DeepSeek 版本演进:V1 → V3 → V3.2 → V4,Index Share 与 KV-offload
更新:2026-06-25 ← 中文导读 · ← 仓库首页(EN) · V1→V3 前代演进
1. 总览
DeepSeek 开源主线分两段:
- V1 → V2 → V3(2024):稠密双语基座 → MLA + MoE → 671B 旗舰(详见 V1→V3 演进)
- V3 之后(2025–2026):R1 / V3.1 / V3.2 / V4 与 infra 补丁
V3 发布后的 Attention / KV infra 与全系列的 MoE 可概括为三条线:
- 算法线:MLA → DSA 稀疏注意力 → CSA/HCA 混合压缩注意力 + mHC
- 基础设施线:标准 MLA KV cache → Indexer/Latent 异构 cache → Index Share → ESS offload → V4 异构 KV + HiSparse
- MoE 线:稠密 FFN → DeepSeekMoE → aux-loss-free 路由 + $L_{\mathrm{Bal}}$ → Hash MoE + FP4
1.1 各工作优化方向分类
下列 §3 版本 与 §4–§6 infra 中的每一项工作,按三条正交优化轴归类。多轴并存时给出 比例(合计 100%);单列 100 表示该工作主要落在此轴。
| 轴 | 含义 | 典型内容 |
|---|---|---|
| 模型 | 权重、数据、对齐与后训练 | scaling laws(答疑)、词表、SFT/DPO / RL(R1)、Hybrid 能力、checkpoint 规模 |
| 架构-train | 为训练改结构或训推系统 | MoE 路由(DeepSeekMoE)、MTP 辅助头、mHC、Muon、FP8 训推数值、DSA / CSA 等需重训的算子 |
| 架构-infer | 为推理改结构或纯 infer 补丁 | MLA latent KV、Prefill/Decode 模式切换、DSA 异构 cache、Index Share、ESS、DSpark、HiSparse |

版本 / 工作一览:
| 工作 | 模型 % | 架构-train % | 架构-infer % | 产出机构 | 发表时间 | 说明 |
|---|---|---|---|---|---|---|
| V1 scaling / BBPE / SFT·DPO | 100 | — | — | DeepSeek | 2024-01 | 数据管线、词表、对齐(SFT/DPO);结构为常规模型 |
| MLA(V2 起) | — | 40 | 60 | DeepSeek | 2024-05 | 低秩 KV;训推同构,显存/吞吐收益主要在 infer |
| DeepSeekMoE(V2 起) | — | 45 | 55 | DeepSeek | 2024-05 | 稀疏 FFN;路由在训推两阶段共用 |
| V3 aux-loss-free + 256/8 MoE | — | 50 | 50 | DeepSeek | 2024-12 | 去 aux loss、sigmoid 路由、专家池扩容 |
| V3 MTP | — | 70 | 30 | DeepSeek | 2024-12 | 辅助训练目标;推理可接原生投机 |
| V3 FP8 动态量化 | — | 100 | — | DeepSeek | 2024-12 | 预训练数值与吞吐;非 Transformer 拓扑 |
| R1 RLVR / GRPO | 100 | — | — | DeepSeek | 2025-01 | 与 V3 同架构;差异全在后训练 |
| V3.1 Hybrid / Agent | 80 | — | 20 | DeepSeek | 2025-中 | post-train 能力;同一权重切换 thinking/chat |
| V3.1-T MLA Prefill MHA / Decode MQA | — | — | 100 | DeepSeek | 2025 | 同权重;仅推理路径 MHA↔MQA 间切换 |
| V3.2 DSA | — | 35 | 65 | DeepSeek | 2025-12 | Lightning Indexer + 异构 cache;长上下文 infer 主战场(Exp 2025-09) |
| Index Share | — | — | 100 | 清华 + 智谱 | 2026-03 | 跨层复用 top-$k$ index |
| ESS Latent offload | — | — | 100 | 百度百舸 | 2025-12 | 仅 Latent-Cache CPU 分层;与 DSA 算法正交 |
| V4 CSA / HCA | — | 30 | 70 | DeepSeek | 2026 | 压缩 KV 序列;1M context 算力与 cache 主因 |
| V4 mHC | — | 55 | 45 | DeepSeek | 2025-12 | 残差双随机流形;训推均改前向图(V4 落地 2026) |
| V4 Muon | — | 100 | — | DeepSeek | 2026 | 优化器替换,加速收敛 |
| V4 Hash MoE + FP4 | — | 55 | 45 | DeepSeek | 2026 | Hash 路由与 FP4 权重量化 |
| DSpark | — | — | 100 | DeepSeek | 2026-06 | V4 线上投机解码;基线 MTP-1;不改基座 |
| V4 HiSparse / 异构 KV offload | — | — | 100 | DeepSeek(layout)+ Together 等 | 2026-05 | C4 inactive entry、磁盘 prefix;纯 infer 内存层级 |
| FlashMLA / DeepGEMM indexer | — | — | 100 | DeepSeek | 2025 | Kernel 实现;承载 MLA / DSA 算子(§6) |
| Visual Primitives MLLM | 60 | 25 | 15 | DeepSeek-AI | 2026 | V4-Flash + ViT;visual primitives CoT;CSA 压视觉 KV(§3.8) |
版本级粗汇总:
| 版本 | 模型 % | 架构-train % | 架构-infer % | 发表时间 | 相对上一版主叙事 |
|---|---|---|---|---|---|
| V1 | 100 | — | — | 2024-01 | 系列首篇;scaling + 双语 |
| V2 | 10 | 45 | 45 | 2024-05 | 首次 MLA + MoE |
| V3 | 15 | 55 | 30 | 2024-12 | MoE 路由 + MTP + 671B 规模 |
| R1 | 100 | — | — | 2025-01 | 纯后训练 |
| V3.1 / Terminus | 75 | — | 25 | 2025-中 | Hybrid + MLA 模式切换 |
| V3.2 | — | 35 | 65 | 2025-12 | 唯一架构改动 = DSA |
| V4(基座) | — | 40 | 60 | 2026 | CSA/HCA/mHC/MoE/Muon 打包 |
| V4 + DSpark(线上) | — | — | 100† | 2026-06 | † 相对已训好的 V4 checkpoint 的 decode 补丁 |
读法:Index Share、ESS、DSpark 等 100% 架构-infer 的工作,与「改权重」的 V3.2 DSA、V4 CSA 可叠加部署;§5 KV-offload 三代与 §6 推理栈是 infer 轴的进一步展开。
1.2 Transformer 四模块演进
Raschka 第三方解读 §8 · 表 8-1 将 Transformer 拆成四条正交演进链;下表映射到本仓库版本节点(非 exhaustive,仅 DeepSeek 主线):
| 模块 | 行业演进链 | DeepSeek 落点 |
|---|---|---|
| Normalization | LayerNorm → RMSNorm → Dynamic TanH | V1–V4:RMSNorm(Pre-Norm) |
| Attention | GQA → sliding window(SWA) → MLA → sparse (DSA) → CSA/HCA | MLA → DSA → CSA/HCA · V4 另含 SWA 局部精确 KV |
| FFN | GeLU → SwiGLU → MoE | DeepSeekMoE → aux-loss-free → Hash MoE + FP4 |
| 残差 | 恒等(ResNet) → Hyper-Connections → mHC | HC → mHC(V4 落地) |
读法:V3.2 的「唯一结构改动」几乎全在 Attention 轴(DSA);V4 同时在 Attention(CSA/HCA)、残差(mHC)、FFN(Hash MoE)三轴打包升级;后训练(R1 RLVR)与 infer 补丁(Index Share / ESS / DSpark)不改变模块拓扑,见 §1.1。
延伸:Raschka 全文 §8 · mHC 专文 §1

2. 版本时间线与关系

图 2 补充:V1 · V2 · MLA · DeepSeekMoE · aux-loss-free · RLVR · DSA · Index Share · ESS · V4 · DSpark · mHC · 优化方向分类 §1.1 各节代表图:§3.1 scaling/BBPE · §3.2 MLA · §3.3 MoE vs V2 / MTP / FP8 · §3.4 GRPO · §3.5 MLA 模式切换 · §3.6 DSA · §3.7 V4 异构 KV + DSpark · §3.8 Visual Primitives · §4 Index Share · §5.1–5.3 KV offload 三代
| 版本 | 发布时间 | 参数量 | 激活参数 | 上下文 | 机构 | arXiv | 相对上一版的核心变化 |
|---|---|---|---|---|---|---|---|
| DeepSeek-LLM V1 | 2024-01 | 7B / 67B | 同左(稠密) | 4K | DeepSeek | 2401.02954 | 系列首篇;LLaMA 系 + GQA(67B);2T 双语;scaling laws |
| DeepSeek-V2 | 2024-05 | 236B | 21B | 128K | DeepSeek | 2405.04434 | 首次 MLA + DeepSeekMoE;8.1T |
| DeepSeek-V3 | 2024-12 | 671B | 37B | 128K | DeepSeek | 2412.19437 | MLA 旗舰化 + 256/8 MoE + MTP + aux-loss-free;14.8T |
| DeepSeek-R1 | 2025-01 | 同 V3 | 同 V3 | 128K | DeepSeek | 2501.12948 | V3-Base 上 RLVR + GRPO,架构不变 |
| DeepSeek-V3.1 | 2025 中 | 同 V3 | 同 V3 | 128K | DeepSeek | — | Hybrid 推理:同一权重切换 thinking / non-thinking |
| V3.1-Terminus | 2025 | 同 V3.1 | 同 V3.1 | 128K | DeepSeek | — | V3.1 收尾 checkpoint,作为 V3.2 续训起点 |
| DeepSeek-V3.2-Exp | 2025-09 | 同 V3.1-T | 同 V3.1-T | 128K | DeepSeek | Exp PDF · 2512.02556 | DeepSeek 官方实验版;引入 DSA(DeepSeek 原创稀疏注意力) |
| DeepSeek-V3.2 | 2025-12 | 同 V3.1-T | 同 V3.1-T | 128K | DeepSeek | 2512.02556 | DeepSeek 官方正式版;DSA 定型;唯一架构改动即为稀疏注意力 |
| ESS | 2025-12 | — | — | — | 百度百舸 | 2512.10576 | 纯推理补丁:Latent-Cache CPU offload;与 DSA 正交 |
| DeepSeek-V4-Pro | 2026 | 1.6T | 49B | 1M | DeepSeek | 2606.19348 | CSA + HCA + mHC + Muon;MoE FP4 |
| DeepSeek-V4-Flash | 2026 | 284B | 13B | 1M | DeepSeek | 同 2606.19348 | 更小激活量,效率优先 |
| Index Share | 2026-03 | — | — | — | 清华 + 智谱 | 2603.12201 | 纯推理补丁 |
| DSpark | 2026-06 | — | — | — | DeepSeek + 北大 | DeepSpec | V4 Flash/Pro 预览引擎;相对 MTP-1 基线;半自回归 draft + 置信度验证;纯推理 |
arXiv 说明:V3.1 / Terminus 为 post-train 与 checkpoint,无独立论文;V3.2-Exp 先发 GitHub 技术报告,DSA 完整叙述并入 V3.2 论文 2512.02556。DSpark 无独立 arXiv,技术报告见 DeepSpec / DSpark_paper.pdf;与 V4 同期开源,叠加在 V4 checkpoint 之上(§3.7 / §6)。
3. 各版本详解
各版本一页纸梗概见 版本梗概索引。以下为展开说明(按时间线从 V1 起)。更细的 V1→V3 脉络另见 V1→V3 演进。
3.1 DeepSeek-LLM V1
V1 正文:DeepSeek-LLM V1(2401.02954 完整中文译文)
论文:DeepSeek-LLM arXiv:2401.02954
架构要点
- 稠密 LLaMA 系:Pre-Norm + RMSNorm + SwiGLU + RoPE;7B(30 层 MHA)与 67B(95 层加深 + 8 头 GQA)。
- 上下文 4K;词表 BBPE 102,400。
- 预训练 2.0T 中英双语;数据管线:跨 dump 去重 → 过滤 → domain 重混。
- 对齐:~150 万 instruction,SFT + DPO。
研究贡献
- 系统 scaling laws($C=M\cdot D$);IsoFLOP 下数据质量越高越应扩模型而非堆数据。
答疑:为何用 $C=M\cdot D$ 而非 Chinchilla 的 $C=6ND$? — $M$=non-embedding FLOPs/token、Table 3 误差、与 IsoFLOP 的关系
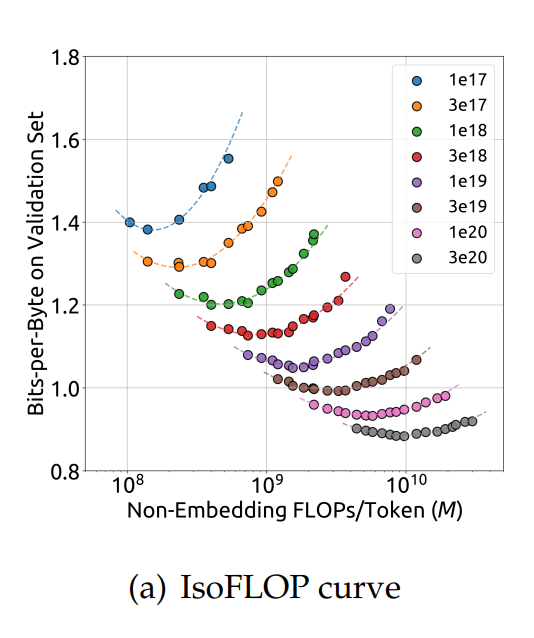
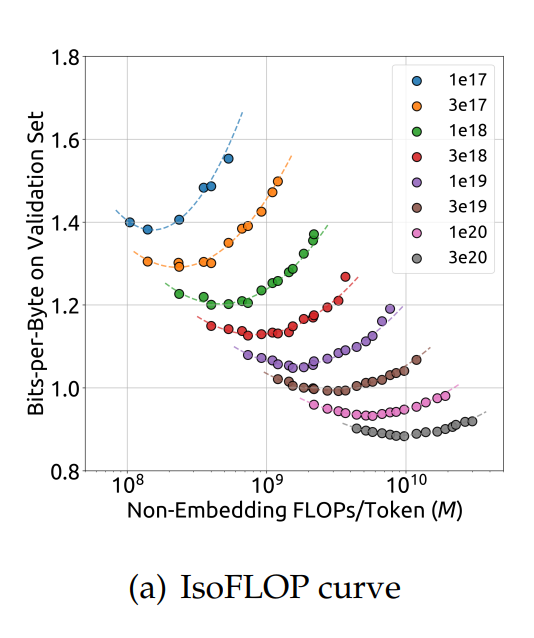
Figure 4a — IsoFLOP 曲线(各算力档 loss 随 $M$ 呈 U 形,谷底 = 最优分配)
{kind=link}
来源:V1 论文 Figure 4a(详见 V1 §3.2 最优 model/data Scaling)。横轴 = non-embedding FLOPs/token $M$;纵轴 = validation bits-per-byte;每条 U 形曲线对应固定总算力 $C$,谷底即该预算下最优 model/data 分配。
词表 BBPE:

{kind=link}
推理 infra 特征
- 标准 GQA/MHA KV cache(与后续 MLA 不兼容);无 MoE、无 latent 压缩;可按常规 Transformer 部署。
3.2 DeepSeek-V2
梗概:DeepSeek-V2 · MLA 详解
论文:DeepSeek-V2 arXiv:2405.04434 仓库:deepseek-ai/DeepSeek-V2
相对 V1 的架构跃迁
| 维度 | V1(67B 稠密) | V2 |
|---|---|---|
| FFN | 稠密 SwiGLU | DeepSeekMoE(160 routed + 2 shared / token 激活 6) |
| 注意力 | GQA | 首次 MLA latent KV |
| 规模 | 67B 全激活 | 236B / 21B activated |
| 上下文 | 4K | 128K |
| 预训练 | 2T | 8.1T |
要点
- MLA 将 K/V 压入 latent cache;论文称相对 67B 稠密 KV 体积约 -93.3%、生成吞吐 5.76×。
- MoE 路由为 softmax 系(V3 起改为 aux-loss-free sigmoid 路由)。
- MLA 结构被 V3 / R1 / V3.1 / V3.2 沿用;V2 是系列中 MLA+MoE 的首次引入。

{kind=link}
为什么 1536 能变成 [128,128] 和 [128,64]? ——不是切分,是两个独立上投影矩阵放大后按头 reshape:
- $q_t^C = W^{UQ} c_t^Q$: $[16384 \times 1536] \cdot [1536] \to [16384]$, 其中 $16384 = n_h \times d_h = 128 \times 128$ → reshape $[128, 128]$
- $q_t^R = \mathrm{RoPE}(W^{QR} c_t^Q)$: $[8192 \times 1536] \cdot [1536] \to [8192]$, 其中 $8192 = n_h \times d_h^R = 128 \times 64$ → reshape $[128, 64]$
$[128,128]$ 里两个 128 含义不同:前一个是头数 $n_h$(共 128 个头),后一个是每头维度 $d_h$(每头 128 维),本配置恰好都等于 128。二者都是架构超参,不是从 1536 算出来的;1536 只决定矩阵的列数。(KV 侧同理:$c_t^{KV} = 512$ 经 $W^{UK}, W^{UV}$ 投影成 $[128,128]$。)
右边 $k_t^R = [64]$ 的 64 怎么来? ——$64 = d_h^R$(每头 RoPE 维度,架构超参);$W^{KR}: [64 \times 5120] \cdot h_t \to [64]$,再加上 RoPE。 关键: $k_t^R$ 没有头维度——所有 $n_h = 128$ 个头共享同一个 $[64]$(解耦 RoPE);而左边 $q_t^R$ 是每头各一份 $[128, 64]$。 正因为 K 的 RoPE 部分全局只存一份 $[64]$(不按头复制),KV 缓存才这么小——这是 MLA 省显存的另一半原因。
MLA 到底压缩了谁?如果不做压缩会变多大? ——下面三项就是 MLA 压缩/解耦的对象(格式:MLA 压缩后 $\Rightarrow$ 不压缩):
- $c_t^Q$ 查询潜向量: $1536 \Rightarrow 16384\ (= n_h d_h)$, 约 11×; 不进缓存,省的是参数与计算量。
- $c_t^{KV}$ KV 联合潜向量: $512 \Rightarrow 16384\ (= n_h d_h)$, 32×; ★进缓存 —— 这是省显存的核心。
- $k_t^R$ 共享 RoPE 键: $64 \Rightarrow 8192\ (= n_h d_h^R)$, 128×; ★进缓存,靠全头共享(不按头复制),而非低秩压缩。
缓存总量: 标准 MHA $= 2n_h d_h = 32768$ → MLA 若不压缩 $= 16384 + 64 = 16448$(仅 MHA 一半) → 实际 MLA $= 512 + 64 = 576 \approx$ MHA 的 1/57
来源:V2 论文 Eq. 37–47;cache 仅存 $c_t^{KV}$(512)+ 共享 $k_t^R$(64)。
推理 infra 特征
- KV cache 变为 MLA latent 格式;需引擎侧自定义 kernel / 适配(后续 FlashMLA 等)。
3.3 DeepSeek-V3
梗概:DeepSeek-V3 · 相对 V2 纯模型结构优化:§对比 V2
论文:DeepSeek-V3 Technical Report 仓库:deepseek-ai/DeepSeek-V3
相对 V2 的架构升级
| 维度 | V2 | V3 |
|---|---|---|
| 规模 | 236B / 21B 激活(~8.9%) | 671B / 37B 激活(~5.5%) |
| MoE | 160 routed,top-6,2 shared;softmax + aux loss | 256 routed,top-8,1 shared;aux-loss-free(sigmoid + bias $b_i$) |
| 注意力 | 首次 MLA | 同族 MLA(latent KV 方程不变;671B / 128K 配比升级) |
| 预测头 | 单步 next-token | + MTP 辅助头(多步并行预测) |
| 预训练 | 8.1T | 14.8T |
要点(三条结构线)
-
MoE 路由革新:去掉 aux loss 主路径;router 内 可学习 bias 做负载均衡,sigmoid affinity 选 expert、门控与选择解耦;专家池扩至 256/8,激活占比更低。
-
MTP(全新):输出层 Multi-Token Prediction 辅助目标;推理可原生投机解码 → 投机解码与 DSpark 专文 §2
-
MLA 继承:K/V 仍压入 latent cache($c_t^{KV}$ 512 + 共享 $k_t^R$ 64);V3 价值在旗舰规模与 128K 巩固,非新 attention 算子(Hybrid / DSA 在 V3.1 / V3.2)。

图示详情 · MoE 详解 · aux-loss-free · MLA 前向流程图
{kind=link}
- 训练:14.8T tokens;后训练含 SFT + RL(R1 为同架构 + RLVR)。
训练 infra(非模型结构):FP8 动态量化 — 块级 scale + 每 $N_c{=}128$ MMA 提升 FP32 累加;与 DualPipe / DeepEP 并列,支撑 671B 预训练吞吐与数值稳定。
推理 infra 特征
- KV cache 为 MLA latent 格式,与标准 GQA/MHA 不兼容。
- vLLM 等引擎需
--trust-remote-code、--block-size 1(MLA 专用)。 - 长上下文下主要瓶颈是 Latent-Cache 线性增长 占满 HBM,限制 batch size。
3.4 DeepSeek-R1
梗概:DeepSeek-R1 · RLVR 详解
论文:DeepSeek-R1 arXiv:2501.12948 训练管线:DeepSeek-R1 训练 Pipeline
要点
- 架构与 V3 完全相同;差异仅在 后训练。
- RLVR(Reinforcement Learning with Verifiable Rewards):数学/代码等用 规则验证器 给奖励,配合 GRPO(无 critic),不用神经 reward model 做主信号。
- R1-Zero:V3-Base 上纯 RL,推理能力自发涌现;可读性弱。
- R1:冷启动 SFT → RL → 拒绝采样 SFT → 二阶段 RL(推理 + 通用 RM),补齐 helpful / safe。

{kind=link}
推理 infra:与 V3 相同(MLA latent KV、引擎配置一致)。
3.5 DeepSeek-V3.1 / V3.1-Terminus
变化:在 V3 权重基础上做 post-training,无架构变更。
| 维度 | V3 | V3.1 |
|---|---|---|
| 推理模式 | Base / R1 分离 | Hybrid:同一模型切换 thinking / chat |
| 上下文 | 128K | 128K(续训扩展) |
| Agent / Tool Use | 较弱 | 明显加强(BrowseComp、SWE 等) |
V3.1-Terminus 是 V3.1 系列的最终 checkpoint,上下文已扩至 128K,作为 V3.2 继续预训练 的起点。
MLA 模式切换:

{kind=link}
- Prefill:MHA 模式(多 query head 独立 latent)
- Decode:MQA 模式(latent 在 query head 间共享)
这为后续 DSA 在 MQA 模式下做稀疏选择打下基础。
3.6 DeepSeek-V3.2 / V3.2-Exp
梗概:DeepSeek-V3.2 · V3.2-Exp
论文:DeepSeek-V3.2 · V3.2-Exp 仓库:deepseek-ai/DeepSeek-V3.2
相对 V3.1-Terminus 的唯一架构改动:DeepSeek Sparse Attention (DSA)

{kind=link}
DSA 两阶段(三阶段表):
- Lightning Indexer:对每个 query,用廉价点积为所有历史 token 打分(复杂度仍 $O(L^2)$,但 head 维极低)。
- Top-$k$ Selector:选出 $k=2048$ 个最重要 token 的 latent entry。
- Core Attention(Core MLA):仅对这 $k$ 个 latent 做 MLA attention(复杂度 $O(Lk)$)。
概念:Lightning Indexer · Top-$k$ Selector · Core MLA · Indexer-Cache · Latent-Cache · ESS
因此 V3.2 的 cache 分裂为两类(异构 KV · DSA逻辑详解 §4):
| Cache 类型 | 作用 | 占总量比例(ESS 论文) | 是否 offload |
|---|---|---|---|
| Indexer-Cache | 计算重要性、选 top-$k$ | ~16.8% | 否(每步全算) |
| Latent-Cache | MLA 核心 attention 的 KV | ~83.2% | 可 offload(ESS) |
V3.2-Exp 与 V3.2 架构相同;Exp 用于验证 DSA 不损精度,V3.2 为正式训练 + 后训练成品。
推理内核:DeepGEMM(indexer logits)、FlashMLA(sparse attention paged kernel)→ 推理 infra
3.7 DeepSeek-V4
论文:DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence 模型:V4-Pro(1.6T / 49B act)、V4-Flash(284B / 13B act)
相对 V3.2 的算法大步进
| 组件 | 说明 |
|---|---|
| CSA (Compressed Sparse Attention) | 每 $m=4$ token 压缩为 1 条 KV entry,再对压缩序列做 DSA(top-$k$ 压缩 entry)→ 专文 §2 |
| HCA (Heavily Compressed Attention) | 每 $m'=128$ token 压缩为 1 条,序列极短,直接 dense attention → 专文 §3 |
| mHC | Manifold-Constrained Hyper-Connections(§3 双随机流形):Sinkhorn–Knopp 凸组合 |
| Muon | 优化器替换,加速收敛 → 专文 §1 |
| Hash MoE | 前几层 dense FFN → Hash-routed MoE → 专文 §1 |
| FP4 MoE | routed expert 权重 FP4 + QAT → 专文 §2 |

图示详情 · V4 梗概 · CSA/HCA 详解 · Hash MoE + FP4 · Muon 详解 · mHC 详解
1M context 效率
| 模型 | 单 token FLOPs | 累计 KV cache |
|---|---|---|
| V4-Pro @ 1M | 27% | 10% |
| V4-Flash @ 1M | 10% | 7% |
Agentic Coding 场景:V4 面向 100K–1M token 的 agent 工作流(代码库、多轮 tool trace),算法侧用 CSA/HCA 压 cache,infra 侧用异构 KV 管理 + offload 才能「真的跑得动」。
推理加速:V4 预览引擎已部署 投机解码与 DSpark(相对 MTP-1 基线;同等吞吐下单用户 +57%–85%)。细节、图示、自测与 MTP 机制 均在专文,此处不重复。
专文:投机解码与 DSpark · DeepSpec
Ablation 困境:V4 同时改了注意力、残差、优化器、MoE 路由、量化精度,很难像 V3.2 那样做单一变量对照——这也是社区更青睐 Index Share 这类「纯 infra、零重训」补丁的原因之一。
3.8 Thinking with Visual Primitives
要点专文:Visual Primitives 论文要点 · PDF:Visual Primitives 原文 PDF
定位:V4-Flash 之上的 MLLM 支线——把 点 / 框 作为 CoT 的 visual primitives,解决语言难以精确 空间引用 的 Reference Gap。
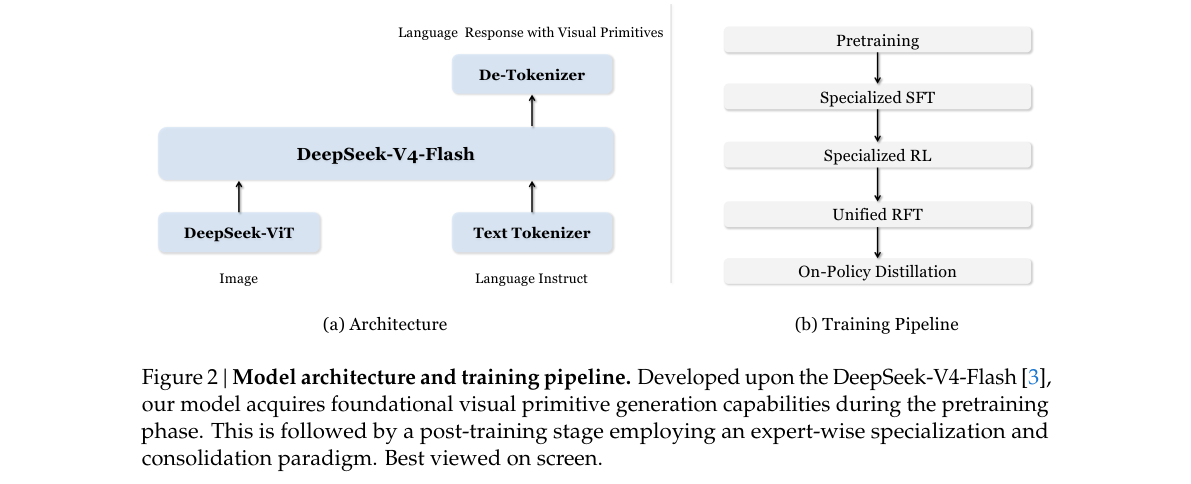
双模块架构:
| 模块 | 角色 |
|---|---|
| DeepSeek-ViT | 任意分辨率图像 → patch token → 3×3 通道压缩 |
| V4-Flash LLM | 视觉 + 文本交错序列;CSA 将视觉 KV 再压 4× |
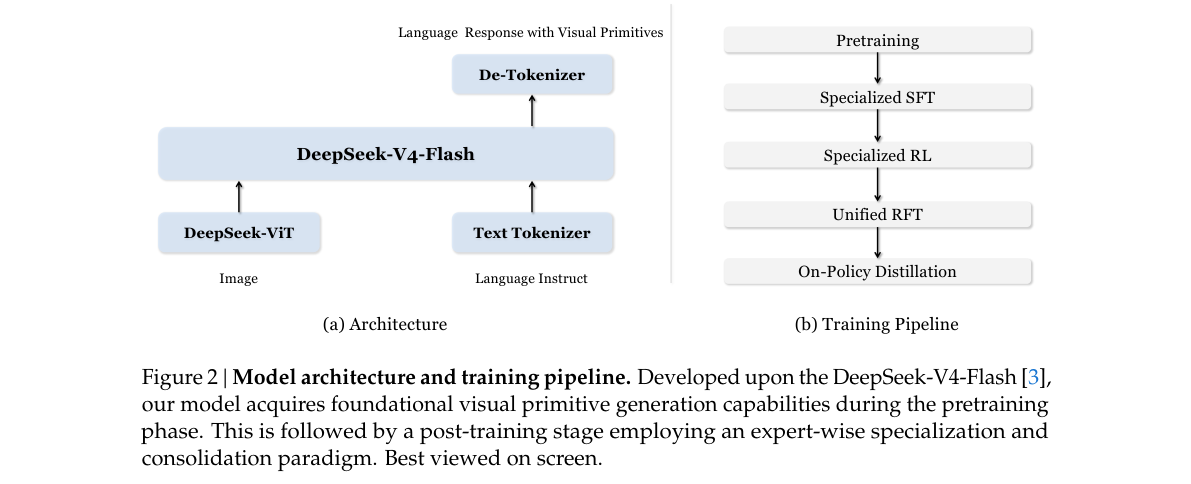
Figure 2 | Model architecture and training pipeline(论文原图)。756×756 示例:2,916 patch → 324 LLM token → 81 KV entries,总压缩 7,056×。
{kind=link}
效率与精度:
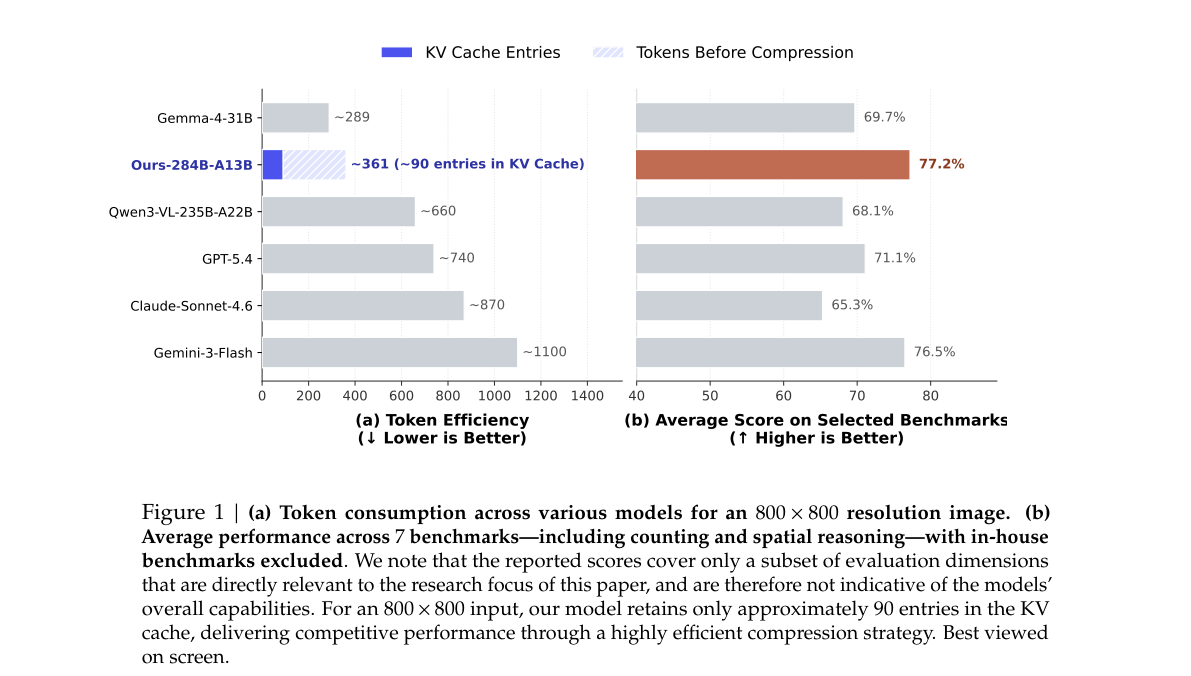
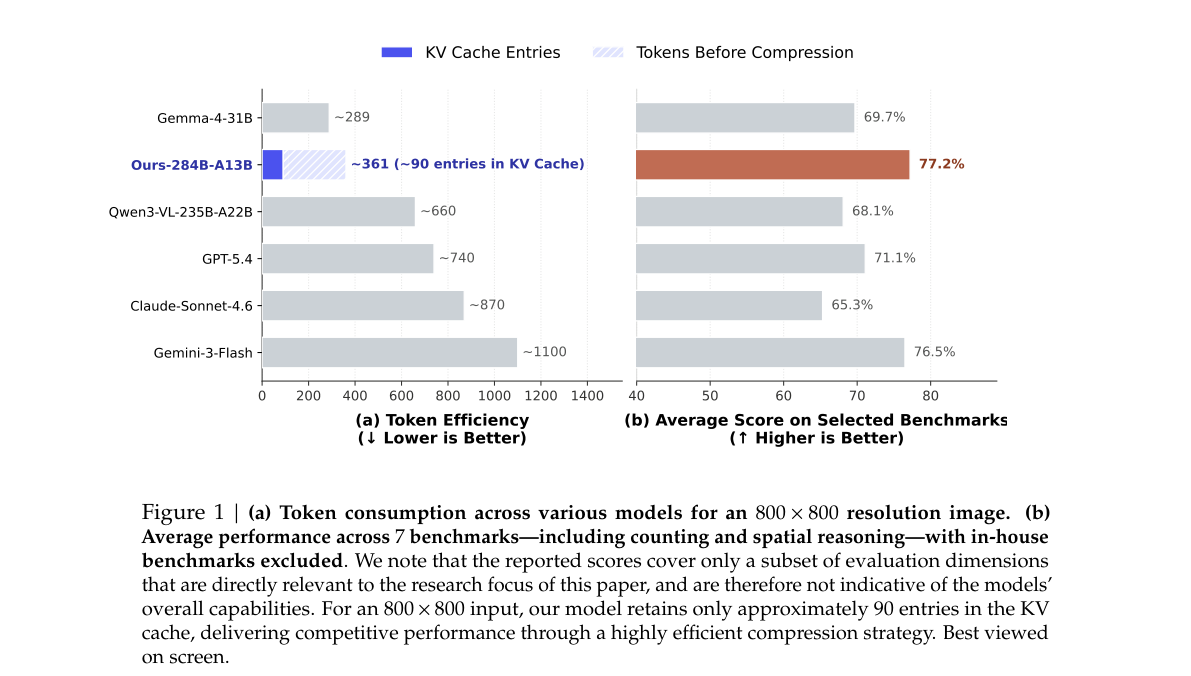
| 指标 | 数值 / 对比 |
|---|---|
| 800×800 视觉 KV | 约 90 entries(全文 ~361 tokens)vs Gemini-3-Flash ~1100 tokens |
| 7 项 benchmark 均分 | 77.2%(子集评测,非全能榜) |
| 拓扑推理 | DS_Maze 66.9、DS_Path_Tracing 56.7,显著高于 Qwen3-VL-235B |
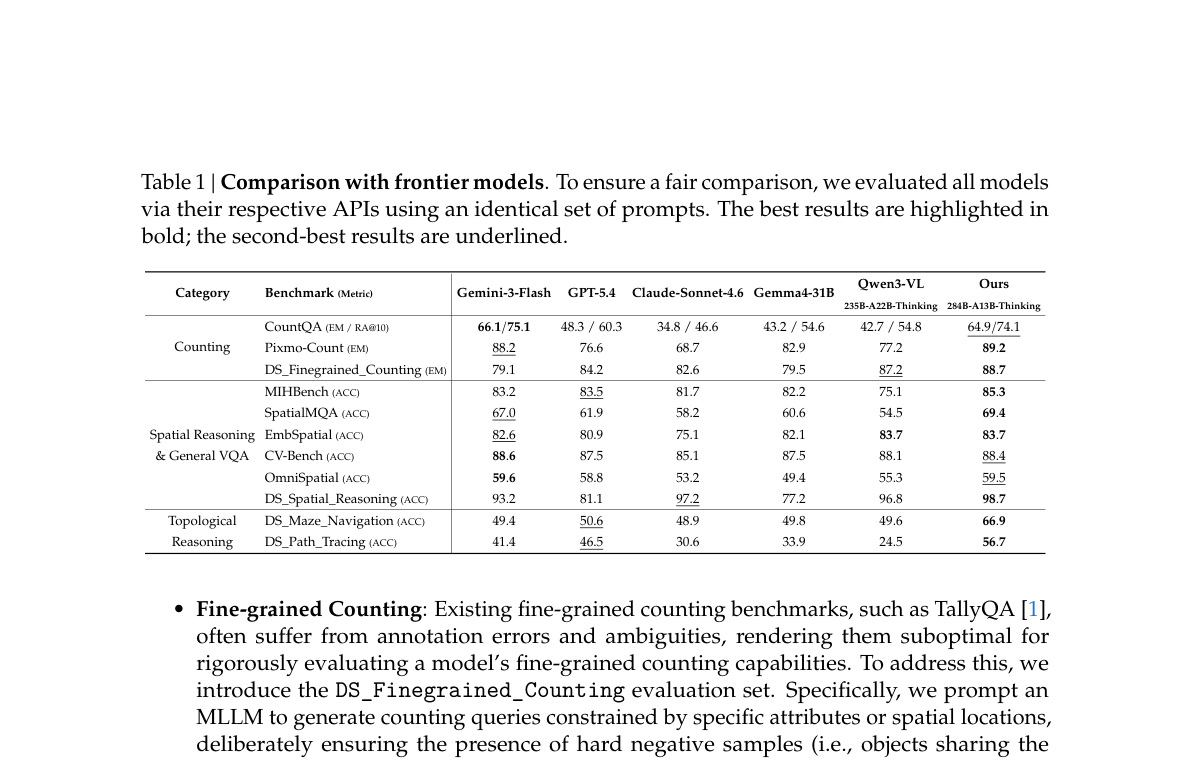
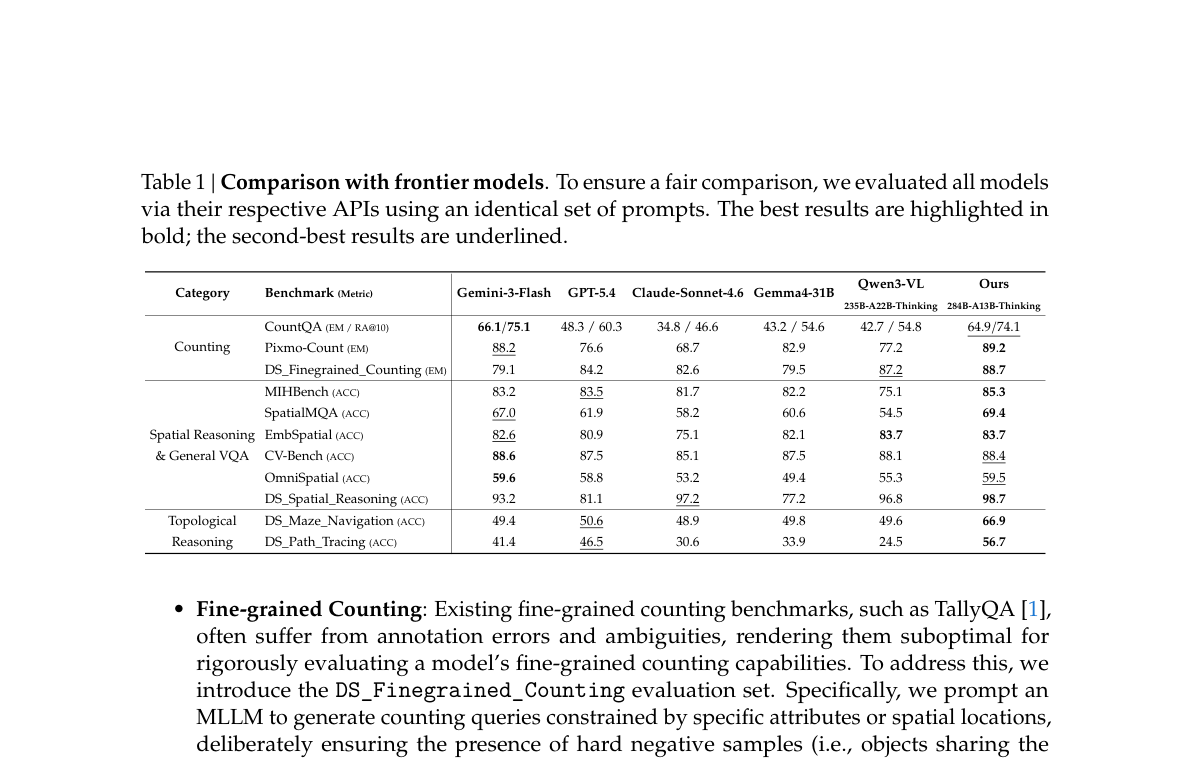
Table 1 | Comparison with frontier models(bold=最佳)。
直接打开 Figure 1 · Table 1 · 要点专文 §4–§5
{kind=link}
{kind=link}
与 §3.7 V4 的关系:共享 CSA 压缩 attention 与 MoE 推理栈;增量在 ViT 编码器 + visual primitives 后训练管线,属于 模型轴(数据/对齐)+ 架构-train(ViT 模块) 的扩展,而非新的文本稀疏注意力变体。
4. Index Share
梗概:Index Share 逻辑详解:Index Share逻辑详解
社区昵称 Index Share / 「V3.3」;正式名 IndexCache。 论文:arXiv:2603.12201(清华大学 + 智谱 AI / Z.ai)· 代码:THUDM/IndexCache
4.0 技术归属
| 角色 | 机构 | 说明 |
|---|---|---|
| 被优化对象 | DeepSeek | 自研 DSA + Lightning Indexer;每层独立 top-$k$,长上下文下 indexer 成为瓶颈 |
| 优化算法 | 清华 + 智谱(Z.ai) | IndexCache / index-share:F 层缓存索引、S 层复用,非 DeepSeek 官方产物 |
| 工程落地 | 百度百舸 等 | 训推引擎集成 IndexCache、分布式与异构芯片适配;ESS 为百舸自研的 Latent-Cache offload,与 IndexCache 正交 |
4.1 解决什么问题
DSA 的 indexer 每层独立运行,复杂度 $O(L^2)$,长上下文 prefill 时 indexer 成为显著开销。观察:相邻层的 top-$k$ index 高度相似。
4.2 机制
将 Transformer 层分为两类:
- Full (F) 层:保留 indexer,正常计算 top-$k$
- Shared (S) 层:不跑 indexer,直接复用最近一个 F 层的 cached indices
典型模式:每 4 层保留 1 个 F 层(FFFS 重复),去掉 75% indexer 计算。

{kind=link}
两种部署:
| 模式 | 做法 |
|---|---|
| Training-free | 在校准集上贪心搜索哪些层保留 indexer,最小化 LM loss |
| Training-aware | 多层蒸馏,让保留的 indexer 拟合其覆盖层的平均 attention 分布 |
4.3 为何被称为「最好的 infra 补丁」
| 属性 | Index Share | V4 级架构改动 |
|---|---|---|
| 权重变更 | 无 | 全量重训 |
| 额外显存 | 零 | 新 cache layout |
| 实现 | SGLang / vLLM 一个 if/else 分支 | 异构 KV + 新 kernel |
| 加速 | 200K:TTFT 1.82×,decode 1.48× | 1M:FLOPs/KV 降至 10% 级 |
| 适用模型 | DSA 系(V3.2、GLM-5) | V4 自带 CSA indexer |
结论:Index Share 典型体现「infra 归 infra,算法归算法」——在 DSA 算法不变的前提下,用跨层冗余做系统优化。
5. KV-offload 演进
KV-offload 指将部分 cache 卸载到 CPU DRAM(或磁盘),按需 prefetch 回 GPU。DeepSeek 各代的 cache 形态不同,offload 策略也完全不同。
5.1 V3 / V3.1:标准 MLA Latent-Cache
- Cache 内容:单一 MLA latent 向量序列。
- Offload:可用通用 KV offload(FlexGen、vLLM CPU offload 等),但 MLA 自定义格式导致很多引擎 不支持标准 offload。
- 瓶颈:线性增长的 latent 占满 HBM → decode batch size 受限。

图示详情 · MLA 前向专文 · MLA §KV Cache
5.2 V3.2:Indexer-Cache + Latent-Cache 分离 → ESS
归属澄清:DeepSeek-V3.2-Exp / V3.2 与 DSA 均为 DeepSeek 官方发布。下文 ESS 论文标题虽含「DeepSeek-V3.2-Exp」,但 ESS 算法来自百度百舸,是针对 DeepSeek DSA 模型的 Latent-Cache offload 方案,不是 DSA 本身,也不是 V3.2-Exp 的发布方。
论文:ESS: An Offload-Centric Latent-Cache Management Architecture for DeepSeek-V3.2-Exp

{kind=link}
| 策略 | 说明 |
|---|---|
| Indexer-Cache 常驻 GPU | 占 16.8%,每步必须全算,offload 无意义 |
| Latent-Cache offload 到 CPU | 占 83.2%,利用 top-$k$ 的 时间局部性(相邻 decode step 的 $K_t^l$ 重叠率高) |
| FlashTrans + UVA | 解决 656B 小块 PCIe 传输带宽极低(原 ~0.8 GB/s H2D)→ 提升至 ~37 GB/s |
| GPU 侧 Sparse Memory Pool | LRU 维护 GPU 热 latent 子集,miss 时从 CPU prefetch |
| Layer-wise overlap | 计算与传输流水线掩盖延迟 |
收益:32K context 吞吐 +69.4%;128K 最高 +123%。
与 V3 的本质区别:offload 单位从「整条 MLA latent 序列」变为「稀疏选中的 Latent-Cache entry」,且需与 indexer 的 top-$k$ 选择协同。
5.3 V4:异构 KV + HiSparse + 磁盘 Prefix Cache
V4 的 cache 不再是单一 MLA latent,而是多类型并存:
| KV 类型 | 来源 | 特点 |
|---|---|---|
| CSA 压缩 entry | 每 4 token → 1 | 序列长 $\frac{L}{4}$,稀疏 top-$k$ |
| HCA 压缩 entry | 每 128 token → 1 | 序列极短,dense attend |
| SWA (Sliding Window) | 最近 $n_{\text{win}}$ token | 独立 eviction 策略 |
| Indexer KV | CSA 的 lightning indexer | 与主 attention 维度不同 |
| Tail buffer | 不足 $m$ 个 token 的未压缩尾 | 等待凑满再压缩 |
KV layout→ 专文:V4 KV Layout
- Classical KV cache:按 $\mathrm{lcm}(m, m')$ 对齐的压缩块,服务 CSA/HCA
- State cache:每请求固定大小块,存 SWA + 未就绪压缩尾
HiSparse→ 专文:V4 HiSparse
- 将 inactive 的 C4(CSA 4:1 压缩层)cache entry offload 到 CPU pinned memory
- GPU 只保留 active「热」工作集
- 单节点 B200 上 KV 容量从 ~1.2M tokens 提升到 ~3.7M tokens(约 3×)
磁盘 Prefix Cache→ 专文:V4 磁盘 Prefix Cache
- CSA/HCA 压缩 entry 可直接落盘,共享 prefix 免重复 prefill
- SWA 体积约为压缩 entry 的 8×,提供 Full / Periodic Checkpointing / Zero 三档策略
5.4 三代 offload 对比
| 维度 | V3 / V3.1 | V3.2 (ESS) | V4 (HiSparse) |
|---|---|---|---|
| Cache 结构 | 同质 MLA latent | Indexer + Latent 异构 | CSA + HCA + SWA + Indexer + tail |
| Offload 对象 | 全量 latent(若引擎支持) | 仅 Latent-Cache | Inactive C4 压缩 entry + 磁盘 prefix |
| 局部性依据 | 顺序滑动窗口 | top-$k$ index 时间相似度 | 稀疏激活 + SWA 复用策略 |
| 传输优化 | 通用 PCIe | FlashTrans / UVA | 分层内存池 + PD 分离 |
| 与算法耦合 | 低 | 中(依赖 DSA top-$k$) | 高(依赖压缩比 $m, m'$) |
知乎社区观点(2026-06):V4 的 KV-offload 策略与 DSV3.2 完全不同——不是简单扩大 ESS,而是围绕异构压缩 cache 重新设计内存层级;V3.2 上可叠加 Index Share + ESS,V4 则需要 HiSparse + 定制 layout。
6. 推理技术栈对照
| 技术 | 适用版本 | 类型 | 链接 |
|---|---|---|---|
| FlashMLA | V3+ | Kernel | deepseek-ai/FlashMLA |
| DeepGEMM indexer | V3.2+ | Kernel | DeepGEMM PR#200 |
| DSpark + DeepSpec | V4 Flash / Pro(线上) | 投机解码 / decode 吞吐 | DeepSpec · DSpark 专文 |
| IndexCache (Index Share) | V3.2, GLM-5 | Infra 补丁 | THUDM/IndexCache |
| ESS(百度百舸) | DeepSeek-V3.2 / V3.2-Exp | Latent-Cache offload | arXiv:2512.10576 |
| SGLang / vLLM recipes | 全系列 | serving | 各模型 README |
7. 与本仓库其他专题的关系
优化方向:各专题在 §1.1 模型 / 架构-train / 架构-infer 分类 中的落点见该表「工作一览」。
| 专题 | 关系 |
|---|---|
| Engram | 另一条稀疏轴(条件记忆查表),与 MoE 正交;可 offload 到 Host/CXL |
| Engram 系列导读 | Engram / CXL Pooling / Tiny-Engram 深度笔记 |
| DSA 系列 · ESS 概念 · Index Share | V3.2 稀疏注意力 + 推理 infra 补丁(与 §3.6 / §5.2 对应) |
| DSpark / DeepSpec | V4 投机解码 线上加速;与 KV/offload 正交(§3.7 / §6) |
| Visual Primitives | V4-Flash 多模态:visual primitives CoT + ViT;CSA 压视觉 KV(§3.8) |
| DeepSeek-R1 训练管线 | R1 四阶段;RLVR 概念 |
8. 参考资料
- DeepSeek-AI. DeepSeek-V3 Technical Report. arXiv:2412.19437, 2024.
- DeepSeek-AI. DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models. arXiv:2512.02556, 2025.
- DeepSeek-AI. DeepSeek-V3.2-Exp: Boosting Long-Context Efficiency with DeepSeek Sparse Attention. 2025.
- Chen et al. ESS: An Offload-Centric Latent-Cache Management Architecture for DeepSeek-V3.2-Exp. arXiv:2512.10576, 2025.
- Bai et al. IndexCache: Accelerating Sparse Attention via Cross-Layer Index Reuse. arXiv:2603.12201, 2026.
- DeepSeek-AI. DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence. arXiv:2606.19348, 2026.
- Together.ai. Serving DeepSeek-V4: why million-token context is an inference systems problem. 2026.