DeepSeekMoE 架构
← 中文导读 · ← 仓库首页(EN) · ← 演进总览 §2 · ← MoE 线导读 · V2 首发版本 · V3 旗舰化 · aux-loss-free 下游 论文:V2 arXiv:2405.04434 · V3 arXiv:2412.19437 §2.1
一句话
DeepSeekMoE = DeepSeek 自研的 细粒度 routed experts + shared experts FFN 稀疏激活框架:每 token 只激活少量 routed expert,并 始终保留 shared expert 路径;V2(2024-05)首次引入,V3 / R1 / V3.1 / V3.2 沿用同一 MoE 骨架,V3 起路由改为 aux-loss-free,V4 前几层改 Hash 路由。
相对稠密 FFN 的动机
| 稠密(V1) | DeepSeekMoE |
|---|---|
| 每层 FFN 全参数激活 | 仅 top-$K$ routed + shared 参与计算 |
| 容量 ↔ 算力线性绑定 | 总参大、激活参小(如 236B / 21B) |
| 无 expert 路由 | 需 负载均衡(V2 softmax 系 → V3 aux-loss-free) |
V2 论文相对 67B 稠密:训练成本 -42.5%、生成吞吐 5.76×(同参数量级对比语境见 DeepSeek-V2)。
优化逻辑:从常规 MoE 到 DeepSeekMoE
V2 技术报告 §2.2 将 DeepSeekMoE 概括为两步改进(引自 Dai et al., 2024):
- Fine-grained expert segmentation(细粒度专家切分) — 把粗专家拆小,在相同激活算力下提高组合灵活性;
- Shared expert isolation(共享专家隔离) — 固定激活 shared expert 承担通用知识,routed expert 专注特化,减轻冗余与「参数竞争」。
论文用三张子图 (a)→(b)→(c) 说明:每一步都尽量保持每 token 激活的 FFN 参数量 / FLOPs 不变,只改「专家怎么切、怎么路由」。
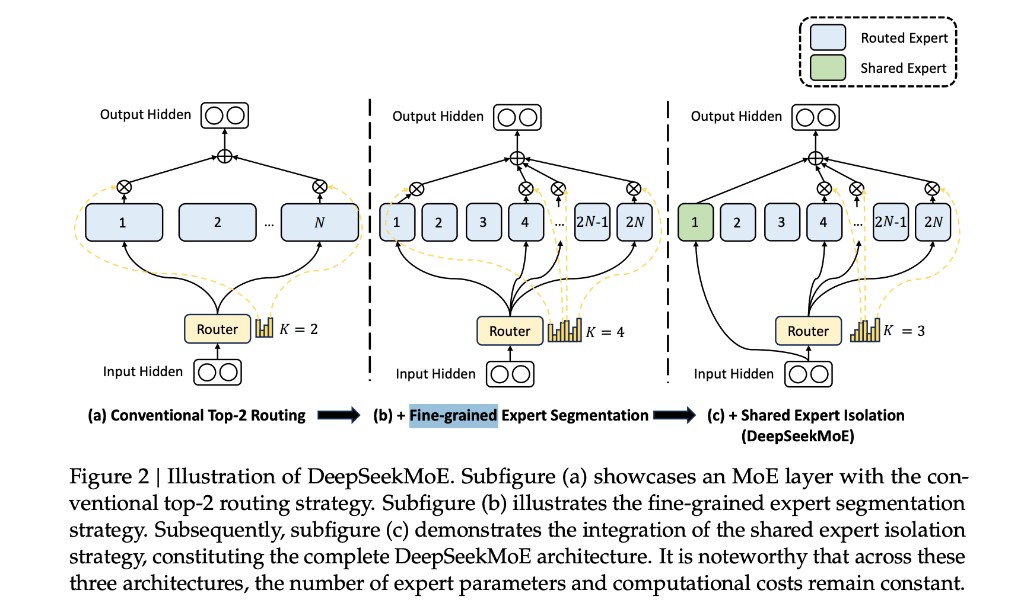
来源:DeepSeek-V2 论文 Figure 2 — Illustration of DeepSeekMoE。蓝 = routed expert;绿 = shared expert;黄 = Router。
常规 Top-$K$ 路由
| 项 | 设定 |
|---|---|
| 专家池 | $N$ 个大 routed expert |
| 每 token 激活 | $K=2$(经典 Top-2 MoE,如 GShard / Switch 系) |
| 数据流 | Hidden → Router 选 2 个 expert → 加权求和 → 输出 |
局限:专家粒度粗,每个 expert 体积大;Top-2 组合空间只有 $\binom{N}{2}$ 种,特化不够细——不同 token 往往被迫共用同一套「大块」知识。
+ 细粒度专家切分
| 项 | 相对 (a) 的变化 |
|---|---|
| 专家池 | 同样总参下,$N$ 个大 expert → $2N$ 个小 expert(每个约一半宽度) |
| 每 token 激活 | $K=4$ routed(数量翻倍) |
| 算力约束 | 激活 expert 个数 × 单 expert 大小 ≈ 与 (a) 相同 → FLOPs 持平 |
直觉:用「更多、更小」的积木拼 FFN;每 token 仍只付固定算力,但可访问的组合从「选 2 大块」变成「选 4 小块」,表达更灵活、特化更准。 V2 产品配置是这一思想的规模化:单层 160 routed、每 token 6 routed(见下表),而非示意图里的 $N/2N$ 玩具数。
答疑:Fine-grained 为何优于 GShard? — 组合数 $\binom{N}{K}!\to!\binom{mN}{mK}$、IsoFLOP 切分与训练机制
+ Shared Expert 隔离
| 项 | 相对 (b) 的变化 |
|---|---|
| Shared expert | 划出 $N_s$ 个 shared(图中 1 个;V2 为 2 个/层),每个 token 必过,不经 Router |
| Routed 选择 | Router 只在剩余 routed 池里 Top-$K_r$;示意 $K_r=3$ |
| 总算力 | $N_s + K_r = 1 + 3 = 4$,仍与 (b) 的 4 routed 激活量同级 |
为什么要 shared? 许多 token 都需要的通用 FFN 模式(语法、高频搭配等)若全塞进 routed expert,会占掉 routed 容量,导致:
- 多个 routed expert 学重复(knowledge redundancy);
- 特化 expert 抢不过通用模式,负载均衡更难。
Shared 路径隔离通用知识,routed 专注长尾 / 领域特化——论文称这能提升 expert specialization 与知识获取精度。
三步合起来:设计不变量
| 不变量 | 含义 |
|---|---|
| 激活 FFN 预算 | (a)(b)(c) 示意中每 token 激活 expert 总数 × 单 expert 宽度大致恒定 |
| 总参可扩 | 总 expert 数可随层加宽加深,但每 token 只走 sparse 子集 |
| DeepSeekMoE = (b) + (c) | 细粒度 routed 且 shared 与 routed 分工 |
前向公式
对第 $t$ 个 token 的 FFN 输入 $u_t$,输出 $h_t'$ 为 残差 + shared 支路 + routed 支路:
$$ h_t' = u_t + \sum_{i=1}^{N_s} \mathrm{FFN}i^{(s)}(u_t) + \sum{i=1}^{N_r} g_{i,t},\mathrm{FFN}_i^{(r)}(u_t) $$
其中 routed 门控:
$$ g_{i,t} = \begin{cases} s_{i,t}, & s_{i,t} \in \mathrm{TopK}\big({s_{j,t}}{j=1}^{N_r},, K_r\big) \ 0, & \text{otherwise} \end{cases}, \quad s{i,t} = \mathrm{Softmax}_i(u_t^\top e_i) $$
| 符号 | 含义 |
|---|---|
| $N_s$ | shared expert 数(V2:2/层) |
| $N_r$ | routed expert 数(V2:160/层) |
| $K_r$ | 每 token 激活 routed 数(V2:6) |
| $e_i$ | 第 $i$ 个 routed expert 的 routing centroid(非 FFN 权重) |
答疑:为何叫 centroid 而非 gate-weight? — affinity / gate 分工与 V3 选择-门控解耦
Shared 项无 $g_{i,t}$ 门控 — 与图中 Expert 1(绿)始终接通一致。
与 V2 工程配置的对应
示意图用 $N,,2N,,K=2/4/3$ 做教学缩放;DeepSeek-V2 真实超参:
| 示意 (c) | DeepSeek-V2 |
|---|---|
| 1 shared + 3 routed | 2 shared + 6 routed / token / 层 |
| softmax Router | 同左;另加 device-limited routing(§2.2.2:每 token 目标 expert 最多跨 $M$ 台设备,$M\ge 3$ 时精度与无限制 Top-$K$ 接近) |
| 负载均衡 | Expert / device / comm 三级 aux loss(V3 起路由改为 aux-loss-free,MoE 骨架仍为 shared + fine-grained routed) |
结构要点
- Fine-grained routed experts:单层 routed 数量 显著多于 早期 MoE(V2:160),单 expert 更小 → 见上文 §优化逻辑 (b)。
- Shared experts:每层 恒激活 shared FFN(V2:2 个),与 routed 输出相加 → 见 §优化逻辑 (c)。
- Per-token top-$K_r$:V2 每 token 6 routed;V3 8 routed / 256 池。
- 路由演进:V2 softmax + aux balance loss → V3 aux-loss-free + $L_{\mathrm{Bal}}$。
各版本配置
| 版本 | 总参 / 激活 | routed 规模 | 每 token 激活 routed | shared | 路由 |
|---|---|---|---|---|---|
| V2 | 236B / 21B | 160 routed / 层 | 6 | 2 / 层 | softmax |
| V3 | 671B / 37B | 256 routed / 层 | 8 | 有 | aux-loss-free |
| V4 | 1.6T / 49B 等 | 继承 V3 框架 | 同族 | 有 | 前几层 Hash MoE + FP4 |
MoE 线位置
| 方向 | 文档 |
|---|---|
| 本节点(② DeepSeekMoE) | MoE 线导读 §1 |
| 上游 ① | 稠密 FFN(概念阶段;V1 产品实例见 DeepSeek-LLM V1) |
| 下游 ③④ | aux-loss-free MoE 路由 · 序列均衡损失 |
| 下游 ⑤ | Hash MoE + FP4 · DeepSeek-V4 |
推理 infra 关注点
- Expert Parallel(EP):routed expert 分片;负载不均时 GPU 空转 → 路由均衡是训练关键(答疑:EP 与 gather/scatter)。
- Shared + routed 双路径:引擎需支持 shared 始终 on + 稀疏 routed gather/scatter。
- V2 路由为 softmax 系;V3+ 为 sigmoid + 动态 bias,权重 checkpoint 不混用路由逻辑。
参考
- DeepSeek-V2 梗概 — MLA + DeepSeekMoE 首次落地(8.1T)
- DeepSeek-V3 梗概 — 256/8 旗舰化 + MTP
- aux-loss-free 路由逻辑
- 仓库:DeepSeek-V2 · DeepSeek-V3