说明
底本为 Language Models Interview Handbook(© 2026 Lamhot Siagian, AI Engineering Insider);版权归原作者所有;个人学习整理,转载请注明出处并勿用于商业再发行。
第 1 章 导论、基础与 LLM 职业路线图
本章概述
开始之前,先看下roadmap:从系统层面交代大语言模型是什么、现代 LLM 栈怎么拼、学习路线怎么摆,并点出 GenAI 相关岗位与interview正在强调哪些能力与趋势。后文按「分词 → 嵌入 → 注意力 → 检索 → 适配 → 评测 → 服务」依次展开,正是同一条主线。
在一场扎实的interview里,候选人很少一上来就背架构名词。更常见的做法是先框定工作负载:模型在哪创造业务价值?周边系统(surrounding system)又怎样把「裸模型能力」变成可上线的产品?这里要练的,正是这种框定问题的习惯(framing mindset)。
Interview Anchor interview锚点
| 维度 | 内容 |
|---|---|
| interviewer真正想测的 | 能否把 LLM 讲成工程系统,而不是孤立的科研热词。 |
| 高质量回答套路 | 先把 LLM 定义为「预训练的下一 token 预测模型」,再说明它如何嵌入更大的应用栈;把该栈与检索、提示、评测、服务、治理以及可量化的产品结果串起来。 |
| 常见低分答法 | 直接跳到具体模型名或媒体 hype。加分答法会交代:要解决的任务是什么、数据怎么走、有哪些可靠性控制、在灵活性 / 成本 / 风险之间如何权衡。 |
INTERVIEW CHEATSHEET interview速记条
| 项 | 要点 |
|---|---|
| 要表达的亮点 | LLM 不是整个产品;它只是推理与生成引擎,处于更大的「检索—工具使用—评测—交付」工作流之中。 |
| 最佳举例 | 解释为什么一个客服助手除了基座模型之外,还需要:提示设计、检索质量、监控、升级(escalation)规则与输出控制。 |
| 可延展方向 | 提及学习路线:从分词、注意力到 RAG、PEFT、服务、评测与治理。 |
| 资深候选人可加 | 把多模态、更小的专用模型、推理优化等行业趋势与真实产品取舍挂钩。 |
| 切忌这样说 | 把 LLM 工程等同于「只会 Prompt」,却不谈数据、质量度量与运维约束。 |
基础:LLM 究竟是什么
大语言模型是在极大规模上训练、用于预测序列中下一个 token 的神经网络。这个目标看似简单,却能让模型内化关于句法、事实、结构、风格与任务行为的统计规律——训练语料规模巨大。
但在interview中,只说到「会生成文本」往往不够。更应再往上抽象一层:LLM 的价值在于可被嵌入到各类工作流中,用于分类、检索、摘要、基于工具的推理,以及结构化输出草稿等。
也正因如此,本书才会从分词与嵌入,一路写到检索、适配、提示、评测与服务。这些层次并非为「好学」硬凑,而是决定一套 GenAI 系统能不能真有用、有据、够快、够安全、经济上站得住的分层。
1.1 在现代 LLM 技术栈上学习与interview的实用路线图
先看下面的图1.1
这张图把全书收成一串循序渐进的学习层(learning layers)。顺着它能看出:为什么前面的章节得先讲「机制」,后面才把重头戏放在检索、适配与部署——而不是停在基座概念就收官。
这张图要紧,还因为太多候选人底层机制还没讲清楚就直奔时髦话题。按作者画的顺序,先把机制压实,再谈产品形态、评测与部署。
作者在图里把六块排成两行:上行从左到右是 Layer 1~3(文本、Token、上下文 → 嵌入与注意力 → 预训练与模型家族);下行从左到右是 Layer 5、4、6,分别是适配、PEFT 与评测,检索、RAG 与提示,服务、治理与产品化。这不是随便贴标签:前三层对应「模型和数据怎么表示、怎么训出来」;后三层是「怎么嵌进检索与提示链路、在资源与风险下怎么适配和度量、怎么交付和治理」。
图下角两句英文 Use this as a study plan… 和 Hiring loops often test these later layers…,可直述为:把这张图当学习计划,顺序是「机制 → 系统设计 → 生产权衡」;interview里更爱追问后几层,因为那才看得出工程判断,而不是只会背名词。
图 1.1 如下;文字说明见上节和下表。
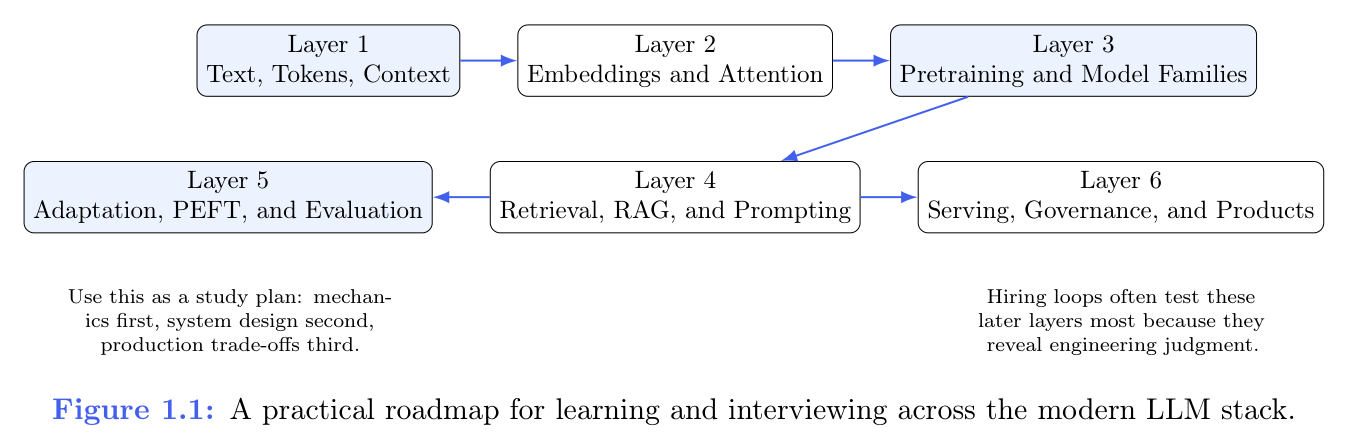
Figure 1.1 。
下表把六层和书中英文用语对齐(顺序按图中 Layer 编号):
| Layer | 英文 | 汉译 |
|---|---|---|
| 1 | Text, Tokens, Context | 文本、Token 与上下文 |
| 2 | Embeddings and Attention | 嵌入与注意力 |
| 3 | Pretraining and Model Families | 预训练与模型家族 |
| 4 | Retrieval, RAG, and Prompting | 检索、RAG 与提示 |
| 5 | Adaptation, PEFT, and Evaluation | 适配、PEFT 与评测 |
| 6 | Serving, Governance, and Products | 服务、治理与产品化 |
Figure 1.1 :A practical roadmap for learning and interviewing across the modern LLM stack.
LLM 与 GenAI 岗位的学习路线
对多数工程师而言,最有效的路线是分层的,而不一定是按年份线性排布:
- 先掌握文本基础与模型机制;
- 再理解检索如何改变上下文质量;
- 然后学习适配与服务怎样让系统可上生产;
- 在此基础上,再专精某一方向:评测、Agent、多模态、安全或垂直 Copilot 等。
同一套分层视角也适用于简历与interview叙事:你可以清楚说自己最强的是「检索 + 评测」,还是「服务 + 优化」,或是「把 Agent 工作流产品化」。这比笼统声称「我什么都懂」要可信得多。
表 1.1 把全书锚在当前产业方向上——刻意没写成 hype 词表;每一行对应团队怎么招人、项目边界怎么划、技术深浅怎么辨。
你可以把它当作优先级过滤器:真正拉开的差距,往往不在多刷一节泛泛的模型课,而在能不能讲清检索质量、评测、推理约束,以及人在回路(human in the loop)该留在哪儿。
表 1.1 对工程学习路线与interview预期影响最大的 LLM 趋势
| 趋势 | 为何重要 | 强候选人应能讨论什么 |
|---|---|---|
| 更长的上下文窗口 | 更多内容能塞进 prompt,但无关上下文仍会伤害答案与成本。 | 为何在模型已支持很大窗口时,检索、排序、上下文压缩仍然关键。 |
| 多模态系统 | 许多企业与消费场景下,纯文本已非默认。 | 图像、音频或文档输入如何改变评测、延迟与体验设计。 |
| 更小的专用模型 | 团队常在前沿质量 vs. 成本 / 可控性 / 部署灵活性之间做权衡。 | 何时选用更小的任务型模型、PEFT 或路由(routing),而不是永远调用最大模型。 |
| 评测与治理 | 产品规模化后,信任与度量比 demo 更难。 | 离线 / 在线评测、幻觉控制、护栏、升级路径与监控。 |
| 推理优化 | 成本与延迟越来越多地决定 LLM 产品是否成立。 | 量化、批处理、缓存、结构化输出与输出 token 预算纪律。 |
| 工具使用与 Agent | 真实产品往往把语言模型与 API、数据库、工作流引擎结合。 | 规划 vs. 执行、工具选择、状态管理与人机协同控制。 |
图 1.2 全书思维导图
这张图作者刻意画得很高层,可作「章节怎么串」的可视化目录:后面再读到 PEFT、服务、多模态,仍可纳入同一条系统叙事,而不是一摞互不相关的interview梗。
自表示走向系统来读:把机制和产品、生产约束接在一起说,口述会顺很多。
中心结点是 LLM Interview Mastery,可理解为「LLM interview要掌握的全貌」。分支英文名保留,右列为常用汉译:
- Tokens and Context — Token 与上下文
- Embeddings and Retrieval — 嵌入与检索
- Attention and Model Design — 注意力与模型设计
- RAG and Grounding — RAG 与 Grounding(译名沿用通用说法)
- Fine-Tuning and PEFT — 微调与 PEFT
- Serving and Decoding — 服务与解码
- Governance and Deployment — 治理与部署
- Multimodal Systems — 多模态系统
它们和上一节六层路线图在书里是同一套逻辑;导图更强调「从概念簇到交付与治理」整块形状。
图 1.2 如下(中心结点、分支与箭头;有的结点在印刷版里是浅色高亮)。
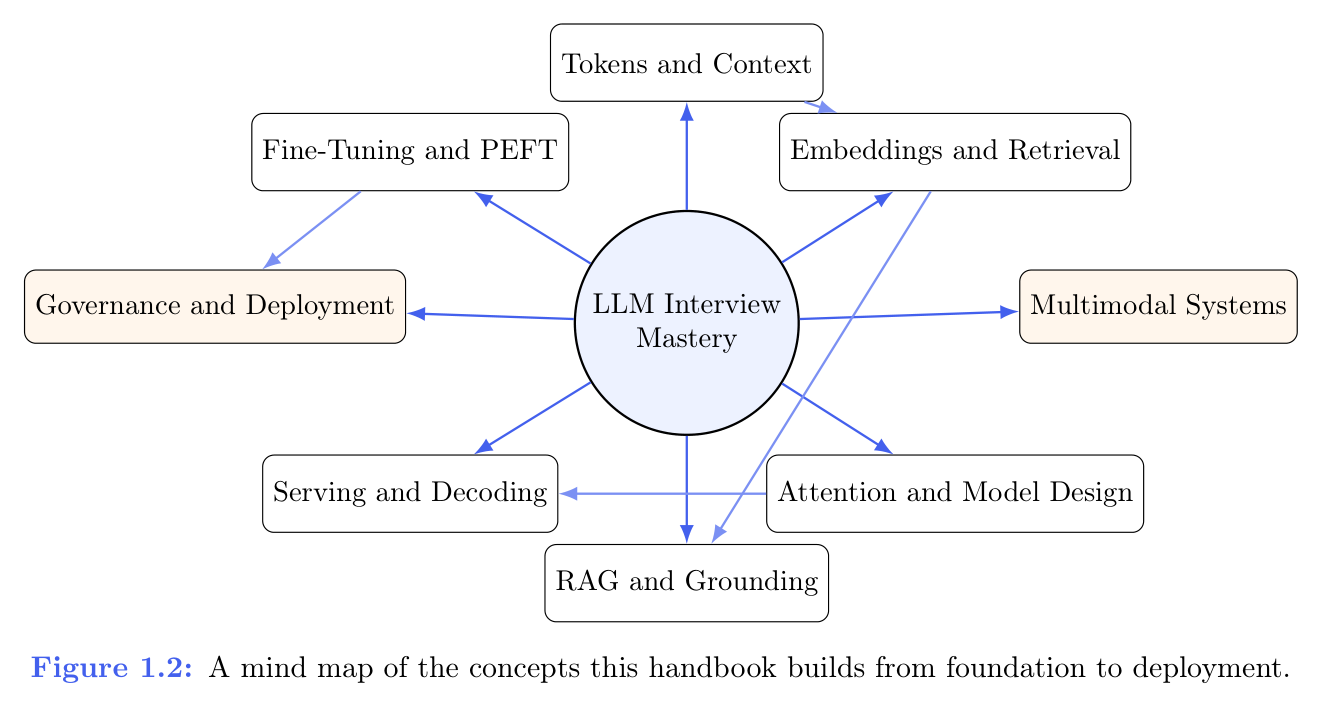
Figure 1.2 。
Figure 1.2 :A mind map of the concepts this handbook builds from foundation to deployment.
Extra Note:LLM / GenAI 岗位的简历结构建议
Bonus Layer
一份有竞争力的「大模型方向」简历,读起来应像一份工程系统说明,而不是热词拼贴。招聘方想看到的是你对真实工作负载的 ownership 证据:评测、检索质量、Agent 编排、可靠性、安全与可量化影响。
作者把简历建议放在第一章,用意之一是让读者把职业叙事和书里这套栈对齐——做过什么、怎么度量、怎么扛权衡。
表 1.2 把「LLM 简历该长什么样」落成可检查的章节清单。
| 板块 | 应证明什么 | 推荐写法模式 |
|---|---|---|
| 标题与摘要 | 与岗位的清晰对齐 | 一句话定位,例如「构建生产级 LLM、RAG 与评测系统的 AI 工程师」,再加 3–4 个高价值专长。 |
| 核心技能 | 技术深度,而非堆关键词 | 按 LLM 栈 / 检索栈 / 服务栈 / 云与可观测 / 评测分组,而非随机罗列工具。 |
| 经历 bullet | 可度量的 ownership | 先写构建的系统,再写决策或优化,最后量化相关性、延迟、成本、可靠性或采纳度。 |
| 项目 | 自驱与完整闭环 | 至少一个旗舰项目:架构、评测闭环、失效控制与部署形态。 |
| 公开信号 | 市场可信度 | GitHub、技术文章、演讲或产品——且与同一叙事相互印证时再写。 |
「强候选人」一句话
「LLM 产品是围绕模型的一整套系统;能答得最漂亮的人,能讲清从分词与嵌入,到检索、适配、服务、评测,以及商业上每一层凭什么站得住。」
表 1.3 如何把经历 bullet 写得像「工程证据」
| 档次 | 示例 |
|---|---|
| 偏弱 | 「参与了聊天机器人与检索流水线。」 |
| 更好 | 「为内部支持助手搭建 BM25 + 向量的混合检索流水线,在评测中提高了有依据命中,并减少了幻觉型回答。」 |
| 更好(带约束与指标) | 「设计 BM25 + 向量检索 + 重排 + 引用校验的内部支持助手流水线,有依据答案命中率提升约 18%,升级工单量下降,且中位响应时间仍满足产品 SLO。」 |
| 为何有效 | 同时体现系统设计、决策质量、可量化结果与工程约束管理。 |
可以记住的三点
- LLM = 系统里的引擎,检索、评测、服务与治理与「会不会写 Prompt」同等重要。
- 学习/叙事尽量按「机制 → 系统 → 生产」分层,再选专精方向。
- 简历与口述尽量用事实、指标与权衡说话,避免空泛热词。
继续阅读:第 2 章:Token、分词与上下文窗口。