览 §3.6 · ← 算法线导读 · ← 基础设施线导读 · ← V3.2 梗概 · 上游 MLA · 下游 CSA/HCA · 下游 V4 梗概 · 下游 Index Share · 下游 ESS · Lightning Indexer 详解 · 完整逻辑 · Raschka §4 DSA 论文:DeepSeek-V3.2 arXiv:2512.02556 · Exp:DeepSeek-V3.2
一句话
DSA 在 MLA 不变 的前提下,把长上下文注意力从「对全长 $L$ 做稠密 MLA」改成 先 indexer 扫全长选 top-$k$,再只对 $k$ 个 latent entry 做 MLA;主路径复杂度 $O(L^2) \to O(Lk)$($k{=}2048$,$k \ll L$)。DeepSeek-V3.2-Exp(2025-09,DeepSeek 官方实验版)验证稀疏不损精度;DeepSeek-V3.2(2025-12)为正式版。
逻辑详解:DSA逻辑详解 · Lightning Indexer · 系列导读
技术归属
| 组件 | 机构 | 说明 |
|---|---|---|
| DSA | DeepSeek | 稀疏注意力算法;V3.2 唯一架构改动 |
| V3.2-Exp / V3.2 | DeepSeek | 官方模型 release(Exp 铺生态,正式版完整后训练) |
| ESS | 百度百舸 | 针对 DeepSeek V3.2 的 Latent-Cache offload;非 DSA 发明方 |
| IndexCache | 清华 + 智谱 | 跨层 index 复用;非 DSA 发明方 |
易混点:ESS 论文标题写 for DeepSeek-V3.2-Exp,指的是优化对象是 DeepSeek 模型,不是百度发布了 V3.2-Exp。
流程图
{kind=link}
三阶段
| 阶段 | 做什么 | 复杂度 | 说明 |
|---|---|---|---|
| ① Lightning Indexer | 当前 $q_t$ 对全长历史的 indexer key $k_s$ 打分($I_{t,s}$) | $O(L^2)$ 量级,常数极小 | 决定「看谁」;walkthrough |
| ② Top-$k$ Selector | 取分数最高的 $k{=}2048$ 个位置 | $O(L \log k)$ | 得到 index 集合 $I$ |
| ③ Core MLA | 仅对 $I$ 中 entry 做标准 MLA attention | $O(Lk)$ | 精度敏感主算子 |

{kind=link}
与滑动窗口的区别:DSA 的 $k$ 个位置是 **学到的、内容相关** 的、不是固定局部窗口。
Lightning Indexer 专题:Lightning Indexer 详解
异构 KV Cache
DSA 把 cache 拆成两类(为 ESS offload、Index Share 铺路):
| Cache | 作用 | 占比(ESS 论文) | GPU 常驻 |
|---|---|---|---|
| Indexer-Cache | indexer 打分、选 top-$k$ | ~16.8% | 是(每步全扫) |
| Latent-Cache | 核心 MLA 的 latent KV | ~83.2% | 可 offload(ESS) |
主 attention 只读 被选中的 $k$ 个 latent entry → Latent-Cache 适合稀疏访问与 CPU 分层。
基础设施线位置
| 方向 | 文档 |
|---|---|
| 本节点(② Indexer/Latent 异构) | 基础设施线导读 §1 |
| 上游 ① 同质 MLA KV | MLA 低秩注意力 |
| 下游 ③ Index Share | Index Share 梗概(indexer 算力,并列) |
| 下游 ④ ESS | ESS Latent offload(Latent offload,并列) |
| 下游 ⑤ V4 infra | DeepSeek-V4 梗概§推理 infra · KV layout · HiSparse · 磁盘 prefix |
算法线位置
| 方向 | 文档 |
|---|---|
| 本节点(② DSA) | 算法线导读 §1 |
| 上游 ① MLA | MLA 低秩注意力 |
| 下游 ③ CSA/HCA | CSA / HCA · DeepSeek-V4 |
在版本线中的位置
| 版本 | DSA |
|---|---|
| V3 / V3.1-T | 稠密 MLA,无 DSA |
| V3.2-Exp | 在 Terminus 上 续训加 DSA;benchmark 平淡,铺推理生态 |
| V3.2 | 架构同 Exp;完整后训练成品 |
| Index Share | 不改 DSA 算法;跨层复用 top-$k$ index,减 indexer 重复计算(Index Share 梗概) |
| V4 | CSA/HCA 等 下一代稀疏/压缩注意力 |
相对 V3.1-Terminus,V3.2 唯一架构改动即为 DSA;MoE、MLA latent 格式、参数量均不变。
与 MLA 的关系
- DSA:在 MLA latent 序列上增加「选哪些位置参与 attention」
- V3.1 Hybrid(Prefill MHA / Decode MQA)仍是 DSA 的前置(DeepSeek-V3.1)
推理 infra
| 组件 | 作用 |
|---|---|
| DeepGEMM | indexer logit kernel |
| FlashMLA | sparse MLA paged kernel |
| IndexCache | Index Share 跨层 index 复用 |
| ESS | Latent-Cache CPU offload |
延伸
| 资源 | 说明 |
|---|---|
| Lightning Indexer 详解 | Lightning Indexer 公式、Indexer-Cache、与滑动窗对比 |
| DSA逻辑详解 | 完整机制、与 Hybrid/ESS/Engram 关系 |
| Index Share逻辑详解 | Index Share FFFS 模式 |
| DeepSeek-V3.2 | V3.2 版本梗概 |
| Raschka DSA 解读 | 第三方梳理 |
论文:V3.2 2512.02556 · ESS 2512.10576
DSA逻辑详解
← 中文导读 · ← 仓库首页(EN) · ← 系列目录 · DSA 梗概 · Index Share 逻辑 · V3.2 梗概 · 演进总览 §3.6 · Raschka §4
1. 定位:V3.2 相对 V3.1 的唯一架构改动
DeepSeek-V3.2(2025-12 正式版;2025-09 先有 V3.2-Exp)在 671B MoE + MLA 基座上,相对 V3.1-Terminus 只改了一处:用 DSA 替换稠密长上下文注意力。
| 维度 | V3.1-T | V3.2 |
|---|---|---|
| 参数量 / 激活 | 671B / 37B | 同左 |
| 上下文 | 128K | 128K |
| 注意力 | 稠密 MLA(Hybrid Prefill/Decode) | 稀疏 MLA:indexer 选 top-$k$ 再算 |
| 公开 benchmark | 基线 | 与 V3.1-T 基本持平 |
V3.2-Exp 与 V3.2 权重架构相同;Exp 验证「稀疏不损精度」,正式版为续训 + 后训练成品。
2. 问题:稠密注意力的 $O$ 墙
标准多头注意力对长度为 $L$ 的序列,QK 点积与 softmax 归一化的有效复杂度为 $O(L^2)$(相对上下文长度二次增长)。在 128K 长上下文下:
- Prefill:算量与 KV 写入随 $L$ 急剧上升;
- Decode:每步虽只增 1 token,但需 attend 全长 cache,$T=L$ 时 attention 项为 $O(L)$ per step,累积仍可观;
- KV Cache 显存:MLA 已压缩 KV,但全长 latent 仍随 $L$ 线性涨。
DSA 的目标:在几乎不损精度的前提下,把「对谁做 attention」变成稀疏问题,从而把主 attention 降到 $O(Lk)$,$k \ll L$。
3. 机制:两阶段稀疏注意力
DSA 每层(在 MLA 路径上)拆成 索引 与 核心注意力 两阶段:
3.1 Lightning Indexer
- 用 极低 head 维 的点积:当前 indexer query $q_t$ 对 每条历史 token $s$ 的 indexer key $k_s$(Indexer-Cache 第 $s$ 行)打分,得 $I_{t,s}$(walkthrough)。
- 复杂度仍是 $O(L^2)$ 量级(每层、每 query 要扫全长),但常数极小,远轻于完整 MLA attention。
- 输出:每个历史位置的重要性分数,用于后续 top-$k$ 选择。
3.2 Top-$k$ Selector
- 从全长中选出 $k=2048$ 个最重要的 latent entry。
- 得到稀疏 index 集合 $I$,$|I|=k$。
3.3 Core MLA Attention
- 仅对 $I$ 中的 entry 做标准 MLA attention($O(Lk)$,$k$ 固定)。
- 这是精度敏感的主路径;稀疏模式由 indexer 决定「看哪里」。
逻辑链:Indexer 贵但轻 → 主 attention 贵但只算 $k$ 个位置 → 总长 $L$ 很大时总收益显著。
4. 异构 KV Cache:Indexer-Cache 与 Latent-Cache
DSA 不仅改算子,还 显式分裂 KV 存储,为后续 offload 与 Index Share 提供结构基础(见你截图中的「Index Cache / Latent Cache」表述;正式文档称 Indexer-Cache / Latent-Cache)。
| Cache 类型 | 存什么 | 典型占比(ESS 论文) | 访问模式 | GPU 常驻 |
|---|---|---|---|---|
| Indexer-Cache | indexer 所需 KV,用于打分、选 top-$k$ | ~16.8% | 每步全量参与 indexer 计算 | 是 |
| Latent-Cache | 核心 MLA attention 的 latent KV | ~83.2% | 仅 被选中的 top-$k$ entry 进入主 attention | 可 offload(ESS) |
设计含义:
- Indexer-Cache 必须留在 GPU:每 decode step 都要对全长跑 indexer,offload 会拖垮延迟。
- Latent-Cache 可分层:主 attention 只 touch $k$ 个 entry → ESS 等方案可把 低频、未选中 的 latent 放到 CPU,按稀疏访问拉回。
- Index Share 的「Index」:后文 infra 补丁复用的是 top-$k$ index 集合(及 F 层算出的 indexer 结果),与 Indexer-Cache 常驻 GPU 并不矛盾——省的是 重复跑 indexer 算子,不是省 Indexer-Cache 本身。
延伸:Index Share 逻辑 · ESS 详解
5. 与 V3.1 Hybrid 推理的关系
V3.1 引入 Hybrid:Prefill 用 MHA 形态、Decode 用 MQA 形态,降低 decode KV 带宽(MHA / GQA / MQA 对照见 V3.1 梗概 §MLA 模式切换)。DSA 在 V3.2 上 叠加稀疏选择,不是推翻 MLA:
- MLA 仍负责 低秩 KV 压缩;
- DSA 在 MLA latent 序列上增加 「选哪些位置参与 attention」;
- 推理栈需 自定义 sparse attention 路径(vLLM day-0、FlashMLA paged kernel 等)。
6. 推理 infra 关注点
| 组件 | 作用 |
|---|---|
| DeepGEMM | indexer logit kernel(含 paged 版) |
| FlashMLA | sparse attention 的 paged kernel |
| Index Share | 跨层复用 index,减 indexer 次数 |
| ESS | Latent-Cache CPU offload,与 Index Share 正交可叠加 |
7. 上下游
| 方向 | 关系 |
|---|---|
| 上游 | V3.1-Terminus:128K + Hybrid,无 DSA |
| 同架构 | V3.2-Exp → V3.2 正式版 |
| 下游 infra | Index Share、ESS |
| 下游算法 | CSA/HCA 混合压缩注意力 · V4 梗概:压缩 + 稀疏的下一代 |
| 正交 | Engram 条件记忆:n-gram 查表稀疏轴 |
8. 参考
- 论文:arXiv:2512.02556
- 代码:deepseek-ai/DeepSeek-V3.2
- 一页梗概:DeepSeek-V3.2
- 系列目录:DeepSeek DSA 与 Index Share 系列
Lightning Indexer 详解
← DSA 梗概 · DSA 逻辑 · §1 在 DSA 中的角色 · §1 答疑:O(L²) 与常数极小 · 为何不用 softmax · Decode 一步 walkthrough 论文:DeepSeek-V3.2 arXiv:2512.02556 · 第三方:Raschka §4
1. 在 DSA 中的角色
Lightning Indexer 是 DeepSeek Sparse Attention (DSA) 的第一阶段:在 Core MLA 做昂贵、精度敏感的主 attention 之前,用极低成本决定「当前 token 该 attend 哪些历史位置」,供 Top-$k$ Selector 选出 $k{=}2048$ 个历史下标。
每层 DSA 流水线:Indexer 选位置 → Top-$k$ 得 index 集 $I$ → Core MLA 只对 $I$ 内 entry 算 attention。Indexer-Cache 与 Latent-Cache 分工 · ess-dual-cache 图。
谁对谁打分?
Decode 推当前 token $t$ 时,Indexer 做的是:一个当前 query,对全长历史里每一个历史位置 $s$ 各打一个分。
| 侧 | 符号 | 从哪来 | 角色 |
|---|---|---|---|
| Query 侧(当前) | $q_t$(或 $q_{t,j}$,$j$=indexer 头) | 本步 $h_t$ 现算,不进 cache | 打分方:「我现在要 attend 谁?」 |
| Key 侧(历史) | $k_s$ | Indexer-Cache 第 $s$ 行(历史 token $s$ 预存) | 被打分方:「历史第 $s$ 个 token 有多相关?」 |
| 输出 | $I_{t,s}$ | 对每个 $s=1\ldots L$ 一个标量 | 当前 $t$ 认为 历史 $s$ 应进入 Top-$k$ 的分数 |
一句话:$q_t$ 对每条历史的 $k_s$ 打分 → 得到 $L$ 个 $I_{t,s}$ → Top-$k$ 得 $I$ → Core MLA 只对 $I$ 内 Latent-Cache 做 attention。
方向:$q_t \to k_s$(当前 query 选历史 key),不是 $k_s$ 选 $q_t$,也不是每个历史 token 各自做 top-$k$。
| 对比 | Lightning Indexer | Core MLA |
|---|---|---|
| 目的 | 决定看谁 | 算 attention 输出 |
| 扫过的历史 | 全长 $L$ 个历史 token | 仅 $I$ 内 $k$ 个历史 token |
| 典型复杂度 | $O(L^2)$ 量级,常数极小 | $O(Lk)$,$k$ 固定 |
| 是否 softmax | 否(为何?) | 是(精度主路径) |
| 是否读 512 维 $c^{KV}$ | 否(读 indexer 专用 cache) | 是(升维后做 MLA) |
答疑:为何 O(L²) 却说「常数极小」?
表里写 Indexer 典型复杂度 $O(L^2)$ 量级、常数极小,容易读成矛盾:既然还是二次,凭什么说「极轻」? 要点:$O(\cdot)$ 只描述随 $L$ 增长的阶;真正决定耗时的是前面的系数(每对 $(t,s)$ 做多少算、读多少字节、走多少条算子)。Indexer 与稠密 MLA 同阶 $L^2$,但系数通常小 一个数量级以上。
1. 「O(L²)」在这里指什么?
| 模式 | Indexer 在做什么 | 量级 |
|---|---|---|
| Prefill | 序列里每个位置 $t$ 都要对全部可见历史 $s$ 打分 | $O(L^2)$(主瓶颈常在这里) |
| Decode 一步 | 一个当前 $q_t$ 对全长 $L$ 个 $k_s$ 打分 | $O(L)$ per step |
因此「$O(L^2)$」主要是 Prefill / 训练口径;Decode 每步是线性的,但每层仍要扫全长 Indexer-Cache。表里与 DSA逻辑详解 沿用同一说法:相对全长历史做 routing,阶与稠密 QK 相同,常数不同。
2. 常数小在哪?
论文 (2512.02556 §DSA) 原话:indexer 仍是 $O(L^2)$,但 requires much less computation compared with MLA;且 small number of heads、可 FP8 实现。本地实现与图(§2 walkthrough)可拆成下面几条:
| 维度 | Lightning Indexer | Core MLA(稠密对照) |
|---|---|---|
| 每 token 读什么 | Indexer-Cache 里 低维 $k_s$(§4 约占 KV ~16.8%) | Latent-Cache 512-d $c^{KV}$ + RoPE,再 升维 到 128 头 |
| 头数 | $H^I$ 很少(远小于 MLA 128 头) | 128 query 头完整 attention |
| 单步算子 | $\sum_j w_{t,j},\mathrm{ReLU}(q_{t,j}\cdot k_s)$:点积 + ReLU + 加权求和 | QK$^\top$ → softmax → 乘 $V$(精度主路径) |
| 是否 softmax / $V$ | 否 | 是 |
| 主 attention 扫多长 | 必须 全长 $L$(为选 Top-$k$) | DSA 下 仅 $k{=}2048$ 条($O(Lk)$) |
一句话:Indexer 是「廉价、低维、无 softmax 的全长打分」;贵的是后面只对 $k$ 条做的 MLA。 系数小来自 更窄的向量、更少的头、更少的算子,而不是 $L$ 的阶更低。
为何 Indexer 不用 softmax?
分工不同。Core MLA 的输出是当前 token 的表示 $u_t$,要对选中的历史做 softmax 权重 × $V$ 加权求和——权重必须在参与求和的条目上 非负且和为 1。Lightning Indexer 只做 routing:为每个历史下标 $s$ 打一个 可比大小的标量 $I_{t,s}$,再 Top-$k$ 得到下标集 $I$;不读 $V$、不产出隐状态,因此 不必 把 $L$ 个分数归一化成 attention 概率。
Top-$k$ 只关心排序,不关心「归一化后的概率」。Indexer 只需回答「哪 $k$ 个 $s$ 最该进主 attention」;$\mathrm{ReLU}(q\cdot k)$ 加多头加权求和 足够表达相关性,又比对每个 $t$ 在全长 $L$ 上做 $\exp$ → 求和 → 除 的 softmax 便宜得多(Prefill 下这是 $O(L^2)$ 格点上的额外非线性)。
| Lightning Indexer | Core MLA | |
|---|---|---|
| 产出 | 下标集 $I$(哪 $k$ 个 $s$) | 向量 $u_t$ |
| 分数怎么用 | 排序 → Top-$k$ | softmax → 权重 → 乘 $V$ |
| 是否在全长 $L$ 上归一化 | 否 | DSA 下在 $k$ 条子集上 softmax |
训练 vs 推理:推理时 Indexer 故意省略 softmax;训练阶段仍可用 KL 散度 等目标,让 Indexer 的选中模式 对齐 稠密 MLA 的 attention 分布(见 §7 训练)。学会「看谁」之后,推理用 廉价打分 + hard Top-$k$ 即可;精度主路径的 softmax 留给 Core MLA,且 只对 $k{=}2048$ 条 latent 做,不再扫全长。
小结:Indexer = 全长粗筛(cheap score);Core MLA = 子集精算(softmax + $V$)。ReLU 提供非线性,真正稀疏来自 Top-$k$(见 §4 打分公式),不是 ReLU 把大部分分数截成 0。
3. 粗算对比
记每个 $(t,s)$ 对的 Indexer 代价 $\propto H^I \cdot d_I$($H^I$ 个头、每头 $d_I$ 维点积;V3.2 官方实现里 $H^I$ 小、$d_I$ 低,且可走 FP8)。 稠密 MLA 的 QK 一项 $\propto H^{\mathrm{MLA}} \cdot d_{\mathrm{head}}$,且之后还有 softmax + 对 $V$ 的加权($V$ 维与 latent 升维同量级)。
再乘 cache 带宽:Indexer 只读 Indexer-Cache 行;MLA 读 512-d latent 并展开。ESS 论文给出异构占比 Indexer ~16.8% / Latent ~83.2%,单 token 的 indexer footprint 约为 latent 的 ~1/5,Prefill 全长扫 cache 时 内存流量也差一截。
所以:阶仍是 $L^2$,但「每格」便宜一个数量级以上 —— 这就是「常数极小」的含义。
4. 既然这么轻,为什么 Index Share 还要优化它?
常数小 ≠ 可忽略:
- Prefill:层数 $\times$ 全长 $\times$ 每层独立 indexer → 长上下文下 indexer 可占 Prefill 大部分时间(IndexCache 论文引 V3.2 场景约 ~81%;§8 推理与 infra)。
- Decode:每步 $O(L)$ 且 每层都跑;$L{=}128\text{K}$ 时累加仍可观。
- DSA 总收益:Indexer 贵但 只 routing;Core MLA 从 $O(L^2)$ 收到 $O(Lk)$($k{=}2048$),端到端长上下文仍明显变快。
Index Share 动的是 重复 indexer 算子(层间复用 Top-$k$),不是否认「单算 indexer 很轻」,而是 F 层算一次、S 层跳过。
5. 和推荐 ETA 的同一句话
两阶段都是 cheap score over full history → expensive attention on top-$k$(与推荐场景 ETA 同构)。ETA 里 Stage-1 也常常是 低维内积 / 双塔,Stage-2 才是 完整 target attention;DSA 的「常数极小」就是 Stage-1 故意做 极简打分器。
2. Decode 一步 walkthrough:$t$、$s$ 怎么完成?
上面是概念层:固定当前 $t$,遍历历史 $s$ 打分,Top-$k$ 选下标。下面用 $L=8$、当前 $t=9$ 的一次 decode 前向(实际 $L$ 可达 128K),把输入 → 前向 → 输出三块与实现对齐。
{kind=link}
2.1 输入是什么?
| 输入 | 形状 / 含义 | 何时产生 |
|---|---|---|
| $h_t$(例 $h_9$) | [5120] 当前隐状态 | 本步由上一层输出 |
| Indexer-Cache 第 $s$ 行 $k_s$ | [d_I] indexer key | 历史:token $s$ 成为当前步时已写入 |
| Latent-Cache $c_s^{KV}$ | [512] + $k^R$ | Indexer 不读;Core MLA 升维用 |
历史 $s=1\ldots 8$ 在各自成为「当前步」时已完成 K 写入(与 MLA 主路径并行、更轻):
$$ k_s = W^{IK},\mathrm{proj}(h_s) \quad \Longrightarrow \quad \text{append Indexer-Cache 第 } s \text{ 行} $$
本步 $t=9$ 不重算 $k_1\ldots k_8$,只读 cache。
2.2 前向怎么完成 $t$、$s$ 操作?
固定当前 $t=9$,对 每个历史 $s \in {1,\ldots,L}$ 各算一个分:
$$ I_{9,s} = \sum_{j=1}^{H^I} w_{9,j},\mathrm{ReLU}(q_{9,j} \cdot k_s) $$
| 步骤 | 操作 | $t$ / $s$ 含义 |
|---|---|---|
| A | $q_9 = W^{IQ},\mathrm{slice}(h_9)$ | $t$ 只出现一次:现算当前 query |
| B | $s=1,2,\ldots,L$(实现为 batched GEMM) | $s$ 在循环里扫:同一 $q_9$ 点积 L 个 $k_s$ |
| C | Top-$k$($k{=}2048$) | 取 $I_{9,s}$ 最高的 $k$ 个历史下标 $s$,得 $I$ |
- DeepGEMM:
dot(q_t, Indexer-Cache)一次产出长度 $L$ 的分数向量 - Indexer 不算 softmax / $V$ / 512 维 $c^{KV}$(留给 Core MLA)
2.3 输出是什么?
| 输出 | 形状 | 下游 |
|---|---|---|
| 分数向量 $[I_{t,1},\ldots,I_{t,L}]$ | $[L]$ | 中间量;Top-$k$ 后立即丢弃大部分 |
| index 集 $I$ | $|I|=k$ 个 $s$ | Core MLA 只读 Latent-Cache 中 $s \in I$ 的行 |
| (本步 append)$k_t$、$c_t^{KV}$ | 各 1 行 | 供下一步 $t{+}1$ 当历史 $s$ 使用 |
$L=8$ 时 Top-$k$ 最多 $\min(2048,L)=8$;$L=32\text{K}$ 时 $k{=}2048$ 才有稀疏收益。
2.4 Prefill 与 Decode
| 模式 | 当前 $t$ | 可见历史 $s$ | Indexer |
|---|---|---|---|
| Prefill 第 $t$ 行 | batch 内位置 $t$ | $1 \le s < t$ | 对前缀打分 → Top-$k$ → Core MLA |
| Decode 一步 | 新 token,$t=L{+}1$ | $1 \le s \le L$ | 对全长 Indexer-Cache 打分 → Top-$k$ |
每处理完 token $t$,append $k_t$ 到 Indexer-Cache(与写 $c_t^{KV}$ 到 Latent-Cache 同步发生,Indexer 路径更轻)。
{kind=link}
左栏:Indexer 路径(与上文 walkthrough 一致);右栏:Latent-Cache 升维 + Core MLA,只吃 $I$ 内 entry。
3. 「位置」、$t$ / $s$ 与 Top-$k$ 方向
「位置」= 序列里第几个 token 的下标
不是空间坐标,也不是 attention head 编号。 已生成序列长度 $L$ 时,每个 token 占序列中的一个槽位;槽位编号就是下标(walkthrough 用 $1\ldots L$,公式里常写 $0 \le s < t$)。
| 符号 | 指谁 | 在 decode 一步里 |
|---|---|---|
| $t$ | 当前正在算的 token | 本步新生成的那个 query(来自 $h_t$) |
| $s$ | 历史序列里的某个 token | Indexer-Cache / Latent-Cache 里第 $s$ 行(过去某 token 存下的向量) |
| $j$(公式 $q_{t,j}$) | Indexer 的第 $j$ 个头 | 与历史下标 $s$ 无关;仅多头打分时出现 |

{kind=link}
图中历史下标有时写作 $j$(如 $\mathrm{indexer}j$),与公式里的 $s$ 同义;不要与 $q{t,j}$ 里的头编号 $j$ 混用。
Top-$k$:谁对谁选?
一句话:当前 step 的 query,在全部历史 token 里选出 $k$ 个最相关的下标(与 §2 walkthrough 一致)。
Decode 每推一个新 token,$t$ 前进一格,重新对更新后的全长历史做一遍 Top-$k$(Index Share 可在层间复用 $I$,那是 infra 优化,不改变「$q_t$ 选历史 $s$」的方向)。
4. 打分公式
对当前 query 下标 $t$、历史 token 下标 $s$($0 \le s < t$),重要性分数:
$$ I_{t,s} = \sum_{j=1}^{H^I} w_{t,j},\mathrm{ReLU}!\left(q_{t,j} \cdot k_s\right) $$
| 符号 | 含义 |
|---|---|
| $H^I$ | Indexer 头数(远小于 MLA 的 128 头;低维、廉价) |
| $q_{t,j}$ | 当前 token $t$ 上、第 $j$ 个 indexer head 的 query($j$=头编号) |
| $k_s$ | 历史 token $s$ 的 indexer key(Indexer-Cache 第 $s$ 行;非 MLA 主 KV) |
| $w_{t,j}$ | 可学习的 per-head 标量权重 |
| $I_{t,s}$ | 当前 $t$ 认为 历史 $s$ 有多重要(分数越高越应进入 Top-$k$) |
实现要点:
- Indexer 只对 query 侧多头;keys 已在 cache,按历史下标 $s$ 查第 $s$ 行即可。
- ReLU 不保证分数为 0;真正稀疏来自 Top-$k$,不是 ReLU 截断。
- Top-$k$ 的 $k$ 与 GQA/MQA 的 KV 头数无关;V3.2 官方实现 $k{=}2048$。
5. Indexer-Cache:存什么、为何不 offload
DSA 把 KV 拆成两类(DSA逻辑详解§4):
| Indexer-Cache | Latent-Cache | |
|---|---|---|
| 内容 | 每条历史 token 的 indexer 轻量向量(打分用) | MLA $c^{KV}$ [512] + $k^R$ [64] |
| 占比(ESS 论文) | ~16.8% | ~83.2% |
| 每步访问 | 全长 $L$ 条(indexer 必须全扫) | 仅 $I$ 内 $k$ 条 |
| GPU 常驻 | 是 | 可 ESS offload |
Lightning Indexer 只读 Indexer-Cache,不升维、不读 512 维 latent,因此单步点积带宽远低于「对全长做 MLA」。
6. 与滑动窗口 / 稠密 MLA 的区别
| 滑动窗口 | 稠密 MLA(V3.1-T) | DSA + Lightning Indexer | |
|---|---|---|---|
| 可见历史 | 固定局部窗 | 全长 | 学到的 $k$ 个位置 |
| 选择规则 | 距离 | 无(全 attend) | indexer 分数 + top-$k$ |
| 能否非局部 | 否 | 是 | 是(内容相关) |
| 典型 $k$ / 窗宽 | 窗宽 $w$ | $L$ | $k{=}2048$ |
DSA 的 $k$ 个位置是 数据驱动、内容相关 的,不是固定局部窗口(Raschka 表 4-1)。
7. 训练:如何不损精度
V3.2-Exp 在 V3.1-Terminus 上 续训加入 DSA(非从零训练)。Indexer 需学会近似稠密 MLA 的「看谁」模式:
- 论文叙述:用 KL 散度 等目标,让 indexer 选出的分布对齐稠密 attention 模式(详见 2512.02556 §DSA)。
- 结果:公开 benchmark 与 V3.1-Terminus 基本持平,长上下文 算力显著下降(V3.2 梗概)。
8. 推理与 infra
| 组件 | 与 Lightning Indexer 的关系 |
|---|---|
| DeepGEMM | indexer logit / 点积 kernel(含 paged 版) |
| Indexer-Cache 常驻 GPU | 每 decode step 全长扫;不可像 Latent 那样 offload |
| Index Share | 跨层 复用 top-$k$ index,减 重复跑 indexer 算子 |
| Prefill 瓶颈 | 长上下文下 indexer 可占 Prefill ~81%(IndexCache 论文引 V3.2 场景) |
Indexer 不做:softmax、latent 升维、读 $c^{KV}$、offload。
9. 上下游
| 方向 | 文档 |
|---|---|
| 前置 | MLA · V3.1 Hybrid |
| 同流水线 | Top-$k$ + Core MLA |
| 下游 infra | Index Share · ESS |
| 下游算法 | CSA/HCA 专文 §2 · V4 梗概(新一代压缩 + 稀疏) |
10. 参考
- DeepSeek-AI. DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models. arXiv:2512.02556, 2025.
- Sebastian Raschka. From DeepSeek V3 to V3.2 — §4 Sparse Attention · 要点速读
- 本地图:§2 walkthrough 图 · ess-dual-cache 图 · dsa-pipeline
Index Share梗概
← 中文导读 · ← 仓库首页(EN) · ← 演进总览 §4 · ← 基础设施线导读 · ← 版本目录 · 上游 DSA §异构 KV · 并列 ESS · 逻辑详解
定位
社区昵称 Index Share / 「V3.3」;正式名 IndexCache(清华 + Z.ai,2026-03)。不是新模型,而是面向 DSA 架构的 纯推理 infra 补丁:零额外显存,在 V3.2 / GLM-5 等模型上即插即用。
典型体现「infra 归 infra,算法归算法」——算法仍是 V3.2 的 DSA,系统侧利用跨层冗余砍掉冗余 indexer 计算。
逻辑详解:Index Share逻辑详解 · 上游 DSA §异构 KV
基础设施线位置
| 方向 | 文档 |
|---|---|
| 本节点(③ Index Share) | 基础设施线导读 §1 |
| 前置 ② 异构 cache | DSA稀疏注意力§异构 KV |
| 并列 ④ ESS | ESS Latent offload(Latent offload,可同开) |
| 下游 ⑤ V4 | CSA / HCA · DeepSeek-V4(V4 自带 CSA indexer,路线互补) |
技术归属
结论摘要
| # | 要点 |
|---|---|
| 1 | IndexCache / Index Share(跨层索引复用)不是 DeepSeek 原创,也不是百度百舸原创 |
| 2 | DSA 稀疏注意力(含 Lightning Indexer)为 DeepSeek 自研,是被优化的模型侧基底 |
| 3 | IndexCache 由 清华大学计算机系 + 智谱 AI(Z.ai) 联合提出(arXiv:2603.12201) |
| 4 | 百度百舸(Baige AI) 在 IndexCache 上主要是工程集成与云侧落地;其自研的同类 infra 是 ESS(Latent-Cache offload),与 IndexCache 正交 |
各方分工
| 机构 | 角色 | 代表工作 |
|---|---|---|
| DeepSeek | 造出带 Lightning Indexer 的 DSA 模型(被优化对象) | DSA、arXiv:2512.02556;每层独立 top-$k$,$O(L^2)$ indexer + $O(Lk)$ Core MLA |
| 清华 + 智谱(Z.ai) | 提出 IndexCache / index-share 跨层索引复用(优化算法本体) | Full (F) 层算索引并 index-cache;Shared (S) 层 index-share 复用;FFFS 等模式 |
| 百度百舸 | ESS 原创 + IndexCache 训推引擎适配/部署(落地方) | ESS arXiv:2512.10576(Latent-Cache offload);百舸云侧集成 IndexCache、KV 缓存、并行调度等 |
IndexCache 论文中的两个名词
(勿与 DSA 里的 Indexer-Cache 存储块混淆,见下节。)
| 论文术语 | 含义 |
|---|---|
| index-cache | F(Full)层算出 top-$k$ 后,把索引集合缓存起来 |
| index-share | S(Shared)层不跑 indexer,直接复用最近 F 层的缓存索引 |
相邻层索引重叠可达约 70%–100%;典型 FFFS 下约 75% 层可跳过 indexer 计算。
DeepSeek 侧:DSA 为何需要这类补丁
- DSA 每层独立 lightning indexer,长上下文 Prefill 时 indexer 可占主导耗时;
- IndexCache 不改 DSA 结构,只在调度上减少「重复跑 indexer」的次数。
百舸侧:两套不同技术
| 技术 | 归属 | 优化对象 |
|---|---|---|
| IndexCache | 清华 + 智谱 发明;百舸 集成部署 | DSA indexer 计算(跨层复用 top-$k$ 下标) |
| ESS | 百舸 原创(Chen et al., 2025) | DSA Latent-Cache 显存(CPU offload + 热池) |
易混淆:三类「Cache」
| 名称 | 谁的概念 | 是什么 |
|---|---|---|
| Indexer-Cache | DSA / ESS 文档 | GPU 常驻的 indexer 向量 KV(~16.8%),每步参与打分 |
| Latent-Cache | DSA / ESS 文档 | MLA latent KV(~83.2%),ESS 可 offload |
| index-cache(IndexCache 论文) | 清华 + 智谱 | F 层产出的 top-$k$ 下标缓存(计算复用,非 KV 存储块) |
| DeepSeek API 硬盘上下文缓存 | DeepSeek 业务 | 请求级 前缀 KV 复用,与 IndexCache 无关 |
逻辑详解:Index Share逻辑详解 §1
DSA 每层独立跑 lightning indexer,复杂度 $O(L^2)$。长上下文 prefill 时 indexer 成为显著瓶颈。观察:相邻层选出的 top-$k$ index 高度相似。
机制
逻辑详解:Index Share逻辑详解 · DSA 前置
层划分为两类:
| 类型 | 行为 |
|---|---|
| Full (F) | 保留 indexer,正常计算 top-$k$ |
| Shared (S) | 不跑 indexer,复用最近 F 层的 cached indices |
典型模式 FFFS 重复:每 4 层留 1 个 F 层,去掉 75% indexer 计算。
部署模式:
- Training-free:校准集上贪心选保留哪些层的 indexer
- Training-aware:多层蒸馏,让 F 层 indexer 拟合覆盖层的平均 attention 分布
效果
| 指标 | 加速 |
|---|---|
| Prefill(TTFT) | 1.82× |
| Decode 吞吐 | 1.48× |
| 精度损失 | 可忽略 |
推理 infra 关注点
- 实现:SGLang / vLLM patch,核心为一个
if/else分支 - 零额外 GPU 显存
- 仅适用于 DSA 系(DeepSeek-V3.2、GLM-5 等)
- 与 ESS Latent-Cache offload 正交,可叠加
与 V4 对比
| 属性 | Index Share | V4 |
|---|---|---|
| 权重 | 不变 | 全量重训 |
| 改动量 | 极小 | 架构级 |
| 上下文 | 128K 系优化 | 原生 1M |
| Ablation | 干净(纯 infra) | 多变量纠缠 |
参考
- 论文:arXiv:2603.12201
- 代码:THUDM/IndexCache
- 前置版本:DeepSeek-V3.2
Index Share逻辑详解
← 中文导读 · ← 仓库首页(EN) · ← 系列目录 · ← 基础设施线导读 · DSA 梗概 · DSA 逻辑 · Index Share 梗概 · 演进总览 §3.6
1. 定位:不是新模型,是 DSA 上的纯 infra 补丁
社区昵称 Index Share / 「V3.3」;正式名 IndexCache(清华 + Z.ai,2026-03,arXiv:2603.12201)。
| 属性 | Index Share | 新模型(如 V4) |
|---|---|---|
| 权重 | 不变 | 全量重训 |
| 显存 | 零额外 | 新 layout / 新算子 |
| 改动面 | 推理调度(F/S 层 + index 缓存) | 架构级 |
| 前提 | 必须有 DSA(lightning indexer + top-$k$) | 自带 CSA indexer 等 |
典型体现:infra 归 infra,算法归算法——算法仍是 V3.2 的 DSA,系统侧利用 跨层冗余 减少 indexer 计算。
1.1 技术归属
| 机构 | 做什么 | 不做什么 |
|---|---|---|
| DeepSeek | DSA + Lightning Indexer 模型结构(每层独立 top-$k$) | 不拥有 IndexCache / index-share 发明 |
| 清华 + 智谱(Z.ai) | IndexCache 论文与开源(THUDM/IndexCache);F 层 index-cache、S 层 index-share | 不改动 DSA 权重 |
| 百度百舸 | ESS(Latent-Cache offload)原创;IndexCache 引擎集成与云部署 | 非 IndexCache 算法发明方 |
一句话:DeepSeek 提供 被优化的 DSA 模型;清华 + 智谱 提供 跨层索引复用算法;百舸把 IndexCache 工程化落地,并与自研 ESS 等 infra 组合服务线上 DeepSeek 推理。
勿混淆:
- DSA 的 Indexer-Cache / Latent-Cache = 异构 KV 存储;
- IndexCache 的 index-cache = top-$k$ 下标的跨层复用缓存;
- ESS 管 Latent 搬移,Index Share 管 indexer 算子次数,二者正交。
2. 前置:DSA 里 indexer 为何成为瓶颈
在 DSA 逻辑 中,每层独立执行:
- Lightning Indexer:对全长 $L$ 打分($O(L^2)$ 量级,常数小);
- Top-$k$ 选择;
- 仅对 $k$ 个 latent 做 Core MLA Attention。
长上下文 Prefill 时,层数 $\times$ 全长 indexer 累加,indexer 可占显著时间;Decode 阶段每层每步也要跑 indexer。 Index Share 不碰第 3 步主 attention,只优化第 1–2 步的 重复劳动。
3. 核心观察:相邻层 top-$k$ index 高度相似
IndexCache 论文与工程实现的出发点:
- 不同 Transformer 层对「哪些历史 token 重要」的判断 高度相关;
- 若 layer $\ell$ 与 $\ell+1$ 的 top-$k$ index 集合 相近,则 $\ell+1$ 不必再跑一遍 indexer,直接 复用 $\ell$(或最近 Full 层)的 indices 即可进入 Core Attention。
这与 DSA 的 异构 Cache 分工一致:
- Indexer-Cache 仍常驻 GPU(F 层要算 indexer);
- 省掉的是 S 层上的 indexer 算子调用,不是取消 Indexer-Cache 存储。
4. 机制:Full 层与 Shared 层
每层标记为两种角色之一:
| 类型 | 行为 |
|---|---|
| Full (F) | 正常运行 Lightning Indexer,计算 top-$k$,写出 index 供后续 S 层复用 |
| Shared (S) | 跳过 indexer;从缓存读取最近 F 层的 top-$k$ indices,直接进入 Core MLA Attention |
flowchart TB
subgraph L1["Layer 1 - F"]
I1[indexer] --> K1[top-k indices]
end
subgraph L2["Layer 2 - F"]
I2[indexer] --> K2[top-k indices]
end
subgraph L3["Layer 3 - F"]
I3[indexer] --> K3[top-k indices]
end
subgraph L4["Layer 4 - S"]
K3 --> Reuse[复用 L3 indices]
Reuse --> A4[Core Attention]
end
K1 --> Share2[可被下层复用]
K2 --> Share3[可被下层复用]
4.1 典型模式 FFFS
每 4 层中 3 个 F + 1 个 S,周期重复:
Layer: 1 2 3 4 5 6 7 8 ...
Role: F F F S F F F S ...
- 去掉 75% 的 indexer 计算(每 4 层只算 3 次 indexer,而非 4 次);
- S 层复用的是 紧前一个 F 层的 indices。
{kind=link}
4.2 实现形态
- 推理框架(SGLang / vLLM patch)中多为 分支:若当前层为 S,则
cached_indices = last_F_layer.indices,否则跑 indexer 并更新缓存。 - 零额外 GPU 显存:复用已有 index 张量,不复制整套 KV。
5. 部署模式:Training-free vs Training-aware
| 模式 | 做法 | 适用 |
|---|---|---|
| Training-free | 在校准集上 贪心搜索 哪些层保留 F、哪些设为 S,约束 LM loss 下降可忽略 | 快速上线、零训练 |
| Training-aware | 多层蒸馏:让保留的 F 层 indexer 拟合其「覆盖」的 S 层的平均 attention 分布 | 更激进 S 比例、更长上下文 |
二者都不改 checkpoint 权重;差别在 F/S 划分与可选蒸馏校准。
6. 效果与适用边界
200K context 量级:
| 指标 | 加速 |
|---|---|
| Prefill(TTFT) | 1.82× |
| Decode 吞吐 | 1.48× |
| 精度 | 可忽略损失 |
适用:
- DSA 系模型:DeepSeek-V3.2、GLM-5 等带 lightning indexer 的栈;
- 不适用 无 DSA 的稠密 MLA/V3.1 路径。
正交叠加:
| 补丁 | 优化对象 | 与 Index Share |
|---|---|---|
| ESS | Latent-Cache CPU offload | 正交,可同时开 |
| V4 HiSparse | V4 异构 KV + 磁盘 prefix | 不同代际,非 V3.2 补丁;HiSparse · 磁盘 prefix |
| Engram | n-gram 条件记忆查表 | 正交,见 Engram 导读 |
7. 与 V4 的对比
| 维度 | Index Share | V4 |
|---|---|---|
| 权重 | 不变 | 重训 |
| 上下文目标 | 优化现有 128K 系 | 原生 1M |
| Ablation | 干净(纯 infra) | 多变量(CSA/HCA、mHC、Muon…) |
| indexer 来源 | 复用 DSA 层间相似性 | CSA 自带压缩 indexer |
社区将 Index Share 戏称为「V3.3」,指的是 收益大、改动小、无需重训,而非官方版本号。
8. 逻辑闭环:从 DSA 双 Cache 到 Index Share
- DSA 分裂 Indexer-Cache(GPU 常驻、每步参与打分)与 Latent-Cache(主 attention、可 ESS offload)。
- Indexer 每层独立 → Prefill/Decode 上 indexer 成为可优化热点。
- Index Share 利用 层间 index 相似,让 S 层跳过 indexer,只复用 F 层的 top-$k$ 选择结果。
- 主 attention 仍走 DSA 稀疏 Core MLA;精度由 F 层密度与 F/S 划分保证。
返回 DSA:DSA逻辑详解§4 异构 KV Cache
9. 参考
- 论文:arXiv:2603.12201
- 代码:THUDM/IndexCache
- 前置:DSA 逻辑详解
- 梗概:Index Share 梗概
- 演进全景:版本演进总览
ESS:Latent-Cache Offload
← 中文导读 · ← 仓库首页(EN) · ← 演进总览 §5.2 · ← 基础设施线导读 · ← DSA · 并列 Index Share · ESS 论文梗概 论文:ESS arXiv:2512.10576 — An Offload-Centric Latent-Cache Management Architecture for DeepSeek-V3.2-Exp(Chen et al., 2025) 论文梗概:ESS 论文梗概
一句话
ESS 是面向 V3.2 DSA 的 KV offload 架构:Indexer-Cache(~16.8%)常驻 GPU;Latent-Cache(~83.2%)卸载到 CPU DRAM,按 top-$k$ 稀疏访问 prefetch 热 entry 回 GPU。不改模型权重,依赖 DSA 把主 attention 限制在 $k{=}2048$ 个 latent 上。
归属:ESS 为 百度百舸(Baige AI) 提出(arXiv:2512.10576),优化 Latent-Cache 显存;与 清华 + 智谱 的 Index Share / IndexCache(优化 indexer 计算)正交,可同开。
为什么 V3.2 需要 ESS
| 问题 | 说明 |
|---|---|
| 128K latent 线性涨 | 即使用 MLA 压缩,全长 Latent-Cache 仍占 HBM 大头 |
| V3 通用 offload 不好用 | 同质 MLA latent 整条搬移,PCIe 小块传输带宽差 |
| DSA 带来的机会 | Core MLA 每步只读 $k$ 个 latent entry → offload 粒度可变成 稀疏 entry,而非全长序列 |
DSA 先把 cache 拆成 Indexer + Latent 两类,ESS 专门管 Latent 那一侧的 CPU/GPU 分层。
双 Cache 与 ESS 分工

图示详情 · 图源 Lightning Indexer · Decode 一步
{kind=link}
读图要点(单层、第 $t$ 个 decode token)
| 组件 | 存什么 | 算什么 | 不算什么 |
|---|---|---|---|
| Indexer-Cache | 全长 $L$ 个 轻量 indexer 向量(~16.8%,GPU 常驻) | 对 $j{=}1..L$ 打分 → Top-2048 下标 $I$ | 不读 $c_j^{KV}$、不做 MLA softmax |
| Latent-Cache | 每位置 $c_j^{KV}$ [512] + $k^R$(~83.2%,ESS 可 offload) | 仅 $j \in I$:prefetch → $W^{UK}/W^{UV}$ 升维 → Core MLA → $u_t$ | 不对全长 $L$ 做稠密 attention |
Indexer 回答「看哪 2048 个位置」;Latent-Cache 回答「这些位置的 MLA K/V 是多少、怎么加权」。详见 MLA 前向流程图。
| Cache | 占比 | ESS 策略 | 原因 |
|---|---|---|---|
| Indexer-Cache | ~16.8% | GPU 常驻,不 offload | 每 decode step 要对全长跑 indexer |
| Latent-Cache | ~83.2% | CPU offload + GPU LRU 热池 | 主 attention 只 touch top-$k$;相邻 step index 重叠率高 |
DSA 异构 cache 同时支撑 ESS(搬 latent) 与 Index Share(省 indexer 计算)。
ESS 核心机制
| 组件 | 作用 |
|---|---|
| Latent-Cache → CPU | 冷 latent entry 放主机 DRAM,释放 GPU HBM |
| Sparse Memory Pool(GPU) | LRU 维护 热 latent 子集;miss 时从 CPU prefetch |
| FlashTrans + UVA | 优化大量 656B 级小块 PCIe 传输 由 ~0.8 GB/s 提升至 ~37 GB/s) |
| Layer-wise overlap | 计算与传输 流水线,掩盖 prefetch 延迟 |
局部性依据:DSA 每步选出的 top-$k$ index 集合在相邻 decode step 间 高度相似 → 多数需要的 latent 已在 GPU 热池,少量 miss 再拉取。
与 Index Share / V4 的关系
| ESS | Index Share | V4 HiSparse | |
|---|---|---|---|
| 改权重 | 否 | 否 | 是(新模型) |
| 省什么 | Latent 显存(offload) | Indexer 算力(跨层复用 index) | 异构压缩 cache + inactive entry offload |
| 适用 | V3.2 DSA | V3.2 / GLM-5 DSA | V4 CSA/HCA |
| 叠加 | 与 Index Share 正交可同开 | 与 ESS 正交 | 非 V3.2 ESS 的简单放大 |
V4 的 KV-offload 围绕 CSA/HCA/SWA 异构 layout 重做,不是把 ESS 直接扩到 1M · DeepSeek-V4。
论文收益
详见 论文梗概 §Table 2。
| 上下文 | 吞吐提升 |
|---|---|
| 32K | +69.4%(MTP=2,batch 52→160,Ratio 1.0→0.21) |
| 128K | 最高 +123%(MTP=2,batch 13→54,Ratio 1.0→0.1) |
基础设施线位置
| 方向 | 文档 |
|---|---|
| 本节点(④ ESS offload) | 基础设施线导读 §1 |
| 前置 ② 异构 cache | DSA稀疏注意力§异构 KV |
| 并列 ③ Index Share | Index Share 梗概(indexer 算力,可同开) |
| 下游 ⑤ V4 infra | DeepSeek-V4 梗概§推理 infra · KV layout · HiSparse · 磁盘 prefix(非 ESS 简单放大) |
在版本线中的位置

{kind=link}
前置:DSA(必须先有双 cache 结构) 并列:Index Share
延伸
| 资源 | 说明 |
|---|---|
| ESS 论文梗概 | 论文梗概:Fig.1–9、Table 1–2 逐图逐表解读 |
| DSA逻辑详解 §4 | 异构 Cache 设计含义 |
| Index Share逻辑详解 | 与 ESS 正交性 |
| DeepSeek-V3.2 | V3.2 梗概 |
| 演进总览 §5.4 | V3 / V3.2 ESS / V4 三代 offload 对比 |
ESS 论文梗概
← 中文导读 · ← 仓库首页(EN) · ← 演进总览 §5.2 · ← ESS 概念页 · ← 基础设施线导读 · DSA 全文:arXiv:2512.10576 · Chen et al., 2025(百度 Baige AI) 对象模型:DeepSeek-V3.2-Exp · 框架:SGLang · 场景:PD 分离 Decode 阶段
一句话
论文提出 ESS(Extended Sparse Server):在 不改模型精度 的前提下,把 Latent-Cache(~83.2%) offload 到 CPU,GPU 上只留 Sparse Memory Pool(LRU 热子集) + 常驻 Indexer-Cache(~16.8%);靠 FlashTrans/UVA 解决 656B 小块 PCIe 传输、LRU-Warmup 降早期 miss、Layer-wise DA/DBA Overlap 掩盖 prefetch 延迟,仿真上 32K 吞吐 +69.4%、128K 最高 +123%。
论文要解决什么
| 矛盾 | 说明 |
|---|---|
| DSA 降了算力 | 稀疏 attention 减轻计算,但 Decode 仍是 PD 架构瓶颈 |
| Latent-Cache 线性涨 | 序列越长 cache 越大 → batch size 被 GPU HBM 卡死 |
| 小块 PCIe 传输 | 每步 top-2048 个 656B entry 分散 → 原生 cudaMemcpyAsync H2D 仅 ~0.79 GB/s |
核心观察:top-$K$ latent 的 index 在 相邻 decode step 高度相似(层内相似度 $r_t^l$ 高,见 Fig.2)→ offload 可行,前提是 高命中率 + 高有效带宽 + 计算通信重叠。
图/表优先 手动截图 放入
screenshots/,运行python3 scripts/figures/ess/install_screenshot.py --inbox;未手动的图仍可用python3 scripts/figures/ess/extract_paper_figures.py从 PDF 裁剪。
系统划分
| Cache | 占比 | ESS 策略 |
|---|---|---|
| Indexer-Cache | ~16.8% | 不 offload;每步全长算 indexer |
| Latent-Cache | ~83.2% | CPU Total Memory Pool 存全量;GPU Sparse Memory Pool 存热子集 |
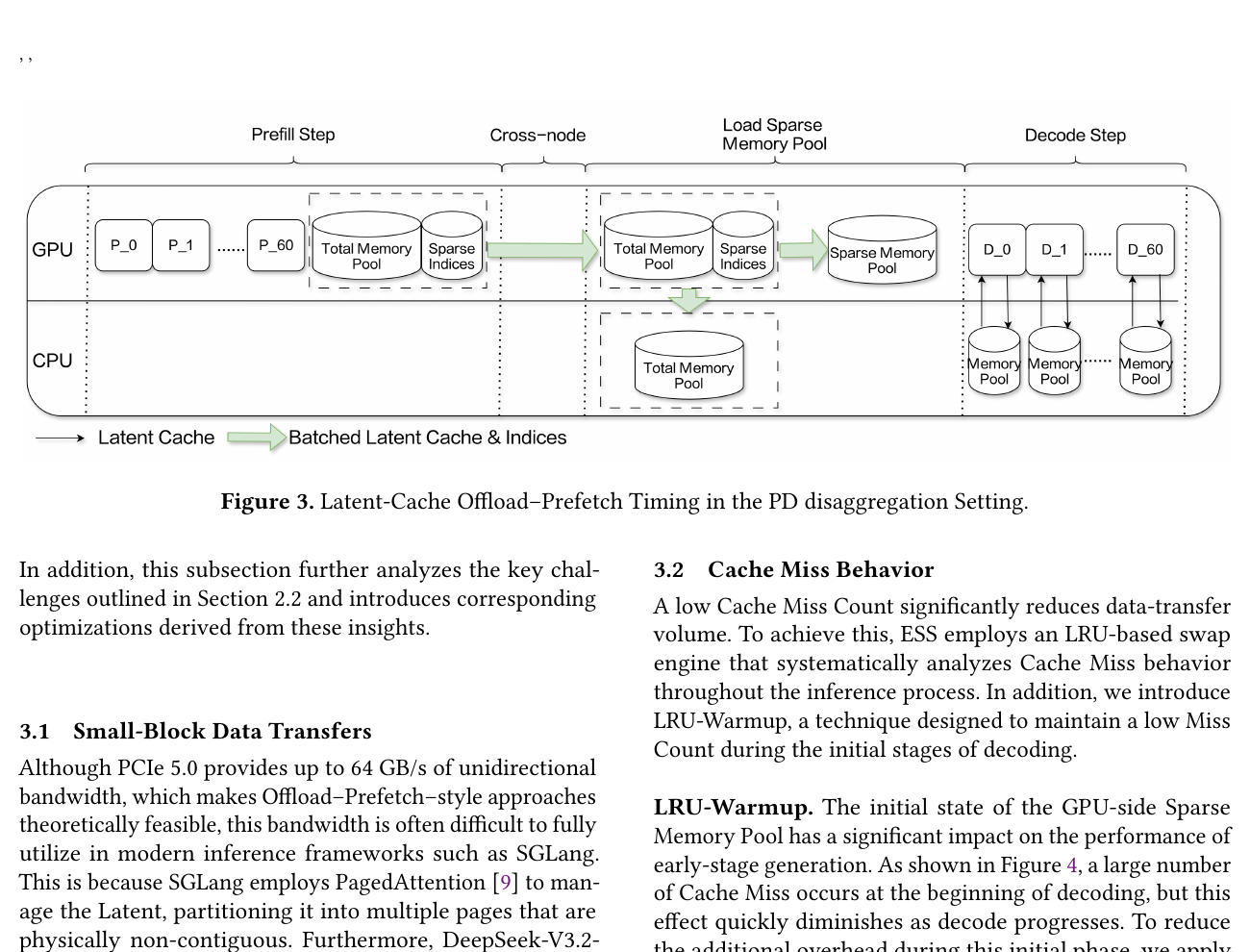
Figure 3. Latent-Cache Offload-Prefetch Timing in the PD disaggregation Setting.
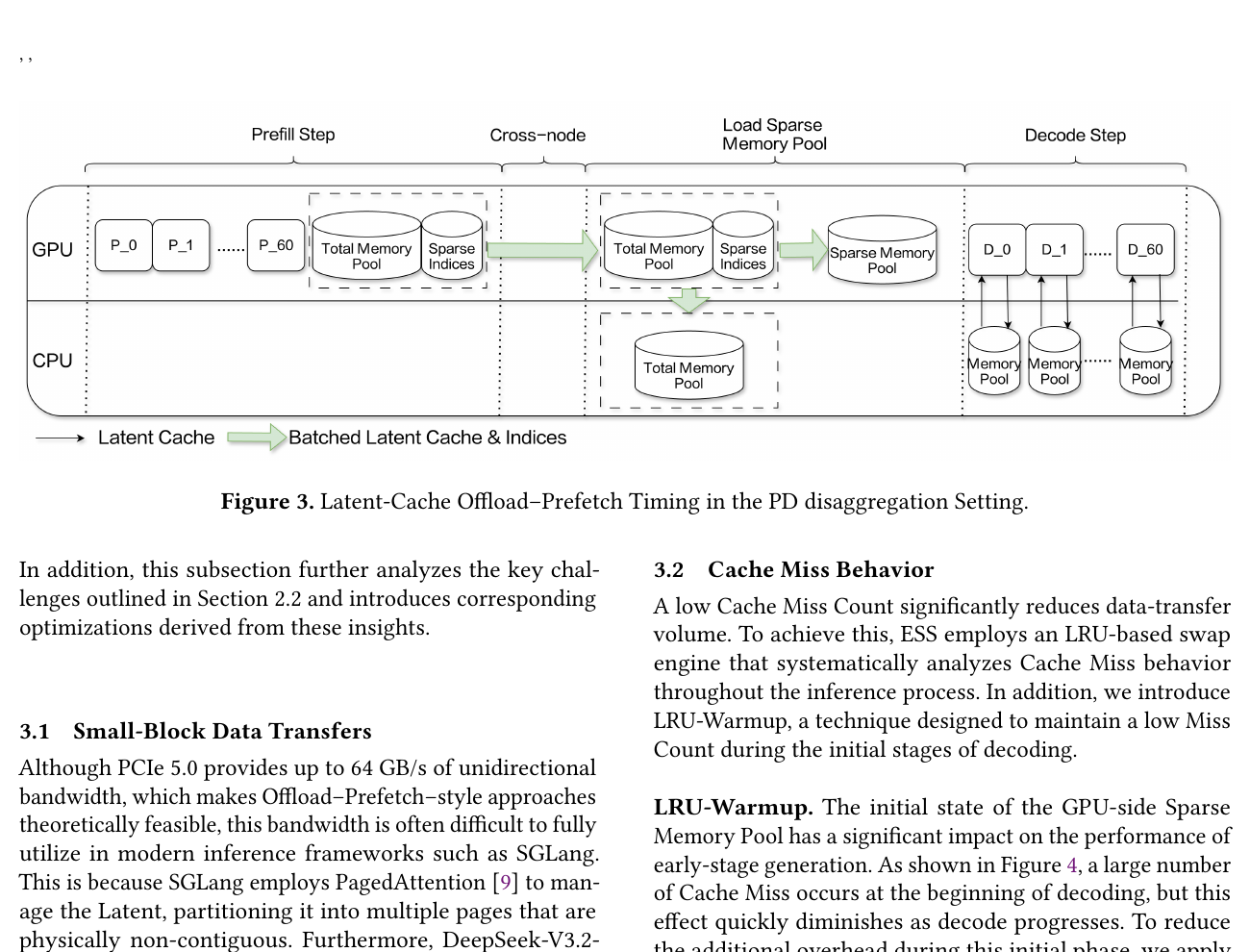{kind=link}
关键图解读
Figure 1 — 吞吐 vs Batch Size
| 要点 | 内容 |
|---|---|
| 设置 | 32K context,配置见 Table 1 |
| 现象 | 理论上调 batch 应持续提吞吐,但 GPU 显存先满 |
| 数据 | batch 最多 52,吞吐封顶 ~9,648 tokens/s |
| 结论 | 显存是 Decode 扩容天花板 → 必须 offload Latent-Cache 才能继续加大 batch |
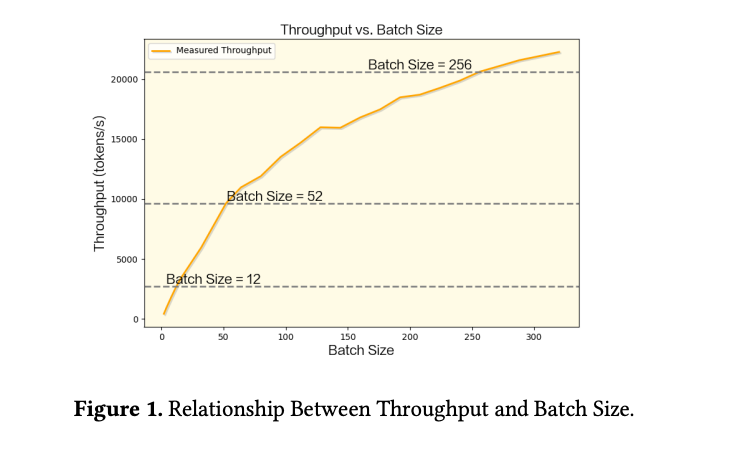{kind=link}
Figure 2 — 层内访问相似度
| 要点 | 内容 |
|---|---|
| 指标 | Intra-Layer Similarity $r_t^l = |K_{t-1}^l \cap K_t^l| / |K_t^l|$ |
| 含义 | 同一层、相邻 decode step 的 top-$K$ index 集合 重叠比例 |
| 数据 | LongBench V2 上 相似度持续偏高 |
| 结论 | Latent-Cache 访问有 强时间局部性 → CPU 扩展 HBM 有意义 |
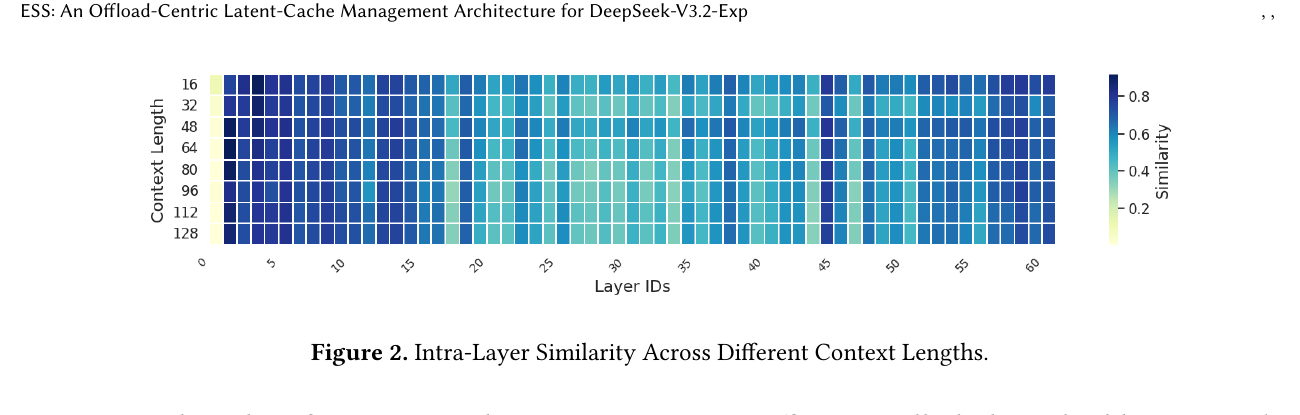
Figure 2. Intra-Layer Similarity Across Different Context Lengths.
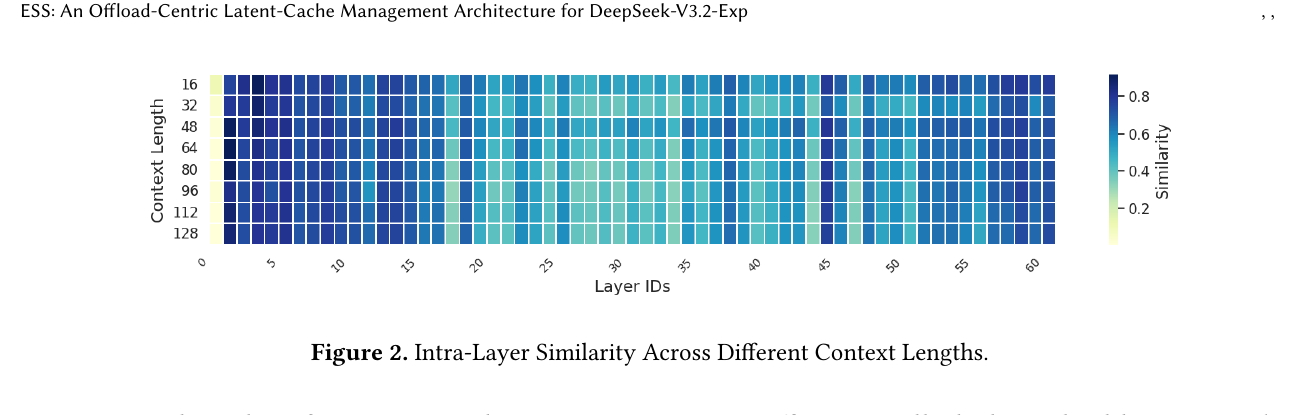{kind=link}
Figure 3 — PD 架构下 Offload/Prefetch 时序
见 系统划分(Fig.3)(仅保留原图与图注,不重复解读)。
Figure 4 — LRU-Warmup 对早期 Cache Miss 的影响

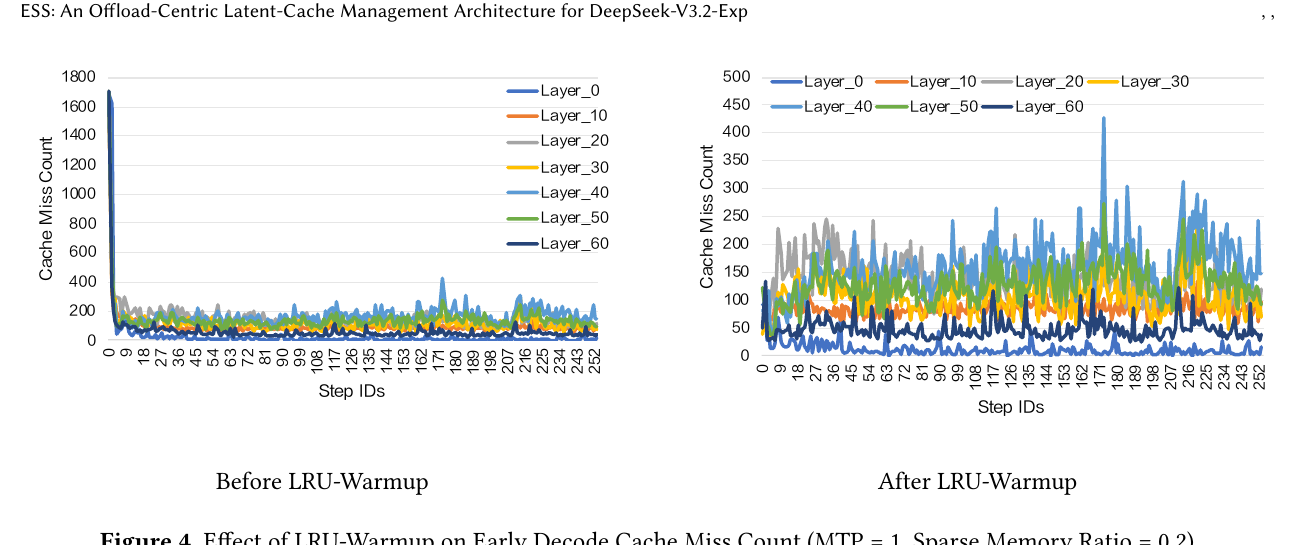{kind=link}
| 对比 | 现象 |
|---|---|
| Warmup 前 | Decode 开头 大量 Cache Miss,很快衰减 |
| Warmup 后 | 早期 miss 显著下降 |
| 做法 | 取 Prefill 最后 32 个窗口 的 top-2K index,预热 GPU LRU 池 |
| 设置 | MTP=1,Sparse Memory Ratio=0.2 |
Figure 5 — 层内 Cache Miss 分析
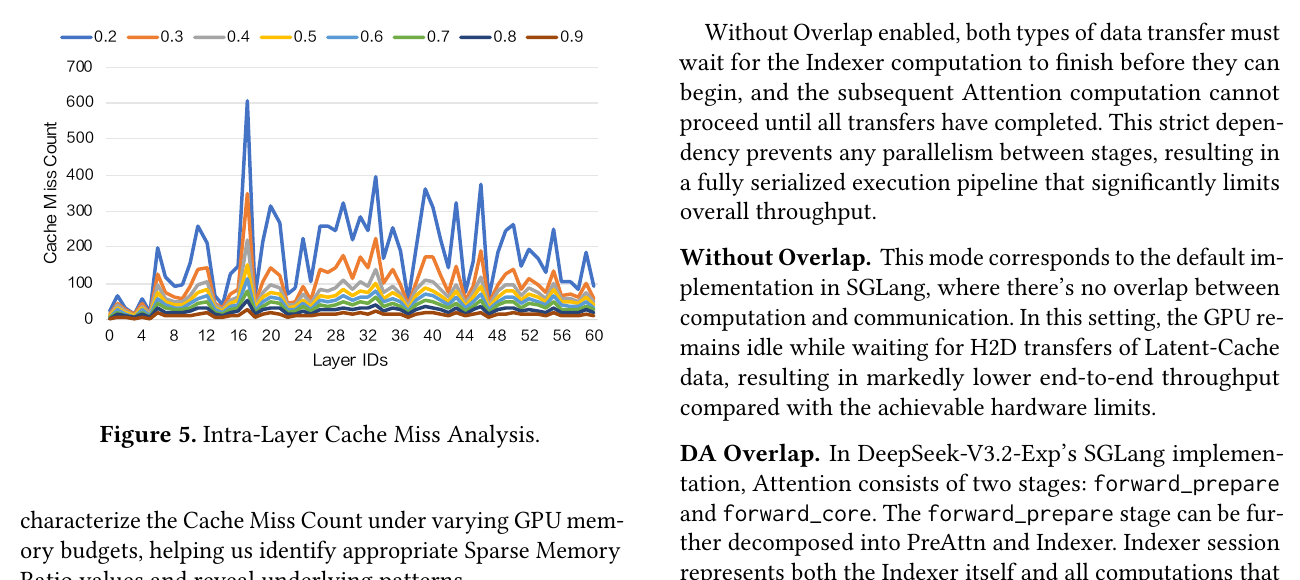
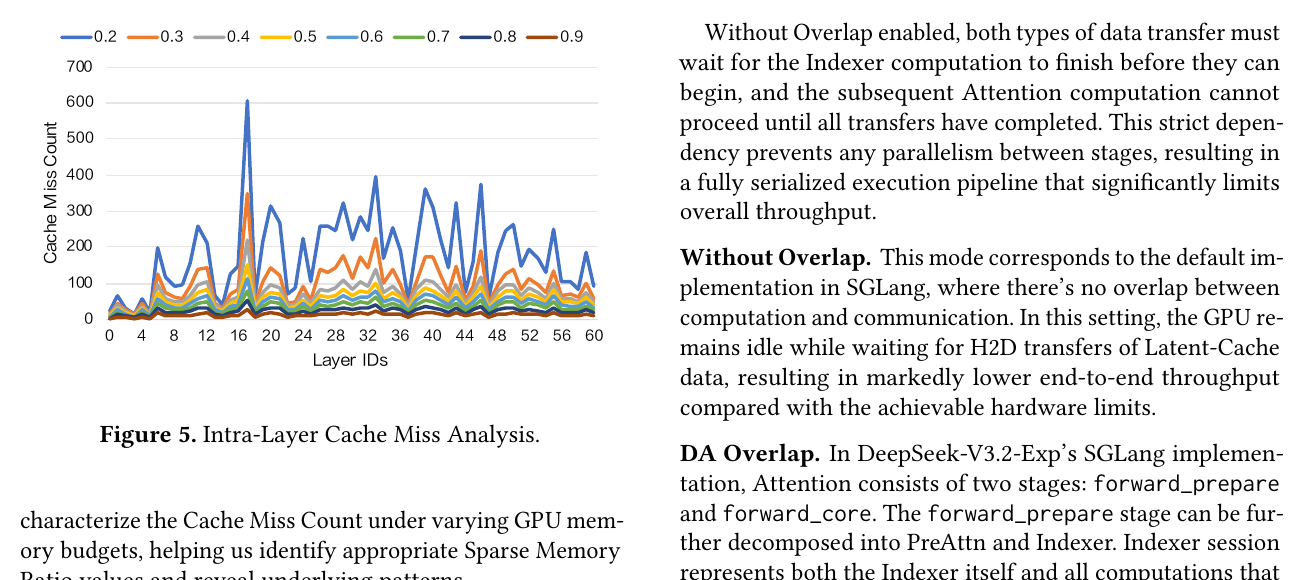{kind=link}
| 要点 | 内容 |
|---|---|
| 横轴 | Layer ID |
| 纵轴 | 每 batch 平均 Latent-Cache miss 数 |
| 变量 | 不同 Sparse Memory Ratio(GPU 侧占全 cache 比例) |
| 结论 | 不同层 miss 差异极大(Ratio=0.2 时约 16.66~605)→ 需要 按层选 Overlap 策略(见 Fig.7、§3.3) |
Figure 6 & 7 — Overlap 策略对比
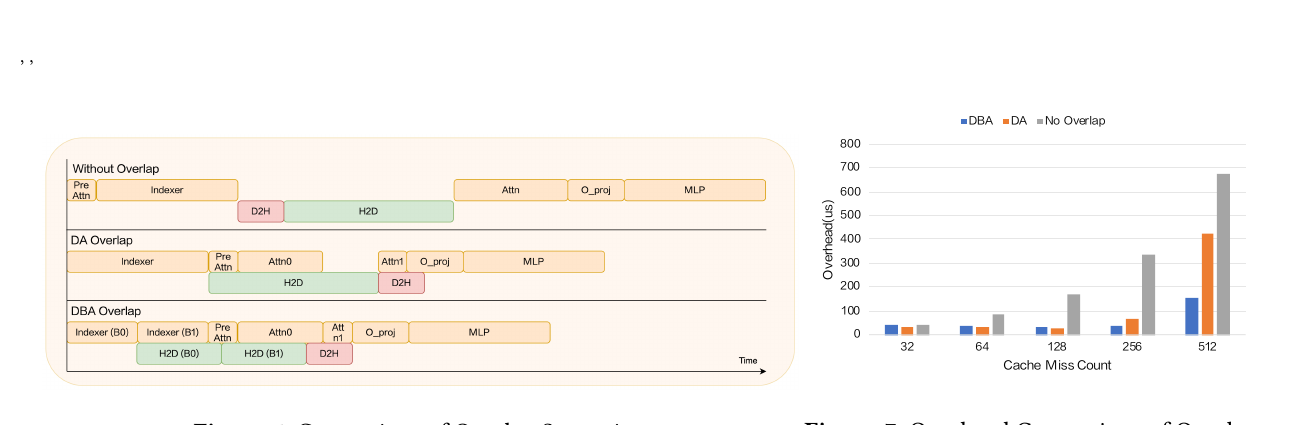
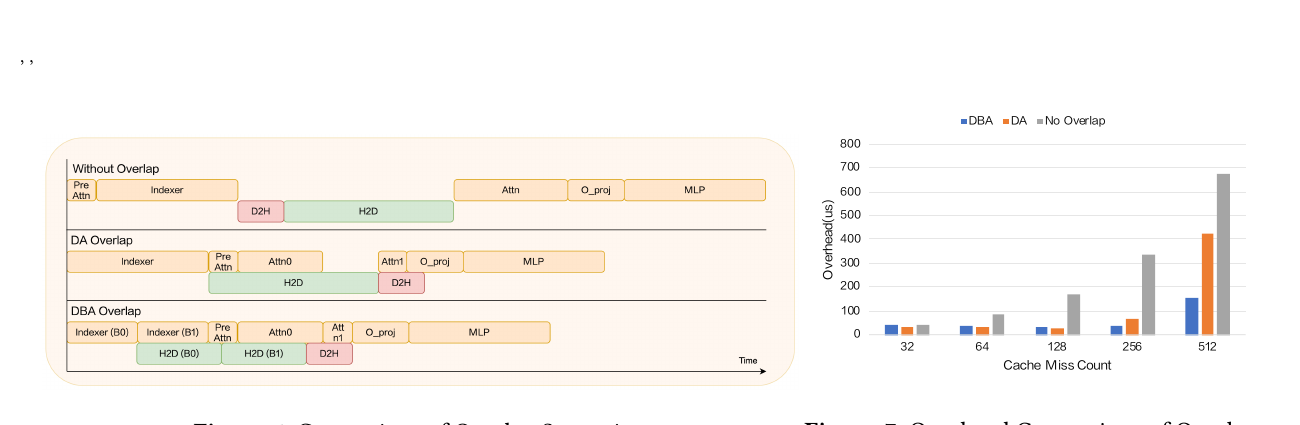{kind=link}
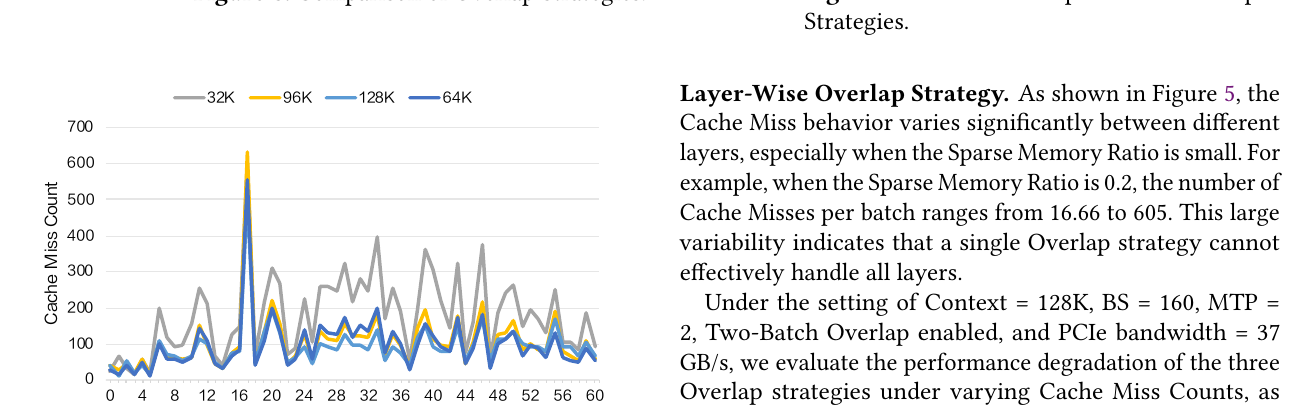
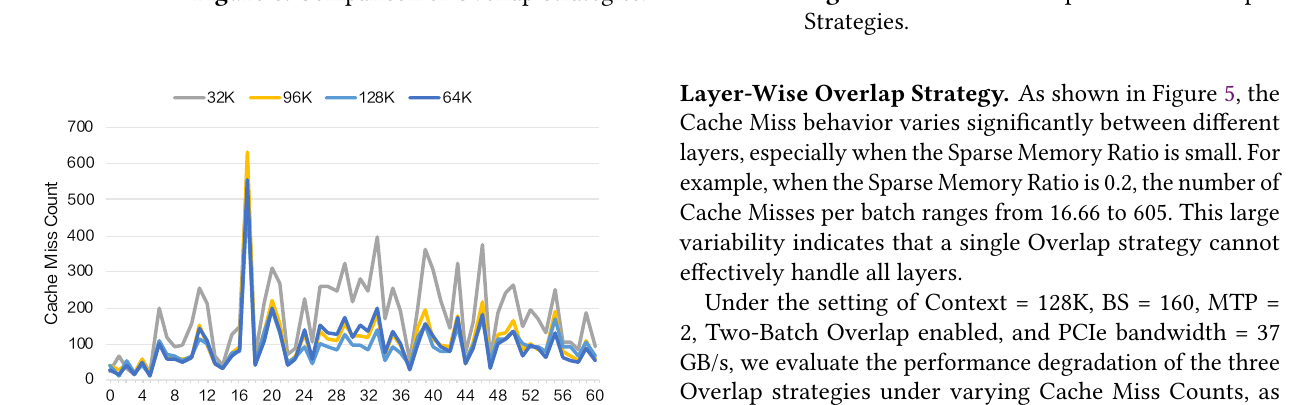{kind=link}
无 Overlap(SGLang 默认)
- H2D 必须等 Indexer 完成;Attention 必须等 H2D 完成 → 全串行,GPU 空等。
DA Overlap(Dual-Attention)
- 拆
forward_prepare:PreAttn 延后;SparseMLA 拆 Attn0(用 GPU 已有 latent)与 Attn1(等 prefetch)→ Attn0 ∥ H2D。
DBA Overlap(DualBatch-Attention)
- 在 DA 基础上 按 batch 维切 Indexer(含
paged_mqa_logits+ Top-K)→ 长上下文下仍有足够计算量掩盖传输。 - Fig.7 时间线:对比 DA vs DBA 的实际重叠程度。
Layer-Wise 选择规则
| Miss 水平 / 上下文 | 更优策略 |
|---|---|
| Miss 较低 | DA(无 Indexer 切分开销) |
| Miss 高(如达 512)、长上下文 | DBA(Indexer 计算随 $L$ 线性增,更能藏传输) |
Figure 8 — 不同上下文长度下的 Cache Miss

{kind=link}
- MTP=2,Ratio=0.2。
- 层维 miss 分布形态跨长度一致 → 可 离线 profiling 标出「高 miss 层」。
- 用于 Layer-Wise Overlap 的 静态分层配置。
Figure 9 — 可扩展性

{kind=link}
| 发现 | 含义 |
|---|---|
| Ratio ≥ 0.2 时,平均 miss 随长度 相对稳定 | 长上下文下 offload 行为可预测 |
| 32K + 小 Ratio miss 最严重 | GPU 热池太小 → 频繁换入换出 |
| 同 Ratio 下,更长 context → 更低平均 miss | ESS 在 128K 等超长场景收益更大(与 Table 2 的 +123% 一致) |
| 建议 | GPU buffer 不小于 6.4K entry |
关键表解读
Table 1 — 仿真基线配置
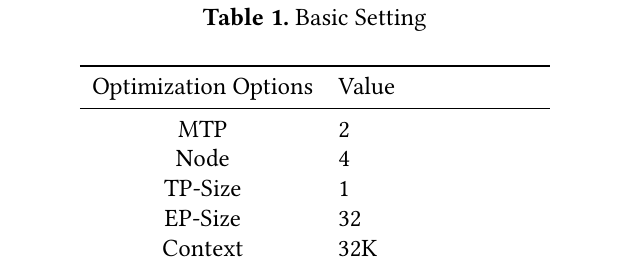
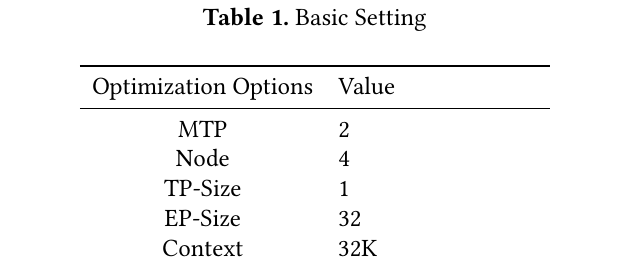{kind=link}
| 项 | 值 | 读表注意 |
|---|---|---|
| Model | DeepSeek-V3.2-Exp | 与 DSA 稀疏 attention 配套 |
| Context | 32K(主实验) | 128K 另有一组 |
| Node / EP | 4 node,EP=32 | 大规模 MoE 部署 |
| MTP | 2(主);Table 2 含 4 | 与 speculative 接受率联动 |
| MTP-Accept-Ratio | 1.7 | 影响有效 OTPS |
| Attention-Engine | FlashMLA | 与 DeepSeek 推理栈一致 |
| Two-Batch Overlap | open | 系统级重叠优化已开 |
| PCIe | 5th gen | FlashTrans 带宽前提 |
此表是 Fig.1、Table 2 默认行 的复现环境;改 MTP / 接受率 / 长度时只动 Table 2 中的变量。
Table 2 — 吞吐与 OTPS
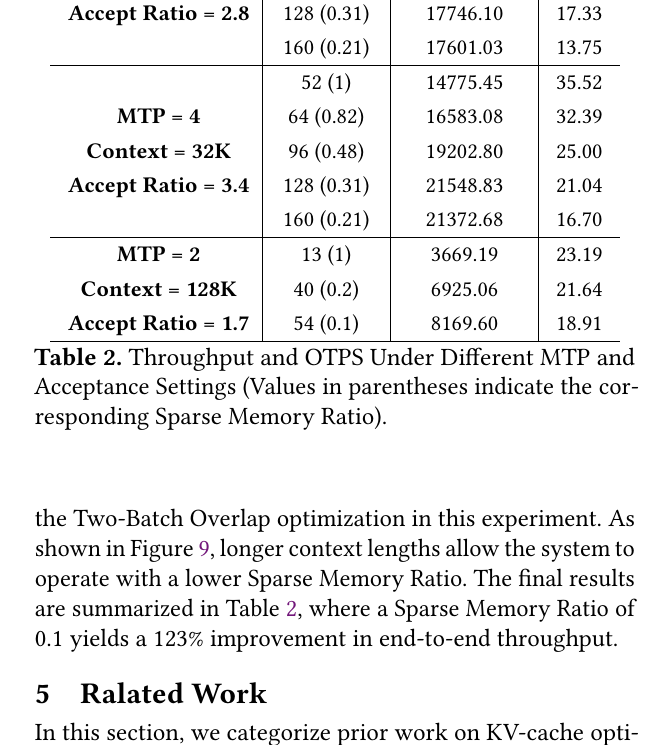
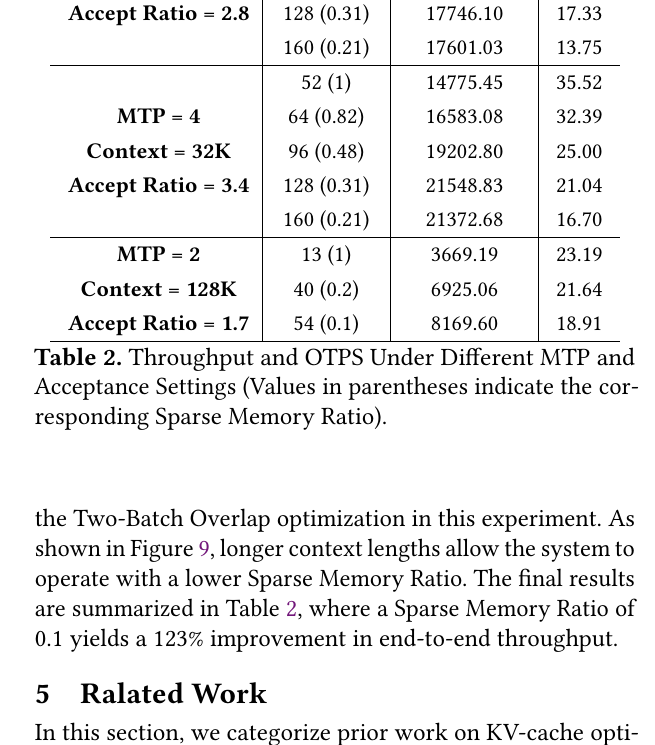{kind=link}
括号内为 Sparse Memory Ratio(GPU 热池占全 Latent-Cache 比例);Ratio 越小 → GPU 显存越省 → batch 可越大。
MTP=2,Context=32K,Accept=1.7
| Batch | Throughput (tokens/s) | OTPS | 相对基线 batch=52 |
|---|---|---|---|
| 52 (1.0) | 9,647.71 | 23.19 | 基线(全 GPU cache) |
| 64 (0.82) | 10,693.31 | 20.89 | |
| 96 (0.48) | 13,155.98 | 17.13 | |
| 128 (0.31) | 15,620.14 | 15.25 | |
| 160 (0.21) | 16,347.88 | 12.77 | +69.4% 吞吐 |
MTP=4,Context=32K — 接受率越高,绝对吞吐越高;ESS 仍随 Ratio 下降而扩容 batch。
MTP=2,Context=128K,Accept=1.7
| Batch | Throughput | Ratio | 备注 |
|---|---|---|---|
| 13 (1.0) | 3,669.19 | 基线 | 极短 batch 上限 |
| 40 (0.2) | 6,925.06 | ||
| 54 (0.1) | 8,169.60 | +123% 吞吐 |
读表要点
- Throughput ↑ 往往伴随 OTPS ↓:batch 变大、单 token 延迟结构变化;论文优化目标是 服务吞吐 / 成本,非单请求延迟。
- Ratio 从 1.0 → 0.1:用 CPU 换 GPU 显存,batch 可扩 3× 以上。
- 128K 行说明:越长上下文,ESS 相对收益越大。
三大工程模块
PD 分离下每步流程(对应 Fig.3):Prefill 结束 → Indexer 选 top-$K$ → prefetch 缺失 latent(H2D)→ Core MLA → 新 latent 写回 CPU(D2H)。Indexer 路径不搬;仅 Latent 在 CPU↔GPU 间流动。
| 模块 | 问题 | 方案 | 关键数字 |
|---|---|---|---|
| FlashTrans + UVA | 656B 碎片块,Memcpy 带宽差 | GPU 直接访 pinned CPU 地址 | H2D 0.79→37 GB/s;D2H 0.23→43 GB/s |
| LRU + Warmup | 早期 / 层间 miss 高 | Prefill 末 32 窗预热;LRU 保留高复用 entry | Fig.4、Fig.5 |
| DA / DBA / Layer-wise | 传输无法被计算掩盖 | Attn0∥H2D;按层选 DA 或 DBA | Fig.6–7 |
与静态/动态 KV 压缩、相关工作的边界
| 类型 | 代表 | 与 ESS 区别 |
|---|---|---|
| 静态压缩 | H2O、SnapKV、StreamingLLM | 永久删 KV;有损风险 |
| 动态选择 | Quest、MagicPig、RetrievalAttention | 每步只算子集,但 ESS 针对 V3.2-Exp 双 cache + 656B latent |
| Offload-Prefetch | FlexGen、SparseServe | ESS = DSA + MLA latent + PD + SGLang 的专用流水线 |
结论与局限
- 已验证:仿真中高保真;无损精度(只搬存储,不改 attention 数学)。
- 未做:论文写明 尚未并入生产框架;未来或与 SnapKV 等 有损压缩 组合。
- 本地对照:ESS Latent offload 概念页 · DSA 稀疏注意力 算法前置 · Index Share 正交 infra 补丁。
图表索引速查
| 图/表 | 一句话 |
|---|---|
| Fig.1 | 32K 下显存卡 batch=52 → offload 必要 |
| Fig.2 | top-$K$ index 逐步相似 → 局部性成立 |
| Fig.3 | PD 下 H2D/D2H 时序(仅图) |
| Fig.4 | LRU-Warmup 降早期 miss |
| Fig.5 | 各层 miss 不均 → 分层 overlap |
| Fig.6–7 | DA / DBA 时间线对比 |
| Fig.8–9 | 跨长度 miss 形态与可扩展性 |
| Table 1 | 仿真环境 |
| Table 2 | +69.4% / +123% 主结果 |
论文 PDF:arXiv:2512.10576
投机解码自测加速比
全文已并入唯一入口:投机解码与 DSpark(DeepSeek 推理加速) §3 外挂 draft 自测、§2 MTP、§4 范式总览。 ← V3 MTP · ← 演进总览 §3.3
本文件仅保留 重定向,避免与 投机解码与 DSpark 内容重复维护。
投机解码与 DSpark
← 中文导读 · ← 仓库首页(EN) · ← 演进总览 §2 时间线 · §3.3 V3 MTP · §3.7 V4 + DSpark · §6 推理栈 · V3 梗概 · V4 梗概 DSpark 开源:DeepSpec · DSpark_paper.pdf · DeepSeek-V4-Pro-DSpark 外部材料:版本演进总览 · V3 论文 MTP 原文摘录
本文档聚合 DeepSeek 系列 投机解码(speculative decoding) 与 DSpark 全部材料:通用循环、V3/V4 MTP、外挂 draft 自测、生产 MTP-1 基线、DSpark 机制与线上数据。演进总览 / V3 / V4 / 基础设施线 只保留链接,细节以本文为准。
1. 投机解码:为何能加速推理
场景:单流(batch=1)、自回归 decode。下文以 gpt2-small draft + gpt2-xl target 为例说明通用机制;DeepSeek 路线见 §2,自测数据见 §3。
1.1 瓶颈:每 token 搬一遍大模型权重
自回归生成严格串行:第 $N$ 个 token 必须等第 $N{-}1$ 个算完。每步都要把 target 全部权重从 HBM 搬进 SM(计算单元)(名词:SM;大矩阵 × 单向量,GEMV 算术强度极低)。
在 batch=1 decode 下,时间主要花在搬权重而非 FLOPS。因此:
- target 生成 1 个 token;
- target 一次并行验证 $k$ 个候选 token;
在带宽瓶颈下耗时 几乎相同(同样搬一遍权重,多算几位几乎不增时延)。
突破口:把「$k$ 次搬大模型权重」压成「1 次」,用便宜的 draft 换少跑几次 target。
答疑:Compute-Bound vs Memory-Bound — DFlash / Eagle 如何对应? — §1.1 的 Memory-Bound 串行读;§4 Eagle(draft 串行、$\tau_q \propto K$)vs DFlash(draft 并行、一次 HBM 流)。
1.2 一轮怎么走:draft → verify → accept
| 出 4 个 token 时($k{=}4$) | |
|---|---|
| 传统 | xl $\to t_1 \to$ xl $\to t_2 \to$ xl $\to t_3 \to$ xl $\to t_4$ → 4 次 target 前向 |
| 投机 | small 猜 $t_1 t_2 t_3 t_4$ → xl 并行验证 1 次 → 接受最长前缀(最多 4 个) |
① Draft(便宜)猜 $k$ 个 token
- 例:gpt2-small 权重约为 gpt2-xl 的 $\sim 1/12$,搬一次快得多。
- 小模型自回归猜出 $k$ 个候选,总代价远低于 xl 跑一步。
- 生产里 draft 也可来自 MTP 头、DSpark 草稿模块等(§2、§5),循环相同。
② Target(贵,但每轮只一次)并行验证这 $k$ 个
- 把 $k$ 个候选拼成长度 $k$ 的序列,一次前向喂给 xl。
- Attention 并行处理多个位置 → 1 次前向同时得到这 $k$ 个位置的概率分布。
- 耗时 $\approx$ 原来生成 1 个 token(同样只搬一遍 xl 权重)。
③ Accept / reject(保证 lossless)
用 xl 的真实分布逐位校验 draft(Leviathan et al. / Xia et al. 的 rejection sampling):猜中的连续前缀直接采纳;第一个猜错处用 xl 分布重采 1 个,其后丢弃,进入下一轮。单步「提议 → 校验」的概率含义见 §1.3。
端到端加速取决于:
| 杠杆 | 含义 |
|---|---|
| 每轮接受长度 | 平均每次 target 前向收下几个 token(头号因素) |
| draft 成本 | 猜 $k$ 个要花多少小模型前向;过大或命中率太低会吃掉收益 |
| 验证占用(高并发) | target 算力是否花在「高存活概率」前缀上(DSpark §6) |
1.3 净收益、lossless 与最坏情况
设单次 target 前向耗时 $\approx T$(与 $k$ 弱相关):
| 传统($k$ 步) | 投机($k$ 候选,全接受) | |
|---|---|---|
| target 前向 | $k$ 次 | 1 次 |
| 产出 token | $k$ | $k$ |
| 单次 target 耗时 | $T$ | $\approx T$ |
- 猜得准:1 次 target 吐出多个 token → 理论 $\approx k\times$,实际约 2–3×(§3 Qwen 自测 2.4–2.9×),需扣除 draft 开销。
lossless:rejection sampling 保证与「逐 token 采样 target」同分布;draft 只改 $q$ 与接受有多快,不改输出分布。
答疑:接受路径、拒绝路径与 lossless 证明 — 单步 $X \sim q$、$U \le \alpha(X)$ 校验;$E_{\mathrm{acc}}(x)$ 上 $P=q\alpha$;$\alpha=\min(1,p/q)$ 与 $p_{\mathrm{resample}}\propto\max(0,p-q)$ 合并得 $\pi(x)=p(x)$。
- 全猜错:target 仍 1 次前向,保底 1 个正确 token(与逐 token 相同);额外多花 $k$ 次 draft 小前向 → 最坏 $\approx$ 原速 $\times (1 + \text{小常数})$,略慢但不翻车。
1.4 PoC 参照
- gpt2-small(124M)+ gpt2-xl(1.5B):同 GPT-2 BPE、同词表,draft 权重约 target 的 $1/12$,无需训练即可验证约 2× 延迟收益;机理见 §1.1–§1.2。
- Qwen3-4B + 0.6B draft:本仓库 vLLM 自测见 §3。
2. DeepSeek 路线:MTP
V3 技术报告 引入 Multi-Token Prediction(MTP):在 主 next-token 目标 之外,用 $D$ 个串联 MTP 模块 预测 $t{+}2, t{+}3, \ldots$ 额外 token。训练时共享 Embedding / Output Head;每层 MTP 通过 Integration Layer 把 上一层 hidden 与 中间 token 的 Emb 融合后再过 1 个 Transformer Block。
中间 token 融合读图:MTP 融合 scheme · MTP 融合 scheme 图
{kind=link}
训练目标:
$$ \mathcal{L} = \mathcal{L}{\mathrm{main}} + \lambda \sum{k=1}^{D} \mathcal{L}_{\mathrm{MTP}}^{(k)} $$
- 主目标:提升主模型性能、数据效率。
- 推理:可 丢弃 MTP 模块、主模型独立 decode;也可 复用 MTP 模块做 speculative decoding 进一步降延迟。
V4 保留 MTP 模块与训练目标(与 V3 同族实现)。

{kind=link}
2.1 MTP 原生 vs 外挂 draft
| 维度 | MTP 原生(V3/V4) | 外挂 draft 小模型 |
|---|---|---|
| Draft 来源 | 同 checkpoint 的 MTP 辅助头 | 独立小模型(如 0.6B) |
| 额外显存 | 无第二套权重 | 需同时加载 target + draft |
| 接受率 | MTP 与主模型 联合训练 对齐 | 依赖 draft 与 target 分布匹配 |
| 训练目标 | $\mathcal{L}{\mathrm{main}} + \lambda \mathcal{L}{\mathrm{MTP}}$ | draft 常单独 SFT / 蒸馏 |
推理侧循环相同;差异只在 draft 从哪来。
2.2 生产基线 MTP-1
V4 Flash / Pro 预览引擎在 DSpark 上线前,生产环境采用 MTP-1:基于 MTP 的 单 token 推测解码基线(每轮 propose/verify 粒度为 1)。DSpark 相对 MTP-1 报告线上增益(§8),不是相对「无投机纯自回归」。
3. 外挂 draft 自测
性质:本仓库 2026-06 自测(vLLM 0.8.5,1000 条样本,单卡 L20)。非 DeepSeek MTP 官方数据,非 DSpark。
| 项 | 值 |
|---|---|
| 基线 | Qwen3-4B-Instruct nospec |
| 投机 | 4B target + 0.6B draft |
| 基线 RT | 459 ms / 条 |
| 方法 | mean RT | 加速比 |
|---|---|---|
| 4B nospec(基线) | 459 ms | 1.00× |
| vLLM ngram / PLD(无 draft) | 369 ms | 1.99× |
| Prefix cache + nospec | 454 ms | 1.61× |
| Draft 投机(4B + 0.6B) | 303 ms | 2.41× |
| Prefix cache + draft | 298 ms | 2.46× |
| Draft + target FP8 | 256 ms | 2.86× |
| Draft + target INT8 离线 | 272 ms | 2.69× |
| 手写 vanilla draft PoC | 1432 ms | 0.51× |
读法:
- 接受率与引擎成熟时,speculative decoding 相对单路 decode 可达 约 2.4–2.9× 延迟收益 → 可作为 MTP 原生投机 的工程量级参照,不替代官方 MTP 吞吐数据。
- draft 质量差时(PoC 0.51×),同属 speculative decoding 也会 慢于基线;MTP 的价值之一是把 draft 与主模型 绑在同一训练目标。
接受率参照:ESS 论文梗概 的 MTP-Accept-Ratio(如 1.7)描述 MTP 投机链路上 每轮平均接受长度 的量级,可与下文各草稿范式的块长、接受率对照阅读。
4. 草稿范式总览
每轮投机:草稿模型 $M_q$ 一次提出 $K$ 个候选,目标模型 $M_p$ 用时间 $\tau_p$ 做 1 次验证;草稿侧总耗时约为 $K \times \tau_q$($\tau_q$ 为与块长相关的单步 draft 代价,自回归路线下 $\tau_q$ 随 $K$ 线性累积)。设本轮 平均接受长度为 $\mathbb{E}[N_{\mathrm{acc}}]$($0 \le \mathbb{E}[N_{\mathrm{acc}}] \le K$),相对「每 token 各跑 1 次 $\tau_p$」的粗算加速比为:
$$ S_{\uparrow} = \frac{\bigl(\mathbb{E}[N_{\mathrm{acc}}] + 1\bigr),\tau_p}{K,\tau_q + \tau_p} $$
设计目标:要把 $S_{\uparrow}$ 做大,需 同时抬高 $\mathbb{E}[N_{\mathrm{acc}}]$(draft 猜得准、接受得长)并 压低 $K\tau_q$(draft 生成别太慢)。两项目标往往拉扯——下文各范式正是在这对矛盾上的不同取舍。
在 DSpark(及同期工业界的半自回归路线)成熟之前,外挂草稿 $M_q$ 长期分两派:Eagle 系(最新 Eagle3,自回归、高接受率)与 DFlash 系(并行整块、低 draft 延迟)。DeepSeek 另备 MTP 原生头(§2);DSpark 则在两派之间取 半自回归折中。
自回归 vs 半自回归:自回归(Eagle3)按 token 串行猜 draft,$\mathbb{E}[N_{\mathrm{acc}}]$ 高但 $K\tau_q$ 随块长 线性涨;半自回归(DSpark)先 并行出整块(压低 $\tau_q$ 侧),再用轻量 顺序头逐位补依赖(抬 $\mathbb{E}[N_{\mathrm{acc}}]$ 后缀)——并行拿速度,顺序补准确率。
| 路径 | 代表 | Draft 生成 | 对 $S_{\uparrow}$ 的侧重 |
|---|---|---|---|
| MTP 原生 | V3/V4 MTP 头 | 同模型辅助头,可 MTP-1 单步 | $\mathbb{E}[N_{\mathrm{acc}}]$ 与 target 对齐;无第二套 $M_q$ |
| 自回归外挂 | Eagle3 | 逐 token 串行 | 抬 $\mathbb{E}[N_{\mathrm{acc}}]$;$K\tau_q$ 大 |
| 并行外挂 | DFlash | 一次前向整块 | 压 $K\tau_q$;后缀 $\mathbb{E}[N_{\mathrm{acc}}]$ 易掉 |
| 半自回归外挂 | DSpark | 并行主干 + 顺序头 | 两者折中;V4 线上相对 MTP-1 |
| 独立小模型 | Qwen 0.6B draft | 另一套权重 | §3 自测量级参照 |
| 范式 | 优势 | 瓶颈 |
|---|---|---|
| Eagle3 | 块内依赖强、接受率稳 | draft 延迟 $\propto K$(Memory-Bound 串行,见 答疑) |
| DFlash | draft 延迟几乎与 $K$ 弱相关(Compute-Bound 并行,见 答疑) | 第 2 位起 $\mathbb{E}[N_{\mathrm{acc}}]$ 骤降 |
| DSpark | 一次并行出整块 + 后缀顺序补依赖 | 并行主干仍须生成完整 $K$ 块(§9) |
5. DSpark 概述
DSpark:面向 V4-Flash / V4-Pro 预览引擎 高并发 decode。用 半自回归草稿 + 置信度调度验证,相对生产基线 MTP-1,在 同等吞吐量 下单用户生成速度 +57%–85%(报道区间 60%–85%)。论文、训练代码、检查点:DeepSpec。

{kind=link}
6. DSpark 机制
6.1 半自回归候选生成
| 阶段 | 做什么 |
|---|---|
| 并行主干(DFlash 改进) | 一次前向 → 整块 hidden + 基础 logits |
| 轻量顺序模块 | 逐 token 注入前缀依赖:马尔可夫头(仅 $t{-}1$)或 RNN 头(完整前缀状态) |
2 层 Transformer 深度的 DSpark 在测试领域 平均每轮接受长度 超过 5 层 DFlash。
| 位置 | DFlash | Eagle3 | DSpark |
|---|---|---|---|
| 第 1 位 | 高(深并行网) | 受浅网限制 | 第 1 位 接近深并行网 |
| 第 2 位起 | 快速衰减 | 稳定/上升 | 顺序模块 缓解衰减 |
为何 draft 上能「堆叠多层」来抬接受率
投机解码的瓶颈在 块内逐位条件分布 是否与 target 对齐:第 $i$ 位 token 能否被接受,取决于 draft 提议分布 $q_i(\cdot)$ 能否逼近 target 在 同一条前缀 下的 $p_i(\cdot)=p(\cdot\mid\text{context}, x_{<i})$(校验时由 target 整段前向 得到,是 ground truth)。对齐的对象是分布 $q_i \approx p_i$,不是单说 hidden 相等。
外挂 draft(Eagle / DFlash / DSpark)的常见做法是:target 先给出(或缓存)某层 hidden $h$,再由投机模块 $f_{\mathrm{spec}}$ 叠若干层,必要时注入块内已猜 $x_{<i}$,输出 draft logits $\ell_i=f_{\mathrm{spec}}(h, x_{<i})$ → $q_i=\mathrm{softmax}(\ell_i)$。多一层 Transformer(或等价模块)就多一轮 $h \to \ell$ 的非线性修正,让 $q_i$ 更贴近校验时的 $p_i$,单点接受概率 $\uparrow$ → 前缀连乘后存活更长 → §4 的 $\mathbb{E}[N_{\mathrm{acc}}]$ $\uparrow$。
易混:MTP 原生 draft 不走「外挂 $f_{\mathrm{spec}}$」,而在 同一 checkpoint 内用 MTP 块接主模型 hidden 链出 logits(§2)。独立小模型 draft 甚至不读 target hidden,靠蒸馏/SFT 让整网 $q$ 逼近 $p$(§3)。
关键不在「层数越多越好」,而在 堆的是什么依赖:
| 堆法 | 补齐的依赖 | 对 $\mathbb{E}[N_{\mathrm{acc}}]$ 的典型效果 |
|---|---|---|
| 加深并行 Transformer(DFlash) | 各位 共享 target 前缀,互不见 块内已猜 $x_{<i}$ | 第 1 位随深度变强;第 2 位起缺 块内因果 → 接受率 快速衰减;加到 5 层也难救后缀 |
| 串行再算(Eagle3) | 每步 draft 显式看见 上一位已猜 token | 后缀稳定/上升;代价是 $K\tau_q$ 随块长 线性涨(§4) |
| 并行主干 + 顺序模块(DSpark) | 单轮 draft 一次前向并行猜 $K$ 位(尤其保第 1 位);马尔可夫/RNN 头 逐位注入 $x_{i-1}$ | 2 层 总深度即可超过 5 层 纯并行 DFlash(上表实证句) |

{kind=link}
因此 DSpark 的「堆叠」是 两阶段叠在同一轮 draft:先用并行主干 一次前向出整块 $K$ 位(低 $\tau_q$、第 1 位接近 DFlash),再用极轻的顺序头做 因果方向的层叠(等价于在后缀位上补 Eagle 式依赖,而不付满额 $K$ 次串行大前向)。V3 MTP 因果链(Main → MTP-1 → MTP-2)则是 target 权重内的另一种「按步数堆模块」:每多一块 MTP 模块,多预测更远 $t{+}k$,推理可作原生 draft(§2)。
文献与对照:DSpark_paper.pdf(Semi-Autoregressive Draft;深度 vs 接受长度消融)· §2 MTP 因果链 · MTP 投机解码总览图 · 加速比读法 §4 · 酱紫君解读:半自回归 draft
6.2 置信度调度验证
- 每候选位置输出 置信度(此前缀全接受条件下该 token 存活概率);
- 验证集 温度缩放 校准置信度 $\approx$ 经验接受率;
- 硬件感知前缀调度器:结合并发请求置信度 + 实测吞吐量曲线,为每请求动态选验证长度,最大化全局吞吐。
负载自适应:低并发验证 4–6 token;高并发 平滑缩短,避免争用。

{kind=link}
7. DSpark 离线基准
Target:Qwen3(4B/8B/14B)、Gemma4-12B · 对比:Eagle3、DFlash 任务:数学 / 代码 / 对话(GSM8K、MATH500、AIME25、MBPP、HumanEval、LiveCodeBench、MT-Bench 等)
| 指标 | 结果 |
|---|---|
| 平均每轮接受长度 | DSpark 全面优于 两基线 |
| Qwen3-4B | vs Eagle3 +30.9%,vs DFlash +16.3% |
8. V4 生产部署
| 项 | 配置 |
|---|---|
| 绑定模型 | V4-Flash / V4-Pro 预览引擎 |
| 并行主干 | 3 MoE 层 + 滑动窗口注意力 |
| 最大候选块 | 5(DSpark-5) |
| 顺序模块 | 马尔可夫头 |
| 对比基线 | MTP-1 |
9. 训练与在线引擎
范畴:DSpark 线上推理(§8、§10)不改 V4 基座权重,是纯 decode 加速栈。**本节「训练」指 DeepSpec 里 外挂 draft 模块(DSpark / DFlash / Eagle3)的 训练与蒸馏管线;「在线引擎」**指该 draft 接入 V4 预览引擎后的调度与 kernel 集成。二者都不是 V3/V4 主模型预训练。
9.1 训练优化
| 优化 | 说明 |
|---|---|
| 隐状态通信 | 只传 target hidden state,不传词表 logits:$O(V) \to O(d)$ |
| 锚点定长打包 | 多预测块压成密集 batch,减 padding 浪费 |
9.2 引擎集成
| 约束 | 对策 |
|---|---|
| CUDA Graph 需提前定 batch 大小 | 异步调度:截断长度用 两轮前 历史置信度预测 |
| 动态变长验证 → kernel padding 浪费 | token 展平 + 稀疏 attention 标记张量 传依赖;改索引 attention / 压缩 kernel |
10. 在线生产实测
真实用户流量(2026-06 报道口径):
V4-Flash
| SLA(单用户 $\ge$ … token/s) | 聚合吞吐量 vs MTP-1 |
|---|---|
| 80 | +51% |
| 120(MTP-1 近边界) | +661% |
V4-Pro
| SLA | 聚合吞吐量 |
|---|---|
| 35 token/s | +52% |
| 50 token/s | +406% |
同等吞吐量下单用户速度 +57%–85%。
11. 局限与边界
局限:调度器截断后缀后,并行主干仍生成完整候选块;低接受率复杂查询的草稿算力 不可回收。
| 项 | 说明 |
|---|---|
| 不是新基座 | 与 V4 同 checkpoint;DeepSeek-V4-*-DSpark = target + 投机模块 |
| 不是 KV / offload | 与 ESS、Index Share 正交 |
| 不是 V3 MTP 论文本身 | MTP 是训练结构;DSpark 是 V4 线上 独立 draft/verify 栈,基线 MTP-1 |
12. 开源与外部材料
DeepSpec
| 内容 | 说明 |
|---|---|
| DSpark | config/dspark/、评测、检查点 |
| DFlash / Eagle3 | 对照草稿训练评测 |
| 推理 | inference/ 最小 demo |
| 论文 | DSpark_paper.pdf |
| HF | DeepSeek-V4-Pro-DSpark |
第三方解读
| 材料 | 说明 |
|---|---|
| 酱紫君(GalAster):DSpark 与投机解码 | 投机背景、半自回归 draft、验证截断、MTP 融合、draft 训练 vs fine-tune;知乎原文 |
| 批量验证机制笔记 | 目标模型单次前向并行验 K 个 draft token |
13. 在全景中的位置
14. 参考
- DeepSeek-AI & Peking University. DSpark — DeepSpec
- DeepSeek-AI. DeepSeek-V3 Technical Report. arXiv:2412.19437 — MTP 训练与推理复用
- DeepSeek-AI. DeepSeek-V4. arXiv:2606.19348
- Leviathan, Y., Kalman, M., & Matias, Y. Fast inference from transformers via speculative decoding. 2022.
- IT之家. DeepSeek 联合北大发布 DSpark. 2026-06-27
V4 KV Layout:Classical + State 双池
← 中文导读 · ← 仓库首页(EN) · ← 演进总览 §5.3 KV layout · ← 基础设施线导读 · CSA/HCA 算法专文 · V4 梗概 §推理 infra · 并列 HiSparse · 并列 磁盘 Prefix Cache · 上游 ESS 论文:arXiv:2606.19348 §3.5.1 — DeepSeek-V4 演进总览 §5.3 只保留梗概;layout 细节以本文为准。
一句话
V4 推理引擎不再用「每层每 token 一条同质 latent」,而是把 CSA/HCA 压缩 entry 放进按 $\mathrm{lcm}(m,m')$ 对齐的 Classical KV cache,把 SWA(Sliding Window Attention,滑动窗口注意力)+ 未凑满压缩块的 tail buffer 放进每请求固定大小的 State cache——两类池子尺寸、生命周期、读写模式不同,是后续 HiSparse offload 与磁盘 prefix 的内存布局前提。
答疑:SWA(Sliding Window Attention) — 最近约 128 token 的精确未压缩 K/V,与 CSA/HCA 分池,eviction 与 prefix 策略独立
为什么 V3/V3.2 的单一 layout 不够
| 代际 | Cache 形态 | 问题 |
|---|---|---|
| V3 / V3.1 | 同质 MLA latent,每层每 token 同 shape | 1M token 下 HBM 与带宽双瓶颈 |
| V3.2 ESS | Indexer-Cache + Latent-Cache 两类,但仍是 每 token 一条 | ESS 只 offload Latent;layout 仍是 DSA 的 per-token 流 |
| V4 | CSA 4:1、HCA 128:1、SWA、Indexer、tail 五类对象 | 压缩比 $m{=}4$、$m'{=}128$ 不同 → 块对齐、尾缓冲、SWA 窗口必须 分池管理(见下) |
答疑:为何要分池?块对齐与尾缓冲 — Classical 只存满块不可变 entry;State 存 tail + SWA;$\mathrm{lcm}(4,128){=}128$ 统一两种压缩边界
算法侧五类 entry 见 CSA/HCA 专文 §4 · V4 梗概 与 演进总览 §5.3 表格;本文只讲引擎如何把它们落进内存。

{kind=link}
Classical KV cache
服务对象:已凑满压缩块的 CSA entry(stride $m{=}4$)与 HCA entry(stride $m'{=}128$)。
| 项 | 说明 |
|---|---|
| 对齐粒度 | 按 $\mathrm{lcm}(m,m') = \mathrm{lcm}(4,128) = 128$ token 对齐的压缩块 |
| 为何 lcm | CSA 每 4 token 一条、HCA 每 128 token 一条;同一物理块需同时满足两种压缩器的块边界,避免跨层/跨类型碎片 |
| 生命周期 | 随 prefix 增长 append;压缩完成后 entry 不可变,适合 prefix 共享与落盘 |
| 读模式 | CSA:top-$k$ 稀疏读;HCA:对 ~$L/128$ 条 entry dense attend(1M context ≈ 8K entry) |
Together.ai 部署解读强调:V4 的难点不在 attention kernel 本身,而在 多种 cache 对象的 batching、eviction 与 prefix 复用(Serving DeepSeek-V4 §「multiple KV-cache layouts」)。
State cache
服务对象:
| 组件 | 含义 |
|---|---|
| SWA | Sliding Window Attention 的 精确局部 K/V;窗口约 128 token,独立 eviction |
| Tail buffer | 不足 $m$(CSA)或 $m'$(HCA)个 token 的 未压缩尾;等待凑满后再写入 Classical 池 |
| Indexer KV(若与 state 同池实现) | CSA lightning indexer 的轻量向量;与主 attention entry 维度不同 |
| 项 | 说明 |
|---|---|
| 分配方式 | 每请求固定大小块(per-request state block),便于 batch 内不同序列长度对齐 |
| 生命周期 | SWA 随 decode 滑动更新;tail 在凑满前 可变 |
| 与 Classical 的分工 | Classical 存「已定型」压缩历史;State 存「仍在形成中」的局部与尾 |
论文 §3.5.1 的 State cache 是 SWA + tail 的归宿;部署上 SWA 往往占 per-token 体积大头(Together 早期 bring-up:全量 SWA 时 per-token KV 甚至略高于 V3 路径),因此 cache 策略(存多少、何时 evict)比压缩算法本身更决定并发容量——见 HiSparse 专文。
与 ESS / HiSparse 的关系
| ESS(V3.2) | V4 KV layout(本文) | HiSparse | |
|---|---|---|---|
| 层级 | 算法已分裂 Indexer/Latent;ESS 管 offload 策略 | 定义 Classical vs State 物理布局 | 在 layout 之上把 inactive C4 搬出 GPU |
| 可否叠加 | — | layout 是 HiSparse / 磁盘 prefix 的 前置 | 依赖 CSA 4:1 entry 的 稀疏激活 |
V4 不是把 ESS 的 Latent-Cache 直接放大到 1M;而是 换一套异构压缩 layout 后再做分层内存(ESS §与 V4)。
基础设施线位置
| 方向 | 文档 |
|---|---|
| 本专题(layout 基础) | 演进总览 §5.3 |
| infra 线 ⑤ 子项 | 基础设施线导读 §1 |
| 并列 offload | HiSparse · 磁盘 Prefix Cache |
| 上游 ④ ESS | ESS Latent offload |
| 算法依赖 | CSA / HCA · V4 梗概 · 算法线 §③ |
延伸
| 资源 | 说明 |
|---|---|
| 演进总览 §5.4 | V3 / V3.2 ESS / V4 三代 offload 对照 |
| Together.ai — Serving V4 | 多 layout 并存的 serving 含义 |
| V4 异构 KV 总览图 | Classical + HiSparse 分层示意图 |
论文:arXiv:2606.19348 §3.5.1
V4 HiSparse:inactive C4 entry CPU offload
← 中文导读 · ← 仓库首页(EN) · ← 演进总览 §5.3 HiSparse · ← 基础设施线导读 · CSA/HCA 算法专文 · V4 梗概 §推理 infra · 前置 KV layout · 并列 磁盘 Prefix Cache · 上游 ESS · 正交 DSpark 部署参考:Together.ai — Serving DeepSeek-V4(2026-05,HGX B200 bring-up) 演进总览 §5.3 只保留梗概;HiSparse 机制与数据以本文为准。
一句话
HiSparse 是面向 V4 CSA 4:1 压缩层(C4) 的 GPU/CPU 分层 cache 策略:decode 每步仅 top-$k$ 稀疏激活 少量压缩 entry,其余 inactive entry offload 到 CPU pinned memory;GPU 只保留 active 热工作集,从而在单节点上把可服务 token 容量从约 1.2M 提升到 ~3.7M(约 3×,B200 部署实测口径)。
为何需要 HiSparse
| 维度 | ESS(V3.2) | HiSparse(V4) |
|---|---|---|
| Cache 结构 | 同质 Latent-Cache([per-token MLA) | CSA/HCA/SWA/Indexer/tail 异构](05-V4-KV-Layout.md) |
| Offload 粒度 | 按 latent entry;依赖 DSA top-$k$ 时间局部性 | 按 C4 压缩 entry;依赖 CSA 空间稀疏激活 |
| Indexer | GPU 常驻 | V4 indexer 仍参与 CSA 路径;layout 见 DeepSeek-V4 |
| 可否直接迁移 | — | 否 — 须先实现 §3.5.1 双池 layout |
V3.2 上 Index Share + ESS 可同开;V4 则需要 HiSparse + 定制 layout + prefix 策略(演进总览 §5.4)。
核心机制
| 组件 | 作用 |
|---|---|
| C4 压缩 entry | CSA stride-4:每 4 token 一条 KV;1M context 约 250K 条(再经 top-$k$ 只读子集) |
| Active 集 | 当前 decode step indexer 选中的 ~128 条 CSA entry + 必要 HCA/SWA 局部 |
| Inactive 集 | 全长 prefix 中 本步未参与 attention 的 C4 entry |
| CPU pinned pool | Inactive entry 驻留 主机 pinned memory;GPU miss 时 prefetch 回 HBM |
| GPU 热池 | LRU(或类似策略)维护 active 工作集;与 ESS Sparse Memory Pool 思想类似,但 entry 形态为压缩块 |
图示详情 · 图下半区标注 HiSparse offload
局部性依据:CSA 每步 top-$k$ 选中的压缩块在相邻 decode step 间 重叠率高(类比 ESS 的 index 时间相似度);多数所需 entry 已在 GPU,少量 cold entry 从 CPU 拉回。
部署数据
| 指标 | 数值 | 说明 |
|---|---|---|
| 平台 | NVIDIA HGX B200 单节点 | Together 早期 V4 bring-up |
| 优化前容量 | ~1.2M tokens | 默认 cache 策略下总 KV 预算 |
| HiSparse + cache 策略后 | ~3.7M tokens | 约 3×;主要释放来自 inactive C4 offload + SWA 复用策略 |
| SWA 注意 | 全量 SWA 时 per-token KV 可 高于 V3 路径 | Together 称早期瓶颈常在 SWA state 而非 CSA/HCA 压缩体本身 |
Together 文中同时提到:通过 只保留最可能被复用的 SWA state,在不改权重的情况下提升总容量——这与 C4 CPU offload 互补,共同构成 V4 serving 的 cache policy 层(非单一 knob)。
与磁盘 Prefix Cache / DSpark 的关系
| 技术 | 关系 |
|---|---|
| KV layout | 前置:须先分 Classical / State 池,HiSparse 主要动 Classical 中 C4 部分 |
| 磁盘 Prefix Cache | 互补:压缩 entry 可 跨请求落盘;HiSparse 管 单请求内 GPU↔CPU 热冷分层 |
| DSpark | 正交:DSpark 优化 decode 步吞吐;HiSparse 优化 KV 驻留容量 |
与 ESS 对照
| 维度 | V3.2 (ESS) | V4 (HiSparse) |
|---|---|---|
| Offload 对象 | 仅 Latent-Cache | Inactive C4 压缩 entry |
| 局部性 | top-$k$ index 时间相似 | CSA 稀疏激活 + SWA 复用 |
| 传输优化 | FlashTrans / UVA | 分层内存池 +(引擎)PD 分离 |
| 与算法耦合 | 中(依赖 DSA top-$k$) | 高(依赖压缩比 $m{=}4$、$m'{=}128$) |
完整表:演进总览 §5.4。
基础设施线位置
| 方向 | 文档 |
|---|---|
| 本节点(⑤ HiSparse) | 基础设施线导读 §1 |
| 前置 layout | V4 KV Layout |
| 并列 prefix | V4 磁盘 Prefix Cache |
| 上游 ④ ESS | ESS Latent offload(非简单放大) |
| V4 总览 | DeepSeek-V4 梗概§推理 infra |
延伸
| 资源 | 说明 |
|---|---|
| Together.ai — Serving V4 | 1.2M→3.7M、SWA 瓶颈、多 layout serving |
| ESS 概念 | V3.2 offload 基线对照 |
| 演进总览 §5.3 | 总览反向链入口 |
论文背景:arXiv:2606.19348(算法侧 CSA/HCA;HiSparse 为 社区/部署层命名,与 Together cache policy 实践一致)
V4 磁盘 Prefix Cache
← 中文导读 · ← 仓库首页(EN) · ← 演进总览 §5.3 磁盘 Prefix Cache · ← 基础设施线导读 · CSA/HCA 算法专文 · V4 梗概 §推理 infra · 前置 KV layout · 并列 HiSparse · 上游 ESS 论文:arXiv:2606.19348 §3.5.2 部署参考:Together.ai — Prefix caching becomes a storage policy 演进总览 §5.3 只保留梗概;prefix 三档策略以本文为准。
一句话
V4 的 prefix 不再等于「整条同质 KV 共享一次 prefill」:引擎须按 cache 类型 决定存什么——CSA/HCA 压缩 entry 可直接落盘(紧凑、immutable),SWA 精确局部 state 体积约为压缩 entry 的 ~8×,论文给出 Full / Periodic Checkpointing / Zero 三档 SWA 策略,在 存储带宽 vs 命中重算 之间取舍。
从「共享 prefix」到「共享哪几类 cache」
传统 prefix cache:相同 token 前缀 → 复用同一份 KV,跳过 prefill。
| Cache 类型 | 是否适合落盘 | 原因 |
|---|---|---|
| CSA 压缩 entry | ✅ 优先 | 4:1 紧凑;块对齐后 不可变 |
| HCA 压缩 entry | ✅ 优先 | 128:1 极紧凑;1M prefix ≈ 8K entry |
| Tail buffer | ⚠️ 随 prefix 推进变化 | 未凑满块;通常随请求走 State 池 |
| Indexer KV | 视引擎实现 | 可与 CSA 路径一并序列化 |
| SWA state | ⚠️ 体积大 | 精确局部 K/V;长约 压缩 entry 的 8× |
Together 总结:Prefix caching becomes a storage policy — 存 CSA/HCA、如何存 SWA、各类型 独立 eviction。
CSA / HCA:压缩 entry 落盘
| 项 | 说明 |
|---|---|
| 收益 | 多请求共享 repo / system prompt / tool trace 等 长公共前缀 时,免重复 prefill 压缩路径 |
| 格式 | Classical KV cache 中已对齐的 immutable 压缩块($\mathrm{lcm}(4,128)$ 对齐,见 V4 KV Layout) |
| 与 HiSparse | 磁盘层 = 跨请求 / 跨会话 持久;HiSparse = 单请求内 GPU↔CPU 热冷(V4 HiSparse) |
| 命中路径 | 加载 CSA/HCA 块 → 仅需补全 tail + SWA(策略见下) |
SWA 三档策略
SWA 保存最近 $n_{\text{win}}$(约 128)token 的 精确 attention state。对 长 prefix,全量 SWA 的 存储与写带宽 迅速成为瓶颈。
| 策略 | 行为 | 优点 | 代价 |
|---|---|---|---|
| Full | 落盘 / 驻留 完整 SWA cache | 命中后 零重算,复用最简单 | footprint 最大;Together 早期 bring-up 采用此策略以降低工程复杂度 |
| Periodic Checkpointing | 每 $K$ token 存一份 SWA 检查点;命中时在相邻检查点间 重算 gap | 存储介于 Full 与 Zero 之间 | 命中需 部分 prefill 重放 |
| Zero(Recompute on hit) | 只存 CSA/HCA(+ tail 元数据);命中 prefix 时 按窗口重算 SWA | 磁盘最省;适合 极长 prefix、高复用、SWA 窗口相对短 | 重算上界 ≈ $n_{\text{win}} \times L_{\text layers}}$ token 量级 |
Zero 策略数量级:$n_{\text{win}}{=}128$、$L_{\text layers}}{=}61$ → 约 8K tokens 重算,相对 1M prefix 往往可接受。
命中 1M 公共前缀(Zero SWA):
磁盘/共享池:CSA + HCA 压缩块(~L/4 + L/128 条)
重算:最后 128×61 ≈ 8K token 的 SWA 路径
vs 全量 prefill 1M:大幅省算力,略增命中延迟
策略选型
| workload | 倾向策略 | 理由 |
|---|---|---|
| Agent / coding(长共享 repo) | 优先 CSA/HCA 落盘 + SWA Periodic 或 Zero | 前缀极长、重复率高;SWA Full 占满 KV 预算 |
| 短 chat、低 prefix 复用 | SWA Full 或不做磁盘 prefix | 重算省下的存储不值 setup 成本 |
| 高并发、磁盘/PCIe 带宽紧 | Zero + HiSparse GPU 热池 | 磁盘只存压缩体;SWA 命中时再算 |
Together 当前(2026-05):Full SWA + 激进 cache eviction → 1.2M→3.7M tokens;说明 策略与 HiSparse 强耦合,无单一默认最优。
与 ESS / V3 prefix cache
| V3 / V3.2 | V4 磁盘 Prefix | |
|---|---|---|
| 共享对象 | 同质 MLA latent 条 | 分类型:CSA/HCA vs SWA |
| ESS 角色 | Latent CPU offload,非磁盘 prefix 专论 | V4 需 新 tiering(GPU / CPU pinned / 磁盘) |
| Index Share | 与 prefix 正交(省 indexer 算力) | V4 仍可能有 indexer 复用,但 不在 §3.5.2 核心 |
基础设施线位置
| 方向 | 文档 |
|---|---|
| 本专题(§3.5.2) | 演进总览 §5.3 |
| infra 线 ⑤ 子项 | 基础设施线导读 §1 |
| 前置 layout | V4 KV Layout |
| 并列 HiSparse | V4 HiSparse |
| V4 总览 | DeepSeek-V4 梗概§推理 infra |
延伸
| 资源 | 说明 |
|---|---|
| Together.ai — Prefix caching | 三档 SWA 工程解读与 Full 策略取舍 |
| 演进总览 §5.4 | 磁盘 prefix 在三代 offload 表中的位置 |
| V4 异构 KV 总览图 | 异构 cache 总览图 |
论文:arXiv:2606.19348 §3.5.2

1. Introduction
This repository contains the official implementation for the paper: Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models.
Abstract: While Mixture-of-Experts (MoE) scales capacity via conditional computation, Transformers lack a native primitive for knowledge lookup. To address this, we explore conditional memory as a complementary sparsity axis, instantiated via Engram, a module that modernizes classic $N$-gram embeddings for $\mathcal{O}(1)$ lookup.
Key Contributions:
- Sparsity Allocation: We formulate the trade-off between neural computation (MoE) and static memory (Engram), identifying a U-shaped scaling law that guides optimal capacity allocation.
- Empirical Verification: Under strict iso-parameter and iso-FLOPs constraints, the Engram-27B model demonstrates consistent improvements over MoE baselines across knowledge, reasoning, code and math domains.
- Mechanistic Analysis: Our analysis suggests that Engram relieves early layers from static pattern reconstruction, potentially preserving effective depth for complex reasoning.
- System Efficiency: The module employs deterministic addressing, enabling the offloading of massive embedding tables to host memory with minimal inference overhead.
2. Architecture
The Engram module augments the backbone by retrieving static $N$-gram memory and fusing it with dynamic hidden states. The architecture is shown below (drawio provided):
3. Evaluation
Scaling Law
Large Scale Pre-training
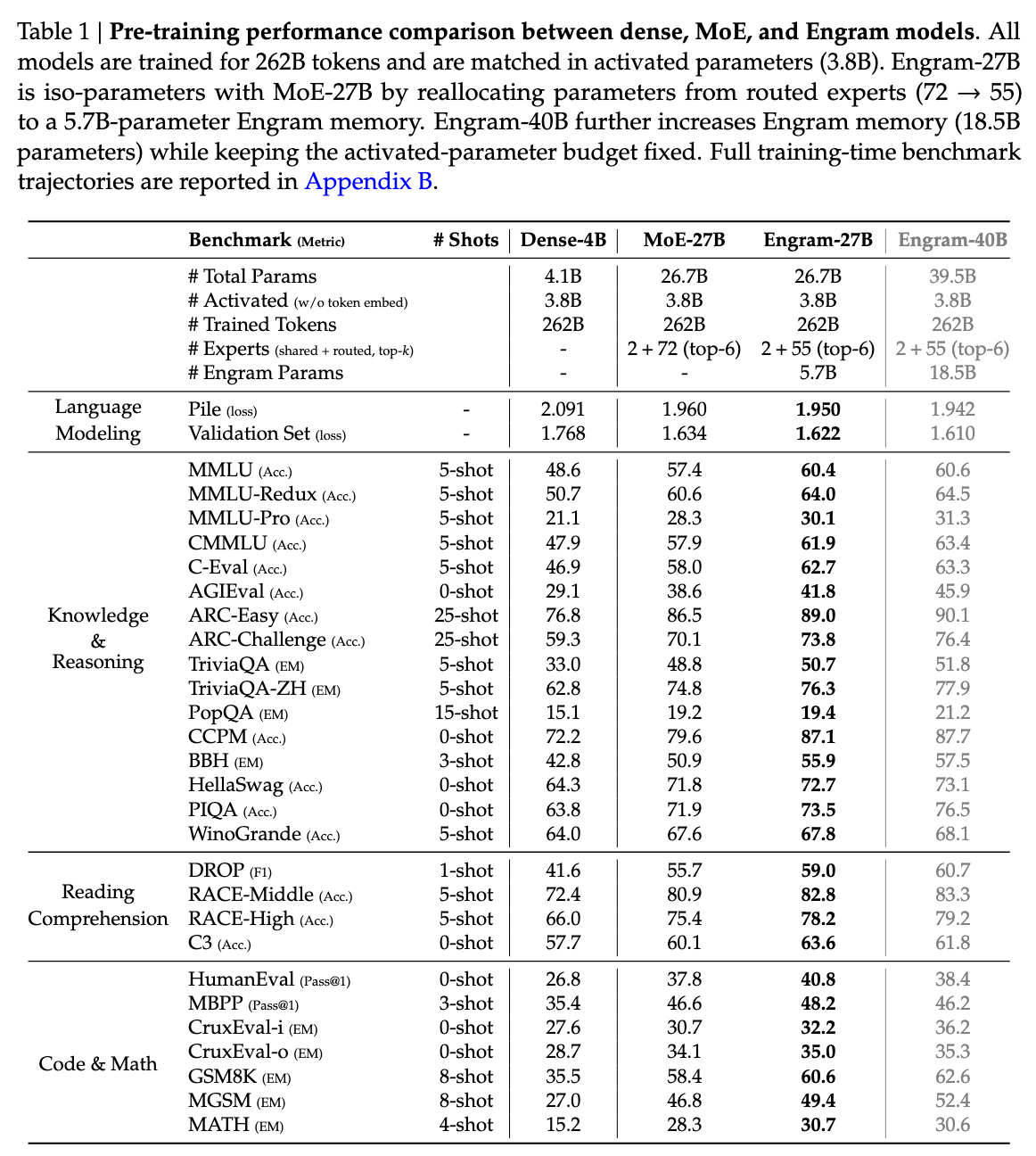
Long-context Training
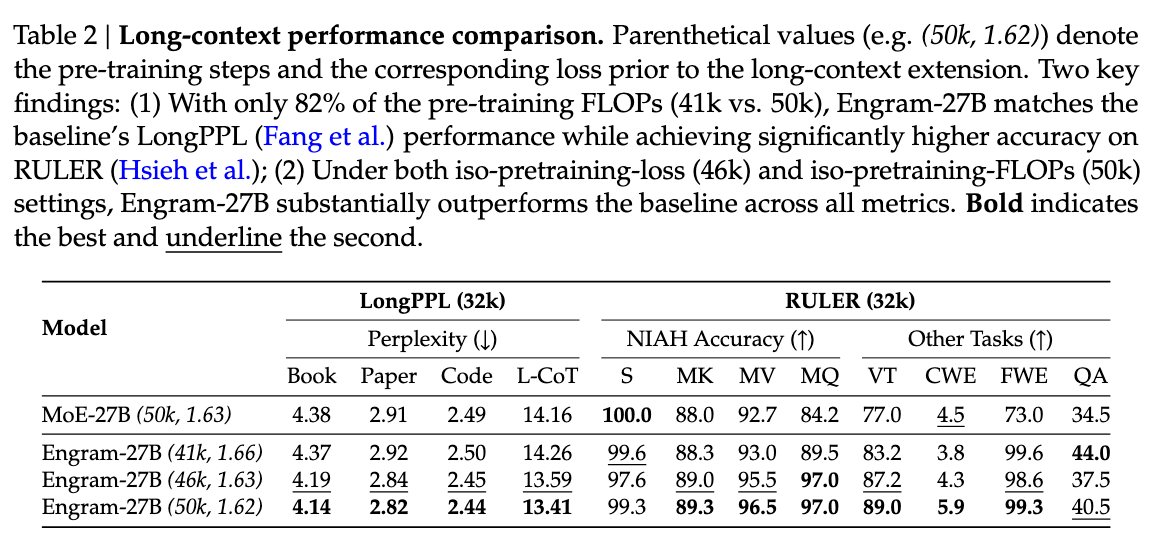
4. Case Study of Engram

5. Quick Start
We recommend using Python 3.8+ and PyTorch.
pip install torch numpy transformers sympy
We provide a standalone implementation to demonstrate the core logic of the Engram module:
python engram_demo_v1.py
⚠️ Note: The provided code is a demonstration version intended to illustrate the data flow. It mocks standard components (like Attention/MoE/mHC) to focus on the Engram module.
6. License
The use of Engram models is subject to the Model License.
7. Contact
If you have any questions, please raise an issue or contact us at service@deepseek.com.
8. 延伸阅读
DeepSeek Engram 系列导读
← 中文导读 · ← Engram 官方 README · ← 演进总览 §7 Engram · 《ds-技术报告》 更新:2026-06-24 PDF 目录:src/
系列在解决什么问题?
Transformer + MoE 用条件计算扩容量,但缺少原生的知识查表原语——模型被迫用多层 FFN/Attention 模拟静态模式检索(固定搭配、事实、局部 n-gram 依赖),浪费算力与有效深度。
Engram 提出 条件记忆(Conditional Memory):
| 稀疏轴 | 机制 | 激活依据 |
|---|---|---|
| 条件计算(MoE) | 动态路由专家 | 当前 hidden state |
| 条件记忆(Engram) | O(1) n-gram embedding 查表 | 输入 token 序列(确定性) |
论文标题:Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models
Abstract:
While Mixture-of-Experts (MoE) scales capacity via conditional computation, Transformers lack a native primitive for knowledge lookup. To address this, we explore conditional memory as a complementary sparsity axis, instantiated via Engram, a module that modernizes classic N-gram embeddings for O(1) lookup.
第二根轴的关键性质:寻址在推理前可知 → 可 prefetch、可 offload 到 Host DRAM / CXL,GPU 只算动态推理。
系列演进关系

{kind=link}
① Engram 奠基
标题:Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models 作者:DeepSeek-AI + 北大等 · 代码开源 · 梁文锋合著

架构详图:Engram 工作原理(Figure 1 + 逐步推导)
核心设计
- N-gram 查表现代化:tokenizer 压缩 + 多头哈希 + 上下文门控 + 多分支注入 Transformer
- O(1) lookup:局部 context → hash → 从大表取 embedding → 与 backbone hidden 融合
- 稀疏分配问题(Sparsity Allocation):MoE 算力 vs Engram 记忆容量如何切?
Engram 架构总览
下图与论文 Figure 1 同构(量子位 整理版;论文原图见 PDF 第 3 页)。左侧是 Engram 在 backbone 中的位置,右侧是模块内部数据流。
在整网中的位置:

{kind=link}
Engram 不替换 标准 embedding / un-embedding,也 不是每层都有;只在系统延迟允许的少数层插入,与 Attention、MoE 串行,各自带残差。
Engram 工作原理
给定序列 $X=(x_1,\ldots,x_T)$,在第 $\ell$ 层 hidden $h_t^{(\ell)}$ 处,Engram 对每个位置 $t$ 做 检索(Retrieval) 与 融合(Fusion) 两阶段。
| Step | 名称 | 记忆过滤 |
|---|---|---|
| 1 | Tokenizer 压缩 | 不过滤 — 只规范化 token ID |
| 2 | 构造 n-gram | 不过滤 — 只组后缀 |
| 3 | 多头哈希寻址 | 不过滤 — 算索引、查表 |
| 4 | 拼接 $e_t$ | 不过滤 — 产出静态记忆(上下文无关) |
| 5 | $W_K$ / $W_V$ 投影 | 备过滤 — 记忆变 $k_t,v_t$,尚未用 $h_t$ |
| 6 | 上下文门控 | ★ 过滤记忆 — $\alpha_t$ 门控,$\tilde{v}_t=\alpha_t v_t$(为何记忆依赖?) |
| 7 | 短卷积 | 已过滤 — 只在 $\tilde{v}_t$ 上运算 |
| 8 | 残差写回 | 已过滤 — $Y$ 注入 backbone,之后接 Attn/MoE |

{kind=link}
阶段 A:确定性检索
Step 1 — Tokenizer 压缩(Vocabulary Projection) · 记忆过滤:不过滤
- 子词 tokenizer 常把语义相同的词切成不同 ID(如
Applevs␣apple)。 - 预计算映射 $P: V \to V'$:NFKC 规范化、小写化等,把 raw ID 压成 canonical ID $x^{\prime}_t = P(x_t)$。
- 论文在 128k 词表上有效词表约 缩小 23%,提高 n-gram 槽位利用率。
Step 2 — 构造后缀 n-gram · 记忆过滤:不过滤
- 对每个位置 $t$、每个阶数 $n$(如 2-gram、3-gram),取压缩后的后缀:
$$ g_{t,n} = (x^{\prime}_{t-n+1}, \ldots, x^{\prime}_t) $$
- 例(图中句子):
Alexander the Great→ 2-gramthe Great、3-gramAlexander the Great。
Step 3 — 多头哈希寻址 · 记忆过滤:不过滤
- 全空间 n-gram 无法显式建表,用 $K$ 个独立 hash 头(每阶 $n$ 各 $K$ 头)映射到素数大小的表 $E_{n,k}$:
$$ z_{t,n,k} = \varphi_{n,k}(g_{t,n}), \quad e_{t,n,k} = E_{n,k}[z_{t,n,k}] $$
- $\varphi_{n,k}$ 为确定性 乘性-XOR hash;多头降低碰撞。
- 关键:索引只依赖 输入 token 序列,推理前即可算出 → 可 prefetch / offload。

{kind=link}
Step 4 — 拼接记忆向量 · 记忆过滤:不过滤 → 静态记忆 e_t
$$ e_t = \mathop{\Big\Vert}\limits_{n=2}^{N} \mathop{\Big\Vert}\limits_{k=1}^{K} e_{t,n,k} \in \mathbb{R}^{d_{\mathrm{mem}}} $$
- $e_t$ 是 上下文无关 的静态先验:「这个 n-gram 在历史上常伴随什么表示」。
阶段 B:上下文门控与融合
静态查表有碰撞、多义性;必须用当前 hidden 做 动态过滤(对应图右侧 Scaled Dot Product / Linear / Conv)。
Step 5 — Key / Value 投影 · 记忆过滤:备过滤(尚未用 h_t)
$$ k_t = W_K e_t, \quad v_t = W_V e_t $$
- 检索向量 $e_t$ 提供 Key、Value;当前 hidden $h_t$(已看过前文 Attention)作 Query 来源。
Step 6 — 上下文门控(Context-aware Gating) · 记忆过滤:★ 在此过滤
$$ \alpha_t = \sigma\left(\frac{\mathrm{RMSNorm}(h_t)^{\top} \mathrm{RMSNorm}(k_t)}{\sqrt{d}}\right), \quad \tilde{v}_t = \alpha_t \cdot v_t $$
- $\alpha_t \in (0,1)$:$e_t$ 与当前语境 一致 则门开大,矛盾(碰撞/歧义)则趋近 0,抑制噪声。
- 本质:用 Attention 式对齐,但 记忆来自查表而非算出来。
答疑:门控依据与记忆依赖过滤
Step 7 — 短卷积扩感受野 · 记忆过滤:已过滤(仅 ṽ_t)
$$ Y = \mathrm{SiLU}\left(\mathrm{Conv1D}(\mathrm{RMSNorm}(\tilde{V}))\right) + \tilde{V} $$
- Depthwise 因果 Conv1D:kernel $w=4$,dilation = 最大 n-gram 阶数 $N$;再 SiLU。
- 在门控后的 $\tilde{V}$ 序列上扩局部感受野、增加非线性。
- 感受野常数(demo 默认 $w=4,N=3$):门控流沿序列从 1 扩到 $1+(w-1)N=10$,不是扩到 4。详见 感受野常数;训练/推理差异见 RF 1→10 影响。

{kind=link}
Step 8 — 残差写回 backbone · 记忆过滤:已过滤 → 注入 H
$$ H^{(\ell)} \leftarrow H^{(\ell)} + Y $$
- 然后接标准 Attention(处理全局依赖)→ MoE(条件计算)。
- 分工:Engram 接管 局部静态搭配;Attention/MoE 专注 动态推理。
多分支 backbone 上的变体
若 backbone 是 多分支 Hyper-Connection($M=4$ 路并行残差流):
| 组件 | 是否共享 |
|---|---|
| 稀疏 embedding 表 $E_{n,k}$ | 共享 |
| Value 投影 $W_V$ | 共享 |
| Key 投影 $W_K^{(m)}$ | 每分支独立 $m=1,\ldots,M$ |
- 每分支用自己的 gate:
$$ \alpha_t^{(m)} = \sigma\left(\frac{\mathrm{RMSNorm}(h_t^{(m)})^{\top} \mathrm{RMSNorm}(W_K^{(m)} e_t)}{\sqrt{d}}\right) $$
- 输出:$u_t^{(m)} = \alpha_t^{(m)} \cdot (W_V e_t)$
- 工程上可把 $W_V$ 与 $M$ 个 $W_K^{(m)}$ 融合成一次 FP8 稠密 GEMM,提高 GPU 利用率。
一步前向的数据流小结
见上文 Step 1–8 总表 与 逐步前向 SVG(每步顶部标注记忆过滤状态)。
与 MoE 的本质区别
导读所称「第二稀疏轴」即论文摘要中的 complementary sparsity axis(第一轴为 MoE 的 conditional computation);原文见上文 系列在解决什么问题? 引用块。
| Engram(条件记忆) | MoE(条件计算) | |
|---|---|---|
| 激活依据 | 输入 token / n-gram(确定性) | 当前 hidden(数据依赖) |
| 操作 | O(1) 查表 + 轻量门控/卷积 | 路由 + 专家 FFN 矩阵乘 |
| 擅长 | 固定搭配、实体、局部事实 | 组合推理、复杂逻辑 |
| 系统 | 可 offload、异步 prefetch | 专家权重通常在 HBM |
机制解释
- Engram 接管早期层的静态模式重建 → backbone 等效加深,复杂推理更好
- 局部依赖交给 lookup → Attention 腾给全局上下文
U 形缩放律
在等参、等 FLOPs 下扫描分配比 ρ(inactive 参数预算中 MoE 专家占比;ρ=1 为纯 MoE),纵轴为 Validation Loss:
- 纯 MoE(ρ=1)不是最优(10B 档 loss 1.7248)
- 经验最优 ρ ≈ 75–80% MoE(Engram 约 20–25%;该档 loss 约 1.7109)
- ρ 过低(Engram 过多):记忆挤占、推理容量不足
- ρ=1(纯 MoE):浅层仍在「重建」静态模式,挤占有效深度
实验亮点
| 类型 | 代表提升 |
|---|---|
| 知识 | MMLU +3.4,CMMLU +4.0 |
| 推理 | BBH +5.0,ARC-Challenge +3.7 |
| 代码/数学 | HumanEval +3.0,MATH +2.4 |
| 长上下文 | Multi-Query NIAH 84.2 → 97.0 |
系统特性
- 100B 参数 embedding 表 offload 到 Host DRAM,吞吐损失 <3%
- 前几层 GPU 计算时,异步 PCIe prefetch Engram embedding
② CXL 内存池化
标题:Pooling Engram Conditional Memory in Large Language Models using CXL 作者:北大、阿里云计算、人大、港大等

动机
Engram 表可达百亿参数级,若每机本地 DRAM 各存一份成本极高;传统 RDMA 内存池(Mooncake 等)面向 KV cache 的 大块 MB–GB 传输,对 Engram 每次仅 ~5 KB/ token/层、16 段离散小 embedding 的访问模式不友好(64B 小包 RDMA 吞吐可跌至峰值带宽 25% 以下)。
体系结构:三级存储分层
论文原型 + 工程解读可抽象为三层(对应 Figure 4 拓扑):
| 层级 | 物理介质 | 典型容量 | 存放内容 | 访问特征 |
|---|---|---|---|---|
| L1(计算层) | GPU HBM | 数十 GB | Transformer/MoE 权重、当前 batch hidden、Engram gate/conv 小参数、prefetch staging buffer | 算力主战场;带宽最高 |
| L2(节点本地) | Host Local DRAM | TiB 级/节点 | 可选 热 embedding 缓存(Zipf 高频 n-gram)、CPU bounce buffer、CXL 映射的 虚拟地址窗口 | 延迟 ≈ 本地 DRAM;可作 CXL 读路径中转 |
| L3(机架共享) | CXL Memory Pool | 论文原型 256 GB/卡,交换机方案可达 4 TB / 8 机 | 完整 Engram embedding 大表(只读、多机共享一份) | 容量最大、单 bit 成本最低;经 CXL Switch 细粒度 load/store |
硬件拓扑:每服务器 CPU/GPU → PCIe 5.0 ×16 CXL Adapter → XConn XC50256 CXL Switch → 多块 CXL.mem;交换机总带宽 512 GB/s,最多 8 机共享 4 TB 池。Engram 表以 DAX 设备 mmap 进用户态,多机只读、无需跨节点 cache coherence。

{kind=link}
缓存访问逻辑

{kind=link}
Engram 访问有三大性质,决定上述分层如何工作:
- 只读、极小激活:每 token 每层只取 5 KB(N=2,3 × 8 hash heads × 320B),相对百亿参数表几乎为零。
- 稀疏离散:hash 索引分散在巨大表中,成千上万次 数百字节级 随机读。
- 延迟可隐藏:索引仅依赖 输入 token,decode 步开始即可发起读,与 Engram 之前各层 GPU 计算重叠。
Step 0 — 索引预计算
ForwardBatch到达(SGLang)→ 由 input token IDs 计算各层 Engram 的 hash 索引offsets[]- 不依赖 hidden,与 GPU 前向可并行启动
Step 1 — 异步 Prefetch 触发
- 解析 prefill / decode batch 的 token IDs → 异步启动 Engram embedding 拉取(目标:本步 Layer $k$ 所需行)
- 数据终点:GPU VRAM staging buffer(或先落 CPU 再拷 GPU)
时间窗约束:Engram 插在 layer $k$(如 $k=2,15$),必须在 layer $1..k-1$ 的计算时间内完成取数:
$$ L_{\mathrm{pool}}(N_{\mathrm{token}}, S_{\mathrm{layer}}) < \sum_{i=1}^{k-1} t_{\mathrm{exec}}(i) $$
以 Qwen3-32B 为例:$t_{\mathrm{step}}\approx 3.6,\mathrm{ms}$ / 64 层 → 每层约 56 μs;Layer 2 的 prefetch 窗口仅 ~56 μs,这是选 CXL 而非 RDMA 的核心原因。
Step 2 — L3 → L2/L1 数据通路
通路 A:CXL → CPU(OpenMP 并行 memcpy)
- CXL DAX 已
mmap到用户态cxl_base - 64 线程按
offsets[i]并行memcpy到cpu_dst(Listing 1) - 延迟:≈ 本地 DRAM
通路 B:CXL → GPU(推荐,绕过 CPU 搬运)
cudaHostRegister注册 CXL 区域为 CUDA pinned host memory- 单 kernel
cxl2vram_copy:每个 block 处理一段离散 embedding,GPU DMA 经 PCIe P2P 直读 CXL(Listing 2) - 避免数千次
cudaMemcpy启动开销;宽 grid 并发打满 PCIe - 延迟略高于 CXL→CPU,但仍 可满足 prefetch 窗口
(通路示意见上图 Step 2:L3 cxl_base + offset[i] 经 PCIe P2P 至 L1 gpu_staging[i],CPU 并行计算 offsets。)
Step 3 — L1 计算融合
- staging 中的 $e_t$ 已在 HBM → $W_K, W_V$ 投影 → 门控 $\alpha_t$ → Conv → $Y$ → $H \leftarrow H + Y$ → Attention → MoE
Step 4 — 热数据短路
① 中 n-gram 服从 Zipf 分布:少数模式占绝大多数命中。工程上可在 L2 Local DRAM / L1 HBM 维护高频 embedding 缓存——命中则跳过 CXL 往返;未命中则从 L3 读取并可选回填 L2(见上图 Step 4)。
CXL 论文原型将 整表放 L3 单卡 256 GB;更大规模用 4 TB 池 + 热缓存 是自然的扩展路径。
与 RDMA 池的访问逻辑对比
| 环节 | RDMA Pool(Figure 2a) | CXL Pool(Figure 2b) |
|---|---|---|
| 语义 | get/put 消息式 | load/store,cache-line 粒度 |
| 数据路径 | GPU → host bounce → NIC RDMA → 远端 DRAM | GPU/CPU 直连 CXL 地址空间 |
| Engram 5KB×离散 | 小包效率差,延迟 数量级高于 DRAM | 延迟 接近本地 DRAM(Figure 3) |
| 多机共享 | 支持 | CXL Switch 硬件地址映射,8 机并发读同一表 |
SGLang 集成:Init → Prefetch → Compute
论文 §4.3 三处改动:
- Initialization:全局
tp_rank=0, pp_rank=0的 ModelRunner 将 Engram 权重 加载进 CXL 共享池(其余 rank 复用映射地址)。 - Prefetching:每个
ForwardBatch到达 → 解析 token IDs → 异步 CXL→GPU 传输,与非 Engram 层 overlap。 - Computation:各 rank 按 DP/TP/PP 分工,到 Engram 层时从 pool(或 staging)取 embedding,与本地 hidden 计算;Engram 带宽占用小,每 rank 可直接读池。
带宽与延迟预算
| 符号 | 含义 | Qwen3-32B 例 |
|---|---|---|
| $T$ | 系统吞吐 (tok/s) | ≈ 70,000 |
| $S_{\mathrm{layer}}$ | 每 token 每层 Engram 载荷 | 5 KB |
| $N_{\mathrm{eng}}$ | 含 Engram 的层数 | 2(layer 2, 15) |
带宽:$B_{\mathrm{pool}} > T \times S_{\mathrm{layer}} \times N_{\mathrm{eng}} \approx 0.7,\mathrm{GB/s}$ — PCIe Gen5 / 百 G 网卡均够,瓶颈不在带宽。
延迟:Layer 2 的 prefetch 窗 ≈ 56 μs —— 必须选 CXL 近 DRAM 延迟,RDMA 不满足。
实验结论
| 指标 | 结果 |
|---|---|
| CXL 读延迟 | CXL→CPU ≈ DRAM;CXL→GPU 略高但可接受(Figure 5/6) |
| 端到端吞吐 | Qwen3-4B:DRAM 5683.7 vs CXL 5614.4 tok/s(≈ 1.2% 损失);8B 类似 |
| 多机扩展 | DP=2, 2 节点吞吐几乎不变(Table 3) |
| 成本 | 大表 + 多节点时 共享 CXL 池 优于每机配满 DRAM(Table 4/5) |
与①的关系
① 在单机 Host DRAM 上证明 offload + prefetch <3% 损失;② 把同一套 确定性索引 → 异步预取 → 计算重叠 逻辑推到 多机 CXL 共享池,并量化 RDMA 不适合、CXL 适合 的访问路径差异。
③ 无冲突热层实验 Engram-Nine
标题:A Collision-Free Hot-Tier Extension for Engram-Style Conditional Memory: A Controlled Study of Training Dynamics

{kind=link}
要验证的直觉
Engram 用多头哈希会有碰撞:不同 n-gram 共享 embedding 行。直觉上「高频键碰撞」可能是瓶颈 → 用 MPHF(最小完美哈希) 给 Top-N 高频 n-gram 建无碰撞热层,长尾仍走原冷层哈希。
论文 Figure 1 — 双层检索:MPHF + fingerprint 命中走 Hot(单表 $K\times d$),未命中走 Cold($K$ 头哈希拼接)。
核心发现
在严格等参对照下:
1. 去碰撞并不稳定降低 val loss — 证伪「碰撞是主要瓶颈」
论文 Table 3:Nine-100/400K(无碰撞热层)val loss 4.4799,与 Hash-500K 4.4809 几乎相同;高碰撞 Hash-300K 4.4825 亦相当。差异小于测量标准差(0.008–0.012)。
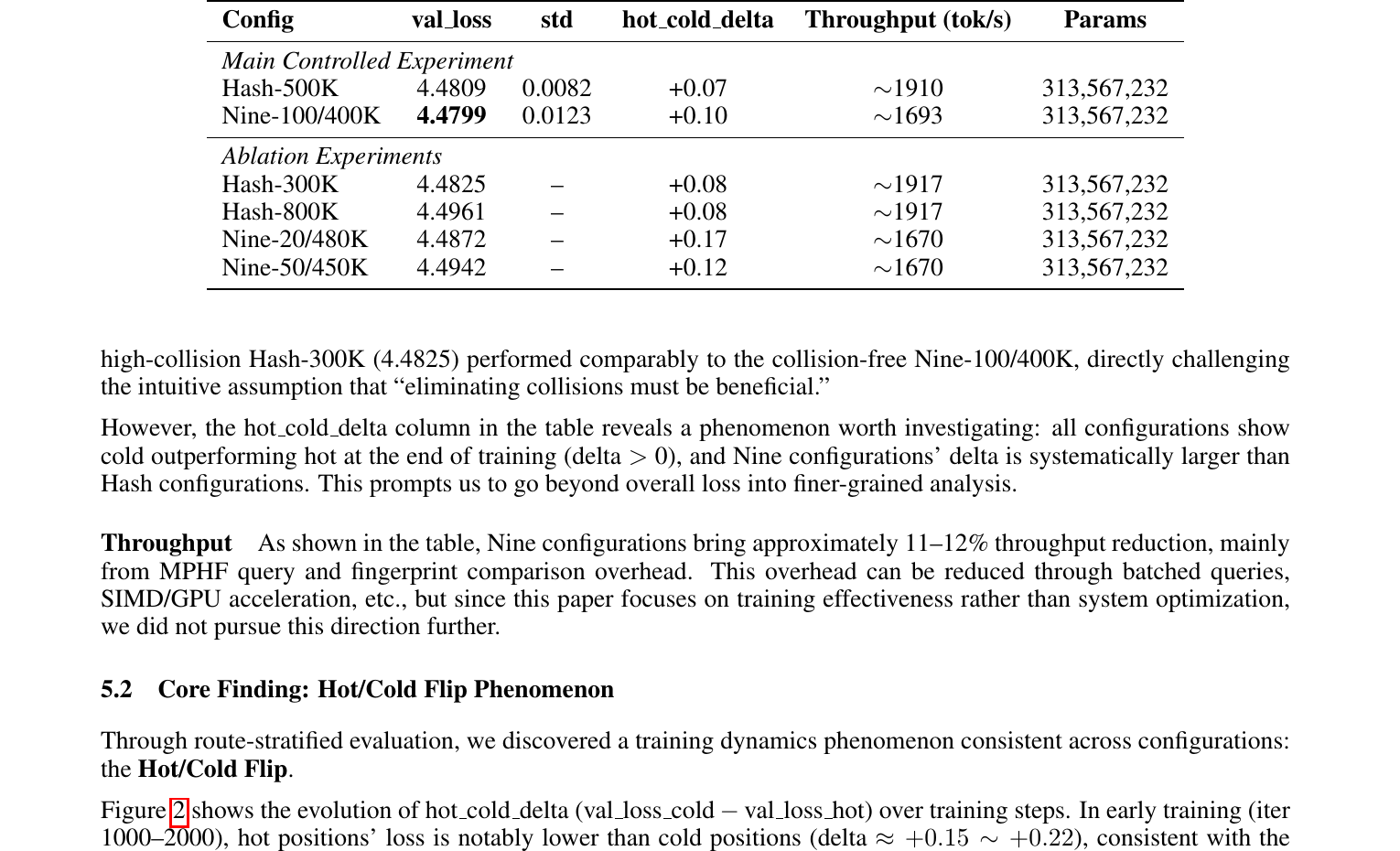
2. Hot-to-Cold Advantage Flip:训练早期 hot位置 loss 更低;后期 cold 位置反超
定义 $\texttt{hot_cold_delta} = \texttt{val_loss_cold} - \texttt{val_loss_hot}$:正值 = hot 更优,负值 = cold 更优。所有配置都经历从 hot 占优到 cold 占优的 crossover。
论文 Figure 2 — 训练全程 flip 曲线;Table 4 — 各配置 flip 时刻与幅度。
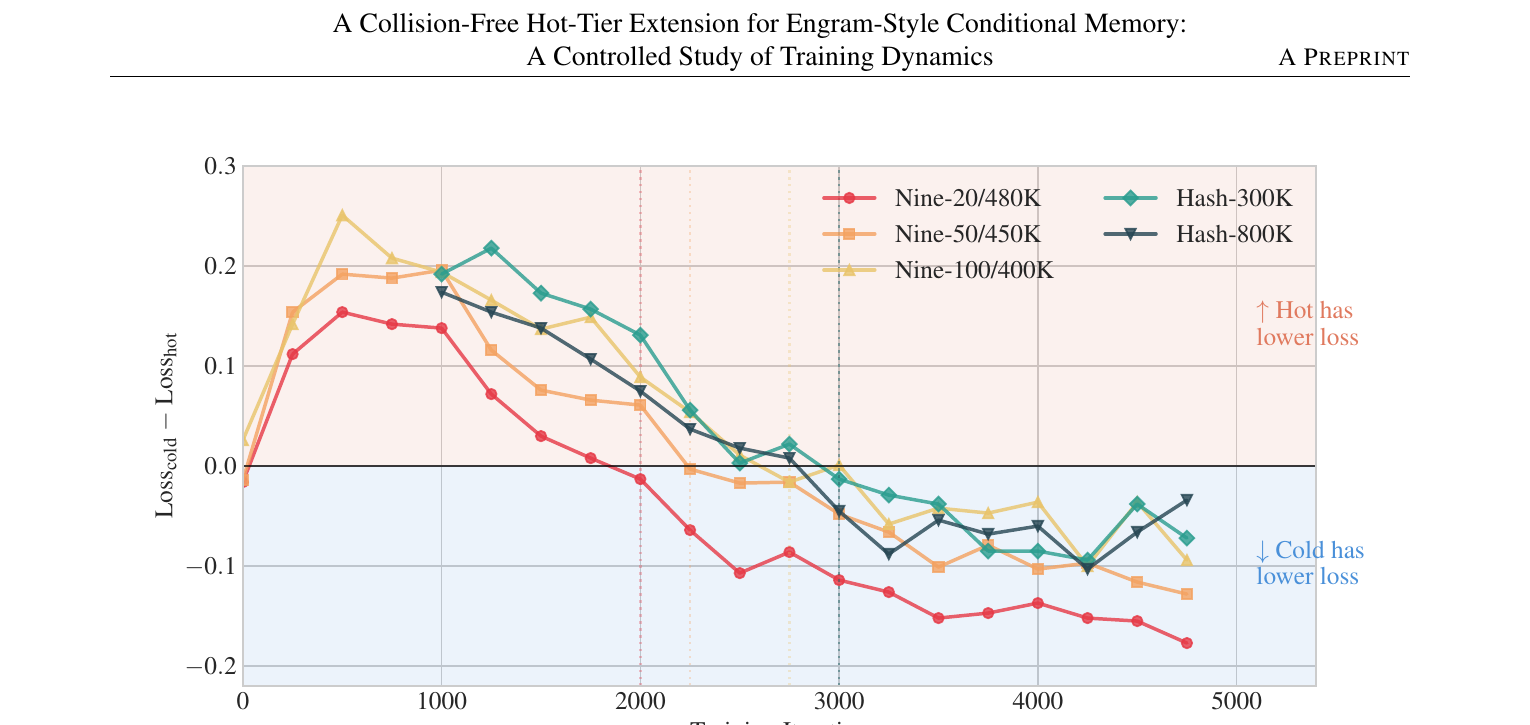

3. 无碰撞配置更早 flip → 碰撞像隐式正则
Nine(无碰撞)在 iter 2000–2750 flip;Hash(有碰撞)多在 iter 3000 才 flip。更小 $N_{\mathrm{hot}}$ 的 Nine 配置 flip 更早(Table 5),与「稀疏样本学得慢」的直觉相反 → 碰撞延迟 flip、像正则。

4. 门控错配:gate 早期学会偏 hot,flip 后仍给 hot 更高权重,但 hot 已不再更优
Figure 3:$\alpha_{\mathrm{hot}} > \alpha_{\mathrm{cold}}$ 从早期固化;Divergence 后 cold loss 已更低,但 $\Delta\alpha$ 仍为正。
Figure 4 / Table 6:高 $\alpha$ bucket 对应 更高 loss(0.8–1.0 桶 avg loss 5.28 vs 0.2–0.4 桶 3.90),且 hot 占比 76% — 与门控设计意图相反。
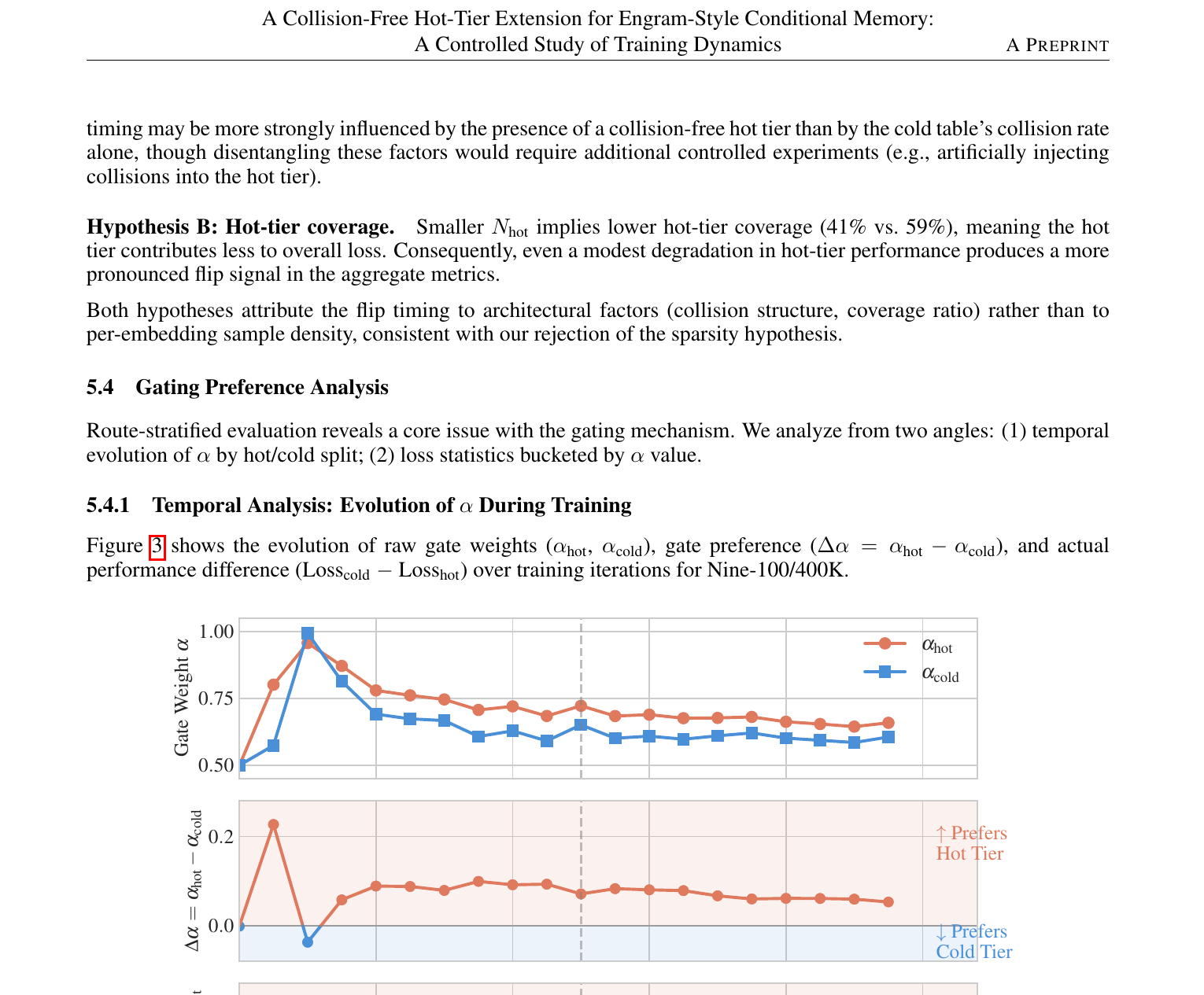

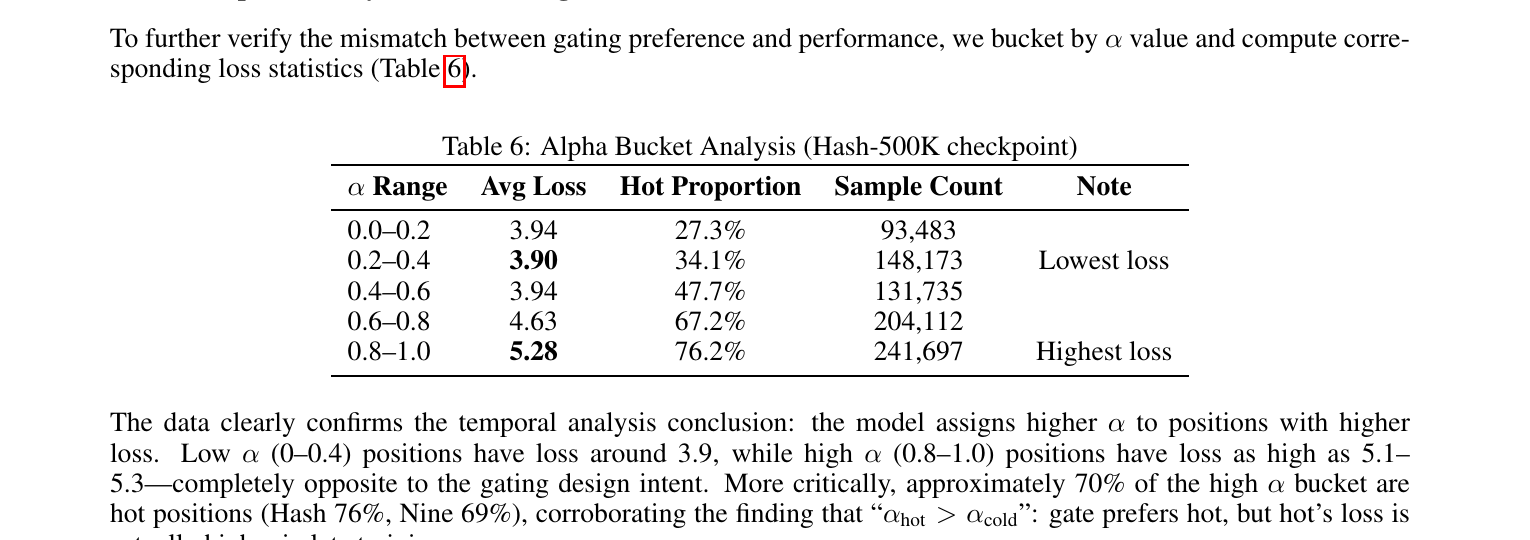
补充 — Figure 5:深层(Layer 6)$\Delta\alpha$ 可出现反转,Nine 配置更明显。

启示
- 改进查表精度 ≠ 必然更好训练
- 瓶颈可能在 gating 的 credit assignment,而非 index 准确度
- 工程上不要盲目消灭哈希碰撞
与①的关系
① 把多头哈希当工程手段;③ 用控制实验说明碰撞可能是特性而非 bug。
④ 视觉 Tiny-Engram
标题:Tiny-Engram: Trigger-Indexed Concept Tables for Generative Vision 机构:AutoArk-AI(开源跟进,非 DeepSeek 官方)

动机
视觉个性化常用 LoRA / adapter 全路径改权重,难以控制「何时、是否」检索某个概念。
方案
- Trigger-indexed concept table:注册稀有 n-gram 触发词 → 查小表 memory residual
- 仅在 prompt 匹配触发区域注入,冻结 SD / DiT backbone
- 调制 text encoder hidden,不改 UNet/DiT 权重
结果
- 图像生成:绑定身份 + 保持 prompt 组合性,参数极少
- 视频:能改主体,跨 prompt 身份持续性仍弱(需视觉侧记忆注入)
- 开源声称:视觉场景下 参数效率与抗灾难性遗忘 优于 LoRA
与①的关系
把 Engram 的「显式地址 + O(1) 查表 + 条件激活」从 LLM 搬到 生成式视觉;证明条件记忆不限于语言 backbone。
四篇对照总表
| 维度 | ① Engram | ② CXL | ③ Engram-Nine | ④ Tiny-Engram |
|---|---|---|---|---|
| 层级 | 模型架构 | 推理系统 | 训练动力学 | 跨模态应用 |
| 核心问题 | 记忆 vs 计算怎么分 | 表放哪、怎么连 | 哈希碰撞要不要消 | 视觉概念怎么注入 |
| 关键结论 | U 形律 ~25% 记忆 | CXL ≈ DRAM 性能 | 碰撞有正则作用 | 触发词查表可个性化 |
| 官方性 | DeepSeek | 系统论文 | 跟进研究 | AutoArk 开源 |
概念速查
| 术语 | 含义 |
|---|---|
| Conditional Memory | 按输入稀疏查表,非全参数前向 |
| Sparsity Allocation | MoE FLOPs 与 Engram 表大小的最优配比 |
| Multi-head hashing | 多 hash 头降碰撞,拼接 embedding |
| MPHF 热层 | 高频 n-gram 完美哈希、无碰撞 |
| CXL pool | 跨机共享内存池,细粒度访问 |
| Trigger-indexed | 仅当 prompt 出现注册 n-gram 才激活记忆 |
若做跟进创新
| 方向 | 可切入点 |
|---|---|
| 与推理框架结合 | Engram prefetch 与 CUDA Graph / 分层 KV 的调度共存 |
| 与 LoRA 对比 | 语言侧 Tiny-Engram 式「触发词记忆」vs LoRA(④ 已在视觉做) |
| 分配律 | 不同任务(代码 vs 知识)是否需不同 MoE/Engram 比 |
| 门控 | ③ 指出 gating credit assignment;可改 gate 结构或训练目标 |
| 多模态 | ④ 视频身份持久 → 视觉 token 侧 Engram 而非仅 text encoder |
参考文献
- Cheng et al. Engram. arXiv:2601.07372. https://github.com/deepseek-ai/Engram
- Pooling Engram using CXL. arXiv:2603.10087
- Collision-Free Hot-Tier Extension. arXiv:2601.16531
- Cai et al. Tiny-Engram. arXiv:2605.20309. https://github.com/AutoArk/TinyEngram
相关文档
Raschka 解读梗概:DeepSeek V3 → V3.2
← 报告目录 · 全文解析(含表格) · 原文 作者:Sebastian Raschka · 2025-12-03(更新 2026-01-01) 本地对照:V3 梗概 · V3.1 梗概 · V3.2 梗概 · MLA · DSA 梗概 · DSA 逻辑 · RLVR
一句话
V3.2 = V3.1-Terminus 权重架构 + DSA 稀疏注意力;训练侧在 R1 的 RLVR+GRPO 上叠加 DeepSeekMath V2 的自验证 与一组 更保守的 GRPO 稳定性补丁;V3.2-Exp 的首要角色是 给 V3.2 铺推理 infra。
发布时间线
| 时间 | 模型 | 要点 |
|---|---|---|
| 2024-12 | V3、R1 | 同架构;R1 靠 RLVR 出圈 |
| 2025 | R1-0528 | 架构不变,后训练小升级 |
| 2025 | V3.1 → V3.1-Terminus | Hybrid 单模型双模式;Terminus = 小改进 + 128K,V3.2 续训起点 |
| 2025-09 | V3.2-Exp | 在 Terminus 上 续训加 DSA;benchmark 不惊艳,但 铺生态/推理栈 |
| 2025-11-27 | DeepSeekMath V2 | 自验证 + 自 refine;V3.2 数学奖励的数据与方法来源 |
| 2025-12-01 | V3.2 | 架构同 Exp;完整后训练成品 |
| 2025-12-31 | mHC 论文 | 残差路径研究(Hyper-Connections 约束流形),非 V3.2 权重变更 |
架构演进
| 版本 | 架构相对 V3 | 训练侧重 |
|---|---|---|
| V3 | MoE + MLA 基座 | 预训练 base |
| R1 | 同 V3 | RLVR + GRPO(可验证奖励) |
| V3.1 / Terminus | 同 V3 | Hybrid chat + reasoning(prompt 切换) |
| V3.2-Exp / V3.2 | + DSA(lightning indexer + top-$k$=2048) | Exp 验稀疏;V3.2 全任务 + 工具/agent |
DSA 复杂度:注意力主路径 $O(L^2) \to O(Lk)$,$k \ll L$。目标 不是刷过 Terminus benchmark,而是 少掉点、大幅省算。
模型类型:专用推理 vs Hybrid
| 路线 | 代表 | Raschka 观察 |
|---|---|---|
| 专用推理 | R1、部分 Qwen3 拆分版 | 单场景更强,但要维护两套模型 |
| Hybrid | Qwen3 初版、gpt-oss、V3.1/V3.2 | 一套权重,模板/系统提示切换模式 |
| DeepSeek 方向 | R1(专用)→ V3.1+ Hybrid | R1 像推理方法试验床;V3.2 面向通用旗舰 |
MLA 要点
- K/V 压进 latent 再进 KV cache;推理时 up-project 回注意力空间(类比 LoRA 升降维)。
- Q 在训练时也压缩,推理时不压缩(文章 side note)。
- MLA 自 V2 引入,V3/R1 沿用。
RLVR / GRPO 要点
R1 奖励
| 奖励 | 作用 |
|---|---|
| format | 答案格式 |
| language consistency | 避免中英混杂 |
| verifier | 数学/代码对错(符号验证) |
V3.2 奖励
| 任务类型 | 奖励组成 |
|---|---|
| reasoning / agent | rule-based outcome + length penalty + language consistency |
| general | 生成式 RM(每 prompt 自带 rubric) |
| math | 并入 DeepSeekMath V2 数据与奖励 |
→ 从「纯 RLVR」变为 RLVR + LLM-as-judge 混合管线。
V3.2 GRPO 相对 DAPO / Dr. GRPO
| 改动 | 摘要 |
|---|---|
| 保留 原 GRPO advantage 归一化 | 不像 Dr. GRPO / DAPO 那样大改目标 |
| 分域 KL 权重 | 数学可近零 KL,但不全局删除 |
| 无偏 KL 估计 | KL 项用与主 loss 相同的 importance ratio 重加权 |
| off-policy sequence masking | 负 advantage 且偏离 rollout 太远的序列丢弃 |
| MoE routing 固定 | rollout 专家路径训练时复现 |
| top-p/k mask 保留 | 训练 action space 与采样一致 |
DeepSeekMath V2 → V3.2 数学能力
| 组件 | 角色 |
|---|---|
| LLM1 证明生成器 | 主模型 |
| LLM2 证明验证器 | 训练时作 reward model;rubric 0 / 0.5 / 1 |
| LLM3 meta-verifier | 训练时监督 LLM2;推理不用 |
| 自 refine | 最多 8 轮;训练用独立 verifier,推理用单一 2-in-1 模型 |
动机:RLVR 只验最终答案 → 推理过程可错;定理证明需要 过程分 而非数值答案。
V3.2 变体
| 模型 | 特点 |
|---|---|
| V3.2 | 通用 + agent + 工具;DSA + 混合奖励 |
| V3.2-Speciale | RL 阶段 仅 reasoning 数据;减弱 length penalty → 更长链、更高精度(推理 scaling) |
结论表
| # | takeaway |
|---|---|
| 1 | V3.2 架构与 V3 系一脉;主要结构改动 = V3.2-Exp 的 DSA |
| 2 | 数学靠 DeepSeekMath V2 自验证 迁入训练 |
| 3 | GRPO 稳定性补丁 多于算法替换 |
| 4 | 文章未展开:蒸馏、长上下文训练、工具集成(类 gpt-oss) |
| 5 | 附录 mHC:在 Hyper-Connections 上做流形约束,改 残差路径 稳定性(2025-12-31 论文) |
与本地文档映射
| 文章章节 | 本地延伸 |
|---|---|
| §3.1 MLA / V3 | MLA 低秩注意力 · DeepSeek-V3 |
| §3.2 RLVR / GRPO | RLVR · DeepSeek-R1 |
| §3.4 V3.1 Hybrid / MLA 切换 | DeepSeek-V3.1 梗概§MLA 模式切换 |
| §4 DSA | Lightning Indexer 详解 · DSA 稀疏注意力 · DSA 逻辑详解 |
| §6 V3.2 infra | DeepSeek-V3.2 · 演进总览 §3.6 |
| §8 mHC | mHC · DeepSeek-V4 |
Raschka 全文解析:From DeepSeek V3 to V3.2
← 梗概 · ← 报告目录 第三方原文:From DeepSeek V3 to V3.2: Architecture, Sparse Attention, and RL Updates(Sebastian Raschka · Ahead of AI · 2025-12-03) 本地对照:V3.1 · V3.2 · DSA 梗概 · DSA 逻辑 · RLVR
1. The DeepSeek Release Timeline
要点:V3(2024-12)起初不火爆;R1 使同架构模型成为开源旗舰。2025 年无「隔年大招」,但有 V3.1 / V3.2-Exp 等铺垫 release;V3.2-Exp 意在预热推理 infra,正式 V3.2 随后发布。V3.2 使用 非标准稀疏注意力,需自定义推理代码。
表 1-1:主要 release 时间线
| 时间 | 模型 / 事件 | 角色(Raschka 归纳) |
|---|---|---|
| 2024-12 | DeepSeek V3 | Base:MoE + MLA |
| 2024-12 ~ 2025-01 | DeepSeek R1 | 同架构 + RLVR;带火 V3 系 |
| 2025 | R1-0528 | 后训练小升级,对标 o3 / Gemini 2.5 Pro 时期 |
| 2025 | V3.1、V3.1-Terminus | Hybrid;Terminus = V3.1 收尾 checkpoint |
| 2025-09 | V3.2-Exp | Terminus + DSA 续训;benchmark 平淡,铺生态 |
| 2025-11-27 | DeepSeekMath V2 | 数学 PoC;自验证管线 |
| 2025-12-01 | V3.2 | 旗舰正式版;架构同 Exp |
| 2025-12-31 | mHC 论文 | 残差 Hyper-Connection 研究(附录 §8) |
原文 Figure 3:release 时间轴(主模型标红)。团队曾传训练芯片从 NVIDIA 换 Huawei,文章称 已回到 NVIDIA(基于公开信息)。
2. Hybrid Versus Dedicated Reasoning Models
要点:V3 = base;R1 = 专用推理(额外 post-training)。行业出现 Hybrid(同一 checkpoint 切换 thinking/chat)与 拆分 instruct/reasoning 两条路线。
表 2-1:推理模型形态对比
| 形态 | 机制 | 代表 |
|---|---|---|
| Dedicated reasoning | 独立 checkpoint / 管线 | DeepSeek R1 |
| Hybrid | 模板或系统提示切换模式 | 初版 Qwen3、gpt-oss、V3.1 / V3.2 |
| Hybrid → 拆分 | 分开发布 instruct / reasoning 版 | Qwen 后续路线 |
表 2-2:DeepSeek 在「专用 vs Hybrid」上的移动
| 阶段 | 方向 | Raschka 解读 |
|---|---|---|
| V3 + R1 | Base + 专用 R1 | R1 验证 RLVR 与推理能力 |
| V3.1 / V3.2 | → Hybrid | 单模型覆盖 chat + reasoning;R1 像 试验床,V3.2 面向 通用旗舰 |
| 未来(推测) | 可能仍有 R2 专用版 | 文章未证实 |
原文 Figure 4–5:R1 训练管线、2025 年 reasoning/hybrid 模型时间线。
3. From DeepSeek V3 to V3.1
3.1 DeepSeek V3 Overview and MLA
要点:V3 两大架构亮点 = MoE + MLA。MLA 将 K/V 投影到低维 latent 再写入 KV cache;推理时 up-project 使用。Q 仅在 训练 时压缩,推理 不压缩。
表 3-1:V3 核心架构组件
| 组件 | 作用 | 备注 |
|---|---|---|
| DeepSeekMoE | 条件计算扩容 | 文章略去 MoE 入门 |
| MLA | KV latent 压缩 | V2 引入;V3/R1 沿用;利于 KV cache |
| MTP | 推测解码相关 | 本地 DeepSeek-V3 |
原文 Figure 6:MLA 降维 → cache → up-project 示意图。
3.2 DeepSeek R1 and RLVR
要点:R1 架构同 V3;差异在 RLVR(Reinforcement Learning with Verifiable Rewards):从可符号/程序验证的任务(数学、代码等)学习。GRPO = 无 critic 的 PPO 简化版;RLVR+GRPO 再省掉 reward model,直接用计算器/编译器等 可验证奖励。
表 3-2:LLM 强化学习管线对比
| RLHF + PPO | GRPO | RLVR + GRPO | |
|---|---|---|---|
| Reward model | 人类偏好训练 | — | — |
| Critic(value model) | 有 | 无 | 无 |
| 奖励来源 | RM 打分 | 组内相对优势 | 符号工具(计算器、编译器等) |
| 典型用途 | 对齐 | 简化 RLHF | 推理(数学/代码可验证) |
3.3 DeepSeek R1-0528
| 项 | 说明 |
|---|---|
| 定位 | 官方称 minor version upgrade |
| 架构 | 同 V3/R1 |
| 提升来源 | 后训练管线优化(细节未公开);托管版或更长推理 |
3.4 DeepSeek V3.1 Hybrid Reasoning
| 项 | 说明 |
|---|---|
| 能力 | Instruct + reasoning 合一 |
| 切换 | Chat prompt 模板(类初版 Qwen3) |
| 权重链 | V3.1 ← V3.1-Base ← V3(架构相同) |
| Terminus | V3.1 收尾版;128K;V3.2 续训基座 → 见 DeepSeek-V3.1 梗概§MLA 模式切换 |
4. DeepSeek V3.2-Exp and Sparse Attention
要点:V3.2-Exp 在 V3.1-Terminus 上 续训加入 DSA。DSA = (1) lightning indexer + (2) token selector;从「看全长」变为「看学到的 top-$k$ 子集」。
表 4-1:滑动窗口注意力 vs DSA
| 滑动窗口(Gemma 3、Olmo 3 等) | DSA | |
|---|---|---|
| 可见历史 | 固定宽度 局部窗 | 学习选择 的 $k$ 个位置 |
| 选择方式 | 规则(距离) | indexer 打分 + top-$k$ |
| 稀疏模式 | 带状局部 | 可 非局部、数据驱动 |
| 典型 $k$ | 窗口宽 $w$ | $k=2048$(官方代码) |
表 4-2:Lightning indexer 打分公式符号
公式:
$$ I_{t,s} = \sum_{j=1}^{H^I} w_{t,j},\mathrm{ReLU}!\left(q_{t,j}\cdot k_{s}\right) $$
| 符号 | 含义 |
|---|---|
| $t$ | 当前 query token 位置 |
| $s$ | 历史 token 位置($0 \le s < t$) |
| $j$ | indexer head 索引($1 \ldots H^I$) |
| $q_{t,j}$ | 位置 $t$、head $j$ 的 query 向量 |
| $k_s$ | 位置 $s$ 的 key(已压缩在 MLA KV cache) |
| $w_{t,j}$ | 可学习的 per-head 权重 |
| top-$k$ 的 $k$ | 与 key 的 $k$ 无关;selector 超参,= 2048 |
实现注:
- indexer 只对 query 多头;keys 已在 cache,无需再按 head 打分。
- ReLU 本身难让分数为 0;真正稀疏来自 top-$k$ selector。
- 复杂度:$O(L^2) \to O(Lk)$。
原文 Figure 9–11:滑动窗 vs DSA 注意力图、DSA 流程图。 本地延伸:Lightning Indexer 详解 · DSA 逻辑详解

5. DeepSeekMath V2
时间:2025-11-27(美国感恩节),V3.2 发布前 4 天。基座:V3.2-Exp-Base。角色:V3.2 的 数学能力 PoC。
表 5-1:常规 RLVR 的局限
| 局限 | 含义 |
|---|---|
| 答案对 ≠ 推理对 | 错误逻辑也可能碰对答案 |
| 定理证明 | 需要 逐步推导,最终数值奖励不适用 |
5.1 Self-Verification
结构:训练 证明生成器 LLM1 + 证明验证器 LLM2;可选 meta-verifier LLM3 监督 LLM2。
表 5-2:证明验证 rubric
| 分数 | 标准 |
|---|---|
| 1 | 完整严谨,逻辑步骤清晰 |
| 0.5 | 整体逻辑正确,有小错或省略 |
| 0 | 根本性逻辑错误 or 关键缺口 |
表 5-3:三模型分工与训练
| 模型 | 基座 / 训练 | 推理时 |
|---|---|---|
| LLM1 生成器 | 用 LLM2 作 reward 训练 | 最终 2-in-1(生成+自评) |
| LLM2 验证器 | V3.2-Exp-SFT + RL(format + 与人类标注分数对齐) | 训练后 不单独部署 |
| LLM3 meta-verifier | RL,评估 LLM2 的分析质量 | 仅训练;meta 分 0.85→0.96(文引数据) |
5.2 Self-Refinement
| 模式 | 说明 |
|---|---|
| 经典 self-refinement | 同一 LLM 生成 → 自评 → 修订 |
| DeepSeek 观察 | 单模型自评易 盲目宣称正确 |
| 训练时 | 独立 LLM2(+LLM3)提供严格反馈 |
| 推理时 | 单一最终生成器 兼做验证(省算力) |
| 迭代 | 论文最多 8 轮;精度随轮次升,未饱和 |
原文 Figure 12–16:generator/verifier/meta-verifier、自 refine 流程、迭代精度曲线。
6. DeepSeek V3.2
要点:对标 GPT-5 / Gemini 3 Pro 级开源旗舰;架构与 V3.2-Exp 完全相同(MoE + MLA + DSA);差异在 训练与后训练。数学采用 Math V2 管线;强调 工具 / agent;训练芯片叙述为 回归 NVIDIA。
6.1 Architecture
| 项 | 内容 |
|---|---|
| 架构声明 | 与 V3.2-Exp 完全一致 |
| 效率动机 | MLA(V2/V3)+ DSA 降长上下文成本 |
| 原文 Figure 19 | DSA 带来的 推理成本节省(截图自 V3.2 报告) |
6.2 Reinforcement Learning Updates
表 6-1:R1 vs V3.2 奖励设计
| DeepSeek R1 | DeepSeek V3.2 | |
|---|---|---|
| Format reward | ✅ | ❌ 移除 |
| Language consistency | ✅ | ✅ |
| Verifier / outcome | ✅(数学/代码) | ✅ rule-based outcome(reasoning/agent) |
| Length penalty | — | ✅(agent 任务) |
| Generative RM + rubric | — | ✅(general 无符号验证任务) |
| Math V2 管线 | — | ✅ 并入数据集与奖励 |
归纳:V3.2 = RLVR(可验证域)+ 生成式 RM(开放域) 混合,而非 R1 式纯 verifier RLVR。
6.3 GRPO Updates
文章先列 Olmo 3 采用的激进 GRPO 改动(DAPO / Dr. GRPO 系),再对比 V3.2 更保守 的补丁。
表 6-2:Olmo 3 的 GRPO 改动
| 改动 | 来源 |
|---|---|
| Zero gradient signal filtering | DAPO |
| Active sampling(动态采样) | DAPO |
| Token-level loss | DAPO |
| No KL loss | DAPO / Dr. GRPO |
| Clip higher | DAPO |
| Truncated importance sampling | Yao et al. |
| No std normalization in advantage | Dr. GRPO |
表 6-3:DeepSeek V3.2 的 GRPO 改动
| 改动 | 说明 |
|---|---|
| 分域 KL 强度 | 保留 KL;数学可 近零 KL,作超参而非全局删除 |
| 无偏 KL 估计 | KL 项用与主 loss 相同的 importance ratio 重加权 |
| Off-policy sequence masking | 复用 rollout 时,丢弃 负 advantage 且过于 off-policy 的整条序列 |
| MoE routing 固定 | rollout 记录专家路由,训练时 强制同路由 |
| 保留 top-p/k 采样 mask | 训练时 action space 与采样一致 |
| 保留原 GRPO advantage 归一化 | 不采用 Dr. GRPO / DAPO 的大改归一化 |
定位:比 Olmo 3 / DAPO 更接近原始 GRPO,靠 工程稳定性补丁 而非重写目标。
6.4 V3.2-Speciale
| 项 | V3.2 | V3.2-Speciale |
|---|---|---|
| RL 数据 | 多域 | 仅 reasoning |
| Length penalty | 常规定 | 减弱 → 更长输出 |
| 行为 | 通用旗舰 | extended thinking;更高精度、更多 token(推理 scaling) |
原文 Figure 17–18、20:benchmark、架构、Speciale 长度-精度权衡。
7. Conclusion
| # | Takeaway |
|---|---|
| 1 | V3.2 架构与 V3 以来一脉相承 |
| 2 | 主要结构变化 = V3.2-Exp 的 稀疏注意力 DSA |
| 3 | 数学提升 = 吸收 DeepSeekMath V2 自验证 |
| 4 | 训练管线含 GRPO 稳定性 等多项更新 |
| 5 | 文章 未展开:蒸馏、长上下文训练、工具集成(类 gpt-oss)等 |
8. Appendix: mHC
时间:2025-12-31 论文。焦点从 attention/FFN 转向 残差路径。
表 8-1:Transformer 模块演进
| 模块 | 演进链 |
|---|---|
| Normalization | LayerNorm → RMSNorm → Dynamic TanH |
| Attention | GQA → sliding window(SWA) → MLA → sparse (DSA) |
| FFN | GeLU → SiLU → SwiGLU → MoE |
| 残差 | 恒等残差(ResNet)→ Hyper-Connections (HC) → mHC(流形约束、保范数) |
mHC:在 HC(多路并行残差流 + 可学习混合)上,将混合矩阵约束在 结构化保范数流形,提升 训练稳定性;有少量开销。
与 V3.2 部署权重无直接对应;在 V4 与独立论文 mHC arXiv:2512.24880 中落地(本地 mHC 详解 · DeepSeek-V4)。
参考与本地映射
| 资源 | 链接 |
|---|---|
| 原文 | https://magazine.sebastianraschka.com/p/technical-deepseek |
| 梗概 | Raschka 要点速读 |
| V3.1 | DeepSeek-V3.1 梗概 |
| V3.2 | DeepSeek-V3.2 梗概 |
| DSA 梗概 | DSA稀疏注意力 |
| DSA 逻辑 | DSA逻辑详解 |
| RLVR | RLVR |
| 演进总览 | 版本演进总览 |
如何评价 DeepSeek 发布 DSpark?哪些亮点值得关注?
← 返回 V3 §三 MTP · 投机解码专文 · 报告目录
作者:酱紫君(GalAster) 原文:知乎回答 对照:DeepSpec · DSpark 论文 PDF · 投机解码专文
这个说的是草稿模型,和 ds4f 最近更新 Flash 草稿模式不是一回事。
和之前 1000T/s 的 Mimo UltraSpeed 一起讲一下吧,都是基于 DFlash 的优化。
DSpark 成本低,加速普适性高,可以套用到任何模型;而 UltraSpeed 一对一成本极高,但是效果更好。
Speculative Decoding
大模型训练完成的推理部分有很多的工程优化,其中加速比最大的就是投机解码,说白了就是用时间换空间,用 Compute-Bound 的并行验证去替代 Memory-Bound 的串行读取。
Compute / Memory 两层读法 · DFlash vs Eagle:答疑:draft 侧 DFlash≈并行 Compute-Bound、Eagle≈串行 Memory-Bound — 开篇整句指 target 并行 verify;draft 范式上 DFlash / Eagle 分别对应两侧。
投机解码需要两个模型,一个是分布为 $P(x)$ 的大模型为 $M_p$,另一个是轻量级分布为 $Q(x)$ 草稿模型为 $M_q$。
接下来会将一次推理分解为草稿阶段(Drafting)和验证阶段(Verification)。
令草稿模型 $M_q$ 串行自回归生成 $K$ 个候选 token $\hat{x}{t+1}, \hat{x}{t+2}, \dots, \hat{x}_{t+K}$。
然后大模型 $M_p$ 一次前向并行校验这 $K$ 个位置,按 rejection sampling 从左到右接受与 $P$ 一致的 prefix;未通过处截断并自 $M_p$ 重采样。输出分布与不用投机时 完全一致(lossless)。
在外置方案中,草稿模型和主模型是两套完全独立的表征空间,经常出现鸡同鸭讲导致的拒绝。这也是为什么 MiMo UltraSpeed 可以打出 1000+ 单 token 射速,而其他架构在缺卡的情况下很难做到。
$$ S_{\uparrow} = \frac{\bigl(\mathbb{E}[N_{\mathrm{acc}}] + 1\bigr),\tau_p}{K,\tau_q + \tau_p} $$
要把 $S_{\uparrow}$ 做大,需同时抬高 $\mathbb{E}[N_{\mathrm{acc}}]$(draft 猜得准)并压低 $K\tau_q$(draft 别太慢)。DSpark 正是在这两项目标之间的半自回归折中。
DSpark 半自回归草稿:并行主干 vs 顺序头
DSpark 用改进版 DFlash 作 并行主干(约 2–3 层轻量 MoE),一次前向出 $K$ 个位置特征;再用极轻 顺序头 $g_\theta$ 逐位注入块内因果。
$$ E = {e_{t+1}, \ldots, e_{t+K}} = \mathrm{DFlashBackbone}(h_t^p) $$
$$ \tilde{e}{t+i} = g\theta\bigl(e_{t+i},, \mathrm{Embed}(\hat{x}{t+i-1})\bigr), \quad \hat{q}i = \mathrm{softmax}(W{\mathrm{lm}}\tilde{e}{t+i}) $$
为何「2–3 层 MoE 很大」,而「串行 $K$ 次」却很 trivial?
比的不是 并行 vs 串行,而是 每步有多重:
| 第一步:并行主干 | 第二步:顺序头 $\times K$ | |
|---|---|---|
| 算什么 | 2–3 层 MoE,一次前向出 $K$ 位 $E$ | 每步:embed 上一位 + 极小 $g_\theta$ + lm 投影 → 采 1 token |
| 参数量级 | 小 Transformer/MoE 整块权重 | 论文口径 $<0.1%$ 主模型 |
| 访存 | 从 HBM 拉 MoE 专家,$K$ 位并行 matmul | 主张在 寄存器 / on-chip,几乎不碰大块权重 |
| 在 $\tau_q$ 里 | draft 侧 主体算量 | 加性小尾巴 |
Eagle3 式串行:第 $i$ 步 = 再跑 一整段 draft Transformer → $K$ 次「小模型完整前向」,$\tau_q \propto K$。
DSpark 式串行:第 $i$ 步只在 已算好的 $e_{t+i}$ 上用 $g_\theta$ 注入 $\hat{x}_{t+i-1}$ → $K$ 次 寄存器级微算,不是 $K$ 次 MoE 前向。
一句话:重的只并行 一次(买整块语义 + 第 1 位高接受率);串行只串 轻头(补 DFlash 缺的块内因果)。若第二步也每层跑 MoE,就退化成 Eagle,配不上「半自回归」。

{kind=link}
置信度调度与验证截断
DSpark 为 batch 内每个请求选验证长度 $L_j$($1 \le L_j \le K$),在 SLA 下最大化期望接受收益:
$$ \max_{L_1,\ldots,L_B} \sum_{j=1}^{B}\sum_{i=1}^{L_j} \tilde{c}_{t+i}^{(j)} \quad \text{s.t.}\quad \mathrm{Latency}\bigl(\mathrm{BatchConfig}(L_1,\ldots,L_B)\bigr) \le \mathrm{SLA} $$
$\tilde{c}_{t+i}^{(j)}$ 为第 $j$ 条请求、草稿第 $i$ 位的 存活置信度(校准后 $\approx$ 经验接受率)。
截断 / 减少验证长度:对效率与「准确率」的影响
| 维度 | 影响 |
|---|---|
| 输出准确率 / 分布 | 不变。target 仍按 rejection sampling 校验;lossless,不会多接受主模型本不认可的 token。 |
| 单请求加速比 | $L_j$ 缩短 → 本轮少验后缀 → 单用户 加速红利下降;$L_j \to 1$ 时 体感接近 MTP-1(仍走 draft+verify,不是关投机)。 |
| 系统吞吐 / 效率 | 高负载或低置信时缩短 $L_j$,少把 target batch 浪费在 大概率被拒的尾巴 上 → 全局吞吐 $\uparrow$,SLA 下更多算力给高 $\tilde{c}$ 前缀。 |
| draft 侧算力 | 几乎不减。并行主干往往仍生成完整 $K$ 块草稿;截断只省 verify 侧。 |
| 模式 | draft | target verify | 含义 |
|---|---|---|---|
| 纯原生 decode | 无 | 每步 1 token | 不走 spec-decode |
| 弱投机(MTP-1) | 有(常 1 位) | 每轮 verify 1 位 | $L_j=1$,仍算投机 |
| DSpark 截断 | 可仍生成 $K$ 位草稿 | 只 verify 前缀 $L_j$ 位 | 沿 $L$ 连续变浅,非关投机 |
负载自适应:低并发可验 4–6 位;高并发 平滑缩短 $L_j$。

{kind=link}
MTP:一次前向如何融合中间 token
V3/V4 MTP 在位置 $t$ 上:主网预测 $x_{t+1}$;MTP 链再预测 $x_{t+2}, x_{t+3}, \ldots$。每一位都通过 「上一层 hidden + 一个中间 token 的 embed」 融合,不是无依赖并行吐出 K 个 token。
读图:MTP 融合 scheme 专文 · 融合 SVG · 串行链深度计算图
{kind=link}
{kind=link}
融合公式
对 MTP 深度 $k$($k=1$ 时 $h_t^{(0)}$ 来自主网):
$$ h_t^{\prime(k)} = M_k\bigl[,\mathrm{RMSNorm}(h_t^{(k-1)})\ ;\ \mathrm{RMSNorm}(\mathrm{Emb}(x_{t+k})),\bigr], \quad h_t^{(k)} = \mathrm{TRM}k(h_t^{\prime(k)}), \quad P(x{t+k+1}) = \mathrm{softmax}\bigl(\mathrm{OutHead}(h_t^{(k)})\bigr) $$
- 融的是单个 $x_{t+k}$,不是一次性 $\mathrm{Emb}(x_{t+1:t+k})$ 全塞进去。
- $\mathrm{TRM}_k$ = 1 层浅 Block;不是重跑主网 L 层。
训练目标:
$$ \mathcal{L}{\mathrm{total}} = \mathcal{L}{\mathrm{main}} + \sum_{k=1}^{M} \lambda_k \mathcal{L}_{\mathrm{MTP}}^{(k)} $$
「一次前向」指什么?
| 阶段 | 主 Transformer | MTPBlock | 中间 token 从哪来 |
|---|---|---|---|
| 训练 | 1 次前向 → 全体 $h_t^{(0)}$ | 各 $t$ 上批量跑浅 MTP;不重跑主网 | teacher forcing 真值 $x_{t+1}, x_{t+2}, \ldots$ |
| 推理(MTP 当 draft) | 每 decode 轮 1 次 verify | MTP 链式 $K$ 小步:融 $\mathrm{Emb}(\hat{x}_{t+k})$ + MTPBlock | 上一步刚 propose 的 $\hat{x}$ |
三个不是:
- 不是 一个 softmax 无依赖同时吐出 $t{+}1,\ldots,t{+}K$(因果链仍在)。
- 不是 为 MTP 把 671B 主网跑 $K$ 遍(多的是 K 个 浅 MTP Block)。
- 不是 推理时中间 token 永远用真值(draft 时用 已猜 embed)。
与 DSpark 对照:MTP = 主网 1 次 verify + MTPBlock 串 $K$ 步(融 embed);DSpark = 并行 MoE 主干 1 次 + 更轻的 $g_\theta$ 串 $K$ 步。

{kind=link}

DeepSpec draft 训练 vs 主模型 fine-tune
范畴:DSpark 线上推理不改 V4 基座权重。**「训练」指 DeepSpec 里 外挂 draft 的蒸馏/SFT;「在线引擎」**指 draft 接入后的调度与 kernel。二者都不是 V3/V4 主模型预训练或 fine-tune。
动谁的权重?
| 说法 | 动谁 | 改变什么 |
|---|---|---|
| 主模型 SFT / RL | Target $M_p$ | 输出分布 $p$,能力边界 |
| DeepSpec 训外挂 draft | 只动 $M_q$ / DSpark | 提议分布 $q \to p$,冻结 target |
| V3 MTP 联合训练 | 骨干 + MTP 头 | 既改 $p$ 也改原生 draft(同 checkpoint) |
用新样本「下游特化」算 fine-tune 吗?
- 只训 draft、target 冻结:应叫 draft 域适配 / 蒸馏,不是主模型 fine-tune。lossless 校验保证最终输出仍服从 固定 $p$——不会让主模型变聪明,只可能让 $q_i \approx p_i$ 在新场景上更准 → $\mathbb{E}[N_{\mathrm{acc}}]$ $\uparrow$ → 更快。
- 要改答案质量 / 领域能力:必须 SFT 或 RL 动 target(或预训练期 MTP 联合更新)。可与「为 frozen target 训 domain draft」并行两条线,但 不能互相替代。

{kind=link}
一句话:外挂 draft 用新数据训 = 给 draft 做微调;不更新主模型;在 lossless 前提下 只提速、不升智。加速来自 推理投机栈,不来自 draft 训练本身。
与专文对照
| 主题 | 专文章节 |
|---|---|
| Compute / Memory;DFlash vs Eagle | 答疑 §1–§7 |
| 投机循环、lossless | §1 |
| MTP vs 外挂 draft | §2 |
| MTP 中间 token 融合 | MTP 融合 scheme · SVG |
| Eagle / DFlash / DSpark 范式 | §4 |
| 机制细节 | §5–§6 |
| 线上 MTP-1 基线 | §8、§10 |
Thinking with Visual Primitives — 论文要点
← 演进总览 §3.8 · ← 中文导读 · ← V4 梗概 PDF:Visual Primitives 原文 PDF · DeepSeek-AI + 北大 + 清华 · 2026
一句话
在 DeepSeek-V4-Flash 语言骨干上,把 点 / 框 等视觉原语当作 CoT 的「最小思维单元」交错写入推理链,配合 DeepSeek-ViT → 3×3 patch 压缩 → CSA 4× KV 压缩,800×800 输入在 KV cache 中仅保留约 90 条 视觉 entry,却在多项空间推理 benchmark 上对标 GPT-5.4 / Gemini-3-Flash 等前沿 MLLM。
1. 问题:Reference Gap
| 瓶颈 | 说明 |
|---|---|
| Perception Gap | 「Thinking with Images」靠高分辨率裁剪补感知 |
| Reference Gap | 自然语言难以精确指向复杂空间布局 → 多步空间推理易逻辑崩溃 |
| 本文 | 用 visual primitives(bbox / point)作无歧义空间指针,与文本 CoT 交错 |
2. 架构:V4-Flash + ViT 双模块
LLaVA 式:DeepSeek-ViT 编码图像 → 与文本 token 交错 → V4-Flash(284B / 13B act MoE)生成带 visual primitives 的回复。
Figure 2 — 架构与训练管线

Figure 2 | Model architecture and training pipeline(论文原图截取)。
| 模块 | 要点 |
|---|---|
| DeepSeek-ViT | 自研 ViT;14×14 patch;任意分辨率 |
| 3×3 spatial compression | ViT 输出每 9 个 patch token 通道维合并为 1 |
| V4-Flash LLM | 继承 CSA:视觉 token 在 KV cache 再 4× 压缩 |
| 训练阶段 | Pretrain(输出 primitives)→ 分域 SFT/RL → Unified RFT → On-Policy Distillation |
数值示例:
| 阶段 | Token / entry 数 |
|---|---|
| ViT patch tokens | 2,916 |
| 3×3 压缩后进 LLM | 324 |
| CSA 后进 KV cache | 81 |
| 总压缩比 | 7,056×(像素 → KV entry) |
与纯文本 V4 线的衔接:同一 CSA 稀疏压缩 机制,此处用于 视觉 KV 而非仅长文本 context。
{kind=link}
3. Visual Primitives 定义
| 原语 | 用途 |
|---|---|
| Bounding box | 物体位置与尺度;标注相对确定 |
| Point | 轨迹、拓扑推理等抽象引用 |
Pretrain 目标:模型能在 CoT 中 生成 上述原语(De-Tokenizer 解码为可视化 marker)。
Figure 3 — Cold-start 计数数据示例

Figure 3 | Illustrative cold-start data for coarse-grained and fine-grained counting.
| 要点 | 说明 |
|---|---|
| 数据形态 | 图像 + 语言指令 + 框/点 标注作为监督 |
| 粗 vs 细 | 粗粒度全图计数;细粒度带属性/空间约束 + hard negative |
| 动机 | 公开 COCO / Pixmo 规模与多样性不足 → 大规模 web box grounding(97k+ 源) |
{kind=link}
4. Token 效率

Figure 1 | (a) Token consumption for 800×800 image. (b) Average score on selected benchmarks.
| 子图 | 解读 |
|---|---|
| (a) Token 数 | 800×800 输入:本文约 361 tokens(KV 约 90 entries);Gemini-3-Flash ~1100;Claude-Sonnet-4.6 ~870 |
| (b) 均分 | 7 项 benchmark 子集均分 77.2%,高于 GPT-5.4(69.7%)、Gemini-3-Flash(65.3%)等 |
| 结论 | 极低视觉 KV 占用 下仍保持 competitive 空间推理——压缩链(ViT + CSA)是核心 infra 叙事 |
{kind=link}
5. Table 1 — 与前沿模型对比

Table 1 | Comparison with frontier models(API 统一 prompt 评测;bold=最佳,underline=次佳)。
| 类别 | 代表 benchmark | 本文亮点 |
|---|---|---|
| Counting | CountQA、Pixmo-Count、DS_Finegrained_Counting | 细粒度计数 88.7 EM(DS_Finegrained) |
| Spatial VQA | MIHBench、SpatialMQA、CV-Bench | SpatialMQA 69.4;MIHBench 85.3 |
| Topological | DS_Maze_Navigation、DS_Path_Tracing | 迷宫 66.9、路径追踪 56.7,大幅领先 Qwen3-VL 等 |
论文强调:表内分数仅覆盖与 visual primitives 研究相关的评测维度,不代表模型全能。
{kind=link}
6. 与 DeepSeek 主线关系
| 维度 | 衔接 |
|---|---|
| 基座 | V4-Flash(284B/13B)— 见 演进总览 §3.7 |
| Attention / KV | 复用 CSA 4:1 压缩 → 视觉 KV 81 entries 量级 |
| MoE | 与 V4 Hash MoE / FP4 同代推理栈 |
| 定位 | V4 主线之后的 多模态支线:不改 LLM 稀疏注意力叙事,增加 ViT + 原语 CoT |
7. 图/表索引
| 文件 | 论文 |
|---|---|
| Figure 1 — Token 效率 | Figure 1 |
| Figure 2 — 架构与训练管线 | Figure 2 |
| Figure 3 — Cold-start 计数 | Figure 3 |
| Table 1 — Benchmark 对比 | Table 1 |
重新截取:python3 scripts/figures/papers/extract_visual_primitives.py
开发索引
读者请从 版本演进总览 进入;本页仅供维护源路径与构建。
源稿与成书
| 源 | 书中章节 |
|---|---|
| 版本演进总览 | 01-总览/01-版本演进总览.md |
docs/ 下其余 versions/、reports/ | 见 build_book.py 内 CHAPTER_MAP |
python3 scripts/svg/check_svgs.py # 改 SVG 后须 exit 0
python3 《ds-技术报告》/build_book.py
全量路径表(编辑时查阅)
子项目
| 项目 | 路径 |
|---|---|
| Engram | Engram 系列 |
| RL 笔记 | RL / 后训练笔记 |
| DSA / Index Share | DeepSeek DSA 与 Index Share 系列 |
报告与版本
DeepSeek 文档系列结构审查
本报告对 deepseek-tech-notes 仓库文档系列做结构、双向引用、章节导航、概念去重、SVG 复用审查,并记录已落地修复与后续维护命令。
1. 审查范围
| 层级 | 路径 |
|---|---|
| 总览 hub | 版本演进总览 |
| 三线导读 | 算法线 · 基础设施线 · MoE 线 |
| 版本梗概 | 版本梗概索引 |
| 专题卷 | DeepSeek DSA 与 Index Share 系列 · RL / 后训练笔记 · Engram 系列 |
| 答疑 | 答疑索引 |
| 成书 | 《ds-技术报告》/build_book.py |
2. 入口与阅读顺序
唯一主入口:演进总览 → 按 §3 版本节 / §7 专题表 / 三线导读分叉。
全书线性顺序由 build_book.py 的 READING_ORDER 定义;append_chapter_nav() 在每章文末追加「上一章 / 下一章」表。2026-06-27 已确认 FP8 专文在链中:
… → 04-序列均衡损失 → 06-V3-FP8动态量化 → 03-后训练 RLVR → …
维护:改 READING_ORDER 后须重跑 python3 《ds-技术报告》/build_book.py,否则书中导航会跳过新章(本次已手工校正 04-序列均衡损失 / 06-V3-FP8 / 01-RLVR 三处页脚)。
3. 双向引用
约定:每篇正文首段 blockquote 含 ← 演进总览 §x.x 或 ← 系列目录,并链到书中对应章。
3.1 已修复 / 已对齐
| 文档 | 状态 |
|---|---|
| ../rl/README.md | blockquote → 演进总览 §3.4 |
| ../rl/optimize.md | 补标题 + blockquote → RLVR / §3.4 / 书中 GRPO 章 |
| ../dsa/README.md | blockquote 增 §3.6 V3.2 |
| ../dsa/dsa-logic.md · Index Share 逻辑详解 | 顶栏改为 blockquote + §3.6 锚点 |
| 投机解码自测加速比 | 顶栏合并为 blockquote |
| Engram 系列导读 | hr 下 blockquote → §7 专题关系 |
| 答疑索引 | blockquote → 梗概索引 / 演进总览 |
| v1-technical-report.zh.md · deepseek-llm-v1-highlights.md | stub 页补 §3.1 回链 |
3.2 反向引用
演进总览 §3 各版本节已链到对应梗概 / 专文(含 FP8 动态量化 §3.3)。§7 专题表链 Engram / R1 管线等。
建议:§7 可增补 DSA 系列、ESS 概念、Index Share 一行,与三线导读 §5 反向表完全对称。
4. 概念与文档去重
| 概念 | 唯一主文档 | 摘要嵌入 | 答疑 |
|---|---|---|---|
| FP8 训练量化 | V3 FP8 动态量化 | v3.md §附 FP8 同图同链 | fp8-partial-sum-drift.md;fp8-mma-term.md |
| GRPO vs PPO | rlvr.md#grpo | 演进总览 §3.4 同图 | — |
| MTP / 投机 | v3.md §三 | spec-decode 报告 复用 mtp-speculative.svg | — |
| DSA 管线 | DSA 逻辑详解 | 梗概 / Raschka 链同一 dsa-pipeline.svg | — |
| ESS 双 Cache | ESS Latent offload | DSA 系列 / Lightning Indexer 同一路径 | h2d-d2h-pcie-transfer.md |
| V1 译文 | 已并入 DeepSeek-LLM V1 | stub 页仅重定向 | — |
未发现:同一概念两篇并列「概览」;deepseek-v1-to-v3-lineage.md 与演进总览分工明确(前者 V1→V3 纵切,后者全系列)。
5. SVG 规范与 canonical 路径
生成器:scripts/svg/gen_*.py、dsa/scripts/svg/gen_dsa_svgs.py;校验:scripts/svg/check_svgs.py(含 Markdown <img> 嵌入与布局启发式)。
5.1 复用表
| SVG | canonical 源 | 复用位置 |
|---|---|---|
dsa-pipeline.svg | ../dsa/diagrams/dsa-pipeline.svg | dsa 系列、梗概、Raschka |
ess-dual-cache.svg | ../dsa/diagrams/ess-dual-cache.svg | ESS 概念、Lightning Indexer、dsa/README(勿再用 docs/figures/ess/ess-dual-cache.svg) |
index-share-fffs.svg | ../dsa/diagrams/index-share-fffs.svg | Index Share 逻辑 |
v3-moe-vs-v2.svg | docs/figures/v3/(与 diagrams/ 同步) | v3 梗概、演进总览 §3.3 |
grpo-vs-ppo.svg | docs/figures/rl/ | rlvr、演进总览 §3.4 |
mla-mode-switch.svg | docs/figures/v3/ | v3-1、演进总览 §3.5 |
mtp-speculative.svg | docs/figures/v3/ | v3、spec-decode 报告 |
v3-fp8-dynamic-quant.svg | docs/figures/v3/ | FP8 专文、v3 摘要 |
deepseek-version-lineage.svg | diagrams/ | 演进总览 |
mla-forward-flow.svg | docs/figures/mla/(生成器 gen_mla_forward_flow_svg.py) | MLA 专文、演进总览 §3.2 |
build_book.py 中 ASSET_MULTI_DEST 将 ess-dual-cache.svg 从 单一源复制到书中 DSA 卷与 ESS 卷。
5.2 校验状态
| 项 | 说明 |
|---|---|
mla-forward-flow.svg | 已重绘;自 gen_mla_forward_flow_svg.py 生成;LEGACY_SKIP_LAYOUT 已清空 |
| Engram README | 官方 badge 图为外链 SVG,不计入本地 check |
5.3 维护命令
cd <deepseek-tech-notes 仓库根>
python3 scripts/svg/gen_deepseek_svgs.py # 或单独 gen_*.py
python3 dsa/scripts/svg/gen_dsa_svgs.py
python3 scripts/svg/check_svgs.py # 须 exit 0
python3 《ds-技术报告》/build_book.py
6. 答疑结构
- 6 篇正文均有 文首回父节 blockquote。
- qa/README.md 索引表链到演进总览对应 § 与父文档锚点。
- FP8:
partial-sum= 机制;mma-term= 名词,索引表已标注避免误读为重复专文。
7. 遗留 / 低优先级
| 项 | 建议 |
|---|---|
00-V1-技术报告译文.md | 书中 stub,与源 v1-technical-report.zh.md 一致;可保留或从 CHAPTER_MAP 移除 |
| 演进总览 §7 | 补 DSA / ESS / Index Share 反向一行 |
docs/figures/ess/ess-dual-cache.svg | 生成器仍同步副本;Markdown 已统一引用 ../dsa/diagrams/,副本仅作 build 冗余,可日后从 gen 脚本去掉 |
8. 结论
- 入口:演进总览 + 成书
READING_ORDER已形成层层递进;FP8 章已入链。 - 双向引用:系列主文档顶栏 blockquote 已对齐;stub 页已补回链。
- 概念:一概念一主文档;摘要 vs 专文 vs 答疑层级清晰;SVG 按上表 canonical 复用。
- SVG:
mla-forward-flow已接生成器;改图后须跑check_svgs.py+build_book.py;CI 门禁见 scripts/doc_series_gate.sh。
版本 / MoE 答疑
{kind=link}
H2D / D2H 是什么?
← 返回 ESS 论文梗概 §Figure 6&7 · ← ESS 梗概 §Fig.3 / PD 时序 · 答疑目录
1. 定义
| 缩写 | 英文 | 方向 | 典型含义 |
|---|---|---|---|
| H2D | Host-to-Device | CPU 主机内存 → GPU 显存 | 把数据 搬到 GPU 上算 |
| D2H | Device-to-Host | GPU 显存 → CPU 主机内存 | 把结果或 cache 写回 CPU |
在 CUDA 语境里,二者常通过 PCIe(ESS 论文为 PCIe 5.0)或 NVLink 完成;API 层常见 cudaMemcpyAsync(..., cudaMemcpyHostToDevice)(H2D)与 cudaMemcpyDeviceToHost(D2H)。
2. 在 ESS / V3.2 里指什么
ESS 把 Latent-Cache 大头放在 CPU DRAM,GPU 只留 Sparse Memory Pool(LRU 热子集)。每个 decode step:
- Indexer(GPU)选出本步需要的 top-$K$ latent index;
- H2D(prefetch):Cache miss 的 latent entry(约 656B/条)从 CPU 拉进 GPU 热池;
- Core MLA Attention 在 GPU 上算;
- D2H(写回):本步新生成的 latent 写回 CPU 侧 Total Memory Pool。
因此 Fig.3 时间线上的 H2D prefetch、D2H 写回 都是 Latent-Cache 在 CPU↔GPU 间的搬运;Indexer-Cache 不 offload,也不走这条搬运链。
3. 为何 ESS 论文反复强调 H2D
| 问题 | 说明 |
|---|---|
| 小块、分散 | 每步多达 $K{=}2048$ 次、每次仅 656B → 原生 cudaMemcpyAsync H2D 有效带宽极低 |
| 与算力串行 | SGLang 默认:Indexer → H2D → Attention 全串行 → GPU 在等传输时空转 |
| 优化手段 | FlashTrans + UVA 拉高 H2D/D2H 带宽;DA/DBA Overlap 让 Attention 与 H2D 并行(如 Attn0 $\parallel$ H2D) |
论文报告优化后 H2D 约 0.79 → 37 GB/s,D2H 约 0.23 → 43 GB/s(Table/§3 工程数据,见 梗概 §三大工程模块)。
4. 和「Overlap」的关系
无 Overlap(默认)

{kind=link}
DA Overlap
- 把 Attention 拆成 Attn0(只用 GPU 里已有的 latent)和 Attn1(等 prefetch 完成);
- Attn0 与 H2D 同时进行 → 用计算掩盖一部分传输延迟。
DBA 再在 batch 维切 Indexer,长上下文下算力更足,进一步掩盖 H2D。
5. 相关概念
| 概念 | 与 H2D/D2H 关系 |
|---|---|
| Prefetch | 在需要算 Attention 之前 提前发起 H2D,把 miss 的 latent 拉上来 |
| UVA(Unified Virtual Addressing) | GPU 内核直接访问 pinned 的 CPU 地址,减少小块 Memcpy 开销 |
| PCIe 带宽 | H2D/D2H 的物理上限;ESS 针对「大量小传输」做软件栈优化 |
6. 延伸阅读
- ESS 论文梗概 — Fig.3 时序、Fig.6–7 Overlap、FlashTrans 数据
- ESS Latent offload — ESS 概念与双 Cache 分工
为何 DeepSeek 用 $C=M\cdot D$ 而非 $C=6ND$?
← 返回演进总览 §3.1 V1 · ← V1 §3 Scaling Laws · 答疑目录
来源:DeepSeek-LLM arXiv:2401.02954 §3.2 · Table 3 / Formula 2–4
1. 一句话
不是把 Chinchilla 的 $6$ 随便改掉,而是:$6N$ 只是「每 token 算力」的粗近似;DeepSeek 改用实测的 $M$(non-embedding FLOPs/token),于是总算力按定义写成 $C=M\cdot D$——IsoFLOP 拟合(Figure 4a)才准。
2. 传统写法:$C \approx 6ND$
Kaplan / Chinchilla 系 scaling law 里,训练总算力常写成:
$$ C \approx 6ND $$
| 符号 | 含义 |
|---|---|
| $N$ | 模型规模(参数量,有两种取法,见下) |
| $D$ | 训练 token 数 |
| 6 | 一次 forward + backward 相对 forward 的 FLOPs 倍数($\approx 1+2=3$ 再乘 matmul 计数约定) |
$N$ 的两种常见定义:
| 符号 | 定义 | 文献 |
|---|---|---|
| $N_1$ | non-embedding 参数量 | Kaplan et al. |
| $N_2$ | 含 embedding / lm_head 的全参 | Hoffmann et al.(Chinchilla) |
于是「每 token 算力」可粗写为 $6N_1$ 或 $6N_2$,再乘 $D$ 得 $C$。
3. $6N$ 哪里不准?
V1 论文指出:$6N_1$ 与 $6N_2$ 都不是真实的 per-token FLOPs,误差在小模型上尤其大:
| 近似 | 问题 |
|---|---|
| $6N_1$ | 只数 FFN/线性层 matmul,不含 attention 的 $O(L^2)$ 项 → 低估算力 |
| $6N_2$ | 在 $6N_1$ 基础上 加上 $6,n_{\mathrm{vocab}},d$(vocab 投影)→ 对能力贡献小却 高估算力;仍 不含 attention |
DeepSeek 给出三者闭式(Formula 2,$l_{\mathrm{seq}}$ = 序列长度):
$$ \begin{aligned} 6N_1 &= 72 \cdot n_{\mathrm{layer}} \cdot d_{\mathrm{model}}^2 \ 6N_2 &= 72 \cdot n_{\mathrm{layer}} \cdot d_{\mathrm{model}}^2 + 6 \cdot n_{\mathrm{vocab}} \cdot d_{\mathrm{model}} \ M &= 72 \cdot n_{\mathrm{layer}} \cdot d_{\mathrm{model}}^2 + 12 \cdot n_{\mathrm{layer}} \cdot d_{\mathrm{model}} \cdot l_{\mathrm{seq}} \end{aligned} $$
$M$ = non-embedding FLOPs/token:计 attention,不计 vocab 投影——作为「模型有多重、每 token 算多狠」的度量。
4. Table 3:小模型上误差可达 50%

{kind=link}
| $n_{\mathrm{layer}}$ | $d_{\mathrm{model}}$ | $6N_1/M$ | $6N_2/M$ |
|---|---|---|---|
| 12 | 768 | 0.43 | 1.32 |
| 24 | 1024 | 0.69 | 1.14 |
| 32 | 4096 | 0.97 | 1.01 |
- $6N_1/M < 1$(12 层仅 0.43):缺 attention → 严重低估 $M$
- $6N_2/M > 1$(12 层 1.32):多计 vocab → 高估 $M$
- 模型变大后趋近 1,但 IsoFLOP 扫小模型时若仍用 $6N$,会把「同一 $C$ 下的不同 $(M,D)$ 分配」搞错 → U 形曲线(Figure 4a)拟合被污染
因此 Formula 4 / IsoFLOP 统一用 $M$,不用 $6N_1$/$6N_2$。
5. 改成 $C = M \cdot D$ 在算什么?
这是 定义,不是新物理定律:
$$ \boxed{C = M \cdot D} $$
| 量 | 含义 |
|---|---|
| $M$ | 每个训练 token 的 non-embedding forward FLOPs(含 attention,不含 embedding 矩阵乘) |
| $D$ | 训练 token 总数 |
| $C$ | 总训练算力(FLOPs) |
与 $6ND$ 的关系:若你坚持用参数量 $N$,只能选 $N_1$ 或 $N_2$,再乘 6 去 近似 $M$;DeepSeek 选择 直接测 $M$,避免 $N_1$/$N_2$ 双轨与 attention 缺失。
训练时仍用 3× forward 做 backward——变的只是 用什么标度刻画「模型规模」:从 参数个数 $N$ 换成 每 token 实际 FLOPs $M$。
6. 和 Figure 4a / IsoFLOP 的关系
IsoFLOP 实验:固定总算力 $C$,扫约 10 种 $(M,D)$ 满足 $M\cdot D=C$,找 validation loss 谷底。
- 横轴必须是 真实的 $M$(FLOPs/token),不能是 $6N_1$ 或 $6N_2$
- 若用 $6N$ 当横轴,小模型点会 系统性偏移,谷底位置错 → $M_{\mathrm{opt}}(C)$、$D_{\mathrm{opt}}(C)$(Formula 4)不可信
Figure 4a 的 U 形曲线因此建立在 $C=M\cdot D$ 之上;演进总览 §3.1 所贴即此图。
7. 和数据质量结论的关系
论文在 Formula 4 成立(即用 $M$) 之后还发现:不同语料拟合的 $M_{\mathrm{opt}}\propto C^a$、$D_{\mathrm{opt}}\propto C^b$ 指数 $a,b$ 不同——数据质量越高,$a$ 越大 → 更该扩模型而非堆数据。
这是 第二层结论,依赖第一层「用 $M$ 而不是 $6N$ 把 $C$ 算准」。
8. 常见误解
| 误解 | 正解 |
|---|---|
| DeepSeek 否定了 Chinchilla | 仍做 IsoFLOP;改的是 模型规模的度量($M$ vs $6N$) |
| $C=MD$ 意味着 7B/67B 必须同 $D$ | $C=M\cdot D$ 是乘法 定义;产品统一 2T 是 工程选择,见 Scaling-Law 选择性应用 |
| 6 这个常数错了 | 6 来自 fwd+bwd 计数;问题在于 $N$ 不能代表 per-token FLOPs(缺 attention / 多 vocab) |
9. 延伸阅读
| 文档 | 内容 |
|---|---|
| V1 §3.2 最优 model/data Scaling | Formula 2–4 原文与 Figure 4 |
| Scaling 答疑 | $M$ 推导、Formula 1/4 数值、4B 实战 |
| Scaling-Law 选择性应用 | Figure 3/4/5 分工;2T 产品 vs IsoFLOP 谷底 |
| 产品训练与 Scaling Law | 7B/67B 同训 2T 与 compute-optimal 的区别 |
版本 / MoE 答疑
{kind=link}
名词解释:MMA
← 返回 FP8 专文 · partial sum 漂移 · 答疑目录
MMA 是什么
MMA = Matrix Multiply-Accumulate(矩阵乘加)。
一次 MMA 在硬件上做:
$$ D \leftarrow A \times B + D $$
即:取两块小矩阵(或向量块)相乘,结果 加进 累加器 $D$(不是每次写新内存)。大矩阵乘 GEMM 在 GPU 上就是 成千上万次 MMA 拼出来 的。
在 DeepSeek-V3 FP8 语境里指什么
| 词 | 含义 |
|---|---|
| MMA | Tensor Core 上的 单次/单步 低精度乘加(V3 训练用 FP8) |
| GEMM | 整层线性层 $Y=XW$ 的 完整矩阵乘(内部 = 多轮 MMA) |
| WGMMA | Warp-Group MMA;Hopper(H100 等)上 一组 warp 协作 的一条 MMA 指令流,V3 论文 Figure 7(b) 标成 WGMMA 1–4 |
| [partial sum | 某一输出元素在 整条 MMA 链还没加完 时的中间累加和](fp8-partial-sum-drift.md) |
V3 文档里「每 $N_c{=}128$ 次 MMA」= 每做满 128 个 MMA 粒度的乘加贡献,就把 Tensor Core 里低精度 partial sum 提到 CUDA Core FP32 再累,防止漂移。
和 MHA / MQA 不要混
| 缩写 | 领域 | 含义 |
|---|---|---|
| MMA | GPU 算子 / FP8 训练 | Matrix Multiply-Accumulate |
| MHA | 注意力 | Multi-Head Attention |
| MQA | 注意力 | Multi-Query Attention |
V3.1 Prefill MHA / Decode MQA 是 MLA 模式切换,与 FP8 的 MMA 指令 无关。
硬件落点
| 硬件 | MMA 相关职责 |
|---|---|
| Tensor Core | 执行 FP8 MMA / WGMMA;块内低精度乘加、短链 partial sum |
| CUDA Core | MMA 结果 反量化(乘 $s_x s_w$);partial sum FP32 续累加 |
一句话
MMA = GPU Tensor Core 的 矩阵乘加原语;V3 FP8 训练里的「MMA 漂移 / 每 128 MMA 提升 FP32」都是在说 这条乘加累加链 的数值行为,不是注意力里的 MHA/MQA。
FP8 动态量化里的 partial sum 漂移
1. partial sum 是什么
矩阵乘 $Y = X W$ 里,每一个输出标量都是一条内积:
$$ Y_{i,j} = \sum_{k=1}^{K} X_{i,k}, W_{k,j} $$
硬件做 GEMM 时不会一次性算完整个 $K$,而是按 MMA(Matrix Multiply-Accumulate) 分块:每来一小块 $(X_{i,k}, W_{k,j})$ 就 乘加进同一个累加寄存器。这个 尚未算完的中间和,就是 partial sum(部分和)。
DeepSeek-V3 在 FP8 Tensor Core 上跑这些 MMA;Figure 7(b) 的 WGMMA 1–4 就是在同一条输出维度上 连续收 partial sum。
2. 「漂移」指什么
漂移(drift) = partial sum 相对 理想 FP32/BF16 内积 的偏差,随着 MMA 次数变多 单调变大,最后写回的 $Y_{i,j}$ 系统性偏离真值。
根因不是「FP8 乘一次就不准」这么简单,而是 低精度累加链太长:
| 环节 | 发生了什么 |
|---|---|
| 每次 MMA | FP8(或 TC 内更低精 acc)乘加 → 舍入一次 |
| 重复 $K$ 次 | 误差 累积,不是随机抵消 |
| $K$ 很大 | V3 的 hidden / expert 宽度 $\gg 128$,一条内积要 成千上万次 MMA |
直觉:像用 短尺子 一段段量长跑,每段都有四舍五入,段数越多,终点离真实长度越远。
3. 和 细粒度 scale 的分工
专文 Figure 7 两路逻辑 解决不同环节的问题:
| 机制 | 作用阶段 | 针对误差 | V3 实现要点 |
|---|---|---|---|
| (a) Fine-grained scale | 乘之前 量化 | 激活离群导致 FP8 表示失真 | 激活/权重按 $N_c{=}128$ 切块;每块算 dynamic scale $s_x, s_w$(由块内 absmax 定标);块内 round 到 FP8 后送 Tensor Core MMA;CUDA Core 对 MMA 输出乘 $s_x \cdot s_w$ 反量化 |
| (b) FP32 promotion | 乘之后 累加 | MMA 链上 partial sum 漂移 | WGMMA 在 TC 内用 低精度 acc 沿 $K$ 维收 partial sum;每 128 个 MMA 元素 flush 到 CUDA Core FP32 寄存器 续加;TC acc 清零 再收下一段;整条内积 = 多段 FP32 部分和之和 |
(a) 保证送进 MMA 的 FP8 块「尽量满量程」;(b) 保证 加起来的过程 不会因为 TC 低精度 acc 太长而漂。
实现上两路在同一次 GEMM 内核里串联:先 (a) 按块量化并发起 MMA,MMA 流水里嵌入 (b) 的 128 步 promotion;反量化与 FP32 累加都在 CUDA Core 完成、Tensor Core 只负责 FP8 乘加吞吐。
二者 都要;只做 (a) 仍可能在宽矩阵上累加崩,只做 (b) 仍可能被 outlier 块量化拖垮。
4. 数学上误差怎么叠
设第 $t$ 步 MMA 的真实贡献为 $p_t$,低精度累加器得到 $\hat{s}_t$:
$$ \hat{s}t = \mathrm{round}\bigl(\hat{s}{t-1} + \mathrm{round}(p_t)\bigr) $$
理想 FP32 累加 $s_t = s_{t-1} + p_t$。每步引入 $\epsilon_t = \hat{s}_t - s_t$,一般 有偏、可累积。当 $t$ 从 1 到 $K$:
$$ \hat{s}K - s_K \approx \sum{t=1}^{K} \epsilon_t $$
$K$ 越大(MoE FFN、宽 MLA 投影),$|\hat{s}_K - s_K|$ 越容易 肉眼影响 loss。这就是表格里「大量 FP8 MMA 后 partial sum 漂移」的含义。
5. V3 对策:每 $N_c = 128$ 提升到 FP32
Figure 7(b) Increasing accumulation precision:
- Tensor Core 内用 低精度 acc 收 partial sum(快);
- 每累计 $N_c = 128$ 个 MMA 元素,把当前 partial flush 到 CUDA Core 的 FP32 寄存器,以 FP32 续加;
- TC 侧 acc 清零,再收下一段 128 个 MMA。
效果:低精度链最长只有 128 步,误差被 周期性「归零到 FP32」;总内积仍由多段 FP32 和组成,漂移上界 与「全程 TC 低精度累加 $K$ 步」相比大幅缩小。
对应专文一句:算在 TC、稳在 CUDA FP32。
6. 和推理 FP8 的区别
| 训练(本文 / V3 Figure 7) | 推理 FP8(如 draft benchmark) | |
|---|---|---|
| 目标 | 671B 可收敛 预训练 | 延迟 / 吞吐 |
| partial sum | 显式 FP32 promotion 内核 | 依引擎实现,未必同策略 |
| 块 scale | 训练侧 dynamic $s_x, s_w$ | 部署 calibrate / 静态 scale 常见 |
推理里「FP8 更快」不自动等于训练里同一套 anti-drift;读 partial sum 漂移应 锚定 V3 训练 GEMM。
7. 一句话
Partial sum 漂移 = FP8 MMA 在 Tensor Core 里 太长链低精度累加 导致的系统性数值偏差;V3 用 每 128 MMA 提升到 FP32 截断累加链,与块级 dynamic scale 互补,共同把 FP8 训练做稳。
Hash MoE 为何只改浅层、深层仍用 centroid 路由?
← 返回 Hash MoE §1.2 · EP 答疑 §4 · centroid vs gate-weight §4.4 · 答疑目录
一句话
Hash 路由用确定性函数换 零 router GEMM + 静态负载;适合 浅层偏通用、对语义特化要求低 的 FFN。深层仍要 按 token 语义选 expert($u^\top e_i$ + aux-loss-free),才能保留 V3 系 细粒度 specialization 与 动态均衡——全栈 Hash 省算力更多,但 表达能力与 EP 负载风险 都不划算,所以 V4 选 浅 Hash + 深 centroid 的混合栈。
1. 两种路由各自擅长什么
| 维度 | Hash(浅层) | Centroid / aux-loss-free(深层) |
|---|---|---|
| Expert id | token / 位置 hash → 近似均匀 | $u^\top e_i$ 语义亲和度 + top-$K_r$ |
| Router 算力 | 无 对 256 expert 的打分 GEMM | 每层每 token 一次 routed 打分 |
| 负载均衡 | hash 设计 静态近似均匀 | 动态 bias $b_i$ + $L_{\mathrm{Bal}}$ |
| 特化能力 | 弱 — id 与「内容类型」解耦 | 强 — expert 向量 $e_i$ 学「原型 / 簇」 |
| 典型层位 | 前几层 MoE / 原 dense FFN | 中深层 主力 MoE 层 |
2. 为何浅层可以 Hash
2.1 浅层 FFN 更偏「通用变换」
靠近 embedding 的 FFN 多在 升维 / 非线性 / 局部混合,尚未形成强 任务 / 领域 分化。此时用 hash 把 token 伪随机但均匀 摊到 expert 上,等价于 加宽 FFN 容量,对 语义匹配 依赖较小。
2.2 省下来的主要是 router 与参数
V3 每层 MoE 要对 全体 routed expert 算亲和度(256 维量级),再 top-8。浅层 层数少但 token 吞吐相同,若前几层原是 dense FFN 或 MoE,改成 Hash MoE 可以:
- 去掉 $e_i$、router GEMM 与部分 aux 路径;
- 仍走 EP + shared,id 确定后引擎与 V3 同族。
动机表里写的 「省路由算力与参数;浅层更偏通用变换」 即此。
2.3 静态 hash 够用的前提
Hash 层 不随 batch 调 $b_i$。浅层 expert 负载若天然较匀、且 不承担精细语义分工,静态 hash 的 近似均匀 通常够用;这也是只放浅层的 前提条件。
3. 为何深层不动
3.1 深层需要「按内容选 expert」
越靠后,hidden 越 抽象、任务相关。DeepSeekMoE 的 centroid 叙事是:token 与 expert 原型 $e_i$ 匹配(centroid 答疑)。数学 / 代码 / 多语言等 分化 主要在 中深层 MoE 体现;改成 hash 等于 强行去掉内容条件路由,特化能力损失大。
3.2 动态均衡在深层更关键
深层 MoE 激活参数占比高,EP 下 热点 expert 代价更大(EP 答疑 §3)。V3 的 $b_i$ + $L_{\mathrm{Bal}}$ 针对 batch / 序列内 动态调节;hash 无法 在「某 expert 突然过热」时微调路由,全深层 hash 会让 EP 空转风险 上升。
3.3 训练与迁移:深层沿用 V3 族更稳
V4 继承 DeepSeekMoE 256/8 + shared 与 sigmoid + bias 路由(aux-loss-free)。深层不动 → 大部分 MoE 层 权重形态、训推 kernel、EP 路径与 V3 同族,只在前几层插入 Hash 块;若 全栈 Hash,router 权重与 checkpoint 语义 全面重写,风险与验证成本都高。
3.4 收益递减
Hash 省的是 router 侧 FLOPs 与参数;深层 FFN expert 本体 仍是算力大头。把 Hash 推到全层,额外省的 router 占比变小,但 质量与均衡风险 单调变差 → 混合栈 是 Pareto 折中。
4. 混合栈长什么样

Hash 仅替换浅层 Phase A→B 的路由函数;Phase C(EP scatter → Routed FFN → Gather+shared)与 V3 推理栈不变。
{kind=link}
| 段 | 路由 | 后面引擎 |
|---|---|---|
| 浅层 | Hash MoE — 确定性 id,无 centroid GEMM | hidden 初步混合后进入深层 |
| 深层 | V3 族 MoE — $u^\top e_i$ + top-$K_r$ + shared + $b_i$ 均衡 | 仍走 EP scatter → expert FFN → gather + shared |
- 改的是「浅层选 expert 的函数」;id 一旦确定,后面仍是 EP scatter → expert FFN → gather + shared。
- FP4 作用在 routed expert 权重 上,与 Hash vs centroid 正交(Hash MoE 专文 §2),深层 routed 也可 FP4,router 逻辑仍 centroid。
5. 常见误解
| 误解 | 澄清 |
|---|---|
| 「V4 全部 MoE 都 Hash」 | 否 — 仅 前几层 |
| 「深层不用 MoE」 | 否 — 主力层仍是 256/8 DeepSeekMoE + centroid |
| 「Hash 层不做 EP」 | 否 — 仍 gather/scatter,只改 id 怎么来 |
| 「浅层 Hash = 质量一定差」 | 设计假设是浅层 特化需求低;深层保留 learned routing 兜底能力 |
6. 与论文口径
V4 2606.19348 将 Hash MoE 与 FP4 MoE 作为 MoE 线改动与 CSA/HCA 等 同期打包;公开材料对 具体层号 着墨有限,本地文档以 「前几层 / 浅层 vs 深层 centroid」 表述,细节以论文与权重 config 为准。
参考
MoE 路由:gate-weight 还是 expert centroid?
问题从哪来
多数 MoE 文献(Switch、GShard、Mixtral 等)把 Router 写成 gate network:一个线性层或 MLP 输出 $N$ 维 logits,再 softmax / top-$k$ 得到 gate weights。
DeepSeek-V2 / DeepSeekMoE 论文(Eq. 20–22)却写:
$$ s_{i,t} = \mathrm{Softmax}_i(u_t^\top e_i), \quad e_i = \text{「第 } i \text{ 个 routed expert 的 centroid」} $$
并把 $s_{i,t}$ 叫 token-to-expert affinity(亲和度),$g_{i,t}$ 才叫 gate value——且 $g_{i,t}$ 只在 Top-$K$ 非零。

{kind=link}
1. 算子上:常常等价,语义上:两套叙事
把 $e_i \in \mathbb{R}^d$ 排成矩阵 $E \in \mathbb{R}^{N_r \times d}$,则
$$ u_t^\top e_i = (E u_t)_i $$
这与「Router 线性层 $W_g \in \mathbb{R}^{N_r \times d}$,logits $= W_g u_t$」是同一类双线性打分——参数可一一对应($W_g$ 的第 $i$ 行就是 $e_i^\top$)。
| 叙事 | 在问什么 | 典型符号 |
|---|---|---|
| Gate-weight | 「给每个 expert 一个调度权重」 | $W_g$, router logits, $g_i$ |
| Centroid / affinity | 「token 离哪个 expert 的代表点最近?」 | $e_i$, $s_{i,t}$, affinity |
DeepSeek 选第二种写法,不是因为算子不能实现成 gate layer,而是要把路由解释成 hidden space 里的匹配 / 聚类,与 fine-grained expert specialization 的设计目标对齐。
2. 概念区别:三条分工
DeepSeek 公式里其实拆了三层,很多 gate-only 写法混为一谈:
| 层 | 符号 | 作用 | 是否稀疏 |
|---|---|---|---|
| ① 匹配 | $s_{i,t} = f(u_t, e_i)$ | token 与各 expert 原型的亲和度 | 否(对全体 routed 算分) |
| ② 选择 | Top-$K_r$ on ${s_{i,t}}$(V3 起加 $b_i$) | 哪些 expert 参与 | 是 |
| ③ 门控 | $g_{i,t}$(选中后取 $s$ 或归一化 $s$) | expert 输出 乘多少 | 仅 $K_r$ 非零 |
Gate-weight 文献常把 ①②③ 合成一个向量 $g=\mathrm{TopK}(\mathrm{softmax}(W u))$。
Centroid 叙事强调:
- $e_i$ 不是 FFN 权重,而是 expert $i$ 在 同一 hidden 空间里的 routing 原型(可学习向量);
- expert 特化 = 「处理亲和 $e_i$ 的 token 簇」;
- $g$ 只是稀疏化后的 执行系数,语义上从 affinity 派生。
3. 为什么 DeepSeek 要强调 centroid?
3.1 与 fine-grained segmentation 同构
DeepSeekMoE 把 $N$ 个大 expert 拆成 $2N$ 个小 expert:
- expert 越多 → hidden 空间被划得越细;
- 每个 $e_i$ 像一个 小簇中心;
- 路由 = 「这个 token 属于哪个细簇」→ 走对应小 FFN。
若只叫 gate-weight,很难在论文里自然推出「为什么要 160 个小 expert」;centroid + clustering 直觉更顺。
3.2 与 shared expert 分工一致
- Shared FFN:不走 $e_i$ 匹配,每个 token 必过 → 承担 跨簇公共模式;
- Routed FFN:走 $s_{i,t}=u_t^\top e_i$ → 承担 簇内特化。
这是 「公共底座 + 按簇特化」,比「$N$ 个 gate 加权 expert」更好讲清 shared isolation 动机。
3.3 与 device-limited routing 一致
V2 先按 device 上 expert 组的 affinity 总和 选 $M$ 台机器,再在子集里 Top-$K$。
把 $e_i$ 看成空间中的点,天然支持 「先选区域(device),再选簇内 expert」;纯 gate 矩阵也能算,但缺少几何解释。
4. 对后续建模的影响
4.1 V2:affinity 驱动训练侧均衡
- Expert / device / comm 三级 aux loss 监控的是 被路由到的 token 流,affinity 决定谁被选中;
- Token dropping:丢弃 affinity 最低的 token-expert 对 — 显式假设「低亲和 = 可牺牲的边缘匹配」;
- 若只有匿名 gate,很难区分「调度分数」与「语义匹配质量」。
4.2 V3 aux-loss-free:拆选择 vs 门控
V3 保留 affinity $s_{i,t}$(改为 sigmoid 系),但:
| 用途 | V3 用法 |
|---|---|
| Top-$K$ 排序 | $s_{i,t} + b_i$($b_i$ batch 级启发式更新) |
| 乘 FFN 输出 | 仍用 原始 $s_{i,t}$ |
Centroid 叙事下的含义:
- $e_i$ / $s_{i,t}$:学 「token 是否属于 expert $i$ 的语义簇」(主 loss 反传);
- $b_i$:运维旋钮,只挪负载、不扭曲 gate 幅度 → 避免 aux loss 伤主任务。
若 early MoE 只有一个 gate 向量,把负载均衡和语义匹配绑在同一标量上,V3 这种 解耦 更难表述,也难调。
4.3 V3 $L_{\mathrm{Bal}}$:序列内 complement
$L_{\mathrm{Bal}}$ 在 单序列内 补 $f_i P_i$,与 $b_i$ 的 batch 级均衡互补 — 仍假设 expert 是可被 按亲和度分配 的特化单元,而不是纯随机 gate。
4.4 V4 Hash MoE:部分层离开 centroid 路由
V4 前几层改用 Hash 路由— 不再用 $u^\top e_i$ 做语义匹配,而是确定性 hash。
说明 centroid 路由是 DeepSeekMoE 稠密→稀疏 FFN 阶段的主线;到 V4 为效率/hash 另开一路,但 256/8 + shared + aux-loss-free 骨架仍继承 V2/V3 的 MoE 形态。
5. 对照表
| 维度 | 常见 gate-weight MoE | DeepSeekMoE(centroid) |
|---|---|---|
| Router 参数 | $W_g \in \mathbb{R}^{N \times d}$ | $e_i \in \mathbb{R}^d$(每 expert 一向量) |
| 打分 | $\mathrm{softmax}(W_g u)$ | $\mathrm{softmax}_i(u^\top e_i)$ |
| 语义 | 「学一个调度函数」 | 「token 匹配 expert 原型 / 簇」 |
| 与 FFN 关系 | gate 与 FFN 权重独立 | 同上;$e_i$ ≠ $\mathrm{FFN}_i$ 的 $W_1,W_2$ |
| 负载均衡 | aux loss 直接推 router | V2 aux;V3 $b_i$ 只动选择、不动 $g$ |
| 设计延伸 | — | fine-grained、shared isolation、device-limited |
6. 一句话
Gate-weight 把 MoE 路由说成「学一个 softmax 分类器」;centroid 把同一条算子说成「在 hidden 空间里做 expert 聚类匹配」。DeepSeek 选后者,是为了把 细粒度 expert、shared 分工、affinity 驱动的均衡、以及 V3 选择/门控解耦 串成一条可设计的叙事;算子层面仍可实现为 linear(u, E)。
参考
- DeepSeekMoE 架构
- aux-loss-free 路由
- DeepSeek-V2 arXiv:2405.04434 §2.2 Eq. 20–22
- DeepSeek-V3 arXiv:2412.19437 §2.1 Eq. 16–19
MoE 推理:Expert Parallel与 gather/scatter
← 返回 Hash MoE §1.3 · DeepSeekMoE §推理 infra · 答疑目录
一句话
Expert Parallel(EP) 把 routed experts 的权重 切到多张 GPU 上;前向时 token 经 dispatch(scatter) 送到持有对应 expert 的 rank,算完再 combine(gather) 回 batch 布局。DeepSeek V3 / V4 Hash MoE 共享这条 MoE 推理骨架——变的是 怎么选 expert id(centroid vs hash),不是 EP 通信模式本身。
1. EP 是什么
| 并行维 | 切什么 | MoE 里典型用途 |
|---|---|---|
| Tensor Parallel(TP) | 单层内矩阵 列切 + 行切(见下) | Attention / 大线性层 |
| Expert Parallel(EP) | 不同 expert 的 FFN 权重 分到不同 GPU | routed MoE 层 |
| Data Parallel(DP) | 复制整模型、切 batch | 通用训练 |
TP 补注 表里「按列/行切」指 Megatron 式 TP 在同一层里通常各用一次,不是「整张矩阵只切一种方向就结束」:
- 列切(column parallel):权重按 输出维 / 列 分片;每卡算 $Y_i = X W_i$,得到 输出通道分片(常接 AllGather 或留分片给下一步)。
- 行切(row parallel):权重按 输入维 / 行 分片;每卡算 部分和,需 AllReduce 合并成完整输出。
典型 FFN / 投影块:先列切、后行切(或 Attention 里 QKV 列切 + $O$ 投影行切),至少两次 TP matmul + 中间通信 才走完一层,且 列切那一次与行切那一次分工不同——不是对同一矩阵重复切两次。
DeepSeekMoE 每层有 256 routed + shared(V3 口径):shared 通常各 rank 都有或按 TP 复用;routed 池太大,单卡放不下 → 用 EP 按 expert id 分片。
2. 前向数据流:gather / scatter
对单个 MoE 层、单个 micro-batch,顺序为:路由得 expert id → dispatch(scatter) 把 token 发到持有该 expert 的 GPU → 各 rank 算本 rank expert 子集 → combine(gather) 加权收回原 batch 顺序。
Shared experts 不走稀疏 scatter:每层 恒激活,与 routed 输出 相加。
3. 为何与负载均衡绑在一起
EP 下 每张卡只服务一部分 expert。若路由 collapse(多数 token 涌向少数 expert):
- 热点 rank 打满,其它 rank 空转 → EP 效率 ≈ 最忙那张卡。
- 通信量也随 激活 expert 的 rank 分布 波动。
因此 V3 的 aux-loss-free / $L_{\mathrm{Bal}}$ 首要目标之一是 batch 级 expert 均衡——直接服务 EP 训练与推理吞吐。
4. Hash MoE 改什么、不改什么
| 维度 | V3 centroid 路由 | V4 Hash 层 |
|---|---|---|
| Expert id 怎么来 | $u^\top e_i$ + top-$K_r$ | 确定性 hash(无 router GEMM) |
| EP scatter/gather | ✅ 同族 | ✅ 仍走 routed gather-scatter |
| Shared 双路径 | ✅ | ✅ |
| 负载均衡手段 | $b_i$、$L_{\mathrm{Bal}}$ | hash 函数 静态近似均匀 + 深层仍可 centroid |
读法:Hash MoE 专文 换的是 浅层选 expert 的函数;一旦 id 确定,后面仍是 DeepSeekMoE 的 EP + shared 引擎路径,与 V3 推理栈同族。
5. V4 叠加:FP4 + EP
Hash MoE + FP4 在 EP 路径上多一层约束:
- Routed expert 权重 FP4 存 HBM;各 rank 的 expert 子集 4bit 读 + 高精度累加(引擎需 分 kernel)。
- Shared 路径通常仍用更高精度(与 V3 FP8 栈衔接)。
- EP 通信 payload 仍是 activation(hidden),不是 expert 权重;FP4 主要省 权重带宽与显存,不改变 scatter/gather 拓扑。
6. 与训练侧 DeepEP 的关系
V3 训练文档常并列 DualPipe、DeepEP、FP8:DeepEP 是 MoE token dispatch 的通信库,属于 训推系统层,不是 Transformer 权重结构。
| 层 | 内容 |
|---|---|
| 模型结构 | 256/8 routed、shared、路由公式 |
| EP / DeepEP | expert 分片 + token 怎么跨 rank 搬 |
| Hash MoE | 仅改 部分层 的 id 映射函数 |
7. 对照表
| 术语 | 含义 |
|---|---|
| EP | Expert Parallel;按 expert 切权重 |
| scatter / dispatch | token → 各 expert rank |
| gather / combine | expert 输出 → 回原 batch |
| DeepEP | DeepSeek 系 MoE 通信实现(训练/推理栈) |
| device-limited routing | V2 限制 token 只打本地 expert,减 EP 通信 |
参考
- DeepSeekMoE · aux-loss-free
- Hash MoE + FP4
- Megatron MoE:FlexDispatcher + DeepEP
Fine-grained Expert Segmentation:为何优于 GShard 式粗专家?
← 返回 DeepSeekMoE §优化逻辑 (b) · 答疑目录
来源:DeepSeekMoE 论文(Dai et al., arXiv:2401.06066)§3.1 · V2 技术报告 2405.04434 §2.2
1. 核心直觉:IsoFLOP 下换「组合空间」
Fine-grained 的操作:
- 每个标准 expert FFN 切成 $m$ 个小 expert;
- 中间维缩为 $1/m$;
- 每 token 激活数 $K \to mK$。
总参 / 激活 FLOPs 不变:
$$ K \times d_{\mathrm{ffn}} ;\approx; mK \times \frac{d_{\mathrm{ffn}}}{m} $$
因此优势 不是「多烧算力」,而是在 同等计算预算 下,把路由从「选 $K$ 个大块」换成「选 $mK$ 个小块」——组合数学上,可选方案数爆炸式增长(下文 §2)。

{kind=link}
2. 组合数学视角
2.1 路由 = 从专家池里选子集
MoE 对 token $t$ 的路由,本质是:在 $N$ 个 routed expert 中选 $K$ 个 组成激活集 $\mathcal{S}_t$,再加权求和:
$$ \sum_{i \in \mathcal{S}t} g{i,t},\mathrm{FFN}_i(u_t), \quad |\mathcal{S}_t| = K $$
若 不考虑 gate 权重、只计「选哪几个 expert」,不同激活集的个数为:
$$ \boxed{;#\text{组合} = \binom{N}{K};} $$
这就是 fine-grained 相对 GShard 的 第一性优势:$N$ 变大、$K$ 同比放大时,$\binom{N}{K}$ 超指数增长——模型在 相同 FLOPs 下能表达 vastly more 种「专家配方」。
2.2 论文数值例
DeepSeekMoE 原文给出对照(见下图):

{kind=link}
| 设定 | 专家池 $N$ | 每 token 激活 $K$ | 组合数 $\binom{N}{K}$ |
|---|---|---|---|
| 标准(粗)MoE | 16 | 2 | $\binom{16}{2} = \mathbf{120}$ |
| Fine-grained(每个 expert 切 4 份) | 64 | 8 | $\binom{64}{8} = \mathbf{4{,}426{,}165{,}368}$ |
倍数:$\dfrac{\binom{64}{8}}{\binom{16}{2}} \approx 3.7 \times 10^{7}$ —— 约 3700 万倍 的离散路由方案。
切分参数:$N' = mN = 4 \times 16 = 64$,$K' = mK = 4 \times 2 = 8$,与 §1 的 IsoFLOP 约定一致($m=4$)。
2.3 通式:为何 $m$ 一放大,组合数就「炸」?
记粗粒度 $\binom{N}{K}$,细粒度 $\binom{mN}{mK}$。固定 $N,K$,增大 $m$:
$$ \frac{\binom{mN}{mK}}{\binom{N}{K}} = \prod_{j=0}^{K-1} \frac{mN - j}{N - j} ;\xrightarrow{m\to\infty}; m^{K} \quad\text{(首阶)} $$
直觉:
- 粗 MoE:$K=2$ 时只有 $\binom{N}{2} \sim O(N^2)$ 种「双专家配方」;
- 细 MoE:$mK$ 个 slot 从 $mN$ 个 specialist 里挑,组合数随 $mN$ 与 $mK$ 同时升高,增长远快于 $m^K$ 的多项式级。
论文结论:This combinatorial flexibility allows for more accurate and targeted knowledge acquisition.
2.4 组合多 → 训练为何更好?
| 组合视角 | 对训练的含义 |
|---|---|
| 120 种配方 | Router 只能在 少数粗粒度混合 间选择;每种配方对应 大 FFN 内部折中 |
| $4.4\times 10^9$ 种配方 | Router 可为不同 token 细调 specialist 子集;每种配方 = 多个窄 FFN 的特化组合 |
| 同 FLOPs | 不是「算更多次」,而是 同一次 forward 里,从更大离散菜单点菜 |
| 与 gate 权重联立 | Top-$mK$ 先定 支持集,$g_{i,t}$ 再定 配比 → 连续 × 离散 的表达力都上去 |
类比:粗 MoE 像 120 种固定套餐;fine-grained 像 40 亿种自选小份拼盘——总卡路里(FLOPs)一样,但可针对每个 token 更精准地配知识。
2.5 与 V2 产品配置的尺度感
论文玩具数是 $N=16 \to 64$;V2 部署进一步放大 routed 池:
| 版本 | routed 数 $N_r$ | 每 token 激活 $K_r$ | $\binom{N_r}{K_r}$(量级) |
|---|---|---|---|
| 论文例 | 64 | 8 | $\sim 4.4 \times 10^9$ |
| DeepSeek-V2 | 160 | 6 | $\binom{160}{6} \approx 2.0 \times 10^{11}$ |
| DeepSeek-V3 | 256 | 8 | $\binom{256}{8} \approx 5.6 \times 10^{14}$ |
V2/V3 在 IsoFLOP 路由槽位 下,组合空间比论文 $64/8$ 例再大 $10^2$–$10^5$ 量级——这也是细粒度必须配 centroid / device-limited / 均衡 的原因:池子越大,「点菜菜单」越大,越需要稳定路由(见 §5)。
3. GShard 式粗 expert 的特化问题
组合空间小 且 单 expert 太大时,还会出现 知识重叠:
| 现象 | 后果 |
|---|---|
| 单个 expert 很大 | 路由到它的 token 类型杂 |
| 一个 FFN 同时拟合多种知识 | 参数在 冲突梯度 间拉扯 |
| $\binom{N}{K}$ 本身很小 | 即使 router 想细分,离散菜单不够 |
Fine-grained 同时解决两件事:
- 组合数 $\binom{N}{K} \to \binom{mN}{mK}$(§2);
- 单 expert 宽度 $d_{\mathrm{ffn}} \to d_{\mathrm{ffn}}/m$,每个 specialist 更窄、更专。
4. 与 shared expert、Figure 2 的衔接
| 机制 | 作用 |
|---|---|
| Fine-grained routed | 扩大 $\binom{mN}{mK}$,特化组合 |
| Shared isolation | 通用知识 不占用 routed 组合槽位 |
| Centroid affinity | 在巨大组合空间中 按簇 选 expert,避免随机乱配 |
Figure 2 (b) 对应:$m=2$ 时 $N \to 2N$,Top-$K$ $\to$ Top-$2K$,中间维减半;组合数 $\binom{N}{K} \to \binom{2N}{2K}$,同样 远大于 原 $\binom{N}{K}$。
5. 训练配套
$\binom{mN}{mK}$ 极大时,若 router collapse 到少数 expert,组合优势浪费。DeepSeek 配套:
| 机制 | 作用 |
|---|---|
| Centroid + Top-$K$ | 按簇选 specialist |
| V2 device-limited routing | 控 EP 通信 |
| V2 aux loss / V3 aux-loss-free | 防负载塌缩 |
论文实证(2401.06066):DeepSeekMoE 2B 可达 GShard 2.9B 水平,后者 expert 参数量与计算约 1.5×——说明 组合 + 特化 在同等预算下能换更好效果。
6. 一句话
Fine-grained 在 IsoFLOP 下把 $\binom{N}{K}$ 换成 $\binom{mN}{mK}$,让 router 对每个 token 能从 ** vastly larger 的 specialist 子集菜单** 里精确配知识;再配合更窄的单 expert 与 shared/路由设计,同等算力下训练效果更好。DeepSeek MoE 线(V2→V3→V4)均建立在这一组合数学优势之上。
参考
- DeepSeekMoE 架构
- centroid vs gate-weight
- Dai et al. DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models. arXiv:2401.06066
- DeepSeek-V2 arXiv:2405.04434 §2.2
Hash MoE 为何只改浅层、深层仍用 centroid 路由?
← 返回 Hash MoE §1.2 · EP 答疑 §4 · centroid vs gate-weight §4.4 · 答疑目录
一句话
Hash 路由用确定性函数换 零 router GEMM + 静态负载;适合 浅层偏通用、对语义特化要求低 的 FFN。深层仍要 按 token 语义选 expert($u^\top e_i$ + aux-loss-free),才能保留 V3 系 细粒度 specialization 与 动态均衡——全栈 Hash 省算力更多,但 表达能力与 EP 负载风险 都不划算,所以 V4 选 浅 Hash + 深 centroid 的混合栈。
1. 两种路由各自擅长什么
| 维度 | Hash(浅层) | Centroid / aux-loss-free(深层) |
|---|---|---|
| Expert id | token / 位置 hash → 近似均匀 | $u^\top e_i$ 语义亲和度 + top-$K_r$ |
| Router 算力 | 无 对 256 expert 的打分 GEMM | 每层每 token 一次 routed 打分 |
| 负载均衡 | hash 设计 静态近似均匀 | 动态 bias $b_i$ + $L_{\mathrm{Bal}}$ |
| 特化能力 | 弱 — id 与「内容类型」解耦 | 强 — expert 向量 $e_i$ 学「原型 / 簇」 |
| 典型层位 | 前几层 MoE / 原 dense FFN | 中深层 主力 MoE 层 |
2. 为何浅层可以 Hash
2.1 浅层 FFN 更偏「通用变换」
靠近 embedding 的 FFN 多在 升维 / 非线性 / 局部混合,尚未形成强 任务 / 领域 分化。此时用 hash 把 token 伪随机但均匀 摊到 expert 上,等价于 加宽 FFN 容量,对 语义匹配 依赖较小。
2.2 省下来的主要是 router 与参数
V3 每层 MoE 要对 全体 routed expert 算亲和度(256 维量级),再 top-8。浅层 层数少但 token 吞吐相同,若前几层原是 dense FFN 或 MoE,改成 Hash MoE 可以:
- 去掉 $e_i$、router GEMM 与部分 aux 路径;
- 仍走 EP + shared,id 确定后引擎与 V3 同族。
动机表里写的 「省路由算力与参数;浅层更偏通用变换」 即此。
2.3 静态 hash 够用的前提
Hash 层 不随 batch 调 $b_i$。浅层 expert 负载若天然较匀、且 不承担精细语义分工,静态 hash 的 近似均匀 通常够用;这也是只放浅层的 前提条件。
3. 为何深层不动
3.1 深层需要「按内容选 expert」
越靠后,hidden 越 抽象、任务相关。DeepSeekMoE 的 centroid 叙事是:token 与 expert 原型 $e_i$ 匹配(centroid 答疑)。数学 / 代码 / 多语言等 分化 主要在 中深层 MoE 体现;改成 hash 等于 强行去掉内容条件路由,特化能力损失大。
3.2 动态均衡在深层更关键
深层 MoE 激活参数占比高,EP 下 热点 expert 代价更大(EP 答疑 §3)。V3 的 $b_i$ + $L_{\mathrm{Bal}}$ 针对 batch / 序列内 动态调节;hash 无法 在「某 expert 突然过热」时微调路由,全深层 hash 会让 EP 空转风险 上升。
3.3 训练与迁移:深层沿用 V3 族更稳
V4 继承 DeepSeekMoE 256/8 + shared 与 sigmoid + bias 路由(aux-loss-free)。深层不动 → 大部分 MoE 层 权重形态、训推 kernel、EP 路径与 V3 同族,只在前几层插入 Hash 块;若 全栈 Hash,router 权重与 checkpoint 语义 全面重写,风险与验证成本都高。
3.4 收益递减
Hash 省的是 router 侧 FLOPs 与参数;深层 FFN expert 本体 仍是算力大头。把 Hash 推到全层,额外省的 router 占比变小,但 质量与均衡风险 单调变差 → 混合栈 是 Pareto 折中。
4. 混合栈长什么样

Hash 仅替换浅层 Phase A→B 的路由函数;Phase C(EP scatter → Routed FFN → Gather+shared)与 V3 推理栈不变。
{kind=link}
| 段 | 路由 | 后面引擎 |
|---|---|---|
| 浅层 | Hash MoE — 确定性 id,无 centroid GEMM | hidden 初步混合后进入深层 |
| 深层 | V3 族 MoE — $u^\top e_i$ + top-$K_r$ + shared + $b_i$ 均衡 | 仍走 EP scatter → expert FFN → gather + shared |
- 改的是「浅层选 expert 的函数」;id 一旦确定,后面仍是 EP scatter → expert FFN → gather + shared。
- FP4 作用在 routed expert 权重 上,与 Hash vs centroid 正交(Hash MoE 专文 §2),深层 routed 也可 FP4,router 逻辑仍 centroid。
5. 常见误解
| 误解 | 澄清 |
|---|---|
| 「V4 全部 MoE 都 Hash」 | 否 — 仅 前几层 |
| 「深层不用 MoE」 | 否 — 主力层仍是 256/8 DeepSeekMoE + centroid |
| 「Hash 层不做 EP」 | 否 — 仍 gather/scatter,只改 id 怎么来 |
| 「浅层 Hash = 质量一定差」 | 设计假设是浅层 特化需求低;深层保留 learned routing 兜底能力 |
6. 与论文口径
V4 2606.19348 将 Hash MoE 与 FP4 MoE 作为 MoE 线改动与 CSA/HCA 等 同期打包;公开材料对 具体层号 着墨有限,本地文档以 「前几层 / 浅层 vs 深层 centroid」 表述,细节以论文与权重 config 为准。
参考
名词解释:Birkhoff 多面体
← 返回 mHC §3.2 · §3 双随机流形 · HC 基础 · 答疑目录
一句话
Birkhoff 多面体 $\mathcal{B}_n$ = 所有 $n \times n$ 双随机矩阵 的集合 = $n$ 阶 置换矩阵 的 凸包;mHC 把 HC 混合矩阵投影到 $\mathcal{B}_n$,使多路残差流混合为 凸组合。
1. 双随机矩阵
$H \in \mathbb{R}^{n \times n}$ 若满足:
$$ H_{ij} \ge 0;\quad \sum_j H_{ij}=1;\forall i;\quad \sum_i H_{ij}=1;\forall j $$
则称 $H$ 为 双随机矩阵(doubly stochastic):每行、每列都是 非负且和为 1 的概率分布。
2. Birkhoff 多面体 = 置换矩阵的凸包
记 $\mathcal{B}_n$ 为 全体 $n \times n$ 双随机矩阵的集合,则(Birkhoff–von Neumann 定理):
$$ \mathcal{B}n = \mathrm{conv},{, P\pi \mid \pi \in S_n ,} $$
| 概念 | 含义 |
|---|---|
| 置换矩阵 $P_\pi$ | 每行、每列 恰有一个 1,其余为 0(对应排列 $\pi$) |
| 凸包 $\mathrm{conv}{\cdots}$ | 允许对顶点做 非负权重加权平均,权重和为 1 |
| Birkhoff 多面体 | 双随机矩阵在 $\mathbb{R}^{n \times n}$ 中形成的 凸多面体(有界、闭、凸) |
直觉:任意双随机矩阵都可以写成「若干个置换矩阵的加权平均」;极端点(顶点)就是置换矩阵本身。
$n{=}2$ 小例:$H=\begin{pmatrix}0.7&0.3\0.4&0.6\end{pmatrix}$ 可视为两个置换矩阵(恒等与交换)的凸组合。
3. 为何 mHC 论文叫它「流形」
| 说法 | 含义 |
|---|---|
| 严格几何 | $\mathcal{B}_n$ 是 多面体(polytope),维数 $n^2-n$ |
| 论文 / 工程口语 | 训练时在 $\mathbb{R}^{n^2}$ 上优化 logits,前向用 Sinkhorn 把矩阵 约束回 $\mathcal{B}_n$ → 称 Manifold-Constrained、双随机流形 |
与 mHC §3.4 的 Sinkhorn–Knopp 投影配合:无约束 $\tilde{H}$ → 逼近 $H \in \mathcal{B}_n$。
4. 对残差混合的含义
把 $n$ 条残差流堆叠为 $X$,混合 $H \in \mathcal{B}_n$ 后第 $i$ 行:
$$ (X')i = \sum{j=1}^{n} H_{ij} X_j, \quad H_{ij}\ge 0,; \sum_j H_{ij}=1 $$
即 $(X')_i$ 是各条流的 凸组合 → 单层不放大 最大流范数。
5. 易混名词
| 名词 | 领域 | 与 Birkhoff 多面体 |
|---|---|---|
| SWA | 优化 / 训练 | Stochastic Weight Averaging;与 Birkhoff 无关 |
| SWA(V4) | Attention | SWA(Sliding Window Attention) |
| 单纯形 | 概率 | 行随机矩阵集合;双随机 = 行 + 列 都随机,更严 |
| 置换矩阵 | 线性代数 | $\mathcal{B}_n$ 的 顶点,不是全体 |
6. 相关阅读
| 文档 | 内容 |
|---|---|
| mHC§3 | 双随机定义 · Sinkhorn · 与 HC 对照 |
| Hyper-Connections | 无约束 HC 为何不 stable |
MoE 推理:Expert Parallel与 gather/scatter
← 返回 Hash MoE §1.3 · DeepSeekMoE §推理 infra · 答疑目录
一句话
Expert Parallel(EP) 把 routed experts 的权重 切到多张 GPU 上;前向时 token 经 dispatch(scatter) 送到持有对应 expert 的 rank,算完再 combine(gather) 回 batch 布局。DeepSeek V3 / V4 Hash MoE 共享这条 MoE 推理骨架——变的是 怎么选 expert id(centroid vs hash),不是 EP 通信模式本身。
1. EP 是什么
| 并行维 | 切什么 | MoE 里典型用途 |
|---|---|---|
| Tensor Parallel(TP) | 单层内矩阵 列切 + 行切(见下) | Attention / 大线性层 |
| Expert Parallel(EP) | 不同 expert 的 FFN 权重 分到不同 GPU | routed MoE 层 |
| Data Parallel(DP) | 复制整模型、切 batch | 通用训练 |
TP 补注 表里「按列/行切」指 Megatron 式 TP 在同一层里通常各用一次,不是「整张矩阵只切一种方向就结束」:
- 列切(column parallel):权重按 输出维 / 列 分片;每卡算 $Y_i = X W_i$,得到 输出通道分片(常接 AllGather 或留分片给下一步)。
- 行切(row parallel):权重按 输入维 / 行 分片;每卡算 部分和,需 AllReduce 合并成完整输出。
典型 FFN / 投影块:先列切、后行切(或 Attention 里 QKV 列切 + $O$ 投影行切),至少两次 TP matmul + 中间通信 才走完一层,且 列切那一次与行切那一次分工不同——不是对同一矩阵重复切两次。
DeepSeekMoE 每层有 256 routed + shared(V3 口径):shared 通常各 rank 都有或按 TP 复用;routed 池太大,单卡放不下 → 用 EP 按 expert id 分片。
2. 前向数据流:gather / scatter
对单个 MoE 层、单个 micro-batch,顺序为:路由得 expert id → dispatch(scatter) 把 token 发到持有该 expert 的 GPU → 各 rank 算本 rank expert 子集 → combine(gather) 加权收回原 batch 顺序。
Shared experts 不走稀疏 scatter:每层 恒激活,与 routed 输出 相加。
3. 为何与负载均衡绑在一起
EP 下 每张卡只服务一部分 expert。若路由 collapse(多数 token 涌向少数 expert):
- 热点 rank 打满,其它 rank 空转 → EP 效率 ≈ 最忙那张卡。
- 通信量也随 激活 expert 的 rank 分布 波动。
因此 V3 的 aux-loss-free / $L_{\mathrm{Bal}}$ 首要目标之一是 batch 级 expert 均衡——直接服务 EP 训练与推理吞吐。
4. Hash MoE 改什么、不改什么
| 维度 | V3 centroid 路由 | V4 Hash 层 |
|---|---|---|
| Expert id 怎么来 | $u^\top e_i$ + top-$K_r$ | 确定性 hash(无 router GEMM) |
| EP scatter/gather | ✅ 同族 | ✅ 仍走 routed gather-scatter |
| Shared 双路径 | ✅ | ✅ |
| 负载均衡手段 | $b_i$、$L_{\mathrm{Bal}}$ | hash 函数 静态近似均匀 + 深层仍可 centroid |
读法:Hash MoE 专文 换的是 浅层选 expert 的函数;一旦 id 确定,后面仍是 DeepSeekMoE 的 EP + shared 引擎路径,与 V3 推理栈同族。
5. V4 叠加:FP4 + EP
Hash MoE + FP4 在 EP 路径上多一层约束:
- Routed expert 权重 FP4 存 HBM;各 rank 的 expert 子集 4bit 读 + 高精度累加(引擎需 分 kernel)。
- Shared 路径通常仍用更高精度(与 V3 FP8 栈衔接)。
- EP 通信 payload 仍是 activation(hidden),不是 expert 权重;FP4 主要省 权重带宽与显存,不改变 scatter/gather 拓扑。
6. 与训练侧 DeepEP 的关系
V3 训练文档常并列 DualPipe、DeepEP、FP8:DeepEP 是 MoE token dispatch 的通信库,属于 训推系统层,不是 Transformer 权重结构。
| 层 | 内容 |
|---|---|
| 模型结构 | 256/8 routed、shared、路由公式 |
| EP / DeepEP | expert 分片 + token 怎么跨 rank 搬 |
| Hash MoE | 仅改 部分层 的 id 映射函数 |
7. 对照表
| 术语 | 含义 |
|---|---|
| EP | Expert Parallel;按 expert 切权重 |
| scatter / dispatch | token → 各 expert rank |
| gather / combine | expert 输出 → 回原 batch |
| DeepEP | DeepSeek 系 MoE 通信实现(训练/推理栈) |
| device-limited routing | V2 限制 token 只打本地 expert,减 EP 通信 |
参考
- DeepSeekMoE · aux-loss-free
- Hash MoE + FP4
- Megatron MoE:FlexDispatcher + DeepEP
为何 DeepSeek 用 $C=M\cdot D$ 而非 $C=6ND$?
← 返回演进总览 §3.1 V1 · ← V1 §3 Scaling Laws · 答疑目录
来源:DeepSeek-LLM arXiv:2401.02954 §3.2 · Table 3 / Formula 2–4
1. 一句话
不是把 Chinchilla 的 $6$ 随便改掉,而是:$6N$ 只是「每 token 算力」的粗近似;DeepSeek 改用实测的 $M$(non-embedding FLOPs/token),于是总算力按定义写成 $C=M\cdot D$——IsoFLOP 拟合(Figure 4a)才准。
2. 传统写法:$C \approx 6ND$
Kaplan / Chinchilla 系 scaling law 里,训练总算力常写成:
$$ C \approx 6ND $$
| 符号 | 含义 |
|---|---|
| $N$ | 模型规模(参数量,有两种取法,见下) |
| $D$ | 训练 token 数 |
| 6 | 一次 forward + backward 相对 forward 的 FLOPs 倍数($\approx 1+2=3$ 再乘 matmul 计数约定) |
$N$ 的两种常见定义:
| 符号 | 定义 | 文献 |
|---|---|---|
| $N_1$ | non-embedding 参数量 | Kaplan et al. |
| $N_2$ | 含 embedding / lm_head 的全参 | Hoffmann et al.(Chinchilla) |
于是「每 token 算力」可粗写为 $6N_1$ 或 $6N_2$,再乘 $D$ 得 $C$。
3. $6N$ 哪里不准?
V1 论文指出:$6N_1$ 与 $6N_2$ 都不是真实的 per-token FLOPs,误差在小模型上尤其大:
| 近似 | 问题 |
|---|---|
| $6N_1$ | 只数 FFN/线性层 matmul,不含 attention 的 $O(L^2)$ 项 → 低估算力 |
| $6N_2$ | 在 $6N_1$ 基础上 加上 $6,n_{\mathrm{vocab}},d$(vocab 投影)→ 对能力贡献小却 高估算力;仍 不含 attention |
DeepSeek 给出三者闭式(Formula 2,$l_{\mathrm{seq}}$ = 序列长度):
$$ \begin{aligned} 6N_1 &= 72 \cdot n_{\mathrm{layer}} \cdot d_{\mathrm{model}}^2 \ 6N_2 &= 72 \cdot n_{\mathrm{layer}} \cdot d_{\mathrm{model}}^2 + 6 \cdot n_{\mathrm{vocab}} \cdot d_{\mathrm{model}} \ M &= 72 \cdot n_{\mathrm{layer}} \cdot d_{\mathrm{model}}^2 + 12 \cdot n_{\mathrm{layer}} \cdot d_{\mathrm{model}} \cdot l_{\mathrm{seq}} \end{aligned} $$
$M$ = non-embedding FLOPs/token:计 attention,不计 vocab 投影——作为「模型有多重、每 token 算多狠」的度量。
4. Table 3:小模型上误差可达 50%

{kind=link}
| $n_{\mathrm{layer}}$ | $d_{\mathrm{model}}$ | $6N_1/M$ | $6N_2/M$ |
|---|---|---|---|
| 12 | 768 | 0.43 | 1.32 |
| 24 | 1024 | 0.69 | 1.14 |
| 32 | 4096 | 0.97 | 1.01 |
- $6N_1/M < 1$(12 层仅 0.43):缺 attention → 严重低估 $M$
- $6N_2/M > 1$(12 层 1.32):多计 vocab → 高估 $M$
- 模型变大后趋近 1,但 IsoFLOP 扫小模型时若仍用 $6N$,会把「同一 $C$ 下的不同 $(M,D)$ 分配」搞错 → U 形曲线(Figure 4a)拟合被污染
因此 Formula 4 / IsoFLOP 统一用 $M$,不用 $6N_1$/$6N_2$。
5. 改成 $C = M \cdot D$ 在算什么?
这是 定义,不是新物理定律:
$$ \boxed{C = M \cdot D} $$
| 量 | 含义 |
|---|---|
| $M$ | 每个训练 token 的 non-embedding forward FLOPs(含 attention,不含 embedding 矩阵乘) |
| $D$ | 训练 token 总数 |
| $C$ | 总训练算力(FLOPs) |
与 $6ND$ 的关系:若你坚持用参数量 $N$,只能选 $N_1$ 或 $N_2$,再乘 6 去 近似 $M$;DeepSeek 选择 直接测 $M$,避免 $N_1$/$N_2$ 双轨与 attention 缺失。
训练时仍用 3× forward 做 backward——变的只是 用什么标度刻画「模型规模」:从 参数个数 $N$ 换成 每 token 实际 FLOPs $M$。
6. 和 Figure 4a / IsoFLOP 的关系
IsoFLOP 实验:固定总算力 $C$,扫约 10 种 $(M,D)$ 满足 $M\cdot D=C$,找 validation loss 谷底。
- 横轴必须是 真实的 $M$(FLOPs/token),不能是 $6N_1$ 或 $6N_2$
- 若用 $6N$ 当横轴,小模型点会 系统性偏移,谷底位置错 → $M_{\mathrm{opt}}(C)$、$D_{\mathrm{opt}}(C)$(Formula 4)不可信
Figure 4a 的 U 形曲线因此建立在 $C=M\cdot D$ 之上;演进总览 §3.1 所贴即此图。
7. 和数据质量结论的关系
论文在 Formula 4 成立(即用 $M$) 之后还发现:不同语料拟合的 $M_{\mathrm{opt}}\propto C^a$、$D_{\mathrm{opt}}\propto C^b$ 指数 $a,b$ 不同——数据质量越高,$a$ 越大 → 更该扩模型而非堆数据。
这是 第二层结论,依赖第一层「用 $M$ 而不是 $6N$ 把 $C$ 算准」。
8. 常见误解
| 误解 | 正解 |
|---|---|
| DeepSeek 否定了 Chinchilla | 仍做 IsoFLOP;改的是 模型规模的度量($M$ vs $6N$) |
| $C=MD$ 意味着 7B/67B 必须同 $D$ | $C=M\cdot D$ 是乘法 定义;产品统一 2T 是 工程选择,见 Scaling-Law 选择性应用 |
| 6 这个常数错了 | 6 来自 fwd+bwd 计数;问题在于 $N$ 不能代表 per-token FLOPs(缺 attention / 多 vocab) |
9. 延伸阅读
| 文档 | 内容 |
|---|---|
| V1 §3.2 最优 model/data Scaling | Formula 2–4 原文与 Figure 4 |
| Scaling 答疑 | $M$ 推导、Formula 1/4 数值、4B 实战 |
| Scaling-Law 选择性应用 | Figure 3/4/5 分工;2T 产品 vs IsoFLOP 谷底 |
| 产品训练与 Scaling Law | 7B/67B 同训 2T 与 compute-optimal 的区别 |
V4 里的 Indexer KV 是什么?
← 返回 CSA/HCA 一句话 · §4 异构 KV · KV Layout §State · Lightning Indexer 详解 · DSA 梗概 · 答疑目录
一句话
Indexer KV 是 V4 CSA 稀疏路径上、沿 V3.2 Lightning Indexer 一脉的 轻量 K 向量 cache:当前 $q_t$ 对 全长历史 每条 $k_s$ 廉价打分 → top-$k$ 选出要读的 C4 压缩 entry;维数、池子、是否 offload 均与 主 MLA / HCA entry 不同。
1. 在 decode 一步做什么
| 步 | 对象 | 动作 |
|---|---|---|
| 1 | 当前 hidden $h_t$ | 现算 indexer query $q_t$ |
| 2 | Indexer KV 第 $s$ 行 $k_s$ | 对 每个历史位置 $s$ 打分 $I_{t,s}$ |
| 3 | Top-$k$ | 得到下标集 $I$ |
| 4 | Classical 池 C4 entry | Core attention 只读 $I$ 内压缩块 |
方向始终是 $q_t \to k_s$(当前选历史),不是每个历史 token 各自 top-$k$。机制细节见 Lightning Indexer §1。
2. 为何单独一类 cache
| 对比 | Indexer KV | CSA C4 entry | HCA entry |
|---|---|---|---|
| 目的 | 选位置 | 被选的远距稀疏 K/V | 全局 dense 摘要 |
| 典型维度 | 窄(indexer 专用) | 压缩后主 attention | 更重压缩 |
| 读模式 | 全长扫 打分 | 仅 $I$ 内 稀疏读 | 短序列 dense |
| V3.2 对应 | Indexer-Cache | Latent-Cache | — |
V4 把 indexer 与 C4/HCA 分开记账,引擎才能 分池 eviction、分类型 prefix(KV layout)。
3. 与 ESS / offload 的关系
| 项 | 说明 |
|---|---|
| Indexer | V3.2 ESS:一般不 offload(GPU 常驻,先算 index 再决定搬哪些 latent) |
| V4 | Indexer KV 仍偏 热路径;inactive C4 的 HiSparse offload 不替代 indexer 打分(V3.2 链路描述;V4 对象名不同、分工类似) |
4. 相对纯 DSA 的延续
算法线:MLA → DSA(indexer + top-$k$)→ CSA(压缩序列上再稀疏)。Indexer 不是 V4 新发明,而是 CSA 在 更短 entry 序列 上仍需要 「看谁」 的阶段;HCA 路径则走 dense attend 压缩摘要,不共用同一套 indexer 读法。
5. 相关阅读
| 文档 | 内容 |
|---|---|
| Lightning Indexer 详解 | $q_t$ 对 $k_s$ 打分、$O(L^2)$ 常数极小 |
| DSA 稀疏注意力 | DSA 流水线总览 |
| CSA / HCA | CSA 4:1 块 + indexer 在 V4 栈中的位置 |
V4 为何要分池?块对齐与尾缓冲怎么配合?
← 返回 KV Layout §为何单一 layout 不够 · Classical 池 · State 池 · Tail buffer · SWA · 答疑目录
一句话
V4 同时有 两种块长(CSA $m{=}4$、HCA $m'{=}128$)和 两种生命周期(已压缩定型 vs 仍在滑动/凑块);Classical 池 只放 凑满且不可变 的压缩 entry,State 池 放 尾缓冲 + SWA 等 每步都在变 的状态——混在一个池里会同时破坏 $\mathrm{lcm}$ 块对齐、prefix 共享、HiSparse offload。
1. 为什么要分池管理
1.1 不是「多几种 KV」那么简单,是 读写语义不同
| Classical KV cache | State cache | |
|---|---|---|
| 存什么 | 已凑满的 CSA C4 / HCA 压缩 entry | Tail(未凑满块)+ SWA(滑动窗口精确 K/V)+ 可能含 Indexer |
| 是否可变 | 写入后 不可变(immutable) | 每 decode 步 都可能变(tail 变长/清空,SWA 滑动) |
| 能否 prefix 共享 | 能 — 同一压缩块多请求只存一份 | 难 — 随各请求当前长度 / 窗口不同 |
| 能否落盘 / offload | CSA/HCA 块 优先(紧凑、不变) | 通常 跟请求走;SWA 还有三档策略(磁盘 prefix) |
| 分配粒度 | 按 压缩 entry append | 每请求固定 state block(batch 内对齐) |
V3/V3.2 可以「一层一条同质 latent 流」——shape 一样、生命周期一样。V4 把 远距压缩历史 与 局部未压缩 / 未定型 混在同一抽象里,引擎就无法用 同一套 eviction、同一套 prefix 哈希、同一套 DMA 粒度 管理。
1.2 压缩比 $m \neq m'$ 放大了这个问题
- CSA:每 4 token → 1 条 C4 entry(远距 稀疏 top-$k$ 读)
- HCA:每 128 token → 1 条 HCA entry(全局 dense 读)
二者 entry 密度差 32 倍,读模式也不同。若强行共池:
- 块边界对不齐 — 同一 token 区间在 CSA 是 32 条 entry、在 HCA 是 1 条,物理槽位无法统一编号;
- 尾部长度不同 — CSA tail 最多 3 token,HCA tail 最多 127 token,与 SWA 窗口 叠加 后 State 侧体积不可预测;
- eviction 策略冲突 — HiSparse 想 offload inactive C4;SWA 却要 热窗口常驻 — 必须在池级分开。
所以表里写:$m{=}4$、$m'{=}128$ 不同 → 块对齐、尾缓冲、SWA 窗口必须分池管理。
2. 块对齐:$\mathrm{lcm}=128$ 是啥逻辑
2.1 压缩器的硬约束
块压缩不是「任意截断」,而是:
$$ \text{连续 } m \text{ 个 token 的 K/V} ;\xrightarrow{;\text{compress};}; 1 \text{ 条 entry} $$
- CSA:$m=4$
- HCA:$m'=128$
引擎要为 已完成的块 在 Classical 池里分配 连续、可索引 的槽位。若物理分配粒度只按 4 对齐,HCA 每 128 token 才一条,中间会产生 跨槽碎片;若只按 128 对齐,CSA 每 4 token 一条又无法在子块内寻址。
2.2 用 lcm 统一「大块」边界
取
$$ \mathrm{lcm}(m,m') = \mathrm{lcm}(4,128) = 128 $$
含义:每 128 个 token 构成一个 对齐超级块,在这个边界上:
| 在这 128 token 内 | CSA | HCA |
|---|---|---|
| 满块 entry 数 | $128/4 = 32$ 条 C4 | $128/128 = 1$ 条 HCA |
| 边界 | 32 条 C4 刚好填满 | 1 条 HCA 刚好填满 |
任意 已完成 的历史长度 $L$ 可写成:
$$ L = 128 \cdot q + r,\quad 0 \le r < 128 $$
- $128q$ token → Classical 池里有 $32q$ 条 C4 + $q$ 条 HCA(一一对应同一批 token 区间)
- 剩余 $r$ token → 进 tail,不进 Classical(见下节)
这样 prefix 共享、落盘、HiSparse 按 entry 搬移 时,CSA 与 HCA 的「第 $k$ 个 128-token 段」语义一致,不会出现半块只压了一边的情况。
2.3 小例子:$L=130$ token
| 区间 | Classical 池 | State 池 |
|---|---|---|
| token $1\ldots128$ | 32×C4 + 1×HCA(已满) | — |
| token $129\ldots130$ | 不写(未满 4 也未满 128 的 公共尾) | Tail 2 token + SWA 窗口(含最近 128,与上表重叠由 kernel 定义) |
若把 129–130 强行写入 Classical,要么 伪造半条 HCA(算法不允许),要么 破坏 C4 四元组完整性。
3. 尾缓冲的逻辑
3.1 流式 decode:来一 token,不能立刻压块
Prefill / decode 逐个 append token 时,序列长度 $L$ 任意时刻 不一定 被 4 或 128 整除。
Tail buffer = 当前 还凑不成一整块 的 K/V 暂存区:
| 路径 | 何时「满块」 | Tail 最多多长 |
|---|---|---|
| CSA | $L \bmod 4 = 0$ | 3 token |
| HCA | $L \bmod 128 = 0$ | 127 token |
满块时:压缩 → 一条 entry append 到 Classical 池 → tail 中对应 token 清空或前移。
3.2 为何 tail 必须在 State 池
| 若在 Classical | 若在 State(实际) |
|---|---|
| entry 未定型却要占位 → 无法 immutable 共享 | 明确标记为 进行中 |
| prefix 命中时要拷贝 半块垃圾 | 命中后只需 重算 / 补 tail + SWA |
| offload 无法判断 是否完整块 | Classical 里 全是满块,HiSparse 可安全搬 inactive C4 |
Tail 是 块对齐的工程缓冲,不是新 attention 类型(详见 tail buffer 答疑)。
3.3 与 SWA 同池、不同职责
二者都在 State 池,但:
| Tail | SWA | |
|---|---|---|
| 目的 | 等凑满 压缩块 | 保留 局部精度 |
| 变化方式 | 长度 $0\ldots m{-}1$ 阶跃 | 窗口 滑动 |
| 与 Classical 关系 | 满则 迁入 | 永不压成 CSA/HCA entry |
4. 串起来:一次 decode 步发生了什么
设当前已满 Classical 的历史为 $128q$ token,State 里有 tail + SWA。
- 新 token 到达 → K/V 写入 tail(tail 长度 $+1$);
- 若 tail 使 CSA 满 4(或 HCA 满 128)→ 触发压缩,新 entry append Classical;
- SWA 窗口同步滑动,丢弃最老 token、纳入最新 token;
- Attention kernel:Classical 上稀疏/密集读压缩 entry + State 上读 tail/SWA 精确局部。
分池 = 第 2 步写完的 只读历史 与第 1、3 步的 可变状态 永不混排。
5. 相关阅读
| 文档 | 内容 |
|---|---|
| V4 KV Layout | Classical + State 双池定义 |
| V4 里的 Tail buffer 是什么? | Tail 生命周期 |
| V4 里的 SWA是什么? | SWA 为何独立 eviction |
| V4 HiSparse | 为何 offload 主要针对 Classical 里 inactive C4 |
V4 里的 SWA是什么?
← 返回 CSA/HCA 一句话 · §4 异构 KV · KV Layout §State · 磁盘 Prefix §SWA 三档 · 答疑目录
一句话
SWA 保存最近约 $n_{\text{win}}$个 token 的 精确、未压缩 K/V,给当前 query 提供 局部因果邻域;与 CSA/HCA 压缩 entry 分池(State cache),eviction 与 磁盘 prefix 策略 均 独立——部署上 SWA 常常是 per-token KV 体积大头。
0. 四模块表里的 sliding window 指什么
Raschka 表 8-1 与 演进总览 §1.2 的 Attention 行业链 中,sliding window 指 Sliding Window Attention(SWA,滑动窗口注意力):
| 维度 | 说明 |
|---|---|
| 机制 | 每个 query 只 attend 最近 $W$ 个 token 的 K/V(固定局部窗口),复杂度随序列长度 线性 而非 $O(L^2)$ |
| 行业语境 | Mistral 等长上下文模型常用此路数,介于 GQA(减 KV 头)与 MLA(低秩 latent 压缩 KV)之间 |
| DeepSeek 落点 | V1–V3 主线走 MLA → DSA → CSA/HCA;V4 把 SWA 作为 五类 KV 之一 与压缩 entry 分池(KV Layout §State),保证最近邻域 不丢 token 级精度 |
即:表里的 sliding window 是 行业演进节点;DeepSeek 在 V4 才将其 显式工程化 进异构 cache,而非 V2 引入 MLA 时的同代产物。
1. 在 V4 五类 KV 里的角色
| 维度 | SWA | CSA / HCA |
|---|---|---|
| 表示 | 每 token 一条 精确 K/V | 按块压缩 后的 entry(4:1 或 128:1) |
| 覆盖范围 | 最近 窗口内 局部 | 远距 稀疏(CSA)或 全局摘要(HCA) |
| 存放池 | State cache(per-request 块) | Classical KV cache(对齐 $\mathrm{lcm}(4,128)$) |
| 是否可落盘共享 | 体积大、策略复杂(见 §3) | CSA/HCA 压缩块易落盘 |
CSA/HCA 把历史 压短;SWA 保证 紧邻上下文 不丢精度——二者 互补,不是替代关系。
2. 为何不能只用压缩 entry
块压缩(4:1 / 128:1)会 损失 token 级精度。最近几十个 token 对语法、指代、工具调用格式等 极敏感;SWA 用 滑动窗口 保留这部分 dense 局部,与 CSA top-$k$、HCA dense 摘要 并行参与 同一层 attention 融合。
3. 推理 infra:体积与 prefix 策略
| 现象 | 说明 |
|---|---|
| 体积 | Together 早期:全量 SWA 时 per-token KV 可 高于 仅 MLA 路径;瓶颈常在 SWA state 而非 CSA/HCA 本体(HiSparse 专文) |
| Eviction | 与 C4 inactive offload 正交;可只保留 高复用 SWA 检查点 |
| 磁盘 Prefix | 论文 §3.5.2:Full / Periodic Checkpointing / Zero 三档——在 存储带宽 vs 命中重算 间取舍(专文) |
4. 与 V3.2 DSA 的对比
| V3.2 | V4 SWA | |
|---|---|---|
| 局部性 | 主要靠 顺序滑动 + indexer top-$k$ | 显式 SWA state + CSA/HCA 压缩 |
| Cache 类型 | Indexer-Cache + Latent-Cache | 五类异构对象之一 |
5. 相关阅读
| 文档 | 内容 |
|---|---|
| V4 KV Layout | Classical vs State 双池;SWA 进 State |
| V4 磁盘 Prefix Cache | SWA 三档落盘策略 |
| V4 HiSparse | SWA 与 C4 offload 的容量权衡 |
V4 里的 Tail buffer 是什么?
← 返回 CSA/HCA 一句话 · §4 异构 KV · KV Layout §State · 磁盘 Prefix §可落盘对象 · 答疑目录
一句话
Tail buffer 是流式 decode 时 尚未凑满一块 的 token 尾(CSA 缺 4、HCA 缺 128):在 State cache 里以 未压缩 K/V 暂存,凑满后 才压成 entry append 进 Classical 池——是压缩算法的 块对齐缓冲,不是第四种 attention 机制。
1. 为何需要 tail
块压缩要求 连续 $m$ 个 token 才能输出一条 entry:
| 路径 | 块大小 $m$ | Tail 含义 |
|---|---|---|
| CSA | $m{=}4$ | 当前序列长度 $\bmod 4 \neq 0$ 的 1~3 个尾 token |
| HCA | $m'{=}128$ | 不足 128 的 未压缩尾 |
若强行写入 Classical 池会破坏 $\mathrm{lcm}(4,128)$ 对齐(KV layout §Classical),故 tail 单独挂在 State 池,与 SWA 同属 「仍在形成中」 的状态。
2. 生命周期
| 阶段 | Tail | Classical 池 |
|---|---|---|
| Prefill / 流式 append | 新 token 先 进 tail | 仅 已满块 写入 |
| Tail 达到 $m$ | 触发压缩 → 一条新 entry | append 不可变 entry |
| Prefix 共享 | Tail 随请求推进变化 | 已满块可 共享 / 落盘 |
因此 磁盘 Prefix Cache 对 tail 的结论是:通常随请求走 State 池,不像 CSA/HCA 压缩块那样 直接 immutable 落盘。
3. 与 SWA 同池、分工不同
| Tail buffer | SWA | |
|---|---|---|
| 内容 | 等待压缩 的原始 token K/V | 窗口内精确局部 K/V |
| 是否可变 | 每来一 token 可能变长/清空 | 滑动更新 窗口 |
| 算法角色 | 块对齐工程缓冲 | 注意力精度 保障 |
二者都在 State cache,但 eviction、prefix 策略 各自独立。
4. 读图提示
异构 KV 图 下半 State / tail 区:token 流在进 CSA 4:1 / HCA 128:1 之前,末尾不足一块的部分 不会 出现在 Classical 条带里。
{kind=link}
5. 相关阅读
| 文档 | 内容 |
|---|---|
| V4 KV Layout | Classical vs State 分工 |
| CSA / HCA 混合压缩注意力§4 | 五类对象对照表 |
V4 里的 Indexer KV 是什么?
← 返回 CSA/HCA 一句话 · §4 异构 KV · KV Layout §State · Lightning Indexer 详解 · DSA 梗概 · 答疑目录
一句话
Indexer KV 是 V4 CSA 稀疏路径上、沿 V3.2 Lightning Indexer 一脉的 轻量 K 向量 cache:当前 $q_t$ 对 全长历史 每条 $k_s$ 廉价打分 → top-$k$ 选出要读的 C4 压缩 entry;维数、池子、是否 offload 均与 主 MLA / HCA entry 不同。
1. 在 decode 一步做什么
| 步 | 对象 | 动作 |
|---|---|---|
| 1 | 当前 hidden $h_t$ | 现算 indexer query $q_t$ |
| 2 | Indexer KV 第 $s$ 行 $k_s$ | 对 每个历史位置 $s$ 打分 $I_{t,s}$ |
| 3 | Top-$k$ | 得到下标集 $I$ |
| 4 | Classical 池 C4 entry | Core attention 只读 $I$ 内压缩块 |
方向始终是 $q_t \to k_s$(当前选历史),不是每个历史 token 各自 top-$k$。机制细节见 Lightning Indexer §1。
2. 为何单独一类 cache
| 对比 | Indexer KV | CSA C4 entry | HCA entry |
|---|---|---|---|
| 目的 | 选位置 | 被选的远距稀疏 K/V | 全局 dense 摘要 |
| 典型维度 | 窄(indexer 专用) | 压缩后主 attention | 更重压缩 |
| 读模式 | 全长扫 打分 | 仅 $I$ 内 稀疏读 | 短序列 dense |
| V3.2 对应 | Indexer-Cache | Latent-Cache | — |
V4 把 indexer 与 C4/HCA 分开记账,引擎才能 分池 eviction、分类型 prefix(KV layout)。
3. 与 ESS / offload 的关系
| 项 | 说明 |
|---|---|
| Indexer | V3.2 ESS:一般不 offload(GPU 常驻,先算 index 再决定搬哪些 latent) |
| V4 | Indexer KV 仍偏 热路径;inactive C4 的 HiSparse offload 不替代 indexer 打分(V3.2 链路描述;V4 对象名不同、分工类似) |
4. 相对纯 DSA 的延续
算法线:MLA → DSA(indexer + top-$k$)→ CSA(压缩序列上再稀疏)。Indexer 不是 V4 新发明,而是 CSA 在 更短 entry 序列 上仍需要 「看谁」 的阶段;HCA 路径则走 dense attend 压缩摘要,不共用同一套 indexer 读法。
5. 相关阅读
| 文档 | 内容 |
|---|---|
| Lightning Indexer 详解 | $q_t$ 对 $k_s$ 打分、$O(L^2)$ 常数极小 |
| DSA 稀疏注意力 | DSA 流水线总览 |
| CSA / HCA | CSA 4:1 块 + indexer 在 V4 栈中的位置 |
名词解释:SM
← 返回投机解码专文 §1.1 · Compute vs Memory 答疑 · MMA 名词 · 答疑目录
SM 是什么
SM = Streaming Multiprocessor(流式多处理器)。
NVIDIA GPU 上 一块芯片里重复出现很多次 的基本计算单元:每个 SM 自带一批 CUDA Core、若干 Tensor Core、寄存器文件、共享内存(Shared Memory / L1),并通过片上互联访问 L2,再经 内存控制器 访问片外 HBM(显存)。
可以粗记:HBM 存数据,SM 算数据;kernel 启动后,线程块(thread block)被调度到某个 SM 上执行。
在 GPU 里排哪一层
自顶向下(与本仓库 decode / 投机解码 语境相关):

{kind=link}
DeepSeek 文档里「把权重 从 HBM 搬进 SM」= 一次矩阵乘前,权重 tile 经 HBM → L2 → SM 寄存器/共享内存 流入,再在 该 SM 的 Core 上做乘加。
SM 里谁干什么
| 组件 | 在 SM 内的角色 | 本仓库常见语境 |
|---|---|---|
| CUDA Core | 通用标量/向量运算、控制流、部分 epilogue | FP8 反量化、partial sum FP32 续累加(名词解释:MMA) |
| Tensor Core | 专用 GEMM / MMA,高吞吐低精度矩阵乘 | 训练 FP8 GEMM;推理里大 batch GEMM 更吃 TC |
| 寄存器 | 线程私有,最快 | DSpark 顺序头「寄存器级微算」指这里,不反复读 HBM |
| Shared Memory | 同 block 线程共享,比 HBM 快一个数量级 | FlashAttention 等 kernel 把 tile 缓存在此 |
一个 warp(32 线程)是 SM 上调度的基本单位;Tensor Core 的一条 MMA/WGMMA 通常由一组 warp 协作完成。
为何 decode 文档总提 SM?
投机解码专文 §1.1 与 Compute vs Memory 答疑 §2 的物理图景:
- batch=1 自回归 decode 每步是 GEMV(大权重矩阵 × 单向量),算术强度极低。
- 每生成 1 个 token,仍要把 整层权重 从 HBM 流式读入 SM,但 SM 上实际并行处理的「有效计算量」很小。
- 结果:SM 上的 Core 大量时间在等 HBM/L2 送下一批权重 → 任务 Memory-Bound(带宽瓶颈,不是 FLOPS 瓶颈)。
口语里的「填不满 SM」= SM 内 Tensor Core / CUDA Core 算力闲置,内存子系统已饱和。
「搬进 SM」vs「饱和 SM」
| 说法 | 含义 |
|---|---|
| 权重搬进 SM | 数据路径:HBM → … → SM 寄存器,准备做一次 matmul |
| 填不满 SM | 算力视角:单位时间内 SM 内 有效 FLOPS / 利用率低,因为 访存跟不上 |
| $K$ 宽并行(DFlash / target verify) | 同一次权重流,SM 上处理 $K$ 列激活 → 算术强度 ↑,相对更易 吃算力 |
投机解码 target verify:仍 搬 1 遍 权重进 SM,但在 $K$ 个位置并行算——FLOPS 增加,但 不再为 $K$ 个 token 各搬 $K$ 遍权重。
和相邻名词不要混
| 缩写 | 领域 | 含义 |
|---|---|---|
| SM | GPU 硬件 | Streaming Multiprocessor |
| HBM | 显存 | High Bandwidth Memory,片外大容量存储 |
| GEMV / GEMM | 算子 | 矩阵×向量 / 矩阵×矩阵;decode 常是 GEMV |
| MMA | Tensor Core 指令 | Matrix Multiply-Accumulate(名词解释:MMA) |
| MHA / MQA | 注意力结构 | 与 SM 无关 |
与 NVIDIA 官方术语对照
- CUDA Programming Guide:SM 是 device 上执行 kernel 的 multiprocessor;每个 SM 有独立寄存器、共享内存与 Core 资源。
- Hopper 及以后架构:SM 内 Tensor Core 代际不同(如 WGMMA 在 warp-group 粒度调度),但「HBM 搬入 SM 再算」的分层不变。
一句话
SM = GPU 上 真正执行 kernel 的流式多处理器;DeepSeek 推理文档里说「权重从 HBM 搬进 SM」,是在描述 decode 访存路径;说「填不满 SM」是在说 Memory-Bound 时算力单元空转——与投机解码、Eagle/DFlash 的 mem/compute 讨论直接相关。
反向引用
| 文档 | 锚点 / 说明 |
|---|---|
| 投机解码专文 §1.1 | HBM → 计算单元;GEMV Memory-Bound |
| Compute vs Memory 答疑 §2–§4 | 「搬进 SM」「填不满 SM」 |
| 酱紫君解读 §半自回归 | 顺序头 寄存器 / on-chip vs HBM 拉 MoE |
| 名词解释:MMA | SM 内 Tensor Core vs CUDA Core 分工 |
H2D / D2H 是什么?
← 返回 ESS 论文梗概 §Figure 6&7 · ← ESS 梗概 §Fig.3 / PD 时序 · 答疑目录
1. 定义
| 缩写 | 英文 | 方向 | 典型含义 |
|---|---|---|---|
| H2D | Host-to-Device | CPU 主机内存 → GPU 显存 | 把数据 搬到 GPU 上算 |
| D2H | Device-to-Host | GPU 显存 → CPU 主机内存 | 把结果或 cache 写回 CPU |
在 CUDA 语境里,二者常通过 PCIe(ESS 论文为 PCIe 5.0)或 NVLink 完成;API 层常见 cudaMemcpyAsync(..., cudaMemcpyHostToDevice)(H2D)与 cudaMemcpyDeviceToHost(D2H)。
2. 在 ESS / V3.2 里指什么
ESS 把 Latent-Cache 大头放在 CPU DRAM,GPU 只留 Sparse Memory Pool(LRU 热子集)。每个 decode step:
- Indexer(GPU)选出本步需要的 top-$K$ latent index;
- H2D(prefetch):Cache miss 的 latent entry(约 656B/条)从 CPU 拉进 GPU 热池;
- Core MLA Attention 在 GPU 上算;
- D2H(写回):本步新生成的 latent 写回 CPU 侧 Total Memory Pool。
因此 Fig.3 时间线上的 H2D prefetch、D2H 写回 都是 Latent-Cache 在 CPU↔GPU 间的搬运;Indexer-Cache 不 offload,也不走这条搬运链。
3. 为何 ESS 论文反复强调 H2D
| 问题 | 说明 |
|---|---|
| 小块、分散 | 每步多达 $K{=}2048$ 次、每次仅 656B → 原生 cudaMemcpyAsync H2D 有效带宽极低 |
| 与算力串行 | SGLang 默认:Indexer → H2D → Attention 全串行 → GPU 在等传输时空转 |
| 优化手段 | FlashTrans + UVA 拉高 H2D/D2H 带宽;DA/DBA Overlap 让 Attention 与 H2D 并行(如 Attn0 $\parallel$ H2D) |
论文报告优化后 H2D 约 0.79 → 37 GB/s,D2H 约 0.23 → 43 GB/s(Table/§3 工程数据,见 梗概 §三大工程模块)。
4. 和「Overlap」的关系
无 Overlap(默认)

{kind=link}
DA Overlap
- 把 Attention 拆成 Attn0(只用 GPU 里已有的 latent)和 Attn1(等 prefetch 完成);
- Attn0 与 H2D 同时进行 → 用计算掩盖一部分传输延迟。
DBA 再在 batch 维切 Indexer,长上下文下算力更足,进一步掩盖 H2D。
5. 相关概念
| 概念 | 与 H2D/D2H 关系 |
|---|---|
| Prefetch | 在需要算 Attention 之前 提前发起 H2D,把 miss 的 latent 拉上来 |
| UVA(Unified Virtual Addressing) | GPU 内核直接访问 pinned 的 CPU 地址,减少小块 Memcpy 开销 |
| PCIe 带宽 | H2D/D2H 的物理上限;ESS 针对「大量小传输」做软件栈优化 |
6. 延伸阅读
- ESS 论文梗概 — Fig.3 时序、Fig.6–7 Overlap、FlashTrans 数据
- ESS Latent offload — ESS 概念与双 Cache 分工
MTP 中间 token 融合方案
← V3 §三 MTP · ← 投机解码专文 §2 · 融合 scheme SVG · 答疑目录
{kind=link}
← 中文导读 · ← 仓库首页(EN) · 旧图 MTP 投机解码总览图 是「训练结构 + 投机对照」总览;本文 + MTP 融合 scheme 图 只讲 中间 token 怎么融进 MTP 链。
{kind=link}
1. 先建立时间线:在位置 $t$ 要预测谁?
已接受前缀 $x_{1:t}$,接下来要猜未来 token:
| 谁预测 | 预测目标 | 依赖什么 |
|---|---|---|
| 主网 OutHead | $x_{t+1}$ | 主 Transformer 在 $t$ 的 hidden $h_t^{(0)}$ |
| MTP-1 | $x_{t+2}$ | $h_t^{(0)}$ 融合 $\mathrm{Emb}(x_{t+1})$ |
| MTP-2 | $x_{t+3}$ | $h_t^{(1)}$ 融合 $\mathrm{Emb}(x_{t+2})$ |
| MTP-$k$ | $x_{t+k+1}$ | $h_t^{(k-1)}$ 融合 $\mathrm{Emb}(x_{t+k})$ |
要点:主网负责 下一个 token;MTP 模块负责 更远的 $t{+}2, t{+}3, \ldots$,且 每一位仍因果依赖前面的中间 token。
1.1 你的理解:对在哪里、错在哪里?
| 说法 | 判定 | 说明 |
|---|---|---|
| draft 多个 token 不是一次性 | 对 | 必须 串行 propose:先 $x_{t+1}$,再融 $\mathrm{Emb}(x_{t+1})$ 猜 $x_{t+2}$,再融 $\mathrm{Emb}(x_{t+2})$ 猜 $x_{t+3}$… |
| 「$K$ 个 LM 头、每个头深度不同」 | 半对半错 | V3 是 1 个共享 OutHead,被调用 $K$ 次;变长的是 MTP 因果链,不是 $K$ 套独立 output head |
| 「第 2 个比第 1 个深,因为要融上一个 emb」 | 对(指链深度) | 猜 $x_{t+2}$:链深度 1(1 次 Fusion+TRM,1 个中间 Emb);猜 $x_{t+3}$:链深度 2(再串 1 步,累计 2 个 Emb) |
| 「每个 MTP 模块自身更深」 | 错 | 每个 $\mathrm{TRM}_k$ 都是 1 个浅 Block;不是 MTP-2 = 2 层 Transformer、MTP-3 = 3 层 |
一句话:不是 K 路并行 LM 头;是 1 个共享 OutHead + K 步串行 Fusion/TRM,每步多注入 1 个中间 token 的 Emb。

{kind=link}
2. 融合公式
对位置 $t$、MTP 深度 $k$:
$$ h_t^{\prime(k)} = M_k\bigl[,\mathrm{RMSNorm}(h_t^{(k-1)})\ ;\ \mathrm{RMSNorm}(\mathrm{Emb}(x_{t+k})),\bigr] $$
$$ h_t^{(k)} = \mathrm{TRM}k(h_t^{\prime(k)}), \qquad P(x{t+k+1}\mid x_{1:t}) = \mathrm{softmax}\bigl(\mathrm{OutHead}(h_t^{(k)})\bigr) $$
符号说明:
| 符号 | 含义 |
|---|---|
| $h_t^{(0)}$ | 主网在位置 $t$ 的 hidden(不是再跑一遍主网) |
| $x_{t+k}$ | 第 $k$ 个 中间 token(训练用真值,推理用已 propose 的 $\hat{x}$) |
| $M_k$ | 线性投影 $d \to d$(concat 后) |
| $\mathrm{TRM}_k$ | 1 层浅 Transformer Block(不是 L 层主网) |
| $\mathrm{OutHead}$ | 与主网 共享 的输出头 |
$\oplus$ / 融合 = [RMSNorm(h); RMSNorm(Emb)] 拼接后过 $M_k$,不是把 $x_{t+1:t+k}$ 一次性全塞进去。
3. 「一次前向」到底指什么?
容易混的两层:
3.1 训练
整段序列 x_{1:T}
-> 主 Transformer 【1 次前向】-> 所有位置的 h_t^(0)
-> 各 t 上批量跑 MTP-1, MTP-2, ...(浅块,不重跑主网 L 层)
-> 中间 token 用 teacher forcing 真值 Emb(x_{t+k})
- 1 次前向 = 主网对 整批序列 只跑一遍 L 层 Transformer。
- MTP 是在 已有 $h_t^{(0)}$ 上叠 浅 MTP Block,算力远小于「主网 × K 遍」。
3.2 推理
每个 decode 轮:
1) 主网 【1 次】target forward -> verify 已 propose 的 K 个候选
2) MTP 链 【K 小步】串行:
Emb(x_hat_{t+1}) + MTPBlock_1 -> 猜 x_hat_{t+2}
Emb(x_hat_{t+2}) + MTPBlock_2 -> 猜 x_hat_{t+3}
...
- 不是 一个 softmax 无依赖吐出 $t{+}1,\ldots,t{+}K$。
- 也不是 为 MTP 把 671B 主网跑 $K$ 遍;主网每轮仍 1 次 verify。
4. 三个常见误解
| 误解 | 实际 |
|---|---|
| MTP 一次吐出 K 个独立 token | 因果链:深度 $k$ 只融 一个 $x_{t+k}$,更远位靠上一层 $h_t^{(k-1)}$ 传递 |
| MTP 推理 = 主网跑 K 遍 | 主网 1 遍;多出来的是 K 个浅 MTP Block |
| Emb 输入永远是真值 | 训练 teacher forcing;推理 draft 用 上一步刚猜的 $\hat{x}$ embed |
5. 与 DSpark 对照
| MTP | DSpark | |
|---|---|---|
| 重活 | 主网 1 次(verify) | 并行 MoE 主干 1 次 |
| 轻链 | MTPBlock 串 $K$ 步(融 embed) | 顺序头 $g_\theta$ 串 $K$ 步 |
| 权重 | 同 checkpoint MTP 头 | 外挂 DeepSpec draft |
投机 verify 循环相同(§1);差异在 draft 从哪来、怎么猜 K 位。
6. 训练目标
$$ \mathcal{L}{\mathrm{total}} = \mathcal{L}{\mathrm{main}} + \sum_{k=1}^{M} \lambda_k \mathcal{L}_{\mathrm{MTP}}^{(k)} $$
MTP 首要目的是 训练信号 densify / 表征 pre-plan;推理时可 丢弃 MTP 模块,也可 复用做 draft(V3 论文 MTP in Inference)。
7. 反向引用
| 文档 | 说明 |
|---|---|
| MTP 融合 scheme 图 | 融合 scheme 总览 |
| MTP draft 链深度图 | §1.1 串行 draft 链深度计算图 |
| 酱紫君解读 §MTP | |
| 投机解码专文 §2 | |
| V3 论文 Figure 3 原文(Eq.21–23) |
投机解码:Compute-Bound vs Memory-Bound — DFlash / Eagle 如何对应?
← 返回投机解码专文 §1.1 · ← 专文 §4 草稿范式 · ← 酱紫君解读 §Speculative Decoding · 答疑目录
酱紫君原文一句话:
用 Compute-Bound 的并行验证 去替代 Memory-Bound 的串行读取。
下文分 两层 读这句话,并说明 DFlash / Eagle 在 draft 侧如何对应。
1. 两层含义:不要混在一个维度上
| 层级 | 「前者」Compute-Bound 并行 | 「后者」Memory-Bound 串行 | 代表 |
|---|---|---|---|
| A. 整链宏观(target 侧) | target 一次前向并行校验 $K$ 个位置 | 传统 decode:每 token 各跑 1 次 target 前向 | §1.1–§1.2 |
| B. Draft 范式($M_q$ 侧) | 并行出整块 $K$ 位 hidden / logits | 串行自回归,每步完整 draft 前向 | DFlash vs Eagle3 |
结论(直接回答):
- 若问的是 draft 怎么猜 $K$ 个 token:DFlash ≈ 前者(并行 / 更偏 Compute-Bound),Eagle3 ≈ 后者(串行 / Memory-Bound)。
- 若问的是 酱紫君开篇整句在说什么:主语是 投机解码相对纯自回归——用 target 的 1 次并行 verify 换掉 $K$ 次串行 target decode;Eagle / DFlash 是这之后 draft 侧的两条工程路线,不是整句的字面主语。
两层 同构:都是「少搬几次权重,多算一点并行位」。
2. 为何 decode 默认是 Memory-Bound?
专文 §1.1 的物理图景(batch=1 自回归):
- 每生成 1 个 token,都要把 整网权重 从 HBM 搬进 SM(名词:SM;大矩阵 × 单向量,GEMV)。
- 算术强度极低 → GPU 算力闲置,时间花在 访存带宽 上 → Memory-Bound。
- 第 $N$ 个 token 必须等第 $N{-}1$ 个 → 串行读取(每步一遍权重流)。
传统 target decode 出 $K$ 个 token:$K$ 次 target 前向 ≈ $K$ 次搬大模型权重。
投机解码的 target verify:仍搬 1 遍 target 权重,但 attention / FFN 在 $K$ 个位置并行算——多出来的 FLOPS 相对带宽往往 填不满 SM(名词:SM),但 不再乘 $K$ 遍搬权重 → 从系统视角 更像 Compute-Bound 的并行验证(相对「$K$ 次 mem-bound 串行读」)。
3. 为何 Eagle3 是 Memory-Bound 串行?
Eagle3 属于 自回归外挂 draft:块内第 $i$ 个 token 依赖已猜的 $\hat{x}_{t+i-1}$,不能与前面位完全并行,必须:
$$ \hat{x}_{t+1} \to \text{draft 前向}1 \to \hat{x}{t+2} \to \text{draft 前向}2 \to \cdots \to \hat{x}{t+K} $$
3.1 每步都在「再读一遍 draft 权重」
与 target 同理,draft 在 batch=1 decode 下也是 GEMV 型 前向。Eagle3 的第 $i$ 步 = 一整段 draft Transformer(多层 Attention + FFN/MoE)完整前向 → 从 HBM 再拉一遍 draft 全部层权重。
- 块长 $K$ → $K$ 次完整 draft 前向
- draft 侧总耗时 $\tau_q^{\mathrm{Eagle}} \approx K \cdot \tau_{\mathrm{step}}$ → $\tau_q \propto K$(专文 §4、酱紫君解读对照表)
3.2 算力利用率低
每步只推进 1 个 token 的 hidden;矩阵乘法是「大矩阵 × 单向量」,SM 上并行度有限。时间轴上大量周期在 等 HBM 返回下一层权重,而非饱和 Tensor Core → 典型 Memory-Bound。
3.3 换来的收益:块内因果对齐
串行的代价是 每步显式看见 $\hat{x}{t+i-1}$,draft 分布 $q_i$ 更贴近 target 校验分布 $p_i$ → $\mathbb{E}[N{\mathrm{acc}}]$ 高、后缀稳定(专文 §6.1 表)。Eagle 用 多搬几次权重 换 猜得更准。
4. 为何 DFlash 更偏 Compute-Bound 并行?
DFlash 走 并行外挂 draft:在固定 target hidden $h_t^p$ 上,一次前向同时产出 $K$ 个位置的 hidden / 基础 logits:
$$ E = {e_{t+1}, \ldots, e_{t+K}} = \mathrm{DFlashBackbone}(h_t^p) $$
4.1 权重只搬一轮,$K$ 位并行 matmul
- 2–3 层轻量 MoE:1 次 HBM 权重流 → $K$ 个位置并行做 Attention / FFN。
- 相对 Eagle 的 $K$ 次完整前向,访存次数 ~$1/K$;多出来的 FLOPS 用于 并行位 而非 重复搬权重 → draft 延迟 几乎与 $K$ 弱相关(专文 §4 表「DFlash 优势」)。
4.2 瓶颈从带宽转向算力
同一轮 draft 里,SM 处理 $K$ 宽的激活 → 算术强度高于「$K$ 次单向量 GEMV」。在固定 draft 参数量下,更吃算力、更少重复访存 → 工程上归类为 Compute-Bound 并行一侧。
4.3 代价:缺块内因果
各位 共享 target 前缀,互不见块内已猜 $\hat{x}{<i}$ → 第 2 位起 $q_i \not\approx p_i$ → $\mathbb{E}[N{\mathrm{acc}}]$ 骤降(专文 §6.1)。DFlash 用 少搬权重、并行算 换 低 draft 延迟,但 后缀接受率 不如 Eagle。
5. DSpark:在同一轮 draft 里拆「重并行 + 轻串行」
DSpark 不是第三条 mem/compute 轴,而是 把 Eagle 的串行依赖拆成极轻顺序头:
| 阶段 | 访存 / 算力 | 作用 |
|---|---|---|
| 并行主干(DFlash 改进) | 1 次 HBM 拉 MoE;$K$ 位并行 | 低 $\tau_q$、第 1 位高接受率 |
| 顺序头 $g_\theta$ × $K$ | 寄存器 / on-chip;$<0.1%$ 主模型参数 | 逐位注入 $\hat{x}_{i-1}$,补块内因果 |
若顺序头也每层跑 MoE → 退化成 Eagle,$\tau_q$ 再次 $\propto K$(酱紫君解读 §半自回归)。
6. 对照总表
| Eagle3(后者 / 串行) | DFlash(前者 / 并行) | DSpark | |
|---|---|---|---|
| Draft 生成 | $K$ 次完整 Transformer 前向 | 1 次并行主干 | 1 次主干 + $K$ 次轻头 |
| 主导瓶颈 | HBM 带宽(重复搬 draft 权重) | 并行算力($K$ 宽 matmul) | 主干同 DFlash;轻头 on-chip |
| $\tau_q$ vs $K$ | $\propto K$ | ≈ 常数 | 主干 ≈ 常数 + 极小尾巴 |
| $\mathbb{E}[N_{\mathrm{acc}}]$ | 高(块内因果完整) | 第 1 位高,后缀掉 | 折中 |
| 加速公式 $S_{\uparrow}$ 杠杆 | 抬接受率;$K\tau_q$ 大 | $K\tau_q$ 小;后缀接受差 | 两者折中 |
加速比粗式(专文 §4):
$$ S_{\uparrow} = \frac{\bigl(\mathbb{E}[N_{\mathrm{acc}}] + 1\bigr),\tau_p}{K,\tau_q + \tau_p} $$
- Eagle:分子大($\mathbb{E}[N_{\mathrm{acc}}]$),分母里 $K\tau_q$ 也大
- DFlash:分母小,但 $\mathbb{E}[N_{\mathrm{acc}}]$ 限制分子
- DSpark:在 $K\tau_q$ 与 $\mathbb{E}[N_{\mathrm{acc}}]$ 之间取半自回归折中
7. 一句话记忆
- Memory-Bound 串行读取 = batch=1 decode 下 每 token 各搬一遍权重;Eagle draft 是典型($K$ token → $K$ 遍 draft 权重流)。
- Compute-Bound 并行验证 = 搬一遍权重、多位置并行算;target verify 与 DFlash 并行主干同属这一类。
- DFlash ≈ 前者,Eagle ≈ 后者 —— 在 draft 范式维度上成立;开篇整句 additionally 指 target 并行 verify 替代 $K$ 次串行 target decode。
8. 反向引用
| 文档 | 锚点 / 说明 |
|---|---|
| 投机解码专文 §1.1 | Memory-Bound 瓶颈原文 |
| 投机解码专文 §4 | Eagle / DFlash / DSpark 范式表 |
| 投机解码专文 §6.1 | 堆叠依赖与接受率 |
| 酱紫君解读 §Speculative Decoding | 「用并行验证替代串行读取」原文 |
| 酱紫君解读 §半自回归 | Eagle 式 vs DSpark 式 $\tau_q$ 对照 |
| 投机解码:为何接受率是 $\min$、修正分布是 $\max$ | lossless 接受路径(与 mem/compute 正交) |
| 名词解释:SM | SM / HBM / 「填不满 SM」名词 |
9. 外部文献
- Leviathan et al., Fast Inference from Transformers via Speculative Decoding, arXiv:2211.17002, 2022.
- Li et al., EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty, 2024(Eagle 系自回归 draft)。
- DSpark_paper.pdf — Semi-Autoregressive Draft;DFlash 并行 vs Eagle 串行消融。
投机解码:为何接受率是 $\min$、修正分布是 $\max$
专文 §1.3 仅保留结论;本节用引用块展开 接受路径 / 拒绝路径 / 合并为 $p$ 与公式推导。
接受路径 — 固定前缀 $s$,draft 抽 $X \sim q$,再独立抽 $U \sim \mathrm{Uniform}(0,1)$。对 token $x$,事件 $E_{\mathrm{acc}}(x)={X{=}x,\ U\le\alpha(x)}$:draft 恰好提议 $x$ 且 校验通过,直接输出 $x$。
$$P\bigl(E_{\mathrm{acc}}(x)\bigr)=P(X{=}x)\cdot P(U\le\alpha(x)\mid X{=}x)=q(x),\alpha(x).$$
连乘是序贯试验的乘法公式:先以 $q(x)$ 抽到 $x$,再以 $\alpha(x)$ 通过校验。
拒绝路径 — 「发生拒绝且最终输出 $x$」:丢弃提议的 $X$,从 $p_{\mathrm{resample}}$ 抽到 $X'{=}x$。与 $E_{\mathrm{acc}}(x)$ 不交。
合并为 target 分布 — 输出 $x$ 的总概率
$$\pi(x)=P\bigl(E_{\mathrm{acc}}(x)\bigr)+P(\mathrm{reject}),p_{\mathrm{resample}}(x).$$
取 $\alpha(x)=\min(1,p(x)/q(x))$ 使接受路径贡献 $q\alpha=\min(q,p)$;取 $p_{\mathrm{resample}}(x)\propto\max(0,p(x)-q(x))$ 补足拒绝路径上的剩余质量,可得 $\pi(x)=p(x)$(§5 逐步验算)。draft 只改 $q$ 与接受有多快,不改边际分布。
1. 问题设定
固定已接受前缀 $s$。希望下一个 token 服从 target 分布 $p(\cdot)\equiv p_{\mathrm{tgt}}(\cdot \mid s)$。
投机解码让 draft 先提议 token $x$,其(条件)概率为 $q(x)\equiv p_{\mathrm{draft}}(x \mid s)$。算法只做两件事:
- 以某个概率 接受 $x$;
- 否则 拒绝,再从另一个分布 重采 $x'$。
要证明 lossless,只需证明:对任意词汇表元素 $x$,最终输出 $x$ 的总概率 $\pi(x)$ 恰好等于 $p(x)$。
2. 单步随机实验:何谓「接受路径」、为何是连乘
2.1 算法对应的一次抽样
把「draft 提议 → target 校验」看成 两步随机试验:
- 提议:随机变量 $X \sim q$(draft 按 $q$ 抽一个 token,$P(X{=}x)=q(x)$)。
- 校验:再抽 $U \sim \mathrm{Uniform}(0,1)$,与 $X$ 独立;若 $U \le \alpha(X)$ 则 接受,否则 拒绝。
其中 $\alpha(x)$ 是待定的接受率(下一节解出 $\alpha(x)=\min(1,p(x)/q(x))$)。
输出规则:
| 事件 | 输出 |
|---|---|
| 接受($U \le \alpha(X)$) | 直接输出提议的 $X$ |
| 拒绝($U > \alpha(X)$) | 丢弃 $X$,从 $p_{\mathrm{resample}}$ 另抽 $X'$ 输出 |
2.2 「接受路径」的严格含义
对某个 具体的 token $x$,定义事件
$$ E_{\mathrm{acc}}(x) ;=; { X = x ;\land; U \le \alpha(x) }. $$
即:draft 恰好提议了 $x$,且校验通过。全文所称 接受路径(acceptance path) 就是指输出 $x$ 时,$E_{\mathrm{acc}}(x)$ 发生这一条分支。
与之互斥的是 拒绝路径(rejection path):
$$ E_{\mathrm{rej}}(x) ;=; { \text{发生拒绝} } ;\land; { X' = x }, $$
其中 $X' \sim p_{\mathrm{resample}}$ 是拒绝后另抽的 token。
两条路径 不交:接受时输出的是 $X$,拒绝时输出的是 $X' \neq X$(逻辑上先拒绝再重采,不会「又接受 draft 又重采」)。
2.3 为何是 $q,\alpha$
由 乘法公式 / 条件概率($U$ 与 $X$ 独立,故给定 $X{=}x$ 时接受概率为 $\alpha(x)$):
$$ P\bigl(E_{\mathrm{acc}}(x)\bigr) = P(X{=}x) \cdot P(U \le \alpha(x) \mid X{=}x) = q(x),\alpha(x). $$
连乘不是额外假设,而是「先以 $q(x)$ 抽到 $x$,再以 $\alpha(x)$ 通过校验」这一 序贯试验 的自然写法。类比:先掷骰得到 6 的概率是 $\frac{1}{6}$,再独立掷硬币正面才采纳,则「出 6 且采纳」$=\frac{1}{6}\times\frac{1}{2}$。
2.4 两条路径合并
任意 $x$ 的最终输出概率是 两条不交路径之和:
$$ \pi(x) = \underbrace{P\bigl(E_{\mathrm{acc}}(x)\bigr)}_{q(x)\alpha(x)}
- \underbrace{P(\mathrm{reject})\cdot p_{\mathrm{resample}}(x)}_{\text{拒绝后重采}}. $$
后文先定 $\alpha$ 使 $q\alpha=\min(q,p)$,再定 $p_{\mathrm{resample}}$ 补足 $\max(0,p-q)$,即得 $\pi(x)=p(x)$。
3. 接受率为何是 $\min!\left}{q}\right)$
记接受概率为 $\alpha(x)$。由 §2.3,接受路径上输出 $x$ 的概率为 $q(x),\alpha(x)$。要求这条路径对 $x$ 的贡献是 $p(x)$ 的一部分,且不超过 $p(x)$(超出部分留给拒绝路径)。最自然要求是
$$ q(x),\alpha(x) = \min\bigl(q(x),, p(x)\bigr). $$
当 $q(x)>0$ 时两边同除以 $q(x)$:
$$ \alpha(x) = \min!\left(1,\ \frac{p(x)}{q(x)}\right). $$
直觉:
| 关系 | 含义 | 接受率 |
|---|---|---|
| $q(x) > p(x)$ | draft 高估 $x$ | $\dfrac{p}{q} < 1$,经常拒绝以 压低 $x$ 出现频率 |
| $q(x) \le p(x)$ | draft 低估或未覆盖 $x$ | 接受率 $=1$;$p-q$ 的正差留给重采分布补足 |
这就是 $\min(1,p/q)$ 的来源:不是经验公式,而是要求「接受路径贡献 $\min(q,p)$」的代数解(见 §2.2 对接受路径的定义)。
4. 修正分布为何 $\propto \max$
对每个 $x$,target 需要总质量 $p(x)$。接受路径已给出 $\min(q(x),p(x))$,还差
$$ p(x) - \min\bigl(q(x),p(x)\bigr) = \max\bigl(0,, p(x) - q(x)\bigr). $$
把所有 token 上「尚未满足的质量」收集起来,归一化,定义 拒绝后重采分布:
$$ p_{\mathrm{resample}}(x) = \frac{\max\bigl(0,, p(x) - q(x)\bigr)}{Z}, \qquad Z = \sum_{x'} \max\bigl(0,, p(x') - q(x')\bigr). $$
直觉:$p-q>0$ 的位置,正是 draft 没给够 的概率质量;拒绝后专门从这些位置补抽,把 target 分布「缺的那一块」填回去。
5. 合并后恰好等于 $p$
基础恒等式 — 记 $a=p(x)$、$b=q(x)$,则
$$\min(a,b) + \max(0,, a-b) = a.$$
分两种情形验证:若 $p \le q$,则 $\min(p,q)=p$、$\max(0,p-q)=0$,相加得 $p$;若 $p > q$,则 $\min(p,q)=q$、$\max(0,p-q)=p-q$,相加得 $q+(p-q)=p$。因此对每个 token,接受路径质量 $\min(q,p)$ 与拒绝路径补足 $\max(0,p-q)$ 刚好拼回 target 的 $p(x)$,与 draft 无关。
拒绝概率
$$ P(\mathrm{reject}) = 1 - \sum_x q(x),\alpha(x) = 1 - \sum_x \min\bigl(q(x),p(x)\bigr) = Z. $$
(由上文恒等式,$\sum_x \min(q,p) + \sum_x \max(0,p-q) = \sum_x p(x) = 1$,故 $P(\mathrm{reject}) = 1 - \sum_x \min(q,p) = \sum_x \max(0,p-q) = Z$。)
最终输出 $x$ 的概率:
$$ \pi(x) = \underbrace{q(x),\alpha(x)}{\min(q,p)} + \underbrace{P(\mathrm{reject})\cdot p{\mathrm{resample}}(x)}_{Z \cdot \frac{\max(0,p-q)}{Z}} = \min\bigl(q(x),p(x)\bigr) + \max\bigl(0,, p(x)-q(x)\bigr) = p(x). $$
因此对 每一个 $x$ 都有 $\pi(x)=p(x)$:与「不用 draft、直接从 $p$ 采样」同分布。
6. 与投机解码整链的关系
- 上面对 单个位置、固定前缀 $s$ 证明一次;链上第 $1,2,\ldots$ 位在 更新前缀后 重复同一规则。
- target 一次并行前向 只是同时算出各位置的 $p_{\mathrm{tgt}}$;接受/拒绝规则不变。
- draft 只影响 $q$ 与接受有多快,不改变 $\pi=p$ 的构造。
7. 参考
- Leviathan, Y., Kalman, M., & Matias, Y. Fast Inference from Transformers via Speculative Decoding. arXiv:2211.17002.
- 专文机制总览:投机解码与 DSpark§1.2–§1.3
V4 为何要分池?块对齐与尾缓冲怎么配合?
← 返回 KV Layout §为何单一 layout 不够 · Classical 池 · State 池 · Tail buffer · SWA · 答疑目录
一句话
V4 同时有 两种块长(CSA $m{=}4$、HCA $m'{=}128$)和 两种生命周期(已压缩定型 vs 仍在滑动/凑块);Classical 池 只放 凑满且不可变 的压缩 entry,State 池 放 尾缓冲 + SWA 等 每步都在变 的状态——混在一个池里会同时破坏 $\mathrm{lcm}$ 块对齐、prefix 共享、HiSparse offload。
1. 为什么要分池管理
1.1 不是「多几种 KV」那么简单,是 读写语义不同
| Classical KV cache | State cache | |
|---|---|---|
| 存什么 | 已凑满的 CSA C4 / HCA 压缩 entry | Tail(未凑满块)+ SWA(滑动窗口精确 K/V)+ 可能含 Indexer |
| 是否可变 | 写入后 不可变(immutable) | 每 decode 步 都可能变(tail 变长/清空,SWA 滑动) |
| 能否 prefix 共享 | 能 — 同一压缩块多请求只存一份 | 难 — 随各请求当前长度 / 窗口不同 |
| 能否落盘 / offload | CSA/HCA 块 优先(紧凑、不变) | 通常 跟请求走;SWA 还有三档策略(磁盘 prefix) |
| 分配粒度 | 按 压缩 entry append | 每请求固定 state block(batch 内对齐) |
V3/V3.2 可以「一层一条同质 latent 流」——shape 一样、生命周期一样。V4 把 远距压缩历史 与 局部未压缩 / 未定型 混在同一抽象里,引擎就无法用 同一套 eviction、同一套 prefix 哈希、同一套 DMA 粒度 管理。
1.2 压缩比 $m \neq m'$ 放大了这个问题
- CSA:每 4 token → 1 条 C4 entry(远距 稀疏 top-$k$ 读)
- HCA:每 128 token → 1 条 HCA entry(全局 dense 读)
二者 entry 密度差 32 倍,读模式也不同。若强行共池:
- 块边界对不齐 — 同一 token 区间在 CSA 是 32 条 entry、在 HCA 是 1 条,物理槽位无法统一编号;
- 尾部长度不同 — CSA tail 最多 3 token,HCA tail 最多 127 token,与 SWA 窗口 叠加 后 State 侧体积不可预测;
- eviction 策略冲突 — HiSparse 想 offload inactive C4;SWA 却要 热窗口常驻 — 必须在池级分开。
所以表里写:$m{=}4$、$m'{=}128$ 不同 → 块对齐、尾缓冲、SWA 窗口必须分池管理。
2. 块对齐:$\mathrm{lcm}=128$ 是啥逻辑
2.1 压缩器的硬约束
块压缩不是「任意截断」,而是:
$$ \text{连续 } m \text{ 个 token 的 K/V} ;\xrightarrow{;\text{compress};}; 1 \text{ 条 entry} $$
- CSA:$m=4$
- HCA:$m'=128$
引擎要为 已完成的块 在 Classical 池里分配 连续、可索引 的槽位。若物理分配粒度只按 4 对齐,HCA 每 128 token 才一条,中间会产生 跨槽碎片;若只按 128 对齐,CSA 每 4 token 一条又无法在子块内寻址。
2.2 用 lcm 统一「大块」边界
取
$$ \mathrm{lcm}(m,m') = \mathrm{lcm}(4,128) = 128 $$
含义:每 128 个 token 构成一个 对齐超级块,在这个边界上:
| 在这 128 token 内 | CSA | HCA |
|---|---|---|
| 满块 entry 数 | $128/4 = 32$ 条 C4 | $128/128 = 1$ 条 HCA |
| 边界 | 32 条 C4 刚好填满 | 1 条 HCA 刚好填满 |
任意 已完成 的历史长度 $L$ 可写成:
$$ L = 128 \cdot q + r,\quad 0 \le r < 128 $$
- $128q$ token → Classical 池里有 $32q$ 条 C4 + $q$ 条 HCA(一一对应同一批 token 区间)
- 剩余 $r$ token → 进 tail,不进 Classical(见下节)
这样 prefix 共享、落盘、HiSparse 按 entry 搬移 时,CSA 与 HCA 的「第 $k$ 个 128-token 段」语义一致,不会出现半块只压了一边的情况。
2.3 小例子:$L=130$ token
| 区间 | Classical 池 | State 池 |
|---|---|---|
| token $1\ldots128$ | 32×C4 + 1×HCA(已满) | — |
| token $129\ldots130$ | 不写(未满 4 也未满 128 的 公共尾) | Tail 2 token + SWA 窗口(含最近 128,与上表重叠由 kernel 定义) |
若把 129–130 强行写入 Classical,要么 伪造半条 HCA(算法不允许),要么 破坏 C4 四元组完整性。
3. 尾缓冲的逻辑
3.1 流式 decode:来一 token,不能立刻压块
Prefill / decode 逐个 append token 时,序列长度 $L$ 任意时刻 不一定 被 4 或 128 整除。
Tail buffer = 当前 还凑不成一整块 的 K/V 暂存区:
| 路径 | 何时「满块」 | Tail 最多多长 |
|---|---|---|
| CSA | $L \bmod 4 = 0$ | 3 token |
| HCA | $L \bmod 128 = 0$ | 127 token |
满块时:压缩 → 一条 entry append 到 Classical 池 → tail 中对应 token 清空或前移。
3.2 为何 tail 必须在 State 池
| 若在 Classical | 若在 State(实际) |
|---|---|
| entry 未定型却要占位 → 无法 immutable 共享 | 明确标记为 进行中 |
| prefix 命中时要拷贝 半块垃圾 | 命中后只需 重算 / 补 tail + SWA |
| offload 无法判断 是否完整块 | Classical 里 全是满块,HiSparse 可安全搬 inactive C4 |
Tail 是 块对齐的工程缓冲,不是新 attention 类型(详见 tail buffer 答疑)。
3.3 与 SWA 同池、不同职责
二者都在 State 池,但:
| Tail | SWA | |
|---|---|---|
| 目的 | 等凑满 压缩块 | 保留 局部精度 |
| 变化方式 | 长度 $0\ldots m{-}1$ 阶跃 | 窗口 滑动 |
| 与 Classical 关系 | 满则 迁入 | 永不压成 CSA/HCA entry |
4. 串起来:一次 decode 步发生了什么
设当前已满 Classical 的历史为 $128q$ token,State 里有 tail + SWA。
- 新 token 到达 → K/V 写入 tail(tail 长度 $+1$);
- 若 tail 使 CSA 满 4(或 HCA 满 128)→ 触发压缩,新 entry append Classical;
- SWA 窗口同步滑动,丢弃最老 token、纳入最新 token;
- Attention kernel:Classical 上稀疏/密集读压缩 entry + State 上读 tail/SWA 精确局部。
分池 = 第 2 步写完的 只读历史 与第 1、3 步的 可变状态 永不混排。
5. 相关阅读
| 文档 | 内容 |
|---|---|
| V4 KV Layout | Classical + State 双池定义 |
| V4 里的 Tail buffer 是什么? | Tail 生命周期 |
| V4 里的 SWA是什么? | SWA 为何独立 eviction |
| V4 HiSparse | 为何 offload 主要针对 Classical 里 inactive C4 |
V4 里的 SWA是什么?
← 返回 CSA/HCA 一句话 · §4 异构 KV · KV Layout §State · 磁盘 Prefix §SWA 三档 · 答疑目录
一句话
SWA 保存最近约 $n_{\text{win}}$个 token 的 精确、未压缩 K/V,给当前 query 提供 局部因果邻域;与 CSA/HCA 压缩 entry 分池(State cache),eviction 与 磁盘 prefix 策略 均 独立——部署上 SWA 常常是 per-token KV 体积大头。
0. 四模块表里的 sliding window 指什么
Raschka 表 8-1 与 演进总览 §1.2 的 Attention 行业链 中,sliding window 指 Sliding Window Attention(SWA,滑动窗口注意力):
| 维度 | 说明 |
|---|---|
| 机制 | 每个 query 只 attend 最近 $W$ 个 token 的 K/V(固定局部窗口),复杂度随序列长度 线性 而非 $O(L^2)$ |
| 行业语境 | Mistral 等长上下文模型常用此路数,介于 GQA(减 KV 头)与 MLA(低秩 latent 压缩 KV)之间 |
| DeepSeek 落点 | V1–V3 主线走 MLA → DSA → CSA/HCA;V4 把 SWA 作为 五类 KV 之一 与压缩 entry 分池(KV Layout §State),保证最近邻域 不丢 token 级精度 |
即:表里的 sliding window 是 行业演进节点;DeepSeek 在 V4 才将其 显式工程化 进异构 cache,而非 V2 引入 MLA 时的同代产物。
1. 在 V4 五类 KV 里的角色
| 维度 | SWA | CSA / HCA |
|---|---|---|
| 表示 | 每 token 一条 精确 K/V | 按块压缩 后的 entry(4:1 或 128:1) |
| 覆盖范围 | 最近 窗口内 局部 | 远距 稀疏(CSA)或 全局摘要(HCA) |
| 存放池 | State cache(per-request 块) | Classical KV cache(对齐 $\mathrm{lcm}(4,128)$) |
| 是否可落盘共享 | 体积大、策略复杂(见 §3) | CSA/HCA 压缩块易落盘 |
CSA/HCA 把历史 压短;SWA 保证 紧邻上下文 不丢精度——二者 互补,不是替代关系。
2. 为何不能只用压缩 entry
块压缩(4:1 / 128:1)会 损失 token 级精度。最近几十个 token 对语法、指代、工具调用格式等 极敏感;SWA 用 滑动窗口 保留这部分 dense 局部,与 CSA top-$k$、HCA dense 摘要 并行参与 同一层 attention 融合。
3. 推理 infra:体积与 prefix 策略
| 现象 | 说明 |
|---|---|
| 体积 | Together 早期:全量 SWA 时 per-token KV 可 高于 仅 MLA 路径;瓶颈常在 SWA state 而非 CSA/HCA 本体(HiSparse 专文) |
| Eviction | 与 C4 inactive offload 正交;可只保留 高复用 SWA 检查点 |
| 磁盘 Prefix | 论文 §3.5.2:Full / Periodic Checkpointing / Zero 三档——在 存储带宽 vs 命中重算 间取舍(专文) |
4. 与 V3.2 DSA 的对比
| V3.2 | V4 SWA | |
|---|---|---|
| 局部性 | 主要靠 顺序滑动 + indexer top-$k$ | 显式 SWA state + CSA/HCA 压缩 |
| Cache 类型 | Indexer-Cache + Latent-Cache | 五类异构对象之一 |
5. 相关阅读
| 文档 | 内容 |
|---|---|
| V4 KV Layout | Classical vs State 双池;SWA 进 State |
| V4 磁盘 Prefix Cache | SWA 三档落盘策略 |
| V4 HiSparse | SWA 与 C4 offload 的容量权衡 |
V4 里的 Tail buffer 是什么?
← 返回 CSA/HCA 一句话 · §4 异构 KV · KV Layout §State · 磁盘 Prefix §可落盘对象 · 答疑目录
一句话
Tail buffer 是流式 decode 时 尚未凑满一块 的 token 尾(CSA 缺 4、HCA 缺 128):在 State cache 里以 未压缩 K/V 暂存,凑满后 才压成 entry append 进 Classical 池——是压缩算法的 块对齐缓冲,不是第四种 attention 机制。
1. 为何需要 tail
块压缩要求 连续 $m$ 个 token 才能输出一条 entry:
| 路径 | 块大小 $m$ | Tail 含义 |
|---|---|---|
| CSA | $m{=}4$ | 当前序列长度 $\bmod 4 \neq 0$ 的 1~3 个尾 token |
| HCA | $m'{=}128$ | 不足 128 的 未压缩尾 |
若强行写入 Classical 池会破坏 $\mathrm{lcm}(4,128)$ 对齐(KV layout §Classical),故 tail 单独挂在 State 池,与 SWA 同属 「仍在形成中」 的状态。
2. 生命周期
| 阶段 | Tail | Classical 池 |
|---|---|---|
| Prefill / 流式 append | 新 token 先 进 tail | 仅 已满块 写入 |
| Tail 达到 $m$ | 触发压缩 → 一条新 entry | append 不可变 entry |
| Prefix 共享 | Tail 随请求推进变化 | 已满块可 共享 / 落盘 |
因此 磁盘 Prefix Cache 对 tail 的结论是:通常随请求走 State 池,不像 CSA/HCA 压缩块那样 直接 immutable 落盘。
3. 与 SWA 同池、分工不同
| Tail buffer | SWA | |
|---|---|---|
| 内容 | 等待压缩 的原始 token K/V | 窗口内精确局部 K/V |
| 是否可变 | 每来一 token 可能变长/清空 | 滑动更新 窗口 |
| 算法角色 | 块对齐工程缓冲 | 注意力精度 保障 |
二者都在 State cache,但 eviction、prefix 策略 各自独立。
4. 读图提示
异构 KV 图 下半 State / tail 区:token 流在进 CSA 4:1 / HCA 128:1 之前,末尾不足一块的部分 不会 出现在 Classical 条带里。
{kind=link}
5. 相关阅读
| 文档 | 内容 |
|---|---|
| V4 KV Layout | Classical vs State 分工 |
| CSA / HCA 混合压缩注意力§4 | 五类对象对照表 |
← 返回 Engram 系列导读 · 答疑目录 · ← 中文导读 · ← 仓库首页(EN)
Engram 系列 · 答疑
主文档公式/推导类细节放本目录;engram-series-overview.md 只保留一行跳转。
| 主题 | 来源章节 | 答疑 |
|---|---|---|
| Step 6 门控依据 / 记忆依赖过滤 | §Step 6 | Step 6 上下文门控:依据与「记忆依赖过滤」 |
| HBM / DRAM / CXL.mem(L1–L3) | §CXL 三级存储 | L1 HBM / L2 DRAM / L3 CXL.mem:三级存储区别 |
| prefetch window / CPU vs GPU | §缓存访问逻辑 | Prefetch window:不是「CPU 比 GPU 强」,而是 CPU 先点火、GPU 腾出时间窗 |
| CXL vs RDMA 通信 pattern | §RDMA 对比 · 02c 图 | CXL vs RDMA:Engram 的两种「远程内存」通信 pattern |
| ③ Engram-Nine 热/冷 flip | §③ 核心发现 · 论文截图 | DeepSeek Engram 系列导读§③ |
| 为何选 CXL 而非 RDMA | §Step 1 时间窗 | 为何选 CXL 而非 RDMA? |
| Step 7 感受野扩充常数 | §Step 7 | Step 7 短卷积:感受野扩充常数 |
| RF 1→10 对训练/推理的影响 | §Step 7 | Step 7 感受野 1→10:训练与推理差异 |
| 记忆过滤在哪一步? | §Step 1–8 总表 | 01c 前向图 + Step 6 门控说明 |
{kind=link}
{kind=link}
L1 HBM / L2 DRAM / L3 CXL.mem:三级存储区别
← 返回 §CXL 三级存储 · 硬件拓扑 02b · 访问时序 02c · prefetch window · CXL vs RDMA · 答疑目录
{kind=link}
问题
CXL 硬件拓扑图 里出现 L1 HBM、L2 Local DRAM、L3 CXL Pool——三者物理上是什么?在 Engram 部署里各放什么、差在哪?
结论
| HBM(L1) | Host DRAM(L2) | CXL.mem(L3) | |
|---|---|---|---|
| 物理位置 | 焊在 GPU 封装内 | CPU 插槽旁 主板内存条 | CXL 扩展内存卡,经 Switch 挂到 PCIe/CXL fabric |
| 谁直接访存 | GPU SM(最高带宽) | CPU;GPU 经 PCIe 间接读 | CPU / GPU 经 CXL 协议 load/store(像内存,不像网卡消息) |
| 典型容量 | 数十 GB / 卡 | TiB 级 / 节点 | 论文 256 GB/卡;多机池 4 TB / 8 机 |
| 延迟 | 最低(GPU 片上) | 本地 DRAM 级 | 论文:≈ 本地 DRAM(远好于小包 RDMA) |
| 带宽特点 | 极高(TB/s 级),容量瓶颈 | 高,按节点私有 | 交换机聚合 512 GB/s;多机共享一份表 |
| Engram 放什么 | MoE/Attn 权重、hidden、gate/conv 小参数、prefetch staging | 热 embedding 缓存、CPU offsets[]、bounce buffer、CXL 的 mmap 窗口 | 完整 Engram embedding 大表(只读、DAX mmap) |
| 大表能否全放下 | ❌ 装不下百亿参数表 | ⚠️ 单机可放一部分;多机各拷一份贵 | ✅ 机架级共享一份 |
一句话:HBM = GPU 算力旁边的小而快内存;DRAM = CPU 旁边的大内存(可当中间缓存);CXL.mem = 用内存语义挂在 fabric 上的超大扩展池,专扛 Engram 只读大表 + 多机共享。
1. 三种介质分别是什么
HBM
- 是什么:与 GPU die 2.5D/3D 封装的专用 DRAM 栈(如 H100 上的 HBM2e/HBM3)。
- 特点:带宽极高、延迟最低,但 每卡只有几十 GB~百余 GB,且 只有 GPU 能高效用。
- 类比:GPU 的「工作台台面」——算子权重、激活、临时 buffer 必须在这儿才能跑满算力。
Host DRAM
- 是什么:服务器主板上 DDR4/DDR5 内存条,CPU 通过内存控制器访问。
- 特点:容量 比 HBM 大一个数量级以上(单节点可达 TB),延迟低,但 GPU 访问要经过 PCIe(除非 pinned + DMA)。
- Engram 语境:奠基论文把大表 offload 到 Host DRAM,异步 prefetch 进 HBM,吞吐损失 <3%;CXL 论文里 L2 还可做 Zipf 热 n-gram 缓存,命中则不必每次打到 L3。
CXL.mem
- 是什么:符合 CXL.mem 协议的 扩展内存设备(内存语义设备),经 CXL Adapter + Switch 接到 CPU/GPU 同一 fabric。
- 与「普通 DRAM」的区别:
- 不在 主板 DIMM 槽里,而是 扩展卡 / 池化设备;
- 多主机可通过 Switch 映射到各自地址空间,共享物理一份数据(Engram 表只读,无需 cache coherence);
- 软件用 DAX + mmap:
cxl_base + offset[i]按 cache line 细粒度 load/store,适合 Engram 5 KB×多段离散小读。 - 与 RDMA 池的区别:RDMA 是 消息式 远端读写,小包效率差;CXL 是 字节寻址内存,延迟接近 DRAM(见 CXL 论文 Figure 3/5/6)。
2. Engram 三级分层
CXL 论文 Figure 4 把部署抽象为三层(与 02b 拓扑图 一致):
L3 CXL Pool 完整 embedding 表(只读,多机一份)
| prefetch / memcpy
L2 Host DRAM 热缓存、CPU 算 offsets、可选中转
| DMA / P2P
L1 GPU HBM staging e_t -> W_K,W_V, gate, conv -> 写回 H
| 步骤 | 典型位置 | 说明 |
|---|---|---|
| [ | hash / offsets | CPU + L2 |
| 读表 | L3(未命中热缓存时) | 离散小读;可 overlap 前层 GPU 计算 |
| 热命中 | L2 或 L1 缓存 | Zipf:高频 n-gram 不必每次访问 L3 |
| gate / conv / Attn | L1 HBM | 需要 $h_t$,必须在 GPU |
数据通路:
- CXL → CPU:OpenMP 并行
memcpy(延迟 ≈ DRAM) - CXL → GPU(推荐):
cxl2vram_copyP2P,离散 embedding 直进 HBM staging
详见 02c 访问时序。
3. 为什么 Engram 需要三层,而不是「全放 HBM」
- 表太大:百亿参数级 embedding 放不进 HBM;全复制到每机 DRAM 贵且浪费。
- 访问又小又碎:每 token 每层约 5 KB、多段随机读——适合 内存语义细粒度读,不适合 RDMA 小包风暴。
- 索引可提前算:与 GPU 算力 overlap prefetch(~56 μs 窗口 / 层,见 overview §②)。
- 多机推理:L3 共享一份表 + L2/L1 热缓存,比每节点 DRAM 全副本更省。
4. 和「奠基论文只用 DRAM offload」的关系
| 阶段 | 存储 |
|---|---|
| Engram ①(2601.07372) | 大表 offload 到 Host DRAM,PCIe prefetch 到 HBM |
| CXL Pooling ②(2603.10087) | 表升级到 L3 CXL 共享池;L2 热缓存 + L1 staging 逻辑 不变 |
CXL 论文结论:端到端吞吐 CXL ≈ DRAM(如 Qwen3-4B 1.2% 损失),成本上多机大表更优。
5. 速查:该把什么放在哪
| 数据 | 推荐层级 |
|---|---|
| Transformer / MoE 权重 | L1 HBM |
| 当前 hidden、KV(若在本机) | L1 HBM |
| Engram gate / ShortConv 参数 | L1 HBM(小) |
| prefetch 到的 $e_t$ / embedding 行 | L1 staging |
| 高频 embedding 缓存 | L2(可选 L1 更小缓存) |
| 完整 Engram 表 | L3 CXL(或单机时 L2 DRAM) |
hash offsets[] 计算 | CPU(不占 HBM 算力) |
参考
- DeepSeek Engram 系列导读§② 三级存储
- engram-02b-cxl-hardware-topology.svg
- engram-02c-cxl-cache-access.svg
- engram-01d-multi-head-hash.svg — CPU/GPU 分界
- CXL 论文 arXiv:2603.10087 · CXL 论文 PDF
{kind=link}
Prefetch window:不是「CPU 比 GPU 强」,而是 CPU 先点火、GPU 腾出时间窗
← 返回 §prefetch window · 02c 时序图 · L1–L3 存储 · CXL vs RDMA · 答疑目录
问题
02c 图 右侧 prefetch window 和左侧绿色 Step 0/1(CPU) 连在一起——是不是 prefetch 放在 CPU 上比 GPU 更强?为什么?
结论
不是。 Prefetch window 不是一块「放在 CPU 上的内存」,而是 一段时间:
$$ \text{window} = \sum_{i=1}^{k-1} t_{\mathrm{exec}}^{\mathrm{GPU}}(i) $$
即:Engram 插在 第 $k$ 层 时,GPU 先算 Layer $0 \ldots k-1$ 的这段时间,用来 并行 把 Layer $k$ 要的 embedding 从 CXL 拉到 HBM staging。
| 角色 | 做什么 | 「强」在哪 |
|---|---|---|
| CPU(Step 0–1) | 用 token IDs 算 offsets[];SGLang 异步发起 prefetch | 不必等 GPU hidden;decode 步一开始就点火,不占 SM |
| GPU(窗口主体) | 算 Layer $0..k-1$(Attn/MoE 等) | 用 算力时间 盖住 CXL 读延迟 |
| CXL / DMA(Step 2) | L3 → L1 staging(Path B P2P 推荐) | 与上两行 overlap,不是串在 GPU critical path 前面 |
所以图里绿色框多,是因为 「谁先能知道要读哪」在 CPU/host;不是说 CXL 数据通路 CPU 比 GPU 更快——Step 2 推荐仍是 CXL→GPU P2P(cxl2vram_copy)。
0. 基础概念:decode、Layer $k$、hidden、「更早做」
Decode是什么
LLM 推理分两段:
| 阶段 | 在干什么 | 一次 forward 处理多少新 token |
|---|---|---|
| Prefill | 吃进整段 prompt | 很多 token(整段并行) |
| Decode | 已生成回复后,每步只新来 1 个 token,再跑一遍模型 | 通常 1 个新 token / 步 |
Decode 步 = 每生成一个新 token 时触发的 一次完整前向(从 Layer 0 一直算到最后一层,再采样下一个 token)。
02c 图 标题 one Decode step 画的就是:这一步 里 Engram 怎么 prefetch。
Layer $k$、Layer $k-1$ 是什么
Transformer backbone 是一叠 相同结构的块,编号 $0,1,\ldots,L-1$(如 64 层)。
- Layer $k$:Engram 插在第 $k$ 块里 的那一层。
- Layer $k-1$:紧挨在它 上面 的一层(下标小 1),要先算完,才能得到喂给 Layer $k$ 的 hidden。
数据流(简化):
$$ h^{(0)} \xrightarrow{\text{Layer 0}} h^{(1)} \xrightarrow{\text{Layer 1}} h^{(2)} \xrightarrow{\text{Engram@2 + Attn + MoE}} \cdots $$
上标 $(\ell)$ 表示 第几层之后 的表示;$h^{(k-1)}$ 就是 Layer $k-1$ 算完以后 的向量。
Hidden是什么
- $h_t$:序列里 位置 $t$ 的 hidden 向量(一个长度为 $d$ 的向量),承载「读到当前 token 为止,模型内部的语境表示」。
- $h_t^{(\ell)}$:同一位置 $t$ 在 第 $\ell$ 层之后 的 hidden。
Attention、MoE 路由、Engram 门控 $\alpha_t$ 都要看 hidden(动态、依赖前文计算)。
对比:
| 量 | 依赖什么 | 何时可知 |
|---|---|---|
| n-gram / hash 索引 | input token IDs | decode 步 一开始 就有 |
| $h_t^{(\ell)}$ | 前面层 Attention/MoE 算出来 | Layer $\ell$ 算完之后 才有 |
「更早做」到底是多早
更早 = 相对「必须等 Layer $k-1$ 的 hidden 出来之后再决定读什么」。
Engram(可更早) — decode 步时间线:
时刻 T0 本步新 token 的 ID 已知(整段 input_ids 都在)
CPU:hash → offsets[](所有 Engram 层要读哪几行都定了)
CPU:SGLang 立刻异步向 CXL 发读请求 ← 「更早做」指这里
时刻 T0~T1 GPU 并行算 Layer 0, 1, …, k-1 ← prefetch window(藏 CXL 延迟)
‖ CXL 并行把 Layer k 要的 embedding 拉进 staging
时刻 T1 GPU 算 Layer k:staging 里已有 e_t,再 gate(h_t, …)
MoE(不能更早) — 路由要看 当前 hidden:
Layer k-1 算完 → 得到 h^{(k-1)} → 才知道选哪个 expert → 才能去读/算
所以 MoE 的「该激活谁」最早也要等到 $k-1$ 层结束;prefetch 有效窗口 $\approx 0$(相对 Engram 而言)。
「更早做」不是:
- ❌ 比 prefill 更早(prefill 是另一阶段;这里指 同一 decode 步内 相对层间依赖更早)
- ❌ CPU 比 GPU 算得快
- ✅ 在 GPU 还没算到 Layer $k-1$ 之前,仅凭 token IDs 就启动 CXL 读 Layer $k$ 的表项
和 Step 3 图的关系
01d 多头寻址图 CPU 区:$g_{t,n}\to\varphi\to z\to E[\cdot]$ 都只依赖 input → 所以能在 decode 步入口 在 CPU 完成,不必等 GPU hidden。
1. 先纠正两个常见误读
误读 A:「prefetch window = CPU 侧缓存」
- 正解:右侧竖条是 时间轴——蓝条 = GPU 在执行前面层;橙条 = 同一时刻 CXL 在拉 Layer $k$ 的数据。
- 条件 $L_{\mathrm{pool}} < \sum_{i=1}^{k-1} t_{\mathrm{exec}}(i)$ 说的是:池子读延迟 必须 小于 GPU 算完 $k-1$ 层的时间,读才能在 Layer $k$ 用到前完成。
误读 B:「Path A比 Path B更推荐」
02c 图 Step 2 同时画了:
| 通路 | 做法 | 论文态度 |
|---|---|---|
| A | CXL → CPU(OpenMP memcpy)→ 再进 GPU | 延迟 ≈ DRAM,可行 |
| B | CXL → GPU staging(PCIe P2P,cxl2vram_copy) | 推荐:绕过 CPU 搬运、少 launch 开销 |
绿色 path A 框 ≠ 「整体以 CPU 为准」;它是 数据搬运的备选路径。点火调度(Step 0–1)在 CPU/host;搬运终点仍是 L1 HBM staging。
2. 为什么 Step 0–1 必须在 CPU/host 侧
Engram 索引 只依赖 input token,因此:
- Decode 步入口 就知道 Layer $k$ 要读哪些
offset[i],不必等 Layer $k-1$ 的 hidden。 - CPU 并行算 hash / offsets 几乎不占 GPU;SGLang 可 立刻 向 CXL 发异步读。
- 若索引像 MoE 路由那样 依赖 $h_t$,则必须等前层算完才知道读什么 → prefetch 无法提前 → 有效窗口 $\approx 0$。
这就是「CPU 侧先算索引」对 prefetch 不可或缺——不是因为 CPU 算力比 GPU 强,而是因为 这件事本来就不该占 GPU,且可以极早做。
3. GPU 在 window 里做什么
没有 GPU 在前面层 实打实算 $t_{\mathrm{exec}}$,就没有窗口长度:
- Qwen3-32B 例:每步 $\approx 3.6,\mathrm{ms}$ / 64 层 → 每层 ~56 μs。
- Engram 若在 Layer 2:窗口只有 Layer 1 那一层 的时间 ≈ 56 μs。
- 这 56 μs 内必须完成 CXL 离散读 + 进 staging;故论文强调 CXL 近 DRAM 延迟,RDMA 小包不够(图右下角 why CXL not RDMA)。→ 完整推导
GPU 越强 / batch 越大 → 前面层越久 → 窗口越宽 → prefetch 越好藏。
4. 串起来:一次 decode 步时间线
t0 ForwardBatch 到达
CPU Step0: offsets[] = hash(token_ids) ← 不占用 GPU
CPU Step1: SGLang 异步发起 CXL read ← 目标 gpu_staging
t0..t1 GPU: Layer 0, 1, …, k-1 ← 这就是 prefetch window(蓝条)
‖ 并行
CXL: fetch layer-k embeddings ← 橙条(Step 2 Path B)
t1 GPU Layer k: staging 已有 e_t
Step3: W_K,W_V, gate, conv, 写回 H ← 必须在 HBM
「强」的是整套 overlap;CPU 负责 早、准地发起;GPU 负责 撑开时间窗 + 消费 staging。
5. 和「奠基论文 DRAM offload」一致
单机 Host DRAM offload 时逻辑相同:索引在 CPU 算、prefetch 与前几层 overlap,只是 L3 换成 L2 DRAM。CXL 论文把 L3 换成共享池,window 机制不变。
6. 一图对照 02c
| 02c 元素 | 含义 |
|---|---|
| 绿圈 Step 0–1 | Host/CPU 编排(索引 + 异步触发) |
| 黄框 L3 | CXL 池里离散 320B 行 |
| 绿框 path A | 可选:经 CPU memcpy |
| 蓝框 L1 staging | GPU HBM 终点 |
| 虚线 P2P preferred | 推荐 直读 CXL→GPU |
| 右侧 window | GPU 算 0..k-1 的时间 ‖ CXL 拉 k |
参考
- DeepSeek Engram 系列导读§缓存访问逻辑
- engram-02c-cxl-cache-access.svg
- L1 HBM / L2 DRAM / L3 CXL.mem:三级存储区别
- CXL 论文 §3.2 时间窗不等式 · arXiv:2603.10087
CXL vs RDMA:Engram 的两种「远程内存」通信 pattern
← 返回 §RDMA 对比 · 02c 时序图(已标注) · L1–L3 存储 · 为何选 CXL 非 RDMA · prefetch window · 答疑目录
问题
02c 图 右下角 communication pattern 里 CXL 与 RDMA 各指什么通信方式?和主流程 Step 2 的箭头如何对应?
结论
| CXL pattern(Engram 用) | RDMA pattern(KV 池 / Mooncake 类) | |
|---|---|---|
| 语义 | 内存 load/store(像读本地 DRAM) | 消息 get/put(像网络 RPC) |
| 寻址 | mmap(cxl_base) + offset[i] 字节地址 | 远端对象句柄 + 显式请求 |
| 粒度 | cache-line / 数百字节 随机读 | 适合 MB–GB 大块 |
| 典型路径 | L3 CXL → PCIe P2P → GPU staging(或经 CPU memcpy) | GPU → host bounce → NIC RDMA → 远端 DRAM |
| Engram 5KB×多段离散读 | 延迟 ≈ DRAM,可塞进 ~56 μs 窗口 | 小包效率差,延迟 远高于 DRAM |
02c 主流程画的是 CXL;灰色 RDMA pool 面板是 对比参照(同一需求若走 RDMA 为何不行)。
→ 时间窗 + 56 μs 如何推出这一结论:为何选 CXL 而非 RDMA?
1. CXL pattern
是什么
CXL.mem 把扩展内存挂进 CPU/GPU 的 统一地址空间。进程 mmap 后,读 embedding 就是 ordinary load/store:
cxl_ptr = mmap(DAX device)
row = load(cxl_ptr + offset[i]) // 离散 320B 行
在 02c 上标在哪
| 图元素 | pattern |
|---|---|
| 黄框 L3 CXL Pool | mmap: cxl_base+offset[i] · CXL.mem: load/store |
| 橙色虚线 path B | CXL load/store + PCIe P2P(推荐) |
| 绿框 path A | CXL→CPU OpenMP memcpy,再进 GPU |
| 蓝框 L1 staging | cxl2vram_copy 终点 |
| 右侧橙条 CXL: fetch @ layer k | 与 GPU 算 0..k-1 并行 的 CXL 读 |
不是发「请给我第 i 行」的网络消息,而是 CPU/GPU DMA 直接按地址读。
2. RDMA pattern
是什么
RDMA 内存池:GPU/CPU 通过 NIC 对远端内存发 get/put:
put(remote_buf, local_chunk) // 消息式
get(local_buf, remote_handle) // 需 NIC 参与、常经 bounce buffer
面向 大块、连续 传输(整段 KV cache);对 Engram 这种 每 token 每层 ~5 KB、16 段离散 320B 访问:
- 大量 小包 → 带宽利用率低
- 软件栈 + NIC 延迟 → 远高于本地 DRAM,填不进 56 μs prefetch 窗
在 02c 上标在哪
| 图元素 | pattern |
|---|---|
| 右下灰框 RDMA pool (KV-style) | get/put · GPU→bounce→NIC→remote |
| 小示意图 GPU—NIC—remote | 不走 主流程 Step 2 |
| 文 many 320B pkts | too slow here | 与 Engram 访问形态不匹配 |
主流程 没有 RDMA 箭头——故意表示 Engram 不选这条 pattern。
3. 为何 Engram 要标清两者
- 延迟预算:Layer 2 的 prefetch 窗 ≈ 56 μs → 需要 近 DRAM 的 CXL,RDMA 不够。
- 访问形态:离散小行读 → load/store 自然;RDMA 消息 开销过大。
- 多机共享:CXL Switch 硬件映射 同一 L3 池;RDMA 也能共享,但 语义不同、延迟曲线不同。
奠基论文在 Host DRAM offload 已验证 prefetch;CXL 论文把 L3 换成 共享 CXL 池,通信 pattern 从「本地 DRAM load/store」换成「CXL load/store」,而不是换成 RDMA。
4. 与三级存储的对应
见 L1 HBM / L2 DRAM / L3 CXL.mem:三级存储区别:
- CXL pattern 发生在 L3 → L1(Step 2)
- RDMA pattern 是另一种「远端内存」产品形态,不落在 Engram 02c 主路径上
参考
- DeepSeek Engram 系列导读§与 RDMA 池对比
- engram-02c-cxl-cache-access.svg
- CXL 论文 Figure 2a vs 2b · arXiv:2603.10087
为何选 CXL 而非 RDMA?
← 返回 §Step 1 时间窗 · 02c 图 · CXL vs RDMA pattern · 答疑目录
先澄清
Engram CXL 论文选的是 CXL,不是 RDMA。
overview 里「这是选 CXL 而非 RDMA 的核心原因」= 解释 为什么不走 RDMA 内存池(Mooncake 类 KV offload 路径),而要用 CXL.mem load/store。
若问「为啥选 RDMA」→ 在 Engram 大表 + 离散小读 + ~56 μs prefetch 窗 这个场景下 不选;RDMA 仍适合 KV cache 大块传输 等别的 workload。
问题
Step 1 里的时间窗不等式
$$ L_{\mathrm{pool}}(N_{\mathrm{token}}, S_{\mathrm{layer}}) < \sum_{i=1}^{k-1} t_{\mathrm{exec}}(i) $$
和「Layer 2 仅 ~56 μs」如何推出 必须 CXL、不能 RDMA?
结论
| 约束来源 | 含义 |
|---|---|
| 时间窗 | Engram 在 Layer $k$,只允许在 GPU 算 Layer $1..k-1$ 的这段时间里,把本层要的 embedding 从 内存池 拉进 HBM staging |
| $L_{\mathrm{pool}}$ | 一次 decode 步、一层 Engram,从池子完成 所有离散读 的端到端延迟 |
| 56 μs 例 | Qwen3-32B:$k=2$ 时窗口 $\approx$ 单层时间 $\approx 56,\mu\mathrm{s}$ |
| CXL | $L_{\mathrm{pool}}$ ≈ 本地 DRAM 量级→ 不等式可满足 |
| RDMA | 离散 320B×多段 + NIC/消息栈 → $L_{\mathrm{pool}}$ 远高于 DRAM → 56 μs 内完不成 |
根因两条:① 延迟预算太紧(早层 Engram);② 访问形态是大量小随机读,不是 RDMA 擅长的大块 get/put。
1. 时间窗从哪来
一次 decode 步:
- CPU 在步入口就算好
offsets[](只依赖 token IDs)。 - SGLang 异步 prefetch Layer $k$ 的 Engram 行。
- GPU 同时算 Layer $0,1,\ldots,k-1$。
- 进入 Layer $k$ 时,staging 里 必须已有 $e_t$。
因此池子读延迟 $L_{\mathrm{pool}}$ 必须小于前面层的 GPU 时间之和:
$$ L_{\mathrm{pool}} < t_{\mathrm{exec}}(1) + \cdots + t_{\mathrm{exec}}(k-1) = \sum_{i=1}^{k-1} t_{\mathrm{exec}}(i) $$
02c 图 右侧蓝条 = 右边求和;橙条 = $L_{\mathrm{pool}}$ 必须落在蓝条长度以内。
2. Qwen3-32B 的 56 μs 怎么算
| 量 | 值 |
|---|---|
| 每 decode 步总时间 $t_{\mathrm{step}}$ | $\approx 3.6,\mathrm{ms}$ |
| 层数 | 64 |
| 单层平均 $t_{\mathrm{exec}}(i)$ | $3.6/64 \approx 56,\mu\mathrm{s}$ |
| Engram 插在 $k=2$ | 窗口 = $t_{\mathrm{exec}}(1) \approx$ 56 μs |
| Engram 插在 $k=15$ | 窗口 = $\sum_{i=1}^{14} t_{\mathrm{exec}}(i) \approx 14\times 56 \approx 0.78,\mathrm{ms}$(宽裕得多) |
最苛刻的是最早插入层(如 Layer 2):几乎只有 一层 的 GPU 时间来藏 CXL 读 → 池子延迟必须 接近 DRAM,不能是「慢一个数量级的网络内存」。
3. 为何 RDMA 过不了这个窗
3.1 延迟:消息栈 vs load/store
| CXL | RDMA 池 | |
|---|---|---|
| 语义 | mmap 后 load/store | get/put 请求/响应 |
| 软件路径 | 用户态直接寻址 + DMA | bounce buffer、NIC、远端处理 |
| 论文测量 | CXL→CPU ≈ DRAM;CXL→GPU 略高仍可接受 | 离散小包延迟 数量级高于 DRAM(Fig 3) |
在 56 μs 预算里,RDMA 一次或多次 round-trip 的固定开销往往就把窗口吃光,更别说 16 段×320B 级别的多段读。
3.2 粒度:5 KB×离散 vs MB–GB 块
Engram 每层每 token:
- 载荷 $\approx$ 5 KB(多阶 n-gram × 多头 × 320B/行)
- 稀疏离散 随机行读
RDMA 池为 KV cache offload 优化:大块、连续 传输效率高;64B~数百字节级海量小包 时:
- 带宽利用率可跌至峰值 ~25% 以下(overview §② 动机)
- 每次 get/put 有固定成本 → $L_{\mathrm{pool}}$ 随段数恶化
CXL 用 cache-line 级 load/store,与「随机抽很多小行」匹配。
3.3 带宽不是瓶颈
论文算过:所需池带宽 $\approx T \times S_{\mathrm{layer}} \times N_{\mathrm{eng}} \approx 0.7,\mathrm{GB/s}$,PCIe Gen5 / 百 G 网卡都够。
卡的是延迟形态,不是峰值 GB/s——所以「RDMA 带宽也很大」不能替代 CXL。
4. 为何 CXL 能过
- 内存语义:
cxl_base + offset[i]按地址读,无 per-chunk 消息。 - 实测延迟:CXL→CPU ≈ DRAM;CXL→GPU P2P 略高仍 < 56 μs 级窗口。
- 端到端:Qwen3-4B DRAM 5683.7 vs CXL 5614.4 tok/s(~1.2% 损),说明换 CXL 池 几乎不掉吞吐。
- 多机:Switch 映射共享 L3,仍保持 load/store 延迟曲线,而非 RDMA 小包曲线。
5. RDMA 适合什么
| Workload | 更合适的技术 |
|---|---|
| KV cache 大块 offload / 跨机共享 | RDMA 池(Mooncake 等) |
| Engram embedding 表 离散小读 + 紧 prefetch 窗 | CXL.mem |
| 单机 Host DRAM 表 | 奠基论文:DRAM + PCIe prefetch(无 CXL 硬件时) |
同一推理栈里可以 KV 用 RDMA、Engram 用 CXL——争的是 不同访问形态,不是二选一谁更强。
6. 决策链
Engram 索引只依赖 input ids
-> decode 步入口即可 prefetch
-> 有效窗口 = sum t_exec(1..k-1) [有时仅 ~56 μs]
-> 需要 L_pool ≈ DRAM
-> CXL load/store 满足;RDMA get/put 不满足
-> 选 CXL 池(Fig 2b),不选 RDMA 池(Fig 2a)
参考
- DeepSeek Engram 系列导读§Step 1
- DeepSeek Engram 系列导读§与 RDMA 对比
- CXL vs RDMA:Engram 的两种「远程内存」通信 pattern
- Prefetch window:不是「CPU 比 GPU 强」,而是 CPU 先点火、GPU 腾出时间窗
- CXL 论文 §3.2 时间窗、Figure 2a/2b/3 · arXiv:2603.10087
Step 6 上下文门控:依据与「记忆依赖过滤」
← 返回 Step 6 · 前向总图 01c · 答疑目录
问题
01c 前向图 里 Step 6 标成「过滤记忆」——门控 $\alpha_t$ 的设计依据是什么?为什么说 gate 是 记忆依赖 的过滤,而不是普通标量门?
结论
| 维度 | Step 1–5 | Step 6 门控 |
|---|---|---|
| $e_t$ / $k_t,v_t$ | 只依赖 input n-gram,与当前句义无关 | 用 $h_t$(语境)× $k_t$(本条记忆) 算 $\alpha_t$ |
| 输出 | 静态查表结果 | $\tilde{v}_t=\alpha_t v_t$:本条记忆留多少 |
| 角色 | O(1) 检索 | 动态过滤:碰撞 / 歧义 / 不合语境 → $\alpha_t\to 0$ |
依据:查表给的是「这个 n-gram 通常 伴随什么向量」,不是「此刻 该不该用」;必须用已含上下文的 $h_t$ 与 本条 记忆的 $k_t$ 做对齐,才能决定 $v_t$ 是否注入 backbone。这就是 记忆依赖——$\alpha_t$ 随 检索到的记忆内容(经 $W_K$)与 当前 hidden jointly 变化,而非每位置固定系数。
α_t 算「一次 Attention」吗?
可以说:像 Attention 的「一个 Q 对一个 K」的那一步;不能说:等于一层 Self-Attention。
| 标准 Attention(位置 $t$) | Engram Step 6 的 $\alpha_t$ | |
|---|---|---|
| Q·K | $\mathrm{softmax}_j\bigl(q_t^\top k_j\bigr)$,对 多个 $j$ 归一化 | 一个 $h_t$ 对 一条 $k_t$,无对 $j$ 的 softmax |
| 非线性 | softmax → 权重和为 1 | $\sigma(\cdot)$ → $\alpha_t\in(0,1)$,不要求与其他位置竞争 |
| V 聚合 | $\sum_j w_{t,j} v_j$ | 标量 $\alpha_t$ 只缩放 本条 $v_t$:$\tilde{v}_t=\alpha_t v_t$ |
| K/V 来源 | 同一 hidden 线性投影 | K/V 来自 查表 $e_t$ |
更贴切的说法:
- 是:一次 scaled dot-product 兼容性打分(Q=$h_t$,K=$k_t$),再乘 V=$v_t$ —— 和 Attention 核心算子同族。
- 不是:对序列 / 多记忆槽的 分布归一化注意力;没有「在 $L$ 个或 $K$ 个头里选谁」那一步(多头哈希的 $K$ 个头已在 Step 4 拼进 $e_t$,Step 6 是对整段 $e_t$ 投影后的 一个 门)。
口诀:「单键 attention 打分 + sigmoid 门」,不是 「一层 multi-head self-attention」。后面 backbone 里的 Attention 仍负责全局依赖;Step 6 只决定 这条静态记忆此刻放多少进来。
1. 为什么 Step 1–5 不能代替门控
Step 1–4 产出 上下文无关 的 $e_t$:
$$ e_t = \Big\Vert_{n,k} E_{n,k}[\varphi_{n,k}(g_{t,n})] $$
索引 $\varphi_{n,k}(g_{t,n})$ 只依赖 input token,因此:
- 哈希碰撞:不同 n-gram 映射到同一槽位 → 表项是混合先验,未必对应当前片段。
- 多义 / 歧义:同一表面 n-gram 在不同句子里语义不同(图脚注「Apple vs apple」类问题在 Step 1 部分缓解,但不能消歧整句)。
- 静态先验 vs 动态需求:$e_t$ 回答「历史上这个搭配常出现什么表示」,不回答「这一句 现在是否需要这条先验」。
Step 5 把 $e_t$ 投影为 $k_t, v_t$,仍 未使用 $h_t$——只是「把记忆装进 K/V 形态」,还没有过滤(01c 图:备过滤)。
2. 门控在算什么
论文 / overview 写法:
$$ \alpha_t = \sigma\left(\frac{\mathrm{RMSNorm}(h_t)^{\top} \mathrm{RMSNorm}(k_t)}{\sqrt{d}}\right), \quad \tilde{v}_t = \alpha_t \cdot v_t $$
| 角色 | 张量 | 语义 |
|---|---|---|
| Query | $h_t$ | 当前层 hidden,已吸收前文 Attention / 下层信息 → 此刻语境 |
| Key | $k_t = W_K e_t$ | 本条 查表记忆在「对齐空间」的表示 |
| Value | $v_t = W_V e_t$ | 若通过门控,实际写入记忆支路的内容 |
| 门 | $\alpha_t \in (0,1)$ | $h_t$ 与 $k_t$ 越一致 越大;不合 → 趋近 0 |
与 Attention 相同点:用归一化 Q·K 衡量 兼容性(scaled dot product)。
与 Attention 不同点:
| Attention | Engram Step 6 | |
|---|---|---|
| K/V 来源 | 由 hidden 算出来 | K/V 来自 查表 $e_t$(O(1)) |
| 范围 | 可对全序列做 softmax | 标量 $\alpha_t$ 门控本条记忆(非全局分布) |
| 计算 | $O(L^2)$ 或稀疏变体 | 查表 O(1) + 一次 dot + sigmoid |
本质:Attention 式对齐,但 记忆是条件查表来的,所以叫 context-aware gating / 记忆过滤。
3. 为何叫「记忆依赖」的过滤
「记忆依赖」指 $\alpha_t$ 不是 只由位置 $t$ 或只由 $h_t$ 决定,而是 耦合本条检索结果:
$$ \alpha_t = f\bigl(h_t,; k_t(e_t(g_{t,\cdot}))\bigr) $$
- 换一句 input → $g_{t,n}$ 变 → $e_t$ 变 → $k_t, v_t$ 变 → 即使 $h_t$ 维数相同,$\alpha_t$ 也可完全不同。
- 同一句里不同层 / 不同分支:$h_t$ 变 → 对 同一条 $e_t$ 也可得到不同 $\alpha_t$(语境变了,是否采纳这条静态先验也变)。
因此 gate 过滤的是 「这一条记忆」对当前语境的贡献,不是对 hidden 做通道级 LayerScale 那种与查表无关的门。
为何乘在 $v_t$ 上:注入 backbone 的是 value 支路;$k_t$ 只参与 是否放行,$v_t$ 是 放行后的内容。Step 7–8 只在 $\tilde{v}_t$ 上运算(01c 图例:S7–8 不再接触未过滤 $v_t$)。
4. 官方 demo 实现
Engram demo 脚本 中 Engram.forward(约 L358–377):
key = self.key_projs[hc_idx](embeddings)
normed_key = self.norm1[hc_idx](key)
query = hidden_states[:, :, hc_idx, :]
normed_query = self.norm2[hc_idx](query)
gate = (normed_key * normed_query).sum(dim=-1) / math.sqrt(hidden_size)
gate = gate.abs().clamp_min(1e-6).sqrt() * gate.sign() # demo 额外:保符号的 sqrt
gate = gate.sigmoid().unsqueeze(-1)
value = gates * self.value_proj(embeddings).unsqueeze(2)
| 项 | demo | overview 公式 |
|---|---|---|
| 归一化 | norm1 on key,norm2 on query | $\mathrm{RMSNorm}(k_t)$,$\mathrm{RMSNorm}(h_t)$ |
| 对齐分数 | 逐维积再 sum = 内积 | $h_t^\top k_t$ |
| 缩放 | / sqrt(hidden_size) | `/ sqrt{d}$ |
| 非线性 | signed_sqrt 再 sigmoid | 直接 $\sigma(\cdot)$ |
| 多分支 | hc_mult 路独立 gate | overview §多分支有 $\alpha_t^{(m)}$ |
阅读建议:结构一致(normed Q·K → 门 → × value);demo 在 sigmoid 前多一步 signed sqrt,属实现细节,不改变「用 $h_t$ 与 本条 memory key 决定是否采用 $v_t$」这一设计。
5. 若去掉 Step 6 会怎样
| 有门控 | 无门控($\alpha_t\equiv 1$) |
|---|---|
| 碰撞 / 歧义表项可被压掉 | 噪声 $v_t$ 直接进 Conv / 残差 |
| 静态先验 按需 接入 | 所有 n-gram 查表结果 强制 影响 hidden |
| 与论文「条件记忆」一致 | 退化成「查表 + 固定加回」,难扛多义 |
Engram-Nine 等工作进一步讨论 gating credit assignment(门控是否跟对表项);瓶颈常在 门控质量 而非索引精度(见 overview §热冷层 / Nine 梗概)。
6. 与前后 Step 的衔接
S1–4: e_t 静态(input only)
S5: k_t, v_t = W_K e_t, W_V e_t ← 备过滤
S6: α_t = f(h_t, k_t); ṽ_t = α_t v_t ← ★ 记忆过滤
S7–8: 只用 ṽ,写回 H
→ 短卷积 / 感受野:Step 7 短卷积:感受野扩充常数(在 已过滤 的 $\tilde{V}$ 上扩序列混合)
参考
- DeepSeek Engram 系列导读§Step 5–6
- engram-01c-forward-dataflow.svg
- Engram demo 脚本 —
Engram.forward
← 返回 Engram 系列导读 · 答疑目录 · ← 中文导读 · ← 仓库首页(EN)
Step 7 感受野 1→10:训练与推理差异
先澄清:「10 倍」指什么
不是算力放大 10×,而是门控记忆流 $\tilde{V}$ 沿序列的有效依赖跨度 从 1 个位置 扩到 10 个 token 索引范围(默认 $w=4,d=3$)。
$$ \mathrm{RF}_{\mathrm{seq}}:\ 1 ;\rightarrow; 1+(w-1)d = 10 $$
影响总览

{kind=link}
1. 能力上差什么
| RF = 1(仅 Step 6) | RF = 10(Step 7 后) | |
|---|---|---|
| 每位置输入 | 仅 $\tilde{v}_t$ | $\tilde{v}t,\tilde{v}{t-3},\tilde{v}{t-6},\tilde{v}{t-9}$ |
| 表达 | 每 token 独立 的过滤记忆 | 跨位置组合 已过滤记忆 + SiLU 非线性 |
| 与 n-gram 关系 | 查表已见 2–3 token input | 在 记忆向量序列 上再对齐 n-gram 间隔 $d$ 做融合 |
| 仍不做的事 | — | 不替代 Attention(全局仍靠 Attn/MoE) |
直觉:Step 1–4 给每个位置一张「局部词典卡片」;Step 6 决定信不信;Step 7 把 间隔为 3 的多张卡片 合成一句更长的「记忆短语」,再写入 backbone。
2. 训练带来的差异
2.1 梯度与耦合
- RF=1:loss 对 $\tilde{v}_t$ 的梯度只回传到位置 $t$ 的 gate / 查表 / 投影。
- RF=10:$Y_t$ 的梯度经 depthwise Conv 同时回传 到 $t,t{-}3,t{-}6,t{-}9$ 四条记忆路径。
- 卷积权重 $W_{\mathrm{conv}}$ 可学习:模型学习「哪些间隔 3 的记忆组合有用」,而非硬编码拼接。
2.2 优化与表达
| 效应 | 说明 |
|---|---|
| 更强局部组合 | 超出单次 n-gram 槽位的 短语级 静态先验(仍局部) |
| 非线性 | SiLU(Conv(·)) 在残差旁路;纯线性叠加 $w=4$ 的表达能力有限 |
| 因果安全 | 因果卷积不看未来 token,训练/推理一致 |
| 序列前端 | $t<9$ 时有效 tap 变少(边界),与因果 LM 常见行为一致 |
2.3 训练成本
- 相对 Engram 查表 + gate:增量很小。
- Depthwise Conv1d:每 token 仅 $w=4$ 次 tap 乘加(按 channel 分组),与 $d_{\mathrm{model}}$ 线性,远低于同层 Attention。
- 反向:多 4 个历史位置的 gate/投影梯度,仍 $O(w)$ 常数。
3. 推理带来的差异
3.1 延迟与算力
| 项 | RF=1 | RF=10(有 Step 7) |
|---|---|---|
| 每 decode step 查表 | $O(1)$ / token | 不变 $O(1)$ |
| Gate | 1 次 / token | 不变 |
| 额外 Conv | 无 | $w=4$ tap depthwise,$O(w\cdot d_{\mathrm{hc}})$,常数级 |
| 相对 Attention | Engram 仍偏 memory-bound 查表 | Conv 通常 < 5% Engram 块(实现依赖) |
要点:跨度 10 不等于每步读 10 次表;只是卷积多读 3 个历史 $\tilde{v}$(间隔 3),计算量由 $w$ 决定,不由 10 决定。
3.2 状态与缓存
- Decode 需保留最近 $\tilde{v}$(至少 $t{-}9$)供 dilated conv 取用,或等价地保留 Conv 环形缓冲。
- 额外显存:$\approx 9 \times d_{\mathrm{mem}} \times \mathrm{sizeof}(\mathrm{fp})$ 每序列每 Engram 层,相对 KV cache 通常可忽略。
- Prefill:全长并行,与训练前向同构;仍无未来泄漏。
3.3 与 prefetch / offload 的关系
- n-gram 索引仍 只依赖 input ids(Step 3 前可算)→ prefetch 路径 不受 Step 7 影响。
- Step 7 只在 GPU 上融合 已算出的 $\tilde{V}$,不增加 CXL/表访问次数。
4. 若去掉 Step 7
| 训练 | 推理 | |
|---|---|---|
| 速度 | 略快(少一次 conv) | 略快 |
| 质量 | 每 token 记忆 解耦,难学短语级组合 | 输出更「逐 token 查表感」 |
| 与论文分工 | 削弱 Engram「局部静态搭配」路径 | Attention 负担可能上升 |
论文保留 Step 7 的原因:极便宜地 在记忆支路补上 跨位置局部非线性,把全局留给 Attention。
5. 一图速览

图示详情
{kind=link}
参考
- Step 7 短卷积:感受野扩充常数 — 公式与 tap 下标
- Engram demo 脚本 —
ShortConv,value + short_conv(value)
Step 7 短卷积:感受野扩充常数
← 返回 Step 7 · Step 6 门控专文 · 答疑目录
问题
Step 7 标题写「扩感受野」——是从 1 扩到 4 吗?$w=4$ 的 kernel 是否等于跨度 4?
结论
| 维度 | Step 6 之后 | Step 7 之后(默认 demo) |
|---|---|---|
| 门控记忆流 $\tilde{V}$ 沿序列 | 每位置独立,跨度 1 | 因果 dilated conv 混合,跨度 $1+(w-1)d$ |
| 默认 $w=4$,$d=\text{max_ngram_size}=3$ | — | $1+3\times 3=10$ |
$w=4$ 是卷积核 tap 个数,不是感受野跨度。
1. 两种「看过多远」不要混
A. 输入侧 n-gram 跨度
每个位置 $t$ 查表时,$e_t$ 已编码 后缀 2/3-gram,即最多 3 个 input token 的静态搭配。
这是 查表键的长度,不是门控记忆在序列维上的混合。
B. 门控记忆流沿序列的混合
Step 5–6 对每个 $t$ 独立算 $\tilde{v}_t$;在 $\tilde{V}$ 这条流上,位置 $t$ 在 Step 6 结束时 只依赖 $\tilde{v}t$,与 $\tilde{v}{t-1}$ 等无关 → 序列感受野 = 1。
Step 7 的因果 Conv1D 才在 $\tilde{v}$ 序列 上做局部融合。
2. 公式与代码参数
论文 / overview:Depthwise 因果 Conv1D,kernel $w$,dilation = 最大 n-gram 阶数 $N$。
官方 demo(Engram demo 脚本):
kernel_size = engram_cfg.kernel_size # 默认 4
dilation = engram_cfg.max_ngram_size # 默认 3
因果 dilated 一维卷积,位置 $t$ 的输出依赖的 tap 下标(向后看):
$$ t,; t-d,; t-2d,; \ldots,; t-(w-1)d $$
有效序列感受野(跨度):
$$ \boxed{\mathrm{RF}_{\mathrm{seq}} = 1 + (w-1),d} $$
默认:$\mathrm{RF}_{\mathrm{seq}} = 1 + 3\times 3 = 10$。
即 $Y_t$ 会用到 $\tilde{v}t,,\tilde{v}{t-3},,\tilde{v}{t-6},,\tilde{v}{t-9}$——间隔为 $d$ 的 4 个点,覆盖 10 个 token 索引范围,而非连续 4 个位置。
2.1 逐项看懂:谁在扩感受野?
公式 $Y=\mathrm{SiLU}(\mathrm{Conv1D}(\mathrm{RMSNorm}(\tilde{V})))+\tilde{V}$ 从左到右:
| 顺序 | 操作 | 对位置 $t$ 做了什么 | 序列感受野 |
|---|---|---|---|
| ① | RMSNorm | 只归一化 当前 $\tilde{v}_t$ 这个向量 | 仍为 1(不读邻居) |
| ② | Conv1D | 用 4 个可学习权重 把 $\tilde{v}{t-9},\tilde{v}{t-6},\tilde{v}_{t-3},\tilde{v}_t$ 加权求和 | 1 -> 10(只有这一步扩) |
| ③ | SiLU | 对卷积结果做非线性 | 不新增位置 |
| ④ | $+\tilde{V}$ | 把原始 $\tilde{v}_t$ 加回去(残差) | 不新增位置 |
「第一项」RMSNorm 不扩感受野;真正让 $t$ 看见 $t{-}3,t{-}6,t{-}9$ 的是 第二项 Conv1D。
为何跨度是 10 而不是 4?
- $w=4$ = 卷积 读 4 个点(4 个 tap)
- $d=3$ = 相邻 tap 间隔 3 个 token
- 最左 tap 在 $t{-}9$,最右在 $t$ → 索引覆盖 $t{-}9,\ldots,t$ 共 10 个位置
$$ \underbrace{t-9}{\text{tap 0}};\cdots; \underbrace{t-6}{\text{tap 1}};\cdots; \underbrace{t-3}{\text{tap 2}};\cdots; \underbrace{t}{\text{tap 3}} \quad\Rightarrow\quad \mathrm{RF}_{\mathrm{seq}} = t - (t-9) + 1 = 10 $$

图示详情
{kind=link}
3. 为何 dilation = max n-gram 阶数
直觉对齐:n-gram 查表已在 长度 $N$ 的 input 窗口上编码局部模式;短卷积用 相同间隔 $N$ 在门控后的记忆流上再混合,使序列方向的采样节奏与 n-gram 阶数一致。
4. 残差与 Step 8
$$ Y = \mathrm{SiLU}(\mathrm{Conv1D}(\mathrm{RMSNorm}(\tilde{V}))) + \tilde{V} $$
残差保证 $Y_t$ 至少保留 $\tilde{v}_t$;卷积分支提供跨位置的局部非线性。Step 8 将 $Y$ 残差写入 backbone,之后 Attention 再负责全局依赖。

图示详情
{kind=link}
5. 速查表
| 符号 | demo 默认 | 含义 |
|---|---|---|
| $w$ | 4 | Conv1d kernel_size |
| $d$ | 3 | dilation = max_ngram_size |
| $\mathrm{RF}_{\mathrm{seq}}$ | 10 | $1+(w-1)d$ |
| Step 6 序列 RF | 1 | 每 $t$ 仅 $\tilde{v}_t$ |
| n-gram input 跨度 | 2–3 | 查表键长,≠ 上式 RF |
→ 训练/推理差异:Step 7 感受野 1→10:训练与推理差异
图示详情
参考
- DeepSeek Engram 系列导读§Step 7
- Engram demo 脚本 —
ShortConv,EngramConfig.kernel_size,max_ngram_size