Thinking with Visual Primitives — 论文要点
← 演进总览 §3.8 · ← 中文导读 · ← V4 梗概 PDF:Visual Primitives 原文 PDF · DeepSeek-AI + 北大 + 清华 · 2026
一句话
在 DeepSeek-V4-Flash 语言骨干上,把 点 / 框 等视觉原语当作 CoT 的「最小思维单元」交错写入推理链,配合 DeepSeek-ViT → 3×3 patch 压缩 → CSA 4× KV 压缩,800×800 输入在 KV cache 中仅保留约 90 条 视觉 entry,却在多项空间推理 benchmark 上对标 GPT-5.4 / Gemini-3-Flash 等前沿 MLLM。
1. 问题:Reference Gap
| 瓶颈 | 说明 |
|---|---|
| Perception Gap | 「Thinking with Images」靠高分辨率裁剪补感知 |
| Reference Gap | 自然语言难以精确指向复杂空间布局 → 多步空间推理易逻辑崩溃 |
| 本文 | 用 visual primitives(bbox / point)作无歧义空间指针,与文本 CoT 交错 |
2. 架构:V4-Flash + ViT 双模块
LLaVA 式:DeepSeek-ViT 编码图像 → 与文本 token 交错 → V4-Flash(284B / 13B act MoE)生成带 visual primitives 的回复。
Figure 2 — 架构与训练管线
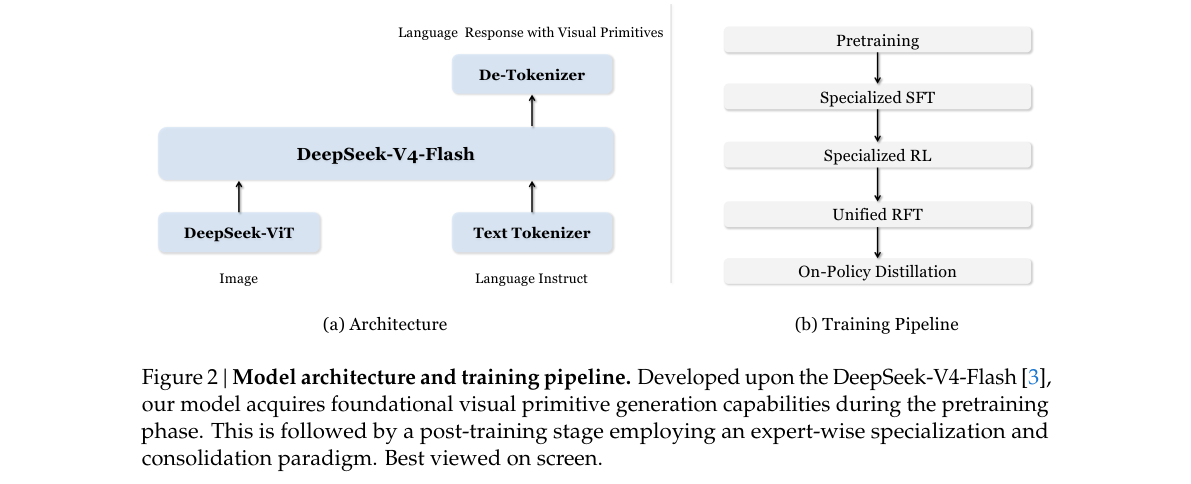
Figure 2 | Model architecture and training pipeline(论文原图截取)。
| 模块 | 要点 |
|---|---|
| DeepSeek-ViT | 自研 ViT;14×14 patch;任意分辨率 |
| 3×3 spatial compression | ViT 输出每 9 个 patch token 通道维合并为 1 |
| V4-Flash LLM | 继承 CSA:视觉 token 在 KV cache 再 4× 压缩 |
| 训练阶段 | Pretrain(输出 primitives)→ 分域 SFT/RL → Unified RFT → On-Policy Distillation |
数值示例:
| 阶段 | Token / entry 数 |
|---|---|
| ViT patch tokens | 2,916 |
| 3×3 压缩后进 LLM | 324 |
| CSA 后进 KV cache | 81 |
| 总压缩比 | 7,056×(像素 → KV entry) |
与纯文本 V4 线的衔接:同一 CSA 稀疏压缩 机制,此处用于 视觉 KV 而非仅长文本 context。
3. Visual Primitives 定义
| 原语 | 用途 |
|---|---|
| Bounding box | 物体位置与尺度;标注相对确定 |
| Point | 轨迹、拓扑推理等抽象引用 |
Pretrain 目标:模型能在 CoT 中 生成 上述原语(De-Tokenizer 解码为可视化 marker)。
Figure 3 — Cold-start 计数数据示例

Figure 3 | Illustrative cold-start data for coarse-grained and fine-grained counting.
| 要点 | 说明 |
|---|---|
| 数据形态 | 图像 + 语言指令 + 框/点 标注作为监督 |
| 粗 vs 细 | 粗粒度全图计数;细粒度带属性/空间约束 + hard negative |
| 动机 | 公开 COCO / Pixmo 规模与多样性不足 → 大规模 web box grounding(97k+ 源) |
4. Token 效率
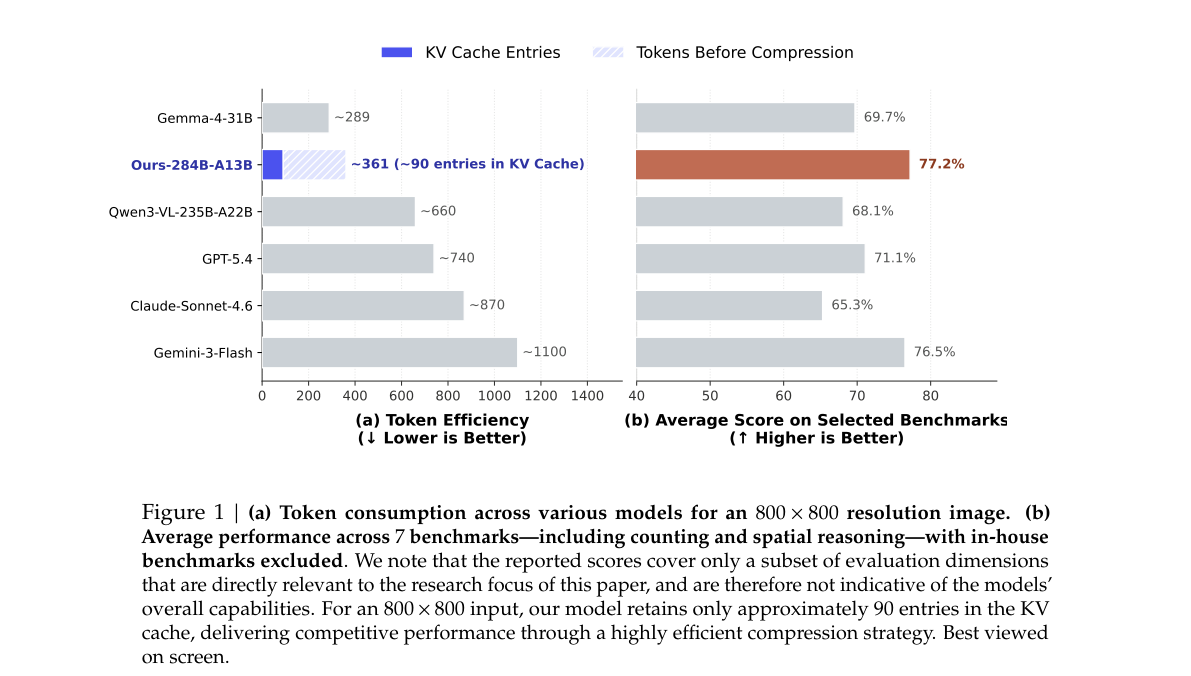
Figure 1 | (a) Token consumption for 800×800 image. (b) Average score on selected benchmarks.
| 子图 | 解读 |
|---|---|
| (a) Token 数 | 800×800 输入:本文约 361 tokens(KV 约 90 entries);Gemini-3-Flash ~1100;Claude-Sonnet-4.6 ~870 |
| (b) 均分 | 7 项 benchmark 子集均分 77.2%,高于 GPT-5.4(69.7%)、Gemini-3-Flash(65.3%)等 |
| 结论 | 极低视觉 KV 占用 下仍保持 competitive 空间推理——压缩链(ViT + CSA)是核心 infra 叙事 |
5. Table 1 — 与前沿模型对比
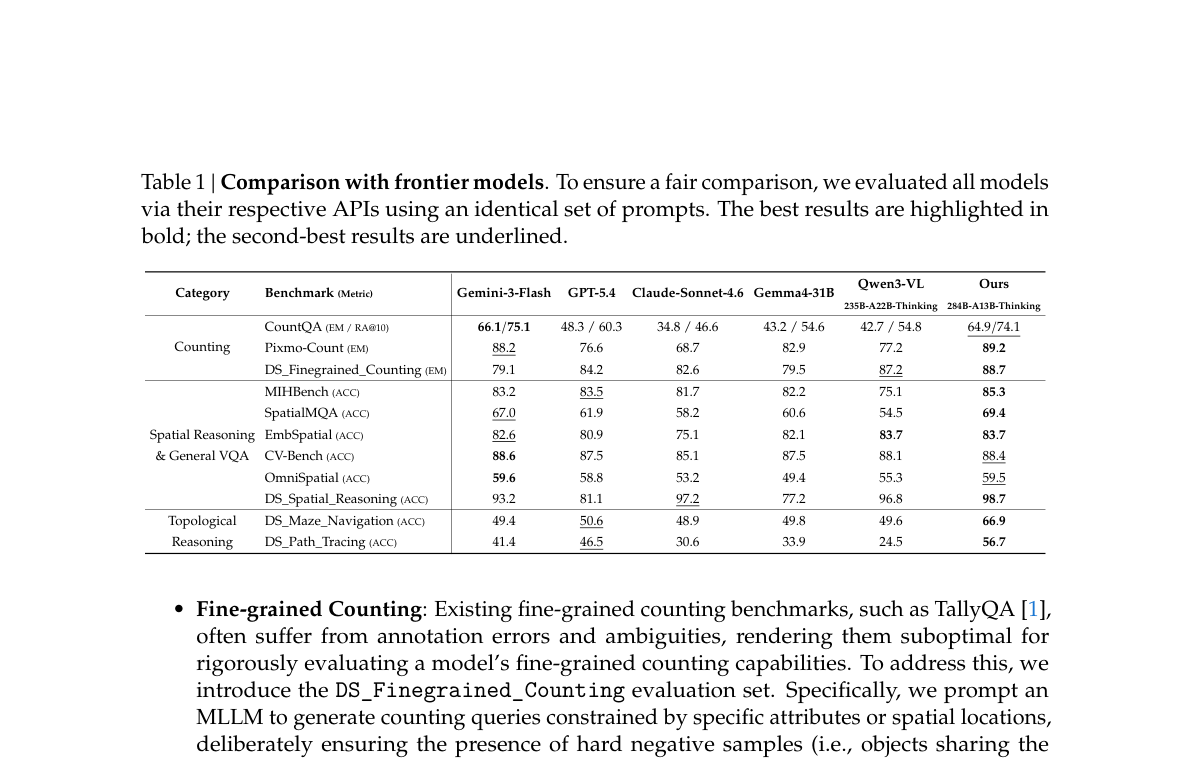
Table 1 | Comparison with frontier models(API 统一 prompt 评测;bold=最佳,underline=次佳)。
| 类别 | 代表 benchmark | 本文亮点 |
|---|---|---|
| Counting | CountQA、Pixmo-Count、DS_Finegrained_Counting | 细粒度计数 88.7 EM(DS_Finegrained) |
| Spatial VQA | MIHBench、SpatialMQA、CV-Bench | SpatialMQA 69.4;MIHBench 85.3 |
| Topological | DS_Maze_Navigation、DS_Path_Tracing | 迷宫 66.9、路径追踪 56.7,大幅领先 Qwen3-VL 等 |
论文强调:表内分数仅覆盖与 visual primitives 研究相关的评测维度,不代表模型全能。
6. 与 DeepSeek 主线关系
| 维度 | 衔接 |
|---|---|
| 基座 | V4-Flash(284B/13B)— 见 演进总览 §3.7 |
| Attention / KV | 复用 CSA 4:1 压缩 → 视觉 KV 81 entries 量级 |
| MoE | 与 V4 Hash MoE / FP4 同代推理栈 |
| 定位 | V4 主线之后的 多模态支线:不改 LLM 稀疏注意力叙事,增加 ViT + 原语 CoT |
7. 图/表索引
| 文件 | 论文 |
|---|---|
| Figure 1 — Token 效率 | Figure 1 |
| Figure 2 — 架构与训练管线 | Figure 2 |
| Figure 3 — Cold-start 计数 | Figure 3 |
| Table 1 — Benchmark 对比 | Table 1 |
重新截取:python3 scripts/figures/papers/extract_visual_primitives.py