DeepSeek-R1 训练 Pipeline
← 中文导读 · ← RL 笔记索引 · ← 演进总览 §3.4 R1 · 《ds-技术报告》 论文:DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning arXiv:2501.12948 · PDF:DeepSeek-R1 论文 PDF 基座:DeepSeek-V3 Base

{kind=link}
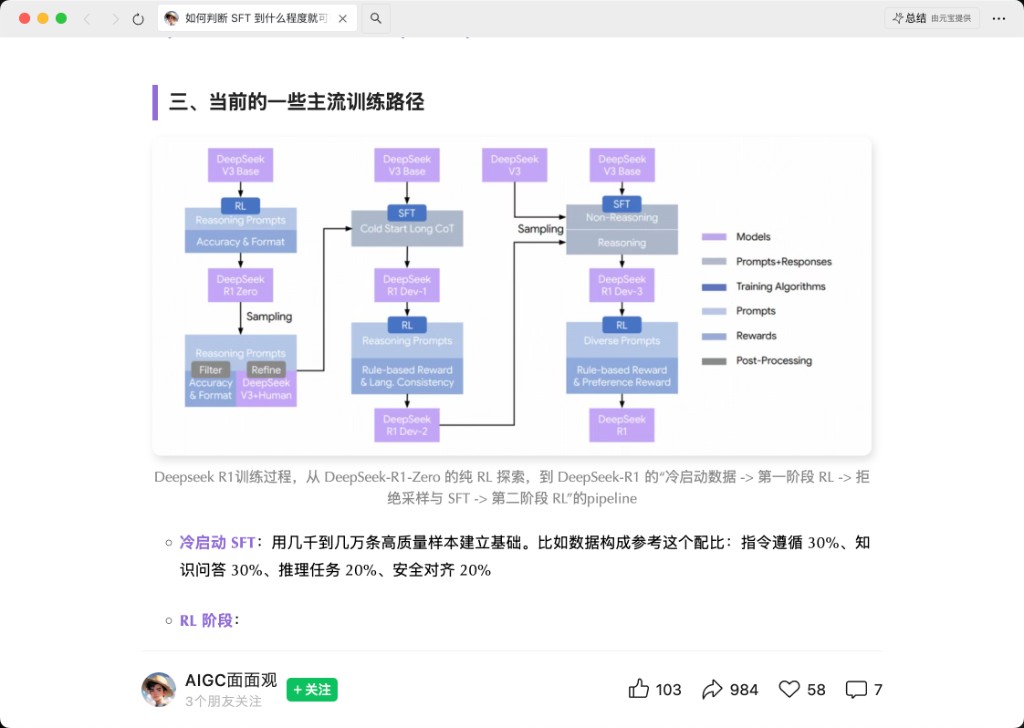
总览:两条支路
| 支路 | 产物 | 核心思想 |
|---|---|---|
| A. 纯 RL | DeepSeek-R1-Zero | 跳过 SFT,GRPO + 规则 reward,推理能力自发涌现 |
| B. 四阶段 | DeepSeek-R1 | 继承 R1-Zero 推理,补齐可读性、多语言能力、通用任务与对齐 |

{kind=link}
支路 A:DeepSeek-R1-Zero
输入 / 算法 / Reward
| 项 | 内容 |
|---|---|
| 起点 | DeepSeek-V3 Base |
| 算法 | GRPO(Group Relative Policy Optimization),无 critic,组内相对 advantage |
| Prompt | Reasoning prompts(数学/代码/逻辑) |
| Reward | Accuracy(答案对错,sympy 等规则验证)+ Format(`` 等格式约束) |
| 不用 | 神经 RM(防 reward hacking)、SFT 冷启动 |
涌现行为
- 响应长度随训练增长(「思考时间」增加)
- 自反思、验证、换策略
- 「Aha moment」:模型自发学会重新审视
局限
- 可读性差、中英混杂
- 偏推理,写作/开放域 QA 弱
支路 B:DeepSeek-R1 四阶段
中间 checkpoint:Dev-1 → Dev-2 → Dev-3 → R1
阶段 1:冷启动 SFT → R1 Dev-1
| 项 | 内容 |
|---|---|
| 数据 | 数千条 Cold Start Long CoT(高质量、对话式、第一人称思考) |
| 来源 | R1-Zero 高温采样 → 过滤正确+可读 → DeepSeek-V3 精炼 → 人工复核 |
| 目的 | 解决 R1-Zero 的语言混杂与表达问题;产品向可读 CoT |
| 数据配比(整理图参考) | 指令遵循 30% · 知识问答 30% · 推理 20% · 安全对齐 20% |
冷启动 CoT 风格要求:
- 先理解问题 → 详细推理 → 反思与验证
- 第一人称、段落简短、避免 markdown
- 语言与问题一致(V3 翻译 thinking 消混杂)
Trade-off:Dev-1 指令遵循↑(IF-Eval、ArenaHard),但冷启动数据小,AIME 等推理略降于 R1-Zero。
阶段 2:第一阶段 RL → R1 Dev-2
| 项 | 内容 |
|---|---|
| 算法 | GRPO |
| Prompt | Reasoning prompts |
| Reward | Rule-based(同 R1-Zero)+ Language Consistency(目标语言词占比) |
| 关键超参 | lr=3e-6,每题 16 rollout,max len 32768,clip ratio ε=10 |
Dev-2 推理能力恢复并超越 Dev-1(Table 3:AIME、Codeforces 等显著提升)。
阶段 3:拒绝采样 + SFT → R1 Dev-3
| 项 | 内容 |
|---|---|
| 数据总量 | ~800K SFT 样本 |
| Reasoning | ~600K:从 Dev-2 checkpoint 拒绝采样(多采样、只留正确);扩展生成式 RM(V3 判对错);过滤混杂语言/长段落/代码块 |
| Non-Reasoning | ~200K:写作、事实 QA、翻译、自认知、软件工程等(复用 V3 SFT 管线);简单 query 不加 CoT |
| 域分布 | Math 395K · Code 211K · General 178K · STEM 10K · Logic 10K(Table 5) |
后处理链:

{kind=link}
Dev-3 在推理与通用(MMLU、IF-Eval)上进一步平衡。
阶段 4:第二阶段 RL → DeepSeek-R1
| 项 | 内容 |
|---|---|
| Prompt | Diverse prompts(推理 + 通用) |
| Reward | $R = R_{\text{reasoning}}^{\text{rule}} + R_{\text{general}}^{\text{RM}} + R_{\text{language}}$ |
| RM | Helpful RM(66K 偏好对,只看 summary)+ Safety RM(106K 点式安全标注) |
| 训练 | 共 1700 steps;最后 400 steps 才加入通用指令与偏好 RM(防 reward hacking) |
| 温度 | 0.7(比一阶段低,防incoherent) |
最终 R1:推理保持 + helpful & harmless 对齐。
各阶段指标快照
| Benchmark | R1-Zero | Dev-1 | Dev-2 | Dev-3 | R1 |
|---|---|---|---|---|---|
| AIME 2024 | 71.0 | 59.3 | 73.3 | 76.7 | 79.8 |
| MMLU | 88.8 | 89.1 | 91.2 | 91.0 | 90.8 |
| IF-Eval | 46.6 | 71.7 | 72.0 | 78.1 | 83.3 |
| LiveCodeBench | 50.0 | 57.5 | 63.5 | 65.9 | 65.9 |
| ArenaHard | 53.6 | 77.0 | 73.2 | 75.6 | 92.3 |
与 OneReason / LoRA 系列对照
| 维度 | DeepSeek-R1 | OneReason |
|---|---|---|
| 领域 | 通用 LLM 推理 | 生成式推荐 |
| 纯 RL 探索 | R1-Zero | 无直接对应 |
| 分阶段 RL | 两阶段 + 不同 reward | specialize-then-unify(分域 GRPO) |
| 拒绝采样 SFT | 800K 混合数据 | RFT 路径 |
| 冷启动 | 数千 Long CoT | R0–R3 分层 SFT |
蒸馏
DeepSeek-R1 还将长 CoT 能力 蒸馏到小模型(Qwen/Llama 等),开源 R1 系列 checkpoint。
文件索引
| 文件 | 说明 |
|---|---|
| 版本演进总览 §3.4 R1 | 全系列时间线中的 R1 定位 |
| DeepSeek-R1 训练 Pipeline | 本文 |
| R1 训练管线流程图 | 自绘流程图 |
| R1 训练管线参考图 | 外部参考图 |
| DeepSeek-R1 论文 PDF | 原文 |