说明
底本为 Language Models Interview Handbook(© 2026 Lamhot Siagian, AI Engineering Insider);个人学习整理,转载请注明出处,勿用于商业再发行。
第 7 章 主题建模、聚类与规模化主题发现
本章概述
主题发现回答的问题与分类不同。分类把数据映射到已知的桶;主题建模与聚类则帮助揭示你事先并未定义的模式。现代 LLM 系统常常把嵌入、聚类与摘要结合起来,在评论、工单、研究论文或客服对话里发现主题。
interview里最完整的答法要同时讲清统计侧与产品侧:发现簇只是第一步;更难的是命名、校验、监控漂移,以及让下游团队真正用得上。
Interview Anchor interview锚点
| 维度 | 内容 |
|---|---|
| interviewer真正想测的 | 能否从原始文本走到可解释的主题,且不把无监督发现与有标注真值混为一谈。 |
| 高质量回答套路 | 讲清从表示到分组再到解释的流水线,并说明人类如何验证簇是否真的有用。 |
| 常见低分答法 | 把簇名吹成事实。主题发现是探索性的,严重依赖表示质量与评估设计。 |
INTERVIEW CHEATSHEET interview速记条
| 项 | 要点 |
|---|---|
| 要表达的亮点 | 主题发现是表示 + 评估问题,不只是选哪种聚类算法。 |
| 最佳举例 | 客服工单常要先做基于嵌入的分组,再由人命名主导主题。 |
| 可追问方向 | 提到降维、簇的可解释性,以及在重跑或新数据上的稳定性。 |
| 资深补充 | 把探索性洞察生成与生产环境类目体系标注区分开。 |
| 切忌这样说 | 把无监督簇标签当成客观真理。 |
书中主题发现示意图把无监督分析与生产工作流串起来:当标注、校验与迭代环绕在聚类步骤周围时,主题建模才最强。
图 7.1(A practical theme-discovery flow from raw corpus to validated topic labels.):
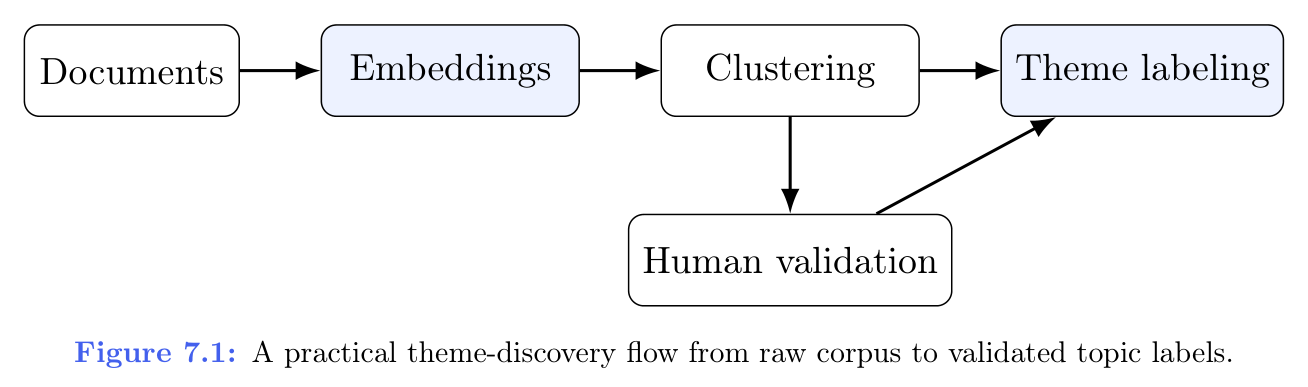
What Strong Candidates Sound Like
「优秀的主题发现流水线把簇当作假设——必须经过解释与验证,而不是算法的自动真理。」
问答
Q51. 主题建模与分类有何不同?
答。 分类是有监督的,从预先定义好的标签集合出发。主题建模通常是探索性的,试图从数据本身挖掘潜在主题。目标不是把每条样本硬塞进已有类目体系,而是发现能反过来塑造类目体系的结构。
实务上,团队常在搭建正式类目体系之前做主题发现:它有助于暴露反复出现的问题、隐藏的子群体,以及真实用户使用的说法。interview里应明确:主题建模重在模式发现,分类重在决策指派。
Q52. 为什么基于嵌入的聚类在主题发现里越来越常见?
答。 基于嵌入的方法把每个文本单元表示在语义向量空间里,因此聚类可以把概念上相关、但并不共享相同关键词的条目归到一起。这对客户反馈、支持日志、研究语料特别有用——人们会用很多种说法描述同一类问题。
吸引力在于可落地:嵌入带来更好的语义分组,而 LLM 又能对发现的簇做摘要或命名。对产品团队来说,这种组合往往比仅靠传统主题–词表更有用。
Q53. 规模化主题发现有哪些实务流水线?
答。 常见流水线是:清洗文本 → 选定分析单元 → 嵌入 → (可选)降维 → 对向量聚类 → 抽取代表性样本 → 最后用 LLM 或人工审阅给簇打标签。最后几步很关键,因为原始簇不会自我说明。
interview里要提到:可扩展性依赖批处理、近似索引、增量更新,以及用于审阅的抽样策略。主题建模系统要按数据产品来设计,而不是只做笔记本实验。
Q54. 为什么工程师常在聚类前先降维?
答。 高维嵌入空间可能嘈杂,某些聚类算法也难以干净地划分。降维可以凸显局部结构、起到一定去噪作用,并让簇在视觉上或算法上更容易分开。
代价是:若使用不当,降维可能扭曲距离。强答应强调:降维是工具,不是默认必做。在它能改善簇结构或可解释性时使用,然后用代表性样本验证结果,而不是只信一张图。
Q55. 主题发现里如何选聚类算法?
答。 取决于你对数据形态的预期。K-means假设簇大致球形,且需要事先选定 k。基于密度的方法能捕捉不规则形状并分离噪声点,对真实文本数据往往有用。层次化方法适合想要由粗到细探索的场景。
interview里要体现判断而非站队某个品牌:合适算法依赖数据分布、规模以及对可解释性的需求。没有哪种聚类能拯救糟糕的嵌入或含糊的分析单元。
Q56. 怎样给簇命名,业务方才真正用得上?
答。 有用的簇标签应概括主题,而不是简单重复最高频词元。好标签通常来自顶部词项、代表性样本,以及能看到足够证据的 LLM 或人工概括者的组合。
最好的标签是可操作的:「结账流程中的账单摩擦」比「支付问题相关词」更有用。interview里可点明:簇命名既是建模问题,也是人因 / 沟通问题。
Q57. 主题随时间演变时怎么处理?
答。 产品变化、事件发生、新说法进入语料,都会让主题漂移。生产系统因此应支持周期性重嵌入、增量聚类,或按时间段切片分析,让团队能看到主题是在增长、萎缩、分裂还是合并。
这里监控很重要:主题发现不是一次性报告。interview里要表现出:你理解主题演化是时序分析问题,不只是静态 NLP 任务。
Q58. 怎样评估「发现的主题」好不好?
答。 好的主题在内部连贯、彼此区分度高,且对决策者有用。自动指标可以参考,但人工检视代表性样本仍然必不可少。若一个簇里语义混杂,标签很可能误导人,即便某个分数「看起来还行」。
强答应强调:评估要同时看统计连贯性与分析师可用性。问题不只是「簇存在吗?」,而是「产品、运营或研究团队能据此行动吗?」
Q59. LLM 如何改进主题建模工作流?
答。 LLM 在聚类之后特别有用:可以标注主题、概括代表样本、比较相邻簇,并从大语料生成人类可读的洞察;在潜在主题被发现后,也能帮助搭建类目体系。
要注意的是:LLM 生成的摘要即使措辞漂亮,底层簇仍可能很乱。interview里应说:LLM 改善解释与汇报,但簇质量仍须用原始样本做验证。
Q60. 团队做规模化主题建模时常见错误有哪些?
答。 常见错误包括:分析单元选错、对噪声套话做聚类、过度解读孱弱的可视化,以及把自动生成的标签当真理。另一类错误是忽视时间漂移,假设同一套簇会永远稳定。
最强的interview回答是强调校验:主题发现应被视为迭代的意义建构。目标是可信的洞察,而不只是好看的图表。