说明
底本为 Language Models Interview Handbook(© 2026 Lamhot Siagian, AI Engineering Insider);个人学习整理,转载请注明出处,勿用于商业再发行。
第 3 章 嵌入与语义表示
本章概述
嵌入(embedding)把离散文本变成稠密向量,使语义相近的条目在向量空间里彼此靠近。它们是语义检索、聚类、重排序、推荐以及许多检索增强生成(RAG)系统的骨干。若说分词回答的是「如何把文本切开?」,嵌入回答的则是「如何把意义用数值表示出来?」
表示学习方面的实践文献表明,可以训练出有用的语义向量,使相关句子、文档或图文对在嵌入空间中占据邻近区域。Sentence-BERT 使句子级相似检索远比逐对交叉编码(cross-encode)高效;其后多模态工作如 CLIP 则将同一思想扩展到文本与图像(Reimers & Gurevych, 2019; Radford et al., 2021)。
Interview Anchor interview锚点
| 维度 | 内容 |
|---|---|
| interviewer真正想测的 | 是否理解嵌入是为几何结构与任务效用而优化的数值表示,而不只是从 API 调出来的「高级向量」。 |
| 高质量回答套路 | 说明嵌入捕获了什么、为何相似性是几何的而非纯词面的,以及这如何影响检索、聚类、推荐、重排与评估。 |
| 常见低分答法 | 暗示所有嵌入模型可互换。应提到任务错配、领域漂移,以及检索质量与生成质量的差异。 |
INTERVIEW CHEATSHEET interview速记条
| 项 | 要点 |
|---|---|
| 要表达的亮点 | 嵌入把语义关系压缩进向量空间,使距离可充当意义的代理。 |
| 最佳举例 | 检索查询应能召回相关文档,即便措辞与原文并不相同。 |
| 可追问方向 | 提到余弦相似度、稠密检索,以及嵌入质量如何依赖训练目标与领域契合。 |
| 资深补充 | 区分第一阶段召回与第二阶段重排及评估。 |
| 切忌这样说 | 把向量检索当成必然为真的机制,而不是概率性相关性流水线中的一环。 |
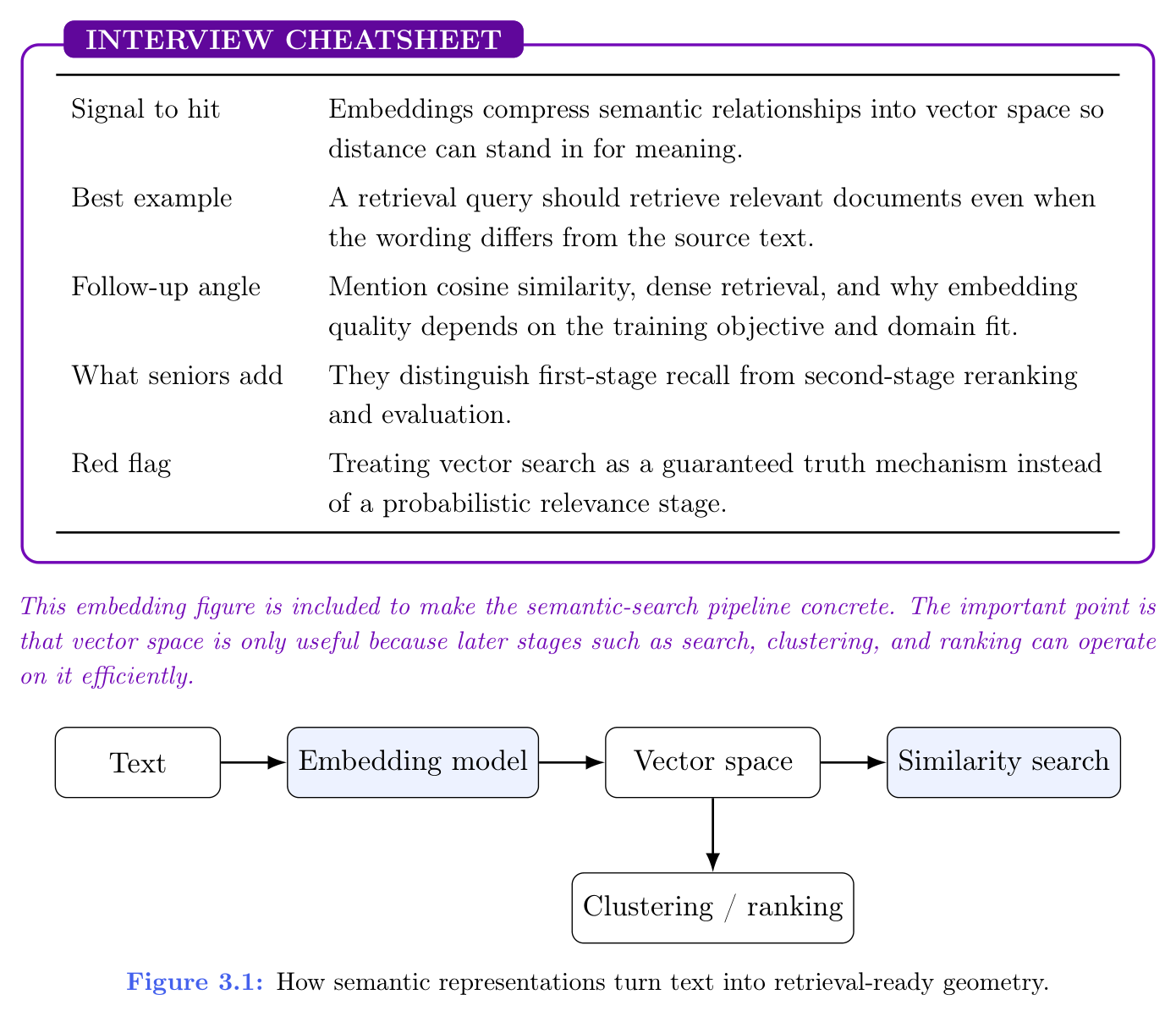
书中嵌入示意图旨在把语义检索流水线说具体。要点是:向量空间之所以有用,是因为后续的检索、聚类、排序等阶段能高效在其上运算。
图 3.1(How semantic representations turn text into retrieval-ready context.):
下面的余弦相似度片段让嵌入讨论保持可感:即便上游模型很复杂,语义检索最终仍归结为数值比较。
Listing 3.1:用归一化向量做的最小语义相似度示例。
1 | from math import sqrt |
强烈建议
「嵌入有用,是因为它们让语义邻近变得可度量,从而使检索、聚类、推荐系统能超越纯关键词重合而扩展规模。」
问答
Q11. 什么是嵌入(embedding)?
答。 嵌入是一个稠密数值向量,以保留有用关系的方式表示词元、句子、文档、图像或其它对象。不把文本当作简单 ID 查表,模型把它映射到连续空间,使距离与方向能编码语义相似性。
通俗地说,嵌入让机器能在不只靠精确关键词匹配的情况下比较意义。因此它们是语义检索与 RAG 的核心。稳健的interview回答应包含两层:嵌入是学出来的数值表示;其价值在于把语义比较变成向量运算。
Q12. 为什么嵌入使语义检索成为可能?
答。 语义检索能工作,是因为相关条目不必词面完全相同——只要嵌入彼此靠近即可。关于「physician salary growth」的查询,仍可能召回写「doctor compensation trends」的内容,因为向量编码的是相关含义,而非严格词面重叠。
这使嵌入在问答、支持库检索和长尾用户表述中特别有用。需要注意的是:稠密相似度也可能召回概念相邻但错误的内容,因此嵌入检索很强,却不会自动精确。这也是生产系统常叠加元数据过滤、词面匹配或重排序的原因。
Q13. 词元嵌入、句子嵌入与文档嵌入有何区别?
答。 词元嵌入表示模型输入层上单个词元的身份,属于模型内部处理的一部分,通常不直接用于检索。句子嵌入把整句压成一个面向语义比较的向量。文档嵌入在更大粒度上做同样的事,常用池化或块级聚合。
interview要点是表示与任务对齐。词元嵌入适合内部语言建模,但不同于检索用嵌入。对检索与聚类,你通常需要显式训练以在该粒度上保持语义相似的句子或块嵌入。
Q14. 工程师为何常对嵌入做 L2 归一化?
答。 归一化把向量缩到单位长度,使相似度主要取决于方向而非原始模长。这使余弦相似度与点积行为更一致,常能提升检索稳定性,尤其在样本间向量范数差异很大时。
实务上,归一化也简化索引行为与阈值设定。没有归一化时,某个向量可能只因更大而在比较中占主导,而非因语义。interview可补充:归一化不是万能药;它是为提升可比性的设计选择,但是否合适取决于嵌入如何训练以及索引如何计算相似度。
Q15. 何时用余弦相似度,而不用点积?
答。 核心思想。 当你希望相似度反映语义方向而非原始向量大小时,用余弦相似度。余弦比较的是向量夹角;点积同时混合角度与长度,因此高范数向量可能胜出,即便在意义上并非最近邻。
余弦通常更稳妥的情况。 当嵌入范数在样本间变化大、模型文档建议基于余弦的检索,或你希望排序对训练/预处理引入的尺度差异不那么敏感时,优先余弦。
注. 若嵌入已 L2 归一化,则对排序而言余弦相似度与点积等价(因每个向量长度均为 1)。在生产中,真正的规则是一致性:采用你的嵌入模型、向量索引与离线评估流水线共同设计的那套度量。错配会在嵌入本身不变的情况下,悄悄改变检索质量。
Q16. 嵌入空间中的 hubness 与各向异性(anisotropy)是什么?
答。 Hubness 指某些向量对过多查询都表现为最近邻的匹配倾向。各向异性指向量空间分布不均,大量嵌入挤在相似方向上。两者都会损害检索质量,因为索引不断浮出过于泛化的条目。
interview不必过度理论化。清晰回答是:并非所有嵌入空间对最近邻检索都同样「健康」。若出现过宽、重复文档被反复检索,应排查归一化、微调质量、负采样与重排,而不是默认怪向量数据库。
Q17. 稠密表示与稀疏表示有何区别?
答。 稠密表示是连续向量,多数维度非零。稀疏表示是高维信号,只有少数维度活跃,如词袋或 BM25 式词面匹配。稠密方法更擅捕获语义相似;稀疏方法更擅保留精确词项命中的证据。
在生产中,这往往不是哲学选择,而是召回与精确率的权衡。稠密检索能找到概念相关文本;稀疏检索能防止漏掉精确术语、姓名、编码或产品 ID。因此混合检索*在许多企业系统中已成为默认方案。
*Q18. 双编码器(bi-encoder)与交叉编码器(cross-encoder)有何区别?
答。 双编码器独立编码查询与候选文本,再比较其向量。这使检索快且可扩展,因为候选向量可预计算。交叉编码器把查询与候选一起处理,允许更丰富的交互,但推理成本高得多。
有用的心智模型是:双编码器像快速图书管理员拉出短名单;交叉编码器像仔细审稿人,把每个入围条目与查询并排细读。interview应强调常见模式:双编码器负责召回,交叉编码器负责重排。
Q19. 嵌入维度如何影响系统设计?
答。 更高维嵌入能捕获更细的区别,但也会增加存储、内存带宽与索引成本。更低维更便宜更快,却可能损失检索保真度,尤其在复杂领域。
因此合适维度是系统决策,不只是模型选择。interview应谈完整权衡:向量大小影响索引占用、延迟、缓存效率与重嵌入迁移成本。优秀工程师不只问「什么最准?」,还问「在真实流量下什么能扩展?」
Q20. 在生产使用前如何评估嵌入模型?
答。 在与实际任务一致的设置上评估嵌入。对检索,测 Recall@k、MRR、NDCG以及下游答案质量。对聚类,看纯度或人工可解释性。对推荐,看邻居是否有意义地相关,而非仅数值上近。
最强的interview回答是:离线向量相似度本身不够。嵌入应在将要驱动的完整流水线里测试。句子级基准有用,但最终问题永远是:嵌入是否改善了业务相关的检索或决策质量。