说明
底本为 Language Models Interview Handbook(© 2026 Lamhot Siagian, AI Engineering Insider);个人学习整理,转载请注明出处,勿用于商业再发行。
第 15 章 文本生成、解码与规模化服务
本章概述
生成是 LLM 系统最可见的部分,但好的生成依赖许多隐藏的工程选择。解码决定下一词元如何被选中;服务基础设施决定在负载下响应能有多快、多可靠。关于神经文本退化的研究表明,朴素似然最大化解码会产生重复、低质量文本,因此现代系统会仔细调节采样策略(Holtzman et al., 2020)。
本章把模型行为与部署现实绑在一起:吞吐、延迟、流式输出、KV 缓存、量化、长上下文服务,以及安全控制。
Interview Anchor interview锚点
| 维度 | 内容 |
|---|---|
| interviewer真正想测的 | 是否理解解码质量与服务可靠性是耦合决策。 |
| 高质量回答套路 | 把解码控制、延迟权衡、批处理、流式、缓存与可观测性讲成同一套服务系统。 |
| 常见低分答法 | 只答温度和 top-p;资深回答会包含吞吐、排队、安全与监控。 |
INTERVIEW CHEATSHEET interview速记条
| 项 | 要点 |
|---|---|
| 要表达的亮点 | 解码不只是「风格」;它改变质量、确定性、速度与用户体验。 |
| 最佳举例 | 面向确定性抽取的正确解码配置,与探索式头脑风暴或创意写作非常不同。 |
| 可追问方向 | 提到流式、批处理、缓存复用与服务等级目标(SLO)。 |
| 资深补充 | 说明生成控制如何与基础设施成本相互作用。 |
| 切忌这样说 | 把服务当成与模型行为无关的另一件事。 |
下面的生成服务示意图把从模型输出到用户交付连成闭环:便于把解码、服务与监控当作一条运维路径,而不是三个割裂话题。
图 15.1(A simplified generation service path from request to monitored delivery.):
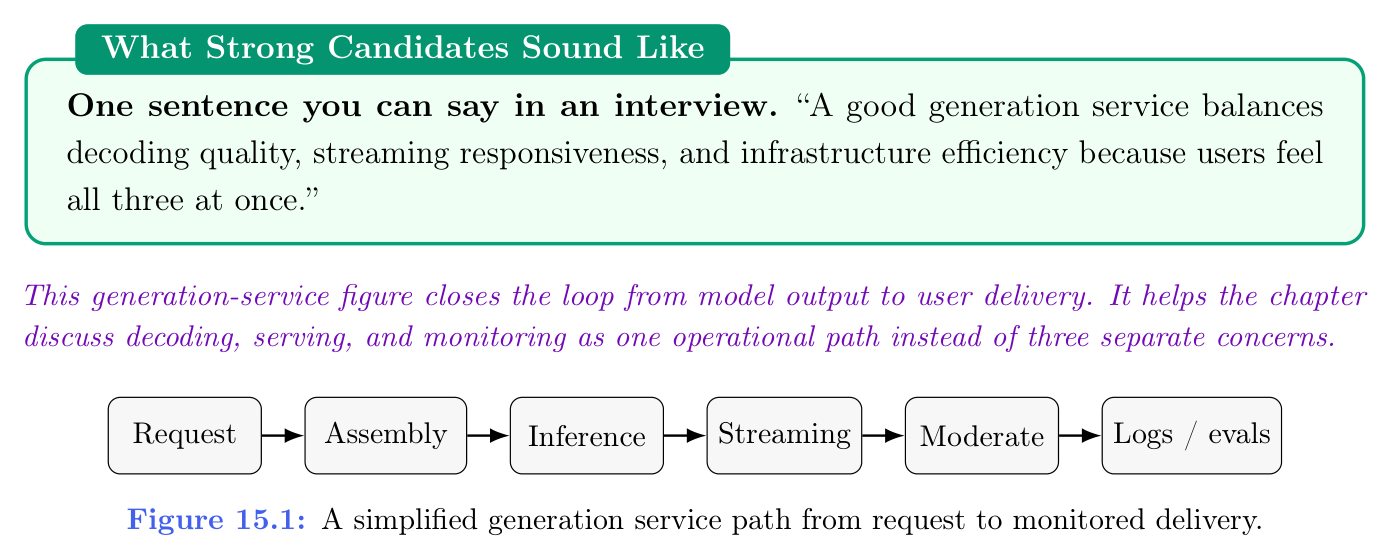
表 15.1 把生成章节保持在可操作层面:说明采样设置是用户体验与安全的杠杆,而不只是论文参数。
| 控制项 | 主要作用 | 实务提示 |
|---|---|---|
| Temperature(温度) | 改变下一词元分布的随机性 | 更低更确定性,更高更多样 |
| Top-k | 把候选限制在概率最高的 k 个词元 | 适合作为对尾部探索的硬上限 |
| Top-p | 从累积概率达到 p 的最小集合中采样(核采样) | 常作为自然文本生成的稳健默认 |
| Max tokens | 封顶输出长度 | 对成本与延迟控制很重要 |
What Strong Candidates Sound Like
:「好的生成服务要同时平衡解码质量、流式响应感与基础设施效率——用户会同时感受到这三者。」
问答
Q132. 温度、top-k 与 top-p 如何改变模型输出?
答。 温度对词元概率分布做缩放:调低更确定,调高更多样。Top-k 把采样限制在概率最高的 k 个词元。Top-p(核采样)把采样限制在累积概率超过 p 的最小词元集合。
interview里要把这些讲成解码控制,而不是神秘的「创造力旋钮」。它们调节确定性、多样性与出错风险之间的权衡。核采样之所以重要,是因为它能减少采到低概率尾部词元——那些词元往往会损害文本质量(Holtzman et al., 2020)。
Q133. 束搜索(beam search)与贪心解码相比如何?
答。 贪心解码每一步都选单个概率最高的下一词元。束搜索同时保留多条候选延续并并行扩展,系统有机会从局部诱人但全局较差的选择中恢复,在翻译或约束生成等任务上可提升连贯性。
代价是算力更高;且它仍在优化较窄的概率目标,对所有开放式任务并非自动更优。interview里可以说:生成是一个搜索问题——贪心是最便宜的搜索,束搜索是对候选延续更广但仍有限的搜索。
下面的采样片段属于服务章节,因为解码选择是产品侧控制:展示一次生成调用如何在 API 边缘暴露温度、top-p 与 token 预算等决策。
Listing 15.1:Sampling controls in a text-generation pipeline
1 | from transformers import pipeline |
Q134. 为何流式生成面向用户系统很重要?
答。 流式让系统逐词元返回,而不必等整段生成完毕。这改善感知延迟、维持用户参与感,并在总生成时间仍较长时让界面感觉更灵敏。
interview里要同时提 UX 与系统含义:流式也会改变取消行为、错误处理与部分输出策略,因此不只是前端技巧。
Q135. 批处理与并发如何提升服务效率?
答。 批处理让多个请求共享加速器工作,提高硬件利用率。并发策略帮助服务器管理大量活跃会话而不让部分用户饿死。两者结合可显著提高吞吐,尤其在高流量推理场景。
代价是延迟:更大的批次提升效率,但可能推迟单个请求。强响应把服务框定为尾延迟与集群利用率之间的平衡。
Q136. 什么是 KV 缓存,为何对自回归解码重要?
答。 在自回归解码中,模型反复对已有词元做注意力。KV 缓存保存已算好的 key/value 张量,避免每个新生成词元都重算一遍。这使生成快得多,尤其对长提示与长输出。
interview里应说:对仅解码器模型,KV 缓存是最重要的服务优化之一——它把冗余的重复计算变成可复用状态。
Q137. 量化如何帮助部署大模型?
答。 量化降低模型权重(有时也包括激活)的数值精度,从而减少内存并常能加快推理。这使大模型能跑在更便宜硬件上,或让单机处理更多并发请求。
interview稳妥说法是:量化是工程权衡——常带来巨大效率收益,但必须验证质量,因为激进压缩可能在部分任务上损害输出保真度。
Q138. 工程师应如何理解吞吐与延迟?
答。 吞吐衡量系统在一段时间内能完成多少总工作量;延迟衡量单个请求耗时多久。优化其一可能损害另一者:高度批处理的集群可能吞吐很高,用户却仍觉得慢。
interview里应说:正确目标取决于产品。内部批任务可能优先吞吐;交互式 copilot 可能优先首词元延迟与尾延迟。
Q139. 什么让长上下文服务很困难?
答。 长上下文难在:内存与注意力成本随序列长度增长,提示处理更贵,上下文稀释风险上升。即便模型支持长上下文,每次请求都用满也可能浪费或有害。
强答应连回检索与上下文设计:更长上下文是能力,不是默认运行模式。
Q140. 安全与审核如何嵌入生成流程?
答。 安全控制可在生成前、生成中、生成后施加:输入可筛查,工具可权限门控,解码可加约束,输出可在交付前审核或校验。在敏感应用中,不安全或不应支持的生成应触发拒绝或人工复核。
interview里要把安全说成全链路属性,而不是单个分类器:可靠系统会叠加多层控制,因为没有单一机制能兜住一切。
Q141. 用系统设计术语,你会如何描述可扩展的 LLM 生成服务?
答。 可扩展的生成服务通常包括:请求路由、鉴权、提示组装、检索或工具编排、模型服务、流式交付、日志、缓存、安全检查,以及评估反馈闭环。也可能采用分层模型路由:简单任务走更便宜模型,更难任务走更强模型。
最佳interview回答是架构式的:展示你能把模型行为与队列、自动扩缩容、可观测性、护栏与回滚策略连起来——那才是把模型访问变成产品服务。