摘要
LCM(Lossless Context Management)是一套面向大模型的确定性上下文管理思路:一旦对话逼近上下文上限,我的目标不是删消息,而是把历史收成一棵分层摘要 DAG,同时把所有原始消息落在可查询的存储里(实现上常用 SQLite 这类嵌入式库)。这样做的直接结果,是送进模型的窗口看起来变短了,但只要沿着 DAG 展开,我仍能无损回到任意一条原文——压缩只发生在「给模型看的那一层」,不发生「从事实层抹掉证据」。
为什么要换掉「阈值一到就整段摘要」
长对话里,我能用的 token budget 是硬顶;还要预留余量,否则模型没有空间现场写摘要。常见做法是:用量爬升到大约 80% 预算就触发一次大段批量摘要,把尽量多的旧消息揉成一条扁平摘要,换出窗口空间。
我介意这种做法,主要因为它在工程上省窗口,在事实与可控性上亏本:
- 摘要往往要 1~2 分钟才能跑完,期间用户体验和时序都很难编排;
- 扁平之后,结构和细粒度一起消失,模型后面容易记串、和早先决策打架、反复问已经说清的事;
- 一旦细节被摘要「覆盖」,我很难再问压缩前到底写了什么——可追溯性断了。
所以我在对比 LCM 时,心里始终有一条标准:省 token 可以,但不能以「永久丢证据」为代价。

对照意图:下面一行是「预算触顶 → 整坨摘要 → 细节难复原」;上面是 token 压力随轮次累积的过程。
我的总体取舍:分层压缩 + 源数据永远在库里
拉长对话时,我仍要面对同一件事:token 只会越来越多。差异在于接近上限时,我不截断、不物理删,而是:
- 把更早的内容收成摘要节点,并显式挂上指向源消息的引用;
- 摘要可以多层(更像树/DAG),越往上越「提纲」化;
- 库里始终保存全量原文;模型窗口里出现的,只是当前最合适的投影。
这样一来,「给模型看的上下文」和「我手下掌握的全部事实」是分开的两层:前者要短,后者要全。
新鲜尾部(Fresh Tail):我为什么坚持留一截永远不压
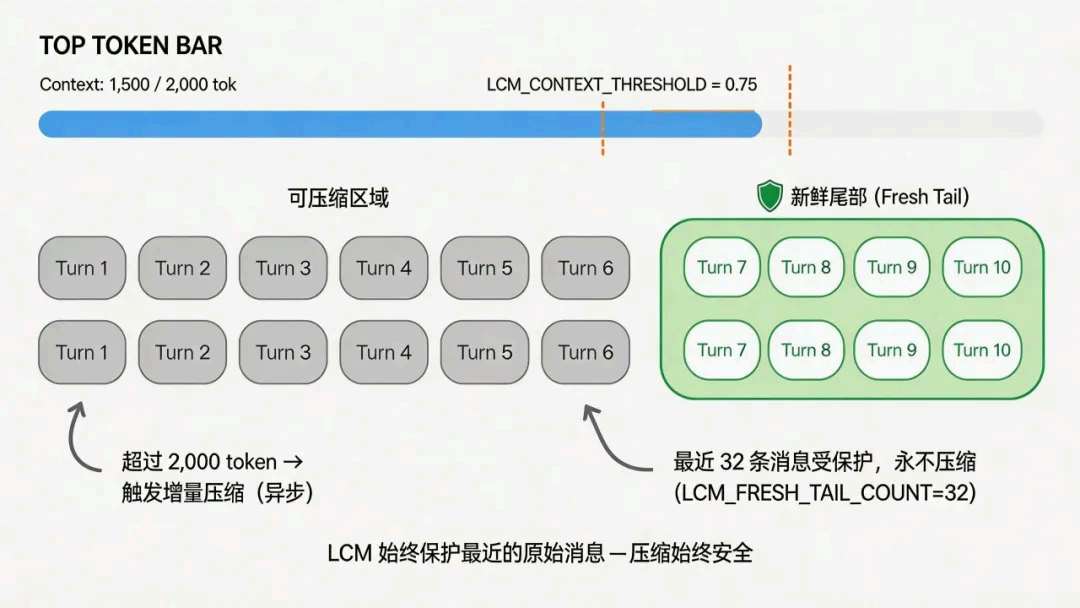
我刻意让最近若干轮原始消息始终完整进窗——这是我说的新鲜尾部。原因很简单:当前话题的指代、半句没说完的约束、刚改过的参数,几乎都挤在这一段;一旦把「刚才」也压进摘要,我立刻付出交互断层和反复确认成本。
具体参数可以按产品调,例如让最近 32 条不参与压缩(LCM_FRESH_TAIL_COUNT=32),并用 TOP TOKEN BAR 一类 UI 持续盯住已用量;何时动手压缩,我用 ~75% 预算之类阈值提前预警(LCM_CONTEXT_THRESHOLD),避免撞墙才慌。
当「尾部以外的、仍原样躺在窗口里的旧消息」合计超过大约 2000 token 这一档,我就触发增量压缩——而且我会让它异步跑:不把用户卡在压缩完成,因为体验上压缩是后台家务,对话是前台主线。
源消息已经落库时,我更放心:压缩动的是摘要节点与呈现关系,不是在数据库里 DELETE 对话——这也是「lossless」在我这儿的第一层含义:存储层不丢行。
增量压缩(深度 0):我为什么用结构化提示、又为什么留钩子
满足规则的一批旧消息,会带着结构化压缩提示进模型;出来的是深度 0摘要。我让摘要去替换窗口里那一段的「展开前视图」,但在 DAG 里边不拆:指向源消息的引用还在,后面用工具或子 Agent 还能按需展开。
深度 0 的提示我偏向明确几件事,都是为后面的轮次服务:
- 留住决策、理由、约束、进行中的任务——这是后面推理真正要继承的状态;
- 清掉重复与寒暄——否则浪费后续每一枪的 token;
- 结尾留一句「若要细节可展开某某块」式的导航线索,让检索不必盲搜。
如果不留引用与钩子,我就又回到「摘要一盖,考古只能靠猜」的老路。
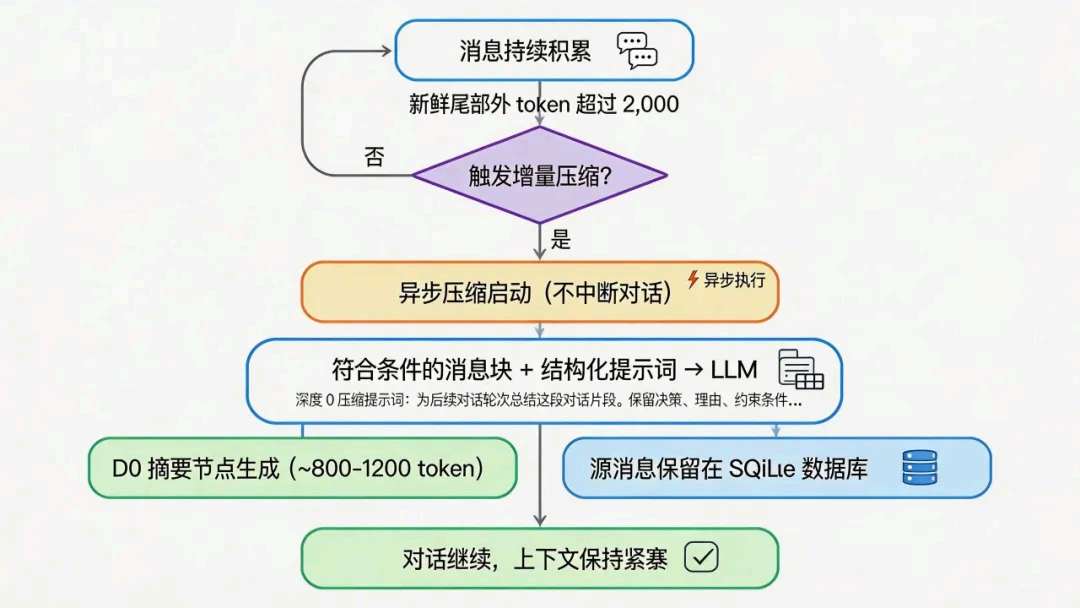
关系说明:被选中块经深度 0 变成摘要节点;源消息仍在库里,主对话继续在更短的上下文中推进。
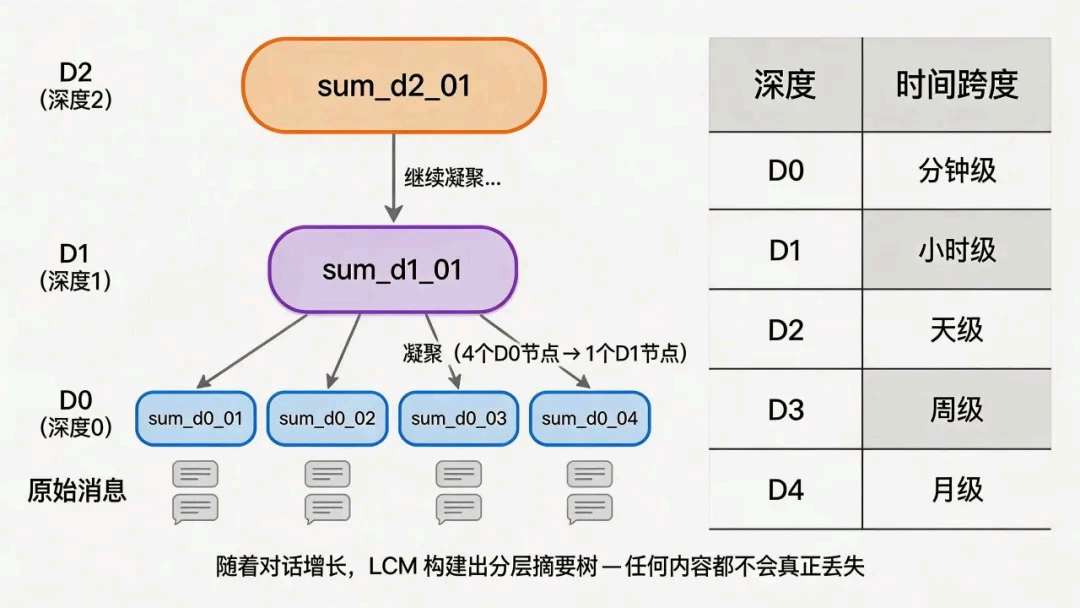
凝聚(Condensation)与多深度:我为什么又要「再摘要一层」
同一深度上摘要节点攒到足够多的话(例如4个一组),我会做凝聚:把几个兄弟摘要再提成更高一层的父节点。父层用的提示必须不同于深度 0——因为输入已经是摘要而非原文,我要它抓脉络而不是复述碎碎念:决策结果、阻塞点、仍在跑的任务线,以及带时间戳的关键事件轴。
时间尺度上我通常这样理解各层职责(也可用分钟 / 小时 / 天 / 月去直觉对齐「越往上,覆盖越长」):
- 深度 0:尽量保留可执行的细节与为什么这样定;
- 深度 1:讲清怎么演变到现在、当前卡在哪;
- 深度 2:收长期仍有效的承诺与里程碑,希望数周后回头看还能当地图用。
没有分层的话,要么摘要太短兜不住长历史,要么一长串摘要又把窗口撑爆——多层本质是在信息密度和可导航性之间再做一次折中。
当 DAG 已经很大时,我喂给「主对话模型」的仍是一条短主线拼新鲜尾部;库里没有消息被删掉,它们只是不再默认全部摊在面上。
主 Agent 与 DAG:我为什么必须上子 Agent、还必须限预算
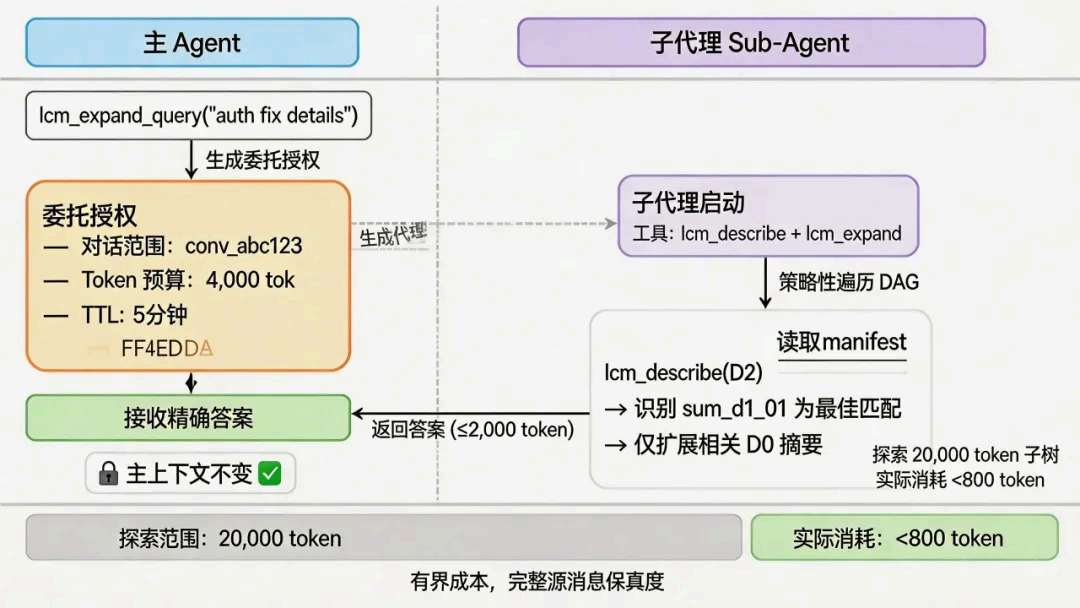
一个深度 2节点背后,动辄上万 token原文。若我为了回答用户一句追问,就把整条子树塞回主 Agent,等于自杀式胀窗,马上触发下一轮压缩——这和我的目标相反。
所以我把「在图里走路」交给子 Agent,并给它隔离上下文:它可以在例如 ~20k token 的可探索子树上规划路径,但用 describe → 有选择 expand 的方式,把真正进上下文的量压在几百到一千 token这一档,主 Agent 宽度不变,却能从很久以前的轮次里抠出原句级细节。
我依赖的几件工具,分工是:
| 工具 |
我为什么要它 |
lcm_describe |
先摸清子树「摘要侧多大、源侧多大、有哪些子节点」,再决定从哪下刀,避免盲展开。 |
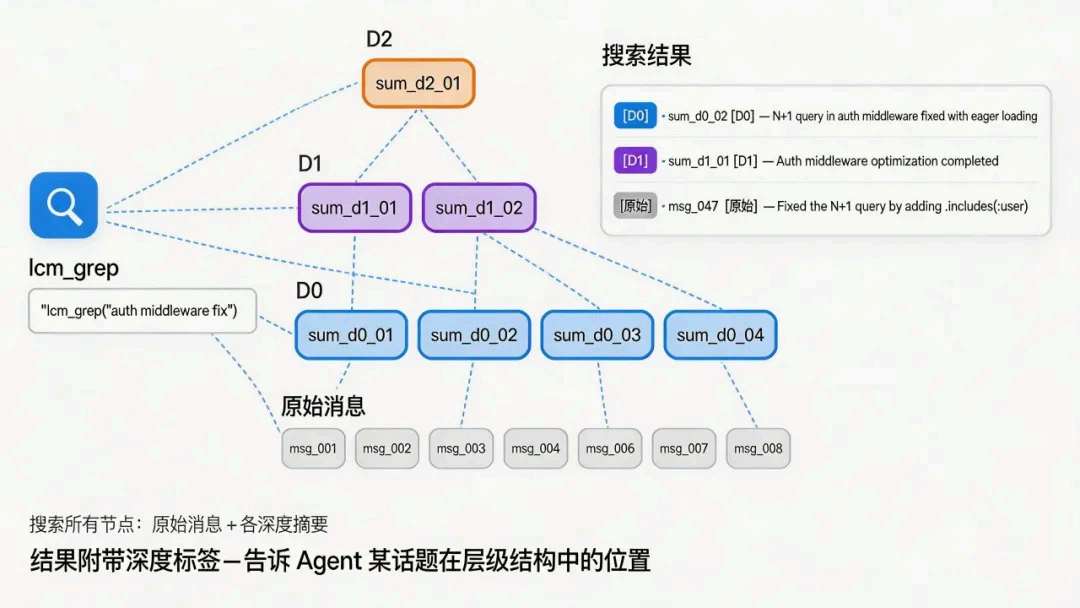
lcm_grep |
在各层节点里关键词命中,结果带深度,我知道该往抽象层还是往叶子挖。 |
lcm_expand / lcm_expand_query |
需要证据链时,用委托授权之类机制派出子 Agent,在硬预算内做策略性遍历。 |
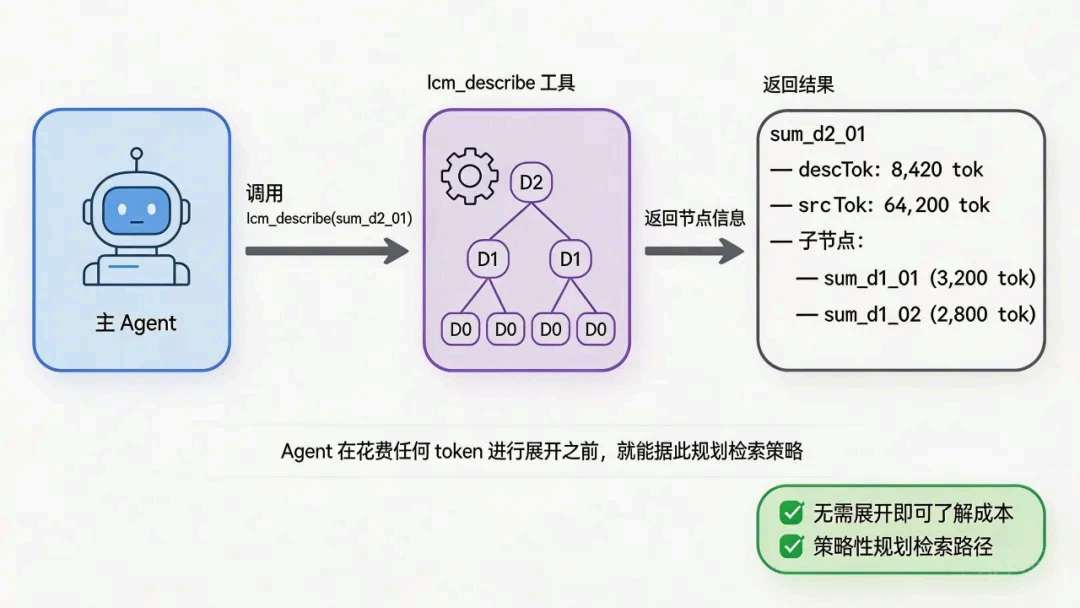
子Agent侧我会给足 lcm_describe / lcm_expand,但把 token 预算(例如 4000)和 TTL 卡死:先看图,再只展开最相关子树。典型情况是:可探索范围量级在 ~20k token,实际吃进模型的可以压到 800 token 以下——主上下文不动,远端细节却仍能对齐回来。
结语
我是在「上下文必须短」和「事实必须可追溯」之间搭一座桥:推理仍交给 LLM,骨架与记忆由分层 DAG、持久原文和一套有界检索工具一起扛。这样我才能既要产品上的响应与成本,又要工程上的可审计与可回滚。
参考链接
- 论文/技术页:https://papers.voltropy.com/LCM
- 开源实现:https://github.com/martian-engineering/lossless-claw
- 站点:https://losslesscontext.ai



















