说明
底本为 Language Models Interview Handbook(© 2026 Lamhot Siagian, AI Engineering Insider);个人学习整理,转载请注明出处,勿用于商业再发行。
第 2 章 Token、分词与上下文窗口
本章概述
本章主要在讲:大语言模型如何把原始文本变成可计算的单元。在能做分类、检索、摘要或问答之前,模型必须先完成分词(tokenize):把输入映射为 token ID,再放进有限的上下文窗口。这些设计会影响模型行为、多语言鲁棒性、显存占用、延迟与计价。
从词级词表走向子词(subword)分词之后,现代语言模型才更适合开放词表任务。诸如字节对编码(BPE)与 SentencePiece 等方法,把文本拆成可复用的片段,从而更好地处理罕见词、专名、拼写变体与多语文本,而不必依赖固定「整词」词典(Sennrich et al., 2016; Kudo & Richardson, 2018)。
Interview Anchor interview锚点
| 维度 | 内容 |
|---|---|
| interviewer真正想测的 | 能否把分词与价格、延迟、多语言表现、截断风险、提示设计联系起来,而不是背词表冷知识。 |
| 高质量回答套路 | 先定义 token 是真实计算单位,说明为何不等于单词;再把 token 数量与上下文预算、检索切块、输出规划挂钩。 |
| 常见低分答法 | 说「模型在读词」。更强回答会提子词、特殊 token,以及输出 token 同样占用同一窗口与预算。 |
INTERVIEW CHEATSHEET interview速记条
| 项 | 要点 |
|---|---|
| 要表达的亮点 | Token 数量同时牵动成本、截断、以及有多大空间放证据。 |
| 最佳举例 | 说明为何一段 JSON、源码块或从 PDF 复制的文本,消耗的 token 往往远超直觉。 |
| 可追问方向 | 提到 BPE 或 SentencePiece,并把分词和切块大小、上下文预算直接连起来。 |
| 资深补充 | 会谈预留输出预算、避免检索切块过大浪费 token。 |
| 切忌这样说 | 把「128k 上下文」理解成 128k 词;或假设更长提示必然带来更好答案。 |
书里开篇几页用图把 token 流、上下文预算和提示机制串起来:在模型真正吐答案之前,token 往往早就成了工程约束。
下面示例刻意很短,用于记 budgeting:在固定窗口里,给输出留多少会直接挤占检索和工具上下文还能用的长度。
Listing 2.1:interview演示与提示设计讨论里用得上的一段 token 预算小助手。
1 | def reserve_context(total_window: int, prompt_tokens: int, output_budget: int) -> int: |
What Strong Candidates Sound Like
「分词是人类语言变成模型计算的地方——它悄悄决定了成本、延迟、检索切块、多语鲁棒性,以及最终答案是否还能塞进窗口。」
下图把分词放进端到端链路:分词不是孤立的预处理,它直接塑造模型实际能依据的上下文。
图 2.1(From raw text to model-ready context.):
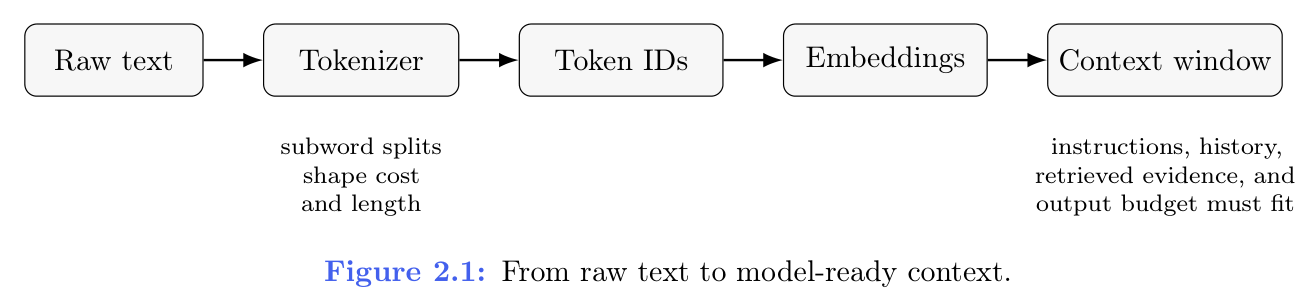
表 2.1(A practical comparison of tokenization strategies):
| 方法 | 长处 | 局限 |
|---|---|---|
| Whitespace / word-level | 易检查 | 罕见词、形态变化、许多多语场景下易崩 |
| Byte-pair encoding (BPE) | 词表紧凑下的强开放词表行为 | 学到的合并对人类未必直观 |
| SentencePiece | 语言无关、可仅从生文本训练、制品可复现 | 仍须评测——切分选择会影响成本与行为 |
问答
Q1. 什么是 token?为什么说它是 LLM 里「真正的」计算单位?
答。 Token 是 LLM 实际读取并预测的单位;实务上 token 通常不是完整单词,可能是整词、词片、标点、空白模式,甚至字符片段,取决于分词器。模型从不直接看见原始句子,只看见一串 token ID。
Token 要紧,因为几乎所有工程上限都用 token 来表述:上下文长度、费用、吞吐、延迟、检索块大小、输出预算。API 说支持 128k 上下文,指的是 128k tokens,不是 128k 单词。interview里最稳的答法,是把分词同时连到建模与运维:它是人类文本与机器计算之间的桥。
Q2. 为什么 token 不会和「词」一一对应?
答。 人类语言很「脏」:前后缀、标点、缩写、emoji、代码片段、多语格式,往往套不进「一词一单元」。分词器因此按对模型统计上高效的方式切块,而不是按语言学上「完美」的方式。
所以看上去短的句子可能吃掉很多 token,看上去长的反而更少。从 PDF、源码、JSON 或没有空格分词的语言里复制提示,常会异常膨胀。这影响线上 prompt 预算与成本估算。interview里可强调:分词优化的是表征效率,不是人类可读性。
Q3. 字节对编码(BPE)如何帮助现代语言模型?
答。 BPE 从小单元出发,反复把高频符号对合并成更大子词;久之,「ing」「tion」或领域片段会变成可复用词表项,使常见文本更紧凑,同时仍能组合式表示罕见词。
关键是开放词表:遇到未登录词不必崩,可以拆成已知碎片。该思想在神经机器翻译中影响深广,后因能改善罕见/未见形态、又不让词表爆炸,而成为大模型分词里的常见方案(Sennrich et al., 2016)。
Q4. 什么是 SentencePiece?何时比经典「先按空白切词」更合适?
答。 一言以蔽之:SentencePiece 在训练分词模型时,把输入看成原始字符序列,不要求你先用空格、标点规则把「词」切好;子词表(以及如何把未见串拆成子词)都从数据里学出来。因此在多语混排、中日韩等不以空格分词、或空白被 OCR、社交平台、代码粘贴弄乱时,比「先按空白切成词再上 BPE」更稳。
SentencePiece 单独说明(interview可展开)
- 与经典流程的对比:常见做法是先按空白
split()再学子词;SentencePiece 则把「词界」也交给统计学习,避免预分词错误传导到子词层。 - 内部仍可接成熟子词算法:常用实现里可选用 BPE 或 Unigram 等目标来合并与剪枝子词,差别在「由谁提供初始切分」——这里是端到端从生文本估计(Kudo & Richardson, 2018)。
- 空格怎么表示:实现上往往用显式符号把「词前空格」编进词表(例如把空格编码成可见记号),这样空白本身也是可学习的 token,中英文、符号混写时行为更一致。
- 交付物:通常是一个
.model(与可选配置/词表),训练与线上推理共用同一文件,利于复现与跨环境对齐。
流程举例(可口述)
下面是一条最小心智路径,便于你在interview里边说边画箭头:
- 准备语料:收集原始句子级文本(允许多语、噪声、代码片段;一般不强制先清洗成「完美词序列」)。
- 训练子词模型:在语料上跑 SentencePiece,指定词表大小与算法(BPE / Unigram 等),得到子词表与合并/抽样规则。
- 编码:新句子进入同一模型 → 输出 token ID 序列(可能对应子词 + 空格/标点片段)。
- 解码:把 ID 串还原为文本,用于检查边界、调试或拼回给人看的字符串。
微型示意(非真实 ID,只说明形状):
- 英语句
New York可能被切成类似▁New、▁York两段子词(▁ 仅表示「前面带空格」,具体以所用模型为准)。 - 中文句「我爱自然语言处理」无空格,可能被切成若干子词,例如
▁我、爱、自然、语言、处理——真实切分完全由训练语料与词表大小决定,interview重点是:你能说清「为何不依赖人工词界」。
实务价值在可复现与可迁移:规则、规范化行为与词表打成一个制品,训练与推理在多系统间一致。interview强答:当你要为混合语料、噪声文本或大规模训练做稳健端到端分词时,SentencePiece 是合理选型(Kudo & Richardson, 2018)。
Q5. 什么是上下文窗口(context window)?
答。 上下文窗口指模型在单次前向里最多能 attend 的 token 数,通常包含系统提示、用户输入、检索上下文、工具结果、对话历史以及生成预留。若总和超上限,就必须截断、摘要或丢弃。
在真实系统里,它不像无限记忆的大殿,更像一张工作台:同一时间只有放得下台面的东西能被积极使用——所以聊天、Agent 循环与 RAG 里,上下文管理是一等工程问题。
Q6. 为什么分词会直接影响成本与延迟?
答。 常见 LLM API 按处理或生成的 token 计费;Transformer 注意力开销随序列长度增长。token 越多,计算与显存压力越大,延迟越高。两条人类眼里「差不多」的 prompt,token 化后运行时可能差很多。
所以有经验的工程会先量 token 再上线式发布长检索上下文、结构化输出或多步串行调用。interview点:token 效率不只是财务,也影响体验、吞吐与负载下稳定性。
Q7. 输入比模型能吃的还长时会发生什么?
答。 必须截断、滑窗、摘要、压缩或有选择地检索。若处理得糙,模型可能错过关键指令或证据,却仍能自信地答不完整。
关键工程教训:长上下文并不取消检索与上下文管理。生产里很少应把所有东西无脑塞进 prompt;需要排序、选块与记忆策略,让最相关信息在预算内活下来。
Q8. 截断、滑动窗口与摘要有何区别?
答。 截断:直接丢 token,常从首尾下手;简单但可能扔掉模型最需要的指令或证据。滑动窗口:用重叠分段看长文局部,而不一次吃掉全篇。摘要:把较早内容压成更短表示,可能保留大意,但会丢措辞精确性。
interview里把权衡说清楚:截断最便宜;滑窗保局部细节;摘要保要旨牺牲原句。
Q9. 为什么特殊 token 对模型行为很重要?
答。 特殊 token 像结构标记:句首/句尾、padding、分隔、指令轮次、图像占位、工具边界等。用户未必看见,却塑造模型如何读序列。
微调或推理时弄错这些边界,会带来隐晦 bug——例如聊天格式若不符合模型习得的角色分界。强答:分词不只「切开文本」,还在编码结构。
Q10. 生产里应如何做 token 预算?
答。 好的预算先为最贵、最难妥协项留位:系统指令、必备工具、护栏、输出长度、置顶检索段落;其余再按价值抢剩余空间——所以检索排序、对话摘要与回复长度上限才那么重要。
实用做法是:从最大安全预算倒推设计提示,而不是从「理想提示」正推。interview里要显得运维化:估计均值与尾部用量、限制输出、监控溢出,把 token 预算当可靠性控制而非事后想起来再补。
Listing 2.2:用 Hugging Face Tokenizer 数 token,把上文理论和工程里「提示为何突然变贵/溢窗」连起来。
1 | from transformers import AutoTokenizer |