说明
底本为 Language Models Interview Handbook(© 2026 Lamhot Siagian, AI Engineering Insider);个人学习整理,转载请注明出处,勿用于商业再发行。
第 8 章 大规模语言模型系统的检索基础
本章概述
检索是连接静态模型知识与新鲜、领域特定信息的核心桥梁。检索增强生成(RAG)提供了一种实用方式,把存在模型权重里的参数化记忆,与存在索引、文档与知识库里的非参数化记忆结合起来(Lewis et al., 2020)。
本章聚焦「如何找到对的证据」这一机制:词汇检索、稠密检索、混合检索、切块、排序、过滤与评估。优秀候选人明白:很多时候,好的 LLM 答案始于一个好的检索问题。
Interview Anchor interview锚点
| 维度 | 内容 |
|---|---|
| interviewer真正想测的 | 能否把检索讲成带召回、精确率、切块、重排、元数据与评估的信息系统,而不只是「选一个向量库」。 |
| 高质量回答套路 | 先讲为何需要检索,再按索引 → 切块 → 召回 → 重排 → 元数据过滤 → 离线评估串起来。 |
| 常见低分答法 | 只谈向量存储,却忽略切块、文档清洁程度与重排往往才是质量主导因素。 |
INTERVIEW CHEATSHEET interview速记条
| 项 | 要点 |
|---|---|
| 要表达的亮点 | 检索质量取决于表示、切块、过滤、排序、新鲜度与评估。 |
| 最佳举例 | 同一模型在知识库如何切块与排序不同时,表现可以天差地别。 |
| 可追问方向 | 提到一阶段召回与二阶段重排,以及文档级元数据过滤。 |
| 资深补充 | 把检索视为可度量子系统,自带指标与回归测试。 |
| 切忌这样说 | 说「我们用了向量」就好像单凭这一点就能解释有据质量。 |
书中用检索记分卡让讨论落在可度量的系统行为上,从含混的「相关性」叙事,转向你能实际评估的维度。
表 8.1:interview中可讨论的紧凑检索记分卡
| 指标 | 检验什么 | 为何重要 |
|---|---|---|
| Recall@k | 相关证据是否出现在候选集里 | 召回低则生成器永远看不到正确事实 |
| Precision@k | 返回的上下文是否大多为有用内容 | 噪声会浪费上下文窗口并抬高胡编风险 |
| MRR 或 nDCG | 检索块之间的排序质量 | 强重排能在不重建全量索引的情况下提升可问答性 |
| 新鲜度检查 | 在需要时能否检索到新近文档 | 在政策与运维类领域可避免陈旧答案 |
下面的切块小工具说明:重叠(overlap)是检索设计选择,而不仅是排版便利。实现刻意保持短小,以便读者聚焦召回上的取舍。
Listing 8.1:一个简单的切块辅助,用重叠换取更好召回。
1 | def chunk_text(tokens, chunk_size=400, overlap=60): |
What Strong Candidates Sound Like
「检索才是有据 LLM 质量通常输赢所在的地方——因为生成器只能在我们成功捞出并排好序的证据之上推理。」
下面的检索流程示意图把切块、索引、排序与生成连成一条有据路径,便于说明召回问题与胡编问题从哪里开始分道扬镳。
图 8.1:
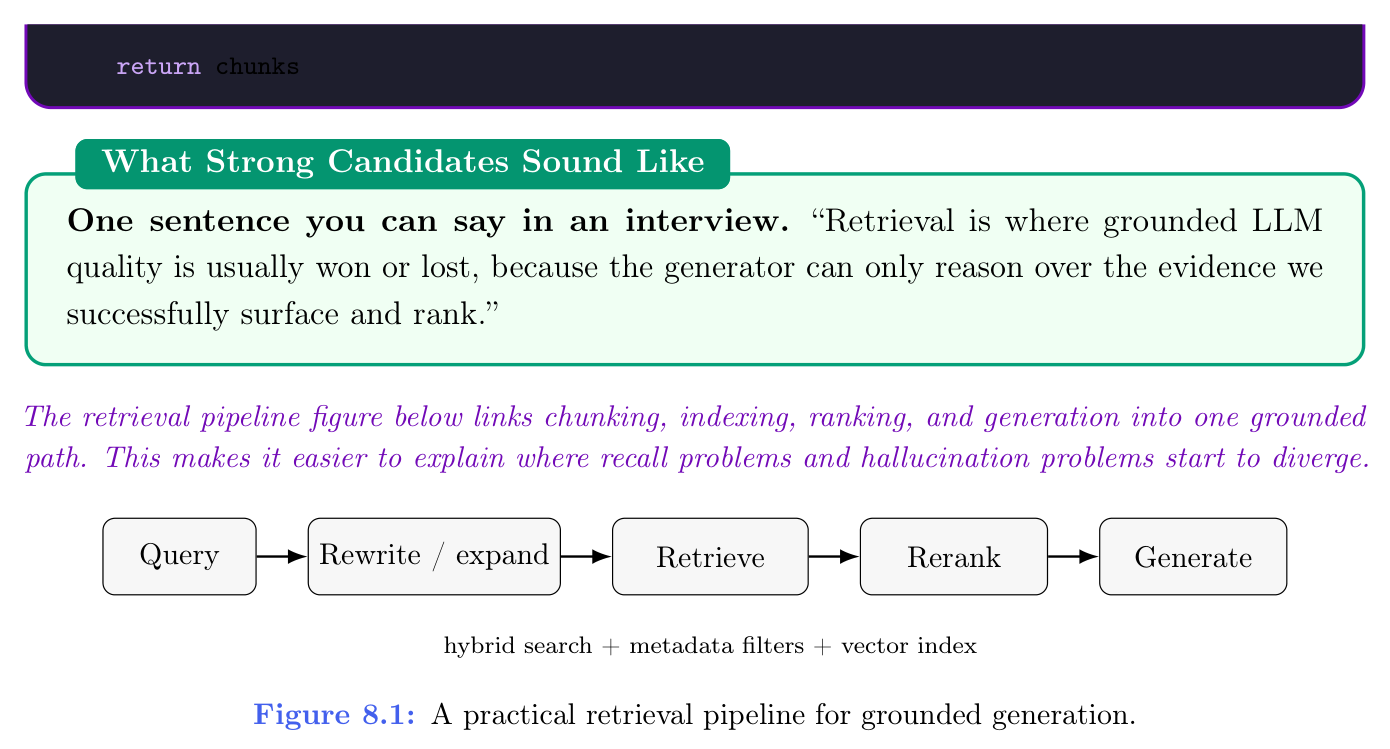
表 8.2:检索质量通常输赢在何处
| 组件 | 核心问题 | 典型失效 |
|---|---|---|
| 切块 | 应以何种粒度被检索? | 块太大或太细 |
| 嵌入 / 词汇检索 | 系统能否找到可能的证据? | 语义漏检或精确匹配漏检 |
| 元数据过滤 | 搜索是否发生在正确的切片? | 租户、日期或范围错误 |
| 重排 | 最优段落是否在前列? | 有用证据埋得太深 |
| 提示拼装 | 模型是否看到足够干净的支撑? | 上下文噪声淹没答案 |
问答(Q61–Q70)
Q61. 什么是检索增强生成(RAG)?
答。RAG 是一种模式:系统先检索相关外部信息,再把这些信息作为上下文交给语言模型生成。目标是加强事实锚定、支持引用,并在不重训基座模型的前提下实现知识更新。
核心洞见在于:并非所有知识都应塞进模型权重。外部检索让系统能访问更新、更可审计的证据。interview中要同时说清目的与收益:RAG 提升可控性的程度,常与提升准确性同样重要(Lewis et al., 2020)。
Q62. 词汇检索与稠密检索有何区别?
答。词汇检索匹配显式词项或短语,因而在措辞重叠重要时很强。稠密检索使用嵌入,因而即使查询与文档表面形式不同,也能检索到语义相关的内容。
取舍很直接:词汇检索保护精确匹配;稠密检索改善语义召回。企业系统里二者常需兼备——用户往往概念化提问,而文档写的是操作性表述。
Q63. 为何混合检索往往优于只用一种方法?
答。混合检索同时结合词汇与稠密信号,使系统同时受益于精确术语与语义相似度。这有助于在同一条链路中处理缩写、错误码、产品名、法律条款与用户改述。
强interview回答是:混合检索缩小每种方法各自的盲区。单靠稠密可能漏掉稀少标识符;单靠词汇可能漏掉改述。二者结合常能改善阶段召回。
Q64. 为何切块在 RAG 中如此重要?
答。切块决定检索的单位。块太大,检索会变粗——每次命中夹带过多无关文本。块太小,答案可能失去解读所需的周围语境。好的切块与源材料结构对齐。
interview中要说:切块既是召回决策也是精确率决策;它既塑造检索器能找到什么,也塑造生成器在段落被捞出后能理解什么。
Q65. 元数据过滤如何改善检索质量?
答。元数据过滤用结构化属性(如产品、地区、日期、语言、权限范围、文档类型)缩小搜索空间。这有助于系统在按语义相关性排序之前,就先检索到正确的邻域。
实务教训是:检索质量不只取决于更好的嵌入。结构化约束能以低廉、可靠的方式承担大量工作。强候选人常把元数据过滤列为生产检索里投入回报比最高的改进之一。
Q66. 什么是向量数据库?它解决什么问题?
答。向量数据库存储嵌入,并支持高效的近邻搜索。它被设计为在大规模下找出与查询向量最相似的向量,常同时结合元数据过滤以及复制、持久化、监控等运维能力。
重要的interview观点是:向量库是基础设施,不是智能本身。它让检索在速度与规模上可行,但相关性仍取决于其上层的嵌入模型、切块策略与排序逻辑。
Q67. 生产系统为何依赖近似最近邻(ANN)搜索?
答。在大索引上精确最近邻很昂贵:每次查询若要与过多候选逐一比较,成本过高。近似方法用少量召回换取速度与可扩展性,在真实系统中通常是正确折中。
interview中最佳回答是运维向的:ANN 的存在是因为搜索系统必须以低延迟服务真实流量。问题不在于近似在哲学上是否「纯粹」,而在于它是否在生产速度下仍保留足够相关性。
*Q68. 什么是重排?为何有用?
答。重排对一阶段检索返回的短名单应用更昂贵的相关性模型。初始检索器最大化速度与召回;重排改善顺序,使最佳证据抵达生成器。
常见模式是双编码器检索再接交叉编码器重排。这兼得向量搜索的可扩展性与更丰富查询—文档交互的精确率。interview中把重排解释为第二阶段质量过滤。
Q69. 查询改写如何帮助检索?
答。查询改写把用户的原始问题转成更贴合索引内容的形式。系统可能展开缩写、规范化行话、补关键词、消歧实体,或将一个复杂查询拆成多个聚焦的检索意图。
关键是:用户不会自然地说「索引友好」的话。强回答是:查询改写常是在不重嵌整个语料的前提下改善召回的最便宜手段之一。
Q70. 检索质量哪些离线指标最重要?
答。Recall@k 度量相关证据是否出现在短名单里。平均倒数排名(MRR)与 nDCG 度量相关项是否靠近列表顶部。对答案生成系统,段落级相关性还应与端到端有据答案质量挂钩。
最强的interview回答是:检索指标不应与生成结果割裂。离线很强的检索器若向生成器喂噪声证据,仍可能在用户任务上失败。