ESS 论文梗概
← 中文导读 · ← 仓库首页(EN) · ← 演进总览 §5.2 · ← ESS 概念页 · ← 基础设施线导读 · DSA 全文:arXiv:2512.10576 · Chen et al., 2025(百度 Baige AI) 对象模型:DeepSeek-V3.2-Exp · 框架:SGLang · 场景:PD 分离 Decode 阶段
一句话
论文提出 ESS(Extended Sparse Server):在 不改模型精度 的前提下,把 Latent-Cache(~83.2%) offload 到 CPU,GPU 上只留 Sparse Memory Pool(LRU 热子集) + 常驻 Indexer-Cache(~16.8%);靠 FlashTrans/UVA 解决 656B 小块 PCIe 传输、LRU-Warmup 降早期 miss、Layer-wise DA/DBA Overlap 掩盖 prefetch 延迟,仿真上 32K 吞吐 +69.4%、128K 最高 +123%。
论文要解决什么
| 矛盾 | 说明 |
|---|---|
| DSA 降了算力 | 稀疏 attention 减轻计算,但 Decode 仍是 PD 架构瓶颈 |
| Latent-Cache 线性涨 | 序列越长 cache 越大 → batch size 被 GPU HBM 卡死 |
| 小块 PCIe 传输 | 每步 top-2048 个 656B entry 分散 → 原生 cudaMemcpyAsync H2D 仅 ~0.79 GB/s |
核心观察:top-$K$ latent 的 index 在 相邻 decode step 高度相似(层内相似度 $r_t^l$ 高,见 Fig.2)→ offload 可行,前提是 高命中率 + 高有效带宽 + 计算通信重叠。
图/表优先 手动截图 放入
screenshots/,运行python3 scripts/figures/ess/install_screenshot.py --inbox;未手动的图仍可用python3 scripts/figures/ess/extract_paper_figures.py从 PDF 裁剪。
系统划分
| Cache | 占比 | ESS 策略 |
|---|---|---|
| Indexer-Cache | ~16.8% | 不 offload;每步全长算 indexer |
| Latent-Cache | ~83.2% | CPU Total Memory Pool 存全量;GPU Sparse Memory Pool 存热子集 |
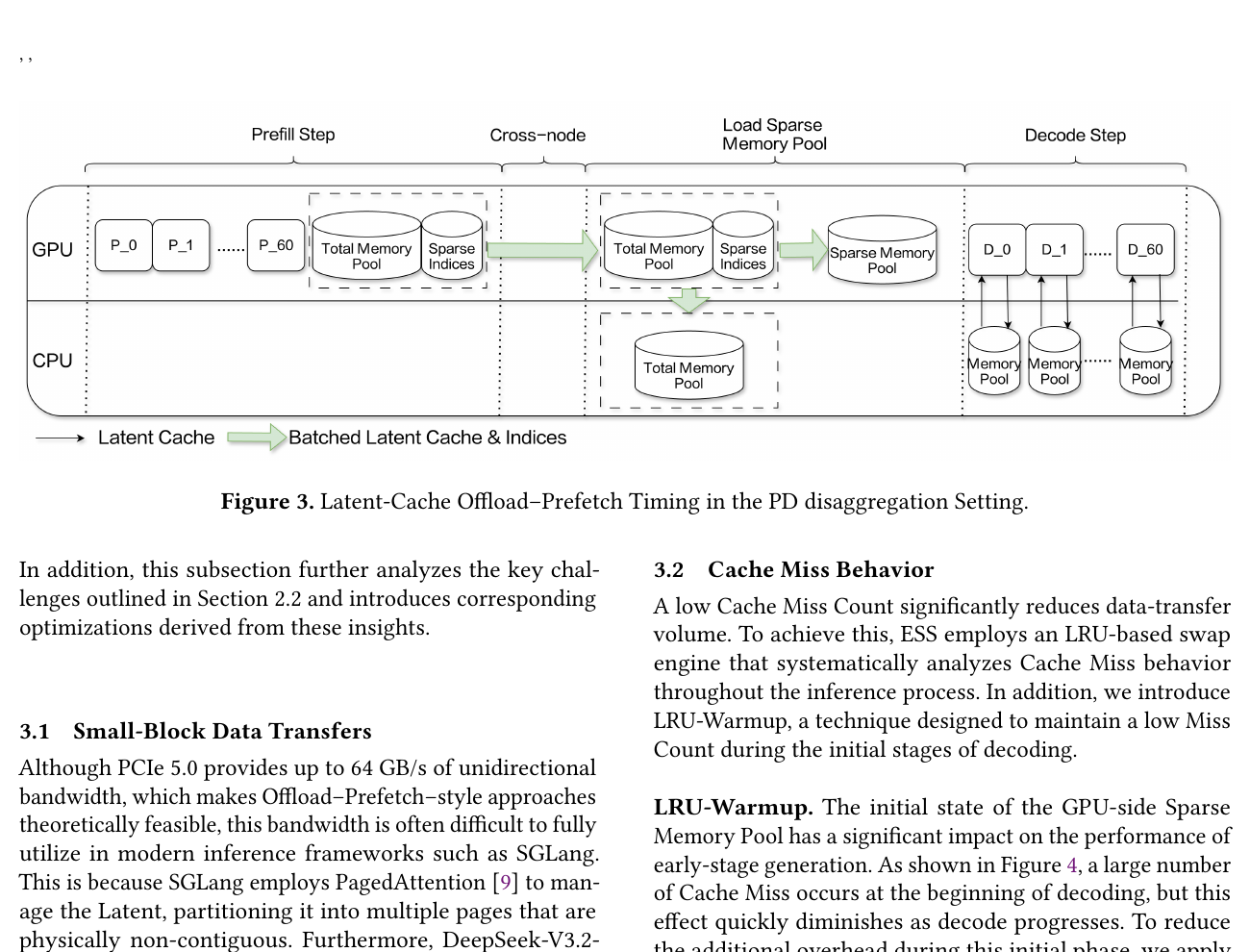
Figure 3. Latent-Cache Offload-Prefetch Timing in the PD disaggregation Setting.
关键图解读
Figure 1 — 吞吐 vs Batch Size
| 要点 | 内容 |
|---|---|
| 设置 | 32K context,配置见 Table 1 |
| 现象 | 理论上调 batch 应持续提吞吐,但 GPU 显存先满 |
| 数据 | batch 最多 52,吞吐封顶 ~9,648 tokens/s |
| 结论 | 显存是 Decode 扩容天花板 → 必须 offload Latent-Cache 才能继续加大 batch |
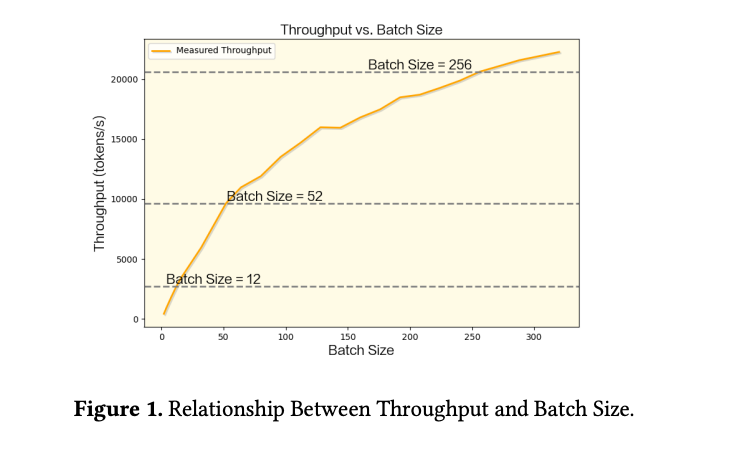
Figure 2 — 层内访问相似度
| 要点 | 内容 |
|---|---|
| 指标 | Intra-Layer Similarity $r_t^l = |K_{t-1}^l \cap K_t^l| / |K_t^l|$ |
| 含义 | 同一层、相邻 decode step 的 top-$K$ index 集合 重叠比例 |
| 数据 | LongBench V2 上 相似度持续偏高 |
| 结论 | Latent-Cache 访问有 强时间局部性 → CPU 扩展 HBM 有意义 |
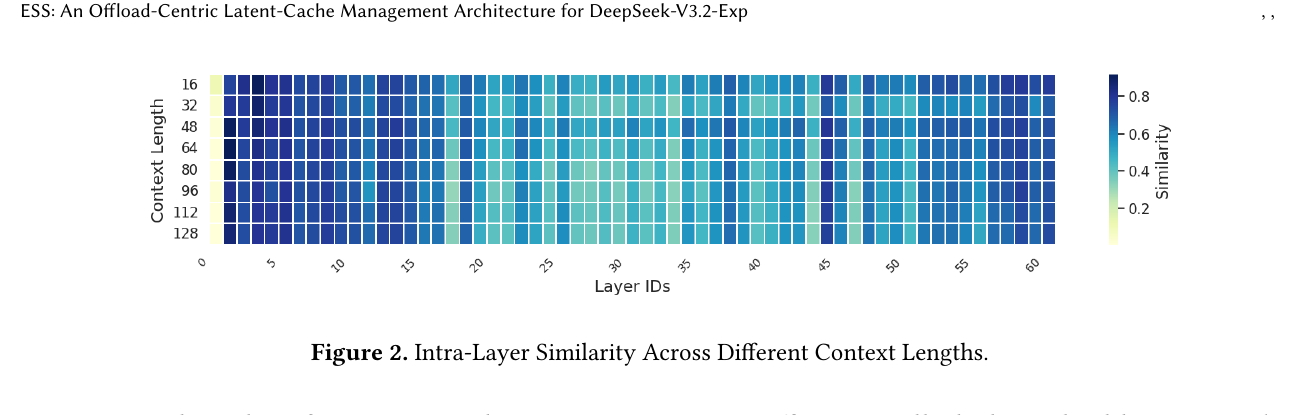
Figure 2. Intra-Layer Similarity Across Different Context Lengths.
Figure 3 — PD 架构下 Offload/Prefetch 时序
见 系统划分(Fig.3)(仅保留原图与图注,不重复解读)。
Figure 4 — LRU-Warmup 对早期 Cache Miss 的影响
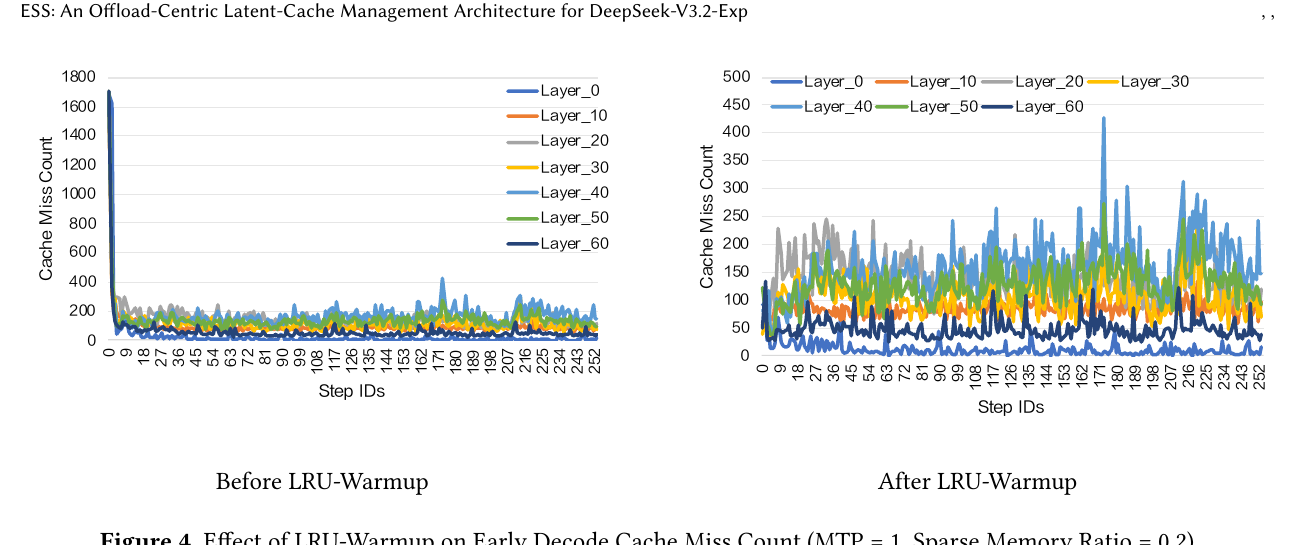
| 对比 | 现象 |
|---|---|
| Warmup 前 | Decode 开头 大量 Cache Miss,很快衰减 |
| Warmup 后 | 早期 miss 显著下降 |
| 做法 | 取 Prefill 最后 32 个窗口 的 top-2K index,预热 GPU LRU 池 |
| 设置 | MTP=1,Sparse Memory Ratio=0.2 |
Figure 5 — 层内 Cache Miss 分析
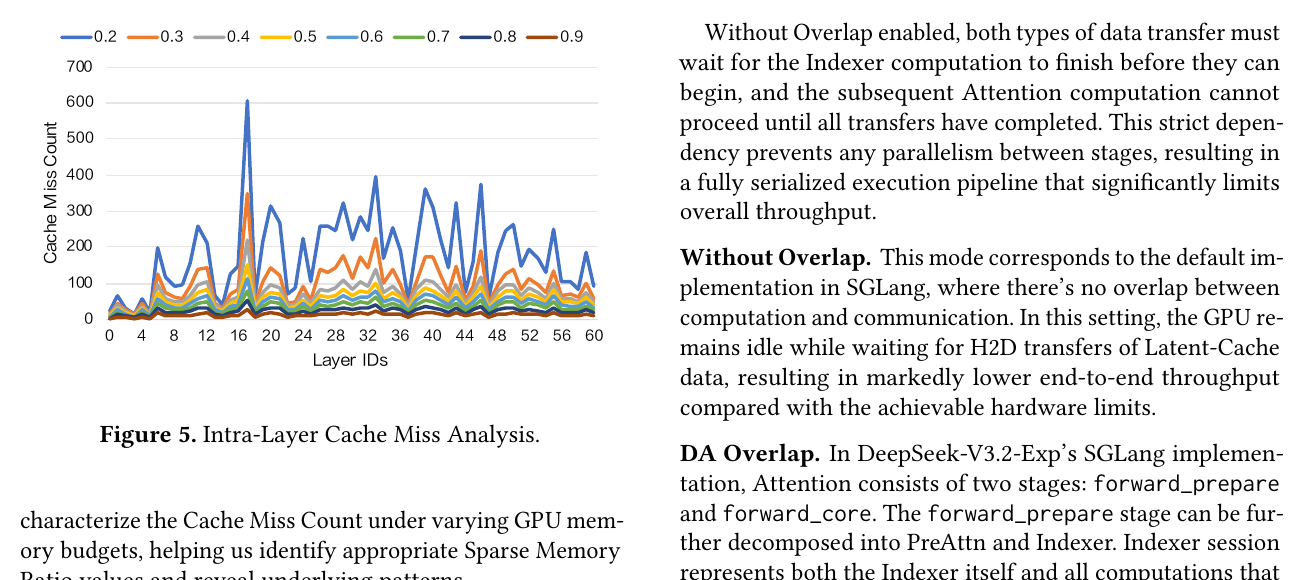
| 要点 | 内容 |
|---|---|
| 横轴 | Layer ID |
| 纵轴 | 每 batch 平均 Latent-Cache miss 数 |
| 变量 | 不同 Sparse Memory Ratio(GPU 侧占全 cache 比例) |
| 结论 | 不同层 miss 差异极大(Ratio=0.2 时约 16.66~605)→ 需要 按层选 Overlap 策略(见 Fig.7、§3.3) |
Figure 6 & 7 — Overlap 策略对比
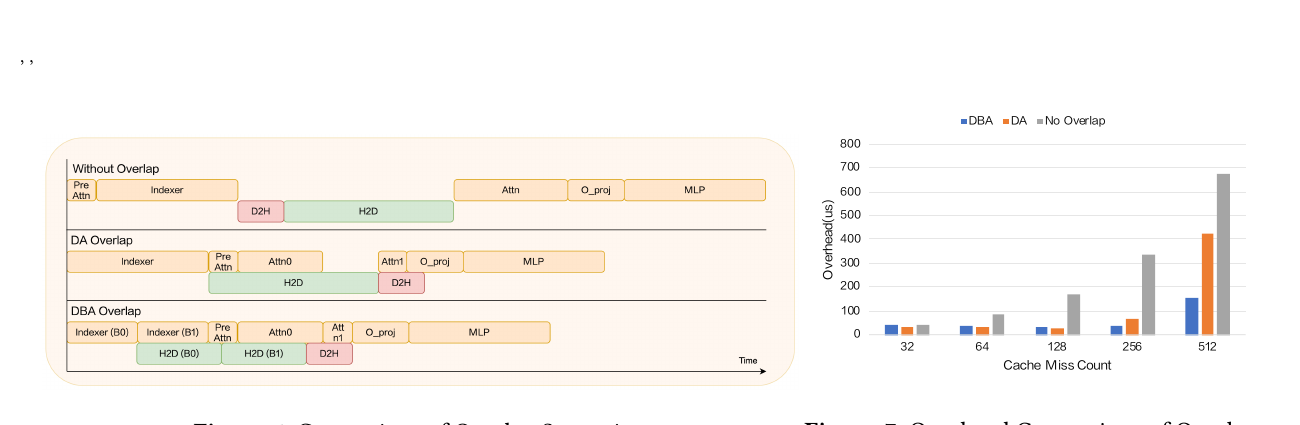
无 Overlap(SGLang 默认)
- H2D 必须等 Indexer 完成;Attention 必须等 H2D 完成 → 全串行,GPU 空等。
DA Overlap(Dual-Attention)
- 拆
forward_prepare:PreAttn 延后;SparseMLA 拆 Attn0(用 GPU 已有 latent)与 Attn1(等 prefetch)→ Attn0 ∥ H2D。
DBA Overlap(DualBatch-Attention)
- 在 DA 基础上 按 batch 维切 Indexer(含
paged_mqa_logits+ Top-K)→ 长上下文下仍有足够计算量掩盖传输。 - Fig.7 时间线:对比 DA vs DBA 的实际重叠程度。
Layer-Wise 选择规则
| Miss 水平 / 上下文 | 更优策略 |
|---|---|
| Miss 较低 | DA(无 Indexer 切分开销) |
| Miss 高(如达 512)、长上下文 | DBA(Indexer 计算随 $L$ 线性增,更能藏传输) |
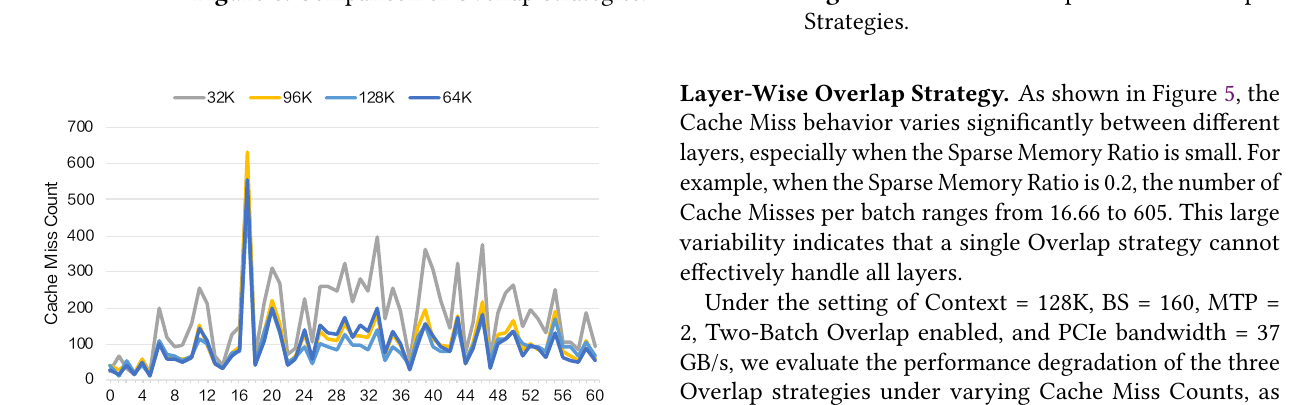
Figure 8 — 不同上下文长度下的 Cache Miss

- MTP=2,Ratio=0.2。
- 层维 miss 分布形态跨长度一致 → 可 离线 profiling 标出「高 miss 层」。
- 用于 Layer-Wise Overlap 的 静态分层配置。
Figure 9 — 可扩展性

| 发现 | 含义 |
|---|---|
| Ratio ≥ 0.2 时,平均 miss 随长度 相对稳定 | 长上下文下 offload 行为可预测 |
| 32K + 小 Ratio miss 最严重 | GPU 热池太小 → 频繁换入换出 |
| 同 Ratio 下,更长 context → 更低平均 miss | ESS 在 128K 等超长场景收益更大(与 Table 2 的 +123% 一致) |
| 建议 | GPU buffer 不小于 6.4K entry |
关键表解读
Table 1 — 仿真基线配置
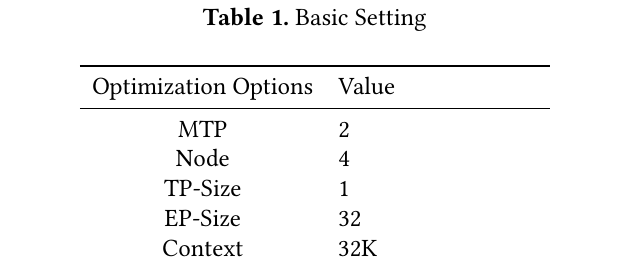
| 项 | 值 | 读表注意 |
|---|---|---|
| Model | DeepSeek-V3.2-Exp | 与 DSA 稀疏 attention 配套 |
| Context | 32K(主实验) | 128K 另有一组 |
| Node / EP | 4 node,EP=32 | 大规模 MoE 部署 |
| MTP | 2(主);Table 2 含 4 | 与 speculative 接受率联动 |
| MTP-Accept-Ratio | 1.7 | 影响有效 OTPS |
| Attention-Engine | FlashMLA | 与 DeepSeek 推理栈一致 |
| Two-Batch Overlap | open | 系统级重叠优化已开 |
| PCIe | 5th gen | FlashTrans 带宽前提 |
此表是 Fig.1、Table 2 默认行 的复现环境;改 MTP / 接受率 / 长度时只动 Table 2 中的变量。
Table 2 — 吞吐与 OTPS
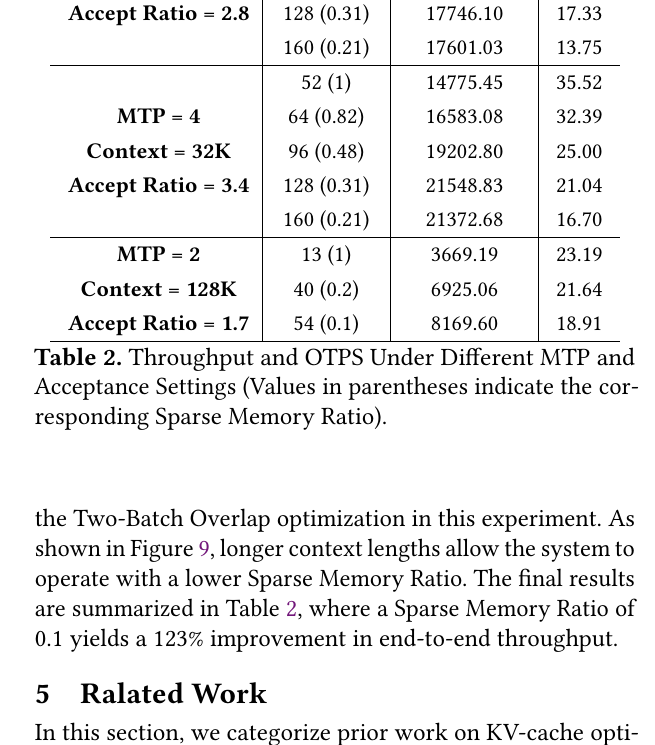
括号内为 Sparse Memory Ratio(GPU 热池占全 Latent-Cache 比例);Ratio 越小 → GPU 显存越省 → batch 可越大。
MTP=2,Context=32K,Accept=1.7
| Batch | Throughput (tokens/s) | OTPS | 相对基线 batch=52 |
|---|---|---|---|
| 52 (1.0) | 9,647.71 | 23.19 | 基线(全 GPU cache) |
| 64 (0.82) | 10,693.31 | 20.89 | |
| 96 (0.48) | 13,155.98 | 17.13 | |
| 128 (0.31) | 15,620.14 | 15.25 | |
| 160 (0.21) | 16,347.88 | 12.77 | +69.4% 吞吐 |
MTP=4,Context=32K — 接受率越高,绝对吞吐越高;ESS 仍随 Ratio 下降而扩容 batch。
MTP=2,Context=128K,Accept=1.7
| Batch | Throughput | Ratio | 备注 |
|---|---|---|---|
| 13 (1.0) | 3,669.19 | 基线 | 极短 batch 上限 |
| 40 (0.2) | 6,925.06 | ||
| 54 (0.1) | 8,169.60 | +123% 吞吐 |
读表要点
- Throughput ↑ 往往伴随 OTPS ↓:batch 变大、单 token 延迟结构变化;论文优化目标是 服务吞吐 / 成本,非单请求延迟。
- Ratio 从 1.0 → 0.1:用 CPU 换 GPU 显存,batch 可扩 3× 以上。
- 128K 行说明:越长上下文,ESS 相对收益越大。
三大工程模块
PD 分离下每步流程(对应 Fig.3):Prefill 结束 → Indexer 选 top-$K$ → prefetch 缺失 latent(H2D)→ Core MLA → 新 latent 写回 CPU(D2H)。Indexer 路径不搬;仅 Latent 在 CPU↔GPU 间流动。
| 模块 | 问题 | 方案 | 关键数字 |
|---|---|---|---|
| FlashTrans + UVA | 656B 碎片块,Memcpy 带宽差 | GPU 直接访 pinned CPU 地址 | H2D 0.79→37 GB/s;D2H 0.23→43 GB/s |
| LRU + Warmup | 早期 / 层间 miss 高 | Prefill 末 32 窗预热;LRU 保留高复用 entry | Fig.4、Fig.5 |
| DA / DBA / Layer-wise | 传输无法被计算掩盖 | Attn0∥H2D;按层选 DA 或 DBA | Fig.6–7 |
与静态/动态 KV 压缩、相关工作的边界
| 类型 | 代表 | 与 ESS 区别 |
|---|---|---|
| 静态压缩 | H2O、SnapKV、StreamingLLM | 永久删 KV;有损风险 |
| 动态选择 | Quest、MagicPig、RetrievalAttention | 每步只算子集,但 ESS 针对 V3.2-Exp 双 cache + 656B latent |
| Offload-Prefetch | FlexGen、SparseServe | ESS = DSA + MLA latent + PD + SGLang 的专用流水线 |
结论与局限
- 已验证:仿真中高保真;无损精度(只搬存储,不改 attention 数学)。
- 未做:论文写明 尚未并入生产框架;未来或与 SnapKV 等 有损压缩 组合。
- 本地对照:ESS Latent offload 概念页 · DSA 稀疏注意力 算法前置 · Index Share 正交 infra 补丁。
图表索引速查
| 图/表 | 一句话 |
|---|---|
| Fig.1 | 32K 下显存卡 batch=52 → offload 必要 |
| Fig.2 | top-$K$ index 逐步相似 → 局部性成立 |
| Fig.3 | PD 下 H2D/D2H 时序(仅图) |
| Fig.4 | LRU-Warmup 降早期 miss |
| Fig.5 | 各层 miss 不均 → 分层 overlap |
| Fig.6–7 | DA / DBA 时间线对比 |
| Fig.8–9 | 跨长度 miss 形态与可扩展性 |
| Table 1 | 仿真环境 |
| Table 2 | +69.4% / +123% 主结果 |
论文 PDF:arXiv:2512.10576