DeepSeek-LLM V1
← 中文导读 · ← 仓库首页(EN) · ← 演进总览 §3.1 · ← 版本目录 · BBPE 词表专文 · V1→V3 演进 原文:DeepSeek LLM: Scaling Open-Source Language Models with Longtermism · arXiv:2401.02954 PDF:2401.02954.pdf · 图件见 Scaling Laws 图件 · BBPE 词表专文
命名说明:论文与社区常称 DeepSeek-LLM 或 DeepSeek V1;与后续 DeepSeek-V2 / V3(MoE + MLA 旗舰线)是不同架构代际,但构成同一产品线的早期稠密基座。
摘要
开源大语言模型(LLM)近年来发展迅猛,但既往文献中的 scaling laws 结论各异,给 LLM 规模化扩展蒙上了阴影。本文深入研究 scaling laws,并给出适用于两种主流开源配置(7B 与 67B)的独到发现。在 scaling laws 指导下,我们推出 DeepSeek LLM——一项以长期主义推进开源语言模型的工程。
预训练阶段我们构建了目前约 2 万亿 tokens、持续扩充的数据集;并对 Base 模型进行 监督微调(SFT) 与 直接偏好优化(DPO),得到 Chat 模型。评测表明:DeepSeek LLM 67B 在多项 benchmark 上超越 LLaMA-2 70B,尤其在代码、数学与推理领域;开放评测中,DeepSeek LLM 67B Chat 表现优于 GPT-3.5。
1. 引言
基于 decoder-only Transformer 的 LLM 已成为通向 AGI 的核心路径。通过下一词预测在大规模语料上自监督预训练,模型获得创作、摘要、代码补全等能力;SFT 与奖励建模使其更好遵循用户意图,对话能力迅速扩展。
ChatGPT、Claude、Bard 等闭源产品以巨大算力与标注成本拉高社区对开源 LLM 的期望。LLaMA 系列整合多项工作,形成高效稳定架构(7B–70B),成为开源模型的 de facto 基准。
然而开源社区在 LLaMA 之后多聚焦于固定尺寸(7B/13B/34B/70B)的高质量训练,较少系统研究 scaling laws。早期工作(Chinchilla、Kaplan 等)对模型/数据随算力扩展的最优分配结论不一致,对超参讨论也不充分。
本文工作:
- 研究 batch size 与 learning rate 的 scaling laws;
- 系统研究 模型与数据规模 的 scaling laws,揭示最优分配策略并预测大模型性能;
- 发现 不同数据集 拟合出的 scaling laws 差异显著——数据选择会明显影响 scaling 行为,跨数据集泛化 scaling laws 需谨慎。
在 scaling laws 指导下,我们从零训练并尽可能开源信息:
- 2T tokens 预训练语料,以中英文为主;
- 架构大体遵循 LLaMA,但用 multi-step LR 替代 cosine,便于 continual training;
- 150 万+ SFT 实例;并采用 DPO 提升对话表现。
DeepSeek LLM 67B 在代码/数学/推理上超越 LLaMA-2 70B;67B Chat 在中英文开放评测上优于 GPT-3.5;安全评测表明 67B Chat 在实践中可给出无害回复。
2. 预训练
2.1 数据
目标:全面提升数据丰富度与多样性。参考 The Pile、RedPajama、FineWeb、LLaMA 等来源,流程分三阶段:
| 阶段 | 作用 |
|---|---|
| 去重(deduplication) | 跨 dump 全局去重,保证样本唯一性 |
| 过滤(filtering) | 语言与语义质量评估,提高信息密度 |
| 重混(remixing) | 提升低占比 domain,平衡多样性 |
去重:对 Common Crawl 全语料去重,效果远优于单 dump 内去重。91 个 dump 跨库去重率达 89.8%,单 dump 仅 22.2%(Table 1)。
Tokenizer — 完整解读见 BBPE 词表与 Tokenizer 专文(§2.1 论文段落;V2 沿用同词表):
| 项 | 值 | 专文 |
|---|---|---|
| 算法 | BBPE(Byte-level BPE;BPE 简述) | HuggingFace tokenizers |
| 预分词 | 换行 / 标点 / CJK 不跨类 merge(同 GPT-2) | 避免中英混排边界错误 |
| 数字 | 拆成 单 digit(同 LLaMA) | 算术、代码、编号更稳 |
| 常规 + special | 100,000 + 15 → 100,015 | §4 词表规模 |
| BBPE 训练语料 | ~24GB 多语言 | 来自上述三阶段管线子集 |
vocab_size(embedding) | 102,400(预留扩展) | 有效 id 仍以 100,015 为准;见专文 易混点 |

图示详情 · 详述见 BBPE 专文 §2
2.2 架构
Table 2 — DeepSeek LLM 规格
| 7B | 67B | |
|---|---|---|
| 层数 | 30 | 95 |
| d_model | 4096 | 8192 |
| n_heads | 32 | 64 |
| n_kv_heads | 32 (MHA) | 8 (GQA) |
| 上下文 | 4096 | 4096 |
| 序列 batch | 2304 | 4608 |
| 学习率 | 4.2e-4 | 3.2e-4 |
| 预训练 tokens | 2.0T | 2.0T |
同 D、不同 M → 不同 $C$;2T 是产品统一语料,非 Formula 4 compute-optimal 要求(7B 相对 ~140B 最优属 over-train)。详见 产品训练与 Scaling Law。
微观设计:
- Pre-Norm + RMSNorm
- FFN:SwiGLU,中间维 8/3 × d_model
- 位置编码:RoPE
- 67B 使用 GQA 降低推理成本
宏观设计:
- 7B:30 层;67B:95 层(在参数量与其他开源模型可比的前提下,便于 pipeline 划分)
- 与常见 GQA 模型加宽 FFN 不同,67B 加深网络而非加宽 FFN,以追求更好性能
2.3 超参数
- 初始化 std = 0.006
- AdamW:β1=0.9, β2=0.95, weight_decay=0.1
- Multi-step LR(非 cosine):
- Warmup 2000 steps 至最大 LR
- 80% tokens 后降至最大值的 31.6%
- 90% tokens 后降至 10%
- 梯度裁剪:1.0
Multi-step vs Cosine:1.6B 模型、100B tokens 上,最终性能基本一致;multi-step 在扩大训练规模时可复用第一阶段 checkpoint,便于 continual training。三阶段 token 比例选 80% / 10% / 10% 以平衡复用与性能。
原理详解、公式与 LLaMA cosine 对比 → 学习率调度 Wiki
Batch size 与 LR 随模型规模变化,见 Table 2。
2.4 基础设施
- 并行:数据并行 + 张量并行 + 序列并行 + 1F1B 流水线并行
- Flash Attention
- ZeRO-1 分片 optimizer states
- 计算/通信 overlap(ZeRO-1 reduce-scatter、序列并行 all-gather 等)
- 算子融合:LayerNorm、GEMM、Adam update
- bf16 训练 + fp32 梯度累积
- In-place cross-entropy(kernel 内 bf16→fp32,降低显存)
- 每 5 分钟 异步 checkpoint;支持换 3D 并行配置 resume
- 评测:vLLM(生成任务);continuous batching(非生成)
3. Scaling Laws
算力预算 $C$、模型规模 $N$、数据规模 $D$:传统近似 $C \approx 6ND$。核心问题:算力增加时如何最优分配模型与数据。
答疑:为何改用 $C=M\cdot D$? — $6N_1$/$6N_2$ 相对 $M$ 的误差(Table 3)、IsoFLOP 为何必须用 $M$
早期工作对最优分配结论不一,且超参是否达最优存疑。本文:
- 先研究超参 scaling laws(batch、LR);
- 用 M(non-embedding FLOPs/token) 替代 N,用 C = MD 替代 C = 6ND;
- 发现数据质量影响最优 model/data 分配。
3.1 超参 Scaling Laws
小算力($C=10^{17}$ FLOPs,177M FLOPs/token)网格搜索:batch 与 LR 在较宽范围内 generalization error 稳定(Figure 2a)。

Figure 2 — batch × LR 网格搜索(上:$C=10^{17}$;下:$C=10^{20}$ 验证)
来源:Figure 2。(a) 小算力下 batch/LR 宽带稳定;(b) $10^{20}$ 验证时拟合点(红星)落在最优区中心。
用 multi-step LR 训练多组模型(算力 $10^{17}$–$2\times10^{19}$),复用第一阶段。将 generalization error 超出最小值 ≤0.25% 的参数视为 near-optimal,拟合得 Formula 1:
$$ \begin{aligned} \eta_{\mathrm{opt}} &= 0.3118 \cdot C^{-0.1250} \ B_{\mathrm{opt}} &= 0.2920 \cdot C^{0.3271} \end{aligned} $$
| 符号 | 含义 |
|---|---|
| $C$ | 训练算力预算(FLOPs),$C = M \cdot D$ |
| $\eta_{\mathrm{opt}}$ | 最优学习率(最大 LR) |
| $B_{\mathrm{opt}}$ | 最优 batch size,单位 tokens/step(非序列条数) |
Formula 1 数值对照:
| $C$ | $B_{\mathrm{opt}}$ | $\eta_{\mathrm{opt}}$ | 备注 |
|---|---|---|---|
| $10^{17}$ | 0.11M tok/step | $2.34\times10^{-3}$ | 小算力拟合区 |
| $10^{18}$ | 0.23M tok/step | $1.75\times10^{-3}$ | |
| $10^{19}$ | 0.48M tok/step | $1.31\times10^{-3}$ | |
| $10^{20}$ | 1.02M tok/step | $9.86\times10^{-4}$ | 1e20 验证点(Figure 2b) |
| $8.5\times10^{22}$ | 9.22M tok/step | $4.25\times10^{-4}$ | DeepSeek 7B @ 2T |
- 算力 ↑ → $B_{\mathrm{opt}}$ ↑,$\eta_{\mathrm{opt}}$ ↓
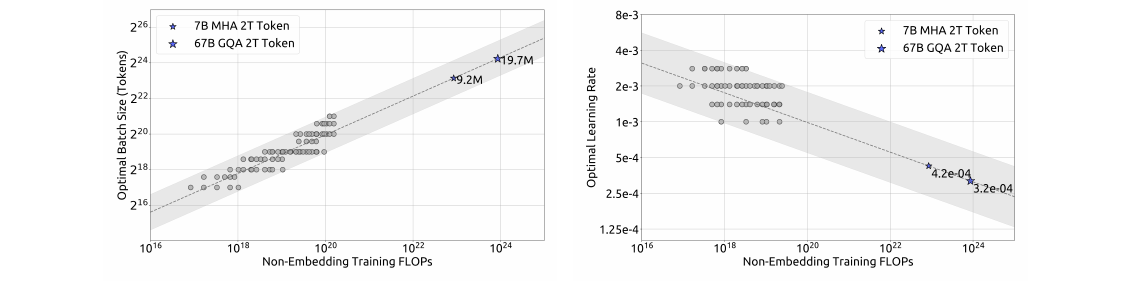
- 7B/67B 实测点落在 near-optimal 带内;$10^{20}$ 验证时拟合参数位于最优区中心(Figure 2b)
局限:尚未建模 $C$ 以外因素;同算力不同 model/data 分配下最优超参空间略有差异——待后续研究。→ Scaling-Law 选择性应用 §3
3.2 最优模型/数据 Scaling
传统写法用 $C \approx 6ND$,其中模型规模 $N$ 有两种常见取法:
| 符号 | 含义 | 来源 |
|---|---|---|
| $N_1$ | non-embedding 参数量 | Kaplan et al. |
| $N_2$ | 完整参数量(含 embedding) | Hoffmann et al. / Chinchilla |
于是可用 $6N_1$ 或 $6N_2$ 近似「每 token 算力」。但两者都有明显误差:
- $6N_1$:不含 attention 的 $O(L^2)$ 计算开销;
- $6N_2$:多了 vocab 投影(对模型能力贡献小),仍不含 attention。
为此报告引入 $M$(non-embedding FLOPs/token):计入 attention,不计 vocab;算力预算简化为 $C = M \cdot D$。
Formula 2 — 三种表示的关系:
$$ \begin{aligned} 6N_1 &= 72 \cdot n_{\mathrm{layer}} \cdot d_{\mathrm{model}}^2 \ 6N_2 &= 72 \cdot n_{\mathrm{layer}} \cdot d_{\mathrm{model}}^2 + 6 \cdot n_{\mathrm{vocab}} \cdot d_{\mathrm{model}} \ M &= 72 \cdot n_{\mathrm{layer}} \cdot d_{\mathrm{model}}^2 + 12 \cdot n_{\mathrm{layer}} \cdot d_{\mathrm{model}} \cdot l_{\mathrm{seq}} \end{aligned} $$
| 符号 | 含义 |
|---|---|
| $n_{\mathrm{layer}}$ | 层数 |
| $d_{\mathrm{model}}$ | 模型宽度 |
| $n_{\mathrm{vocab}}$ | 词表大小(V1 配置 102,400,见 BBPE 专文 §4) |
| $l_{\mathrm{seq}}$ | 序列长度 |
Table 3 — 不同规模下 $6N_1$、$6N_2$ 相对 $M$ 的偏差($n_{\mathrm{vocab}}=102400$,$l_{\mathrm{seq}}=4096$):
| $n_{\mathrm{layer}}$ | $d_{\mathrm{model}}$ | $N_1$ | $N_2$ | $M$ | $6N_1/M$ | $6N_2/M$ |
|---|---|---|---|---|---|---|
| 8 | 512 | 25.2M | 77.6M | 352M | 0.43 | 1.32 |
| 12 | 768 | 84.9M | 164M | 963M | 0.53 | 1.02 |
| 24 | 1024 | 302M | 407M | 3.02B | 0.60 | 0.81 |
| 24 | 2048 | 1.21B | 1.42B | 9.66B | 0.75 | 0.88 |
| 32 | 4096 | 6.44B | 6.86B | 45.1B | 0.85 | 0.91 |
| 40 | 5120 | 12.6B | 13.1B | 85.6B | 0.88 | 0.92 |
| 80 | 8192 | 64.4B | 65.3B | 419B | 0.92 | 0.94 |
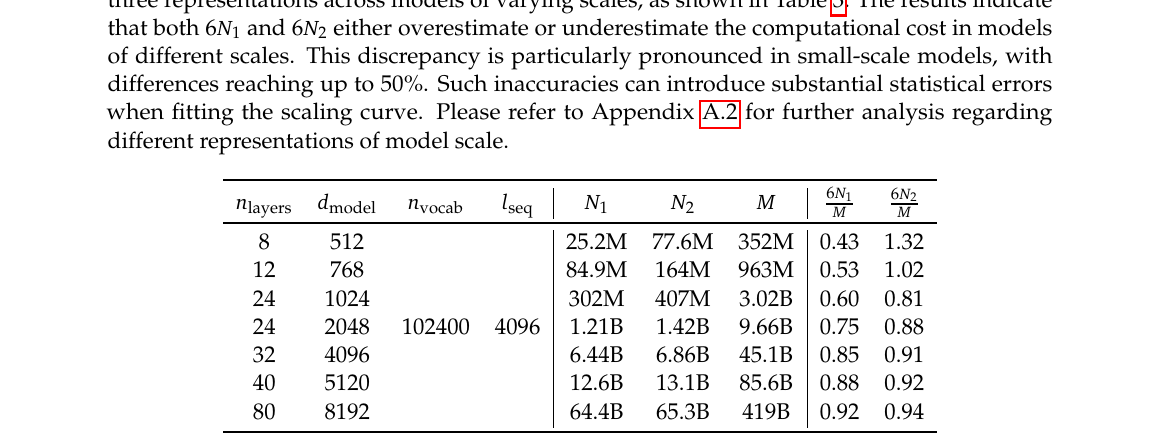
Table 3 — 模型规模三种表示的差异($N_1$、$N_2$ 相对 $M$ 的偏差)
来源:Table 3。右两列 $6N_1/M$、$6N_2/M$ 越偏离 1,用 $6N$ 近似 $M$ 的误差越大。
怎么读 Table 3:
- $6N_1/M < 1$(小模型仅 0.43):$6N_1$ 低估算力,因缺 attention 项;层数少、$d$ 小时最明显。
- $6N_2/M > 1$(小模型 1.32):$6N_2$ 高估算力,因计入 vocab 投影。
- 模型变大后两列趋近 1,但小模型上偏差仍可达 50%,会污染 IsoFLOP 拟合——故 Formula 4 统一用 $M$ 而非 $6N_1$/$6N_2$。
采用 IsoFLOP profile(Chinchilla):8 个算力预算($10^{17}$–$3\times10^{20}$),每预算约 10 种 model/data 分配;超参由 Formula 1 确定;在 100M tokens 独立验证集上算 generalization error(bits-per-byte)。
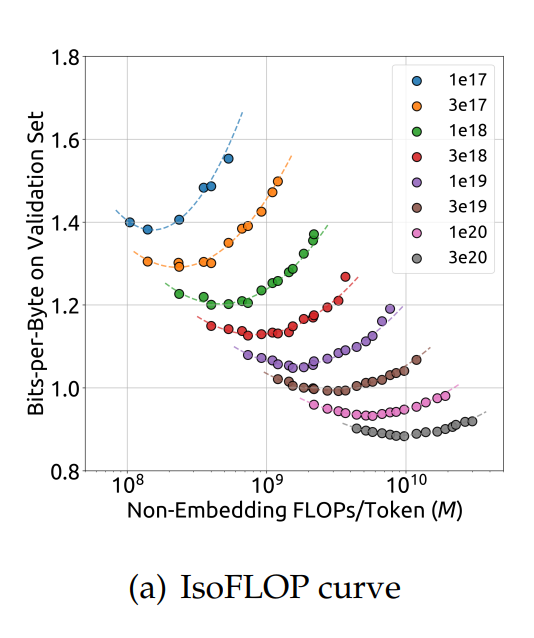
Figure 4a — IsoFLOP 曲线(各算力档 loss 随 $M$ 呈 U 形,谷底 = 最优分配)
来源:Figure 4a。横轴 = non-embedding FLOPs/token $M$;纵轴 = validation bits-per-byte。
Formula 4 — 最优 model/data 分配:
$$ \begin{aligned} M_{\mathrm{opt}} &= 0.1715 \cdot C^{0.5243} \ D_{\mathrm{opt}} &= 5.8316 \cdot C^{0.4757} \end{aligned} $$
| 符号 | 含义 |
|---|---|
| $M_{\mathrm{opt}}$ | 最优 non-embedding FLOPs/token |
| $D_{\mathrm{opt}}$ | 最优训练 token 总量 |
→ 模型与数据规模随算力近似等比扩展(指数 $a \approx b \approx 0.5$)。
Formula 4 数值对照:
| $C$ | $M_{\mathrm{opt}}$ (FLOPs/tok) | $D_{\mathrm{opt}}$ | 备注 |
|---|---|---|---|
| $10^{17}$ | $1.4\times10^{8}$ | 0.71B | |
| $10^{18}$ | $4.7\times10^{8}$ | 2.1B | |
| $10^{19}$ | $1.6\times10^{9}$ | 6.4B | |
| $10^{20}$ | $5.3\times10^{9}$ | 19B | |
| $8.5\times10^{22}$ | $4.2\times10^{10}$ | 2.0T | DeepSeek 7B @ 2T |
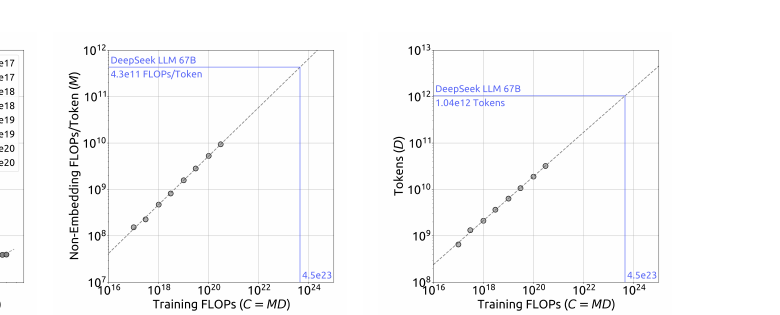
Figure 4b/4c — 最优 model / data scaling
来源:Figure 4b/4c。左:$M_{\mathrm{opt}}$ vs $C$;右:$D_{\mathrm{opt}}$ vs $C$。
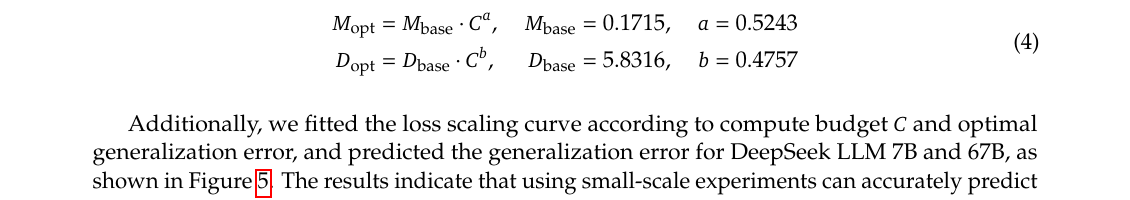
Figure 5 — 性能 scaling 曲线(小实验预测 7B/67B)
来源:Figure 5。灰点 = 小算力实验;虚线 = loss 幂律拟合;蓝星 = DeepSeek LLM 7B / 67B(各 2T tokens)。
小实验可准确预测 1000× 算力下 7B/67B 性能。
读图提示:Figure 3/5 蓝星 = 给定产品 $(M,D=2T)$ 校验 hyperparam / loss;Figure 4 = 固定 $C$ 下最优 $M/D$ 分配(未用于 Table 2 定 2T)。详见 Scaling-Law 选择性应用。
3.3 不同数据上的 Scaling Laws
DeepSeek LLM 开发过程中语料迭代多轮:调整各数据源占比、提升整体质量。借此可分析数据集差异对 scaling laws 的影响。
在三种语料上分别拟合 Formula 4 的指数 $a$($M_{\mathrm{opt}} \propto C^a$)与 $b$($D_{\mathrm{opt}} \propto C^b$):
- 早期内部数据 vs 当前内部数据(质量逐步提升)
- OpenWebText2(Kaplan et al. 用过的公开集;规模较小、处理更精细,质量甚至高于当前内部数据)
Table 4 — 模型/数据 scaling 系数随训练数据分布而变:
| 数据集 | 模型指数 $a$ | 数据指数 $b$ |
|---|---|---|
| OpenAI OpenWebText2 | 0.73 | 0.27 |
| Chinchilla MassiveText | 0.49 | 0.51 |
| Ours 早期 | 0.450 | 0.550 |
| Ours 当前 | 0.524 | 0.476 |
| Ours on OpenWebText2 | 0.578 | 0.422 |
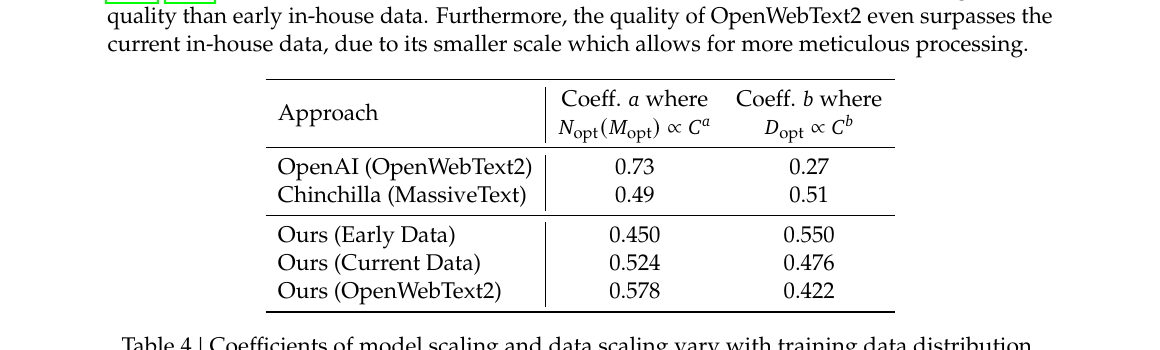
Table 4 — 模型/数据 scaling 系数随训练数据分布而变
来源:Table 4。$a$ 越大 → 算力应多投模型;$b$ 越大 → 算力应多投数据。
数据质量越高 → $a$ 越大、$b$ 越小 → 应多分配算力给模型扩展。高质量数据逻辑清晰、充分训练后预测难度低,扩大模型更有利。不同数据集的 scaling 指数差异也可作为数据质量间接指标——这或许也是早期 scaling law 研究结论不一致的原因之一。
4. 对齐
4.1 数据
约 150 万 中英 instruction 实例:
- Helpful(120 万):通用 31.2% / 数学 46.6% / 代码 22.2%
- Safety(30 万):各类敏感话题
4.2 SFT
| 7B | 67B | |
|---|---|---|
| Epochs | 4 | 2(67B 过拟合严重) |
| LR | 1e-5 | 5e-6 |
- 7B:GSM8K、HumanEval 持续提升;67B 很快触顶
- 监控 repetition ratio:3868 条中英 prompt,统计无法终止、无限重复的比例
- 数学 SFT 增多 → repetition ratio 上升(推理模式相似,弱模型难学)
- 缓解:两阶段 SFT(第二阶段去掉 math/code)或 DPO
7B 两阶段 SFT:stage-1 repetition 2.0% → stage-2 1.4%
4.3 DPO
- 基于 helpfulness / harmlessness 构建 preference 数据
- Helpful:多语言 prompt(创作、QA、指令遵循等),用 DeepSeek Chat 生成候选回复
- 1 epoch,LR 5e-6,batch 512,warmup + cosine LR
- 效果:增强开放域生成;标准 benchmark 变化不大
5. 评测
5.1 公开 Benchmark
数据集覆盖:
- 多选:MMLU, C-Eval, CMMLU
- 语言理解/推理:HellaSwag, PIQA, ARC, OpenBookQA, BBH
- 闭卷 QA:TriviaQA, NaturalQuestions
- 阅读:RACE, DROP, C3
- 指代:WinoGrande, CLUEWSC
- LM:Pile
- 中文:CHID, CCPM
- 数学:GSM8K, MATH, CMath
- 代码:HumanEval, MBPP
- 考试:AGIEval
评测方式:
| 方式 | 适用任务 |
|---|---|
| Perplexity 选题 | HellaSwag, MMLU, C-Eval 等多选题 |
| 生成式(greedy) | GSM8K, HumanEval, BBH 等 |
| LM(bits-per-byte) | Pile-test |
最大序列长度 2048 或 4096。
5.1.1 Base 模型
- 2T 双语预训练,英文理解与 2T 英文 LLaMA-2 相当
- 67B 在 MATH、GSM8K、HumanEval、MBPP、BBH、中文 benchmark 上显著优于 LLaMA-2 70B
- 67B 相对 LLaMA-2 70B 的优势 大于 7B 相对 7B——语言冲突对小模型影响更大
- LLaMA-2 在部分中文任务(如 CMath)表现不错——数学推理可跨语言迁移;但 CHID(成语)等需足够中文 tokens
5.1.2 Chat 模型
- SFT 后多数任务提升
- 知识类(TriviaQA, MMLU):小幅波动,不代表 SFT 增删知识;Chat 0-shot 可比 Base 5-shot
- 推理类:SFT 含 CoT 格式,BBH 等略升——主要是学会推理格式而非新推理能力
- 下降任务:HellaSwag 等完形/句补——纯 LM 更擅长
- 数学/代码:HumanEval、GSM8K 等提升 20+ 点——Base 在这些任务上欠拟合,SFT 补充知识;能力可能偏代码补全与代数题
5.2 开放评测
5.2.1 中文 — AlignBench
683 题,8 大类 36 小类;GPT-4 按参考答案与模板打分。
- DeepSeek 67B Chat 超越 ChatGPT 等基线,仅次于两版 GPT-4
- DPO 版几乎全面提升
- 中文基础语言:DPO 版甚至高于最新 GPT-4;中文推理:显著领先其他中文 LLM
5.2.2 英文 — MT-Bench
8 类多轮对话。
- 67B Chat:8.35,与 GPT-3.5-turbo 可比;超越 LLaMA-2-Chat 70B、Xwin 70B、TÜLU 2+DPO 70B
- 67B Chat-DPO:8.76,仅次于 GPT-4
5.3 Held-Out 评测
在独立 held-out 集上 bits-per-byte 与 scaling 预测一致,验证 scaling laws 有效性。
5.4 安全评测
20 人专家团队,覆盖歧视偏见、侵犯合法权益、违法犯罪等类别。
- 多数子类 >95% 无害回复率(如歧视类 486/500,侵权类 473/500)
- 安全贯穿预训练、SFT、DPO 全流程
5.5 讨论
- 避免 benchmark decoration 与训练「暗箱」
- 双语训练在代码/数学/推理上的优势随规模放大
- SFT 数据配比(尤其数学)需与模型容量匹配
6. 结论、局限与未来工作
结论
DeepSeek LLM 是在 2T 中英 tokens 上从零训练的开源系列。本文详述超参选择、scaling laws 与微调经验;校准既往 scaling laws,提出新的最优 model/data 分配策略;给出给定算力下 near-optimal batch/LR 的预测方法;并指出 scaling laws 与数据质量相关——可能是不同工作 scaling 行为差异的根因。在 scaling laws 指导下完成预训练与全面评测。
局限
- Chat 模型无预训练后持续知识更新
- 可能生成非事实内容、幻觉
- 初版中文数据不 exhaustive,部分中文话题表现欠佳
- 语料以中英为主,其他语言需谨慎使用
未来
- 发布代码智能与 MoE 技术报告(高质量代码预训练数据、稀疏架构达稠密性能)
- 构建更大更好数据集,提升推理、中文知识、数学、代码
- 对齐团队研究 helpful/honest/safe;初步实验表明 RL 可提升复杂推理
附录概要
| 附录 | 内容 |
|---|---|
| A.1 | 致谢 |
| A.2 | 不同模型规模表示(N1/N2/M)分析 |
| A.3 | Benchmark 指标随训练曲线 |
| A.4 | 与代码/数学专用模型对比 |
| A.5 | DPO 阶段 benchmark 结果 |
| A.6 | 各 benchmark 评测格式细节 |
相关文档
- 版本演进总览 · 《ds-技术报告》§3.1 V1
- BBPE 词表与 Tokenizer 专文(§2.1 Tokenizer;预分词 / 102,400 embedding)
- V1→V3 演进
- Scaling 专题(本仓答疑)
- 产品训练 vs Scaling Law:7B/67B 为何都训 2T?
- Scaling-Law 选择性应用(Figure 3/4/5 分工)
- Scaling 答疑(Formula 1/4 推导)
- 学习率调度(§2.3 multi-step vs cosine)
- 中文结构化译文
- 技术要点提炼
- 索引
- 英文原文
- H20 八卡 Scaling Law 实验设计(Figure 3 / Formula 4 / Figure 5 拟合配置)